ZTools для Apache Zeppelin
Zeppelin — это интерактивный блокнот, очень полюбившийся дата-инженерам. Он умеет работать со Spark и отлично подходит для интерактивного анализа данных.
Проект недавно добрался до версии 0.9.0-preview2 и активно развивается, но, тем не менее, множество вещей всё ещё не реализованы и ждут своего часа.
Одна из таких вещей — API для получения дополнительной информации о том, что происходит внутри блокнота. С одной стороны, там имеется API, который полностью решает задачи по высокоуровневому управлению ноутбуками. Но если вам нужно что-то нетривиальное — плохие новости.

С этой проблемой столкнулись разработчики Big Data Tools — плагина для IntelliJ IDEA, который предоставляет интеграцию со Spark, Hadoop и дает возможность редактировать и выполнять ноутбуки в Zeppelin. Для полноценной работы в IDE недостаточно умения создавать и удалять ноутбуки. Необходимо выгрузить целый вагон информации, которая позволит делать такие штуки как умное автодополнение.
С одной стороны, можно было бы добавить дополнительные методы API прямо в Zeppelin. Благо, это открытый проект с исходниками на GitHub. С другой стороны, это не всегда осмысленно. Во-первых, это долго, ведь на ревью таких изменений отвлекается команда разработчиков Zeppelin. Во-вторых, если тебе лично нужна какая-то специфическая метаинформация — совершенно не факт, что она понадобится хоть кому-то ещё. Это прямая дорога к тому, чтобы превратить публичный API в одну большую свалку.
Так возник ZTools — инструментарий, который позволяет вытягивать нужную информацию из Zeppelin, даже если её нет в API. Весь код «серверной» части находится в открытом доступе на GitHub под лицензией Apache License 2.0. Примерно 90% кода написано на Scala, а остальное — на Java.
(На самом деле, эта штука работает с любым Scala REPL, так что его можно использовать не только для Zeppelin).
Чтобы понять, что может ZTools, взглянем на панель Variables View и редактор кода в плагине Big Data Tools. Этот код входит в IntelliJ Ultimate Edition, и конечно, не лежит в опенсорсе, но посмотреть глазами никто не мешает. Если вы захотите использовать ZTools в своих целях, этот пример покажет, как это могло бы выглядеть у вас.
Когда вы добавляете новый ноутбук в Big Data Tools, у вас появляется возможность включить интеграцию с ZTools. После чего в панели инструментов открывается возможность посмотреть значения локальных переменных:
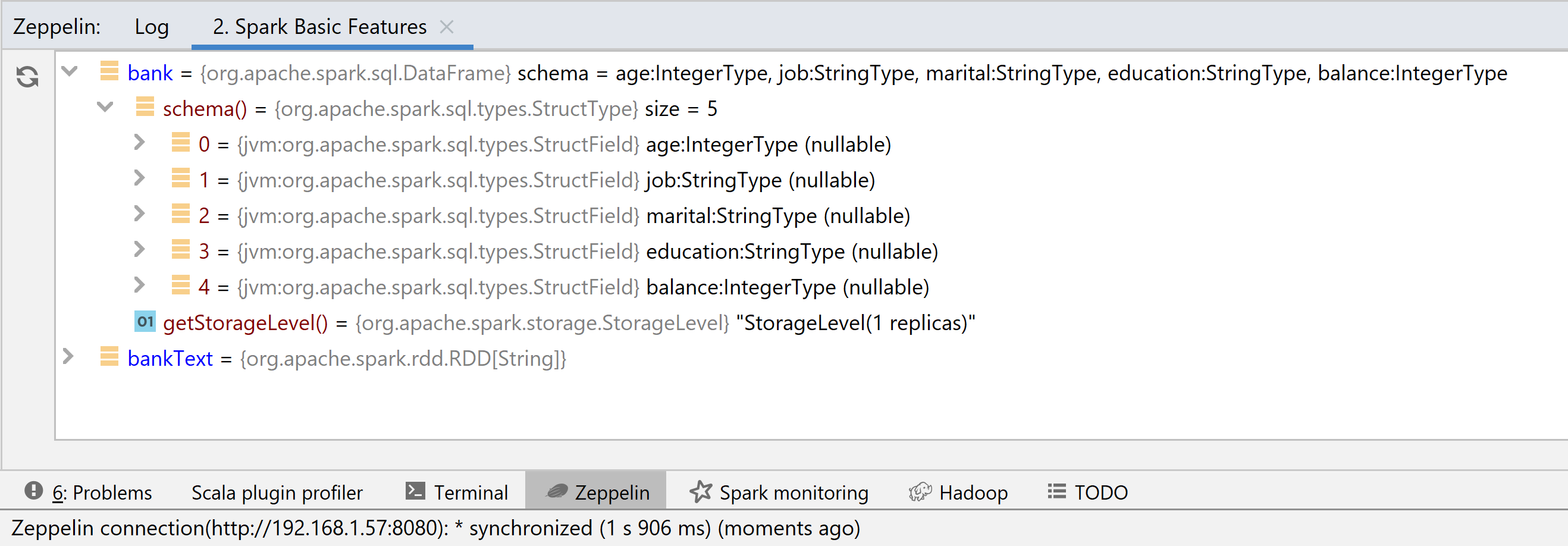
Подождите, как же так? Посмотреть значения переменных после выполнения?
Эта простая фича, по сути, является аналогом отладчика и позволяет сэкономить разработчику кучу времени, когда с его кодом что-то не так.
Это ещё не всё. Если у вас есть какой-то sql.DataFrame, то у него можно увидеть набор колонок!
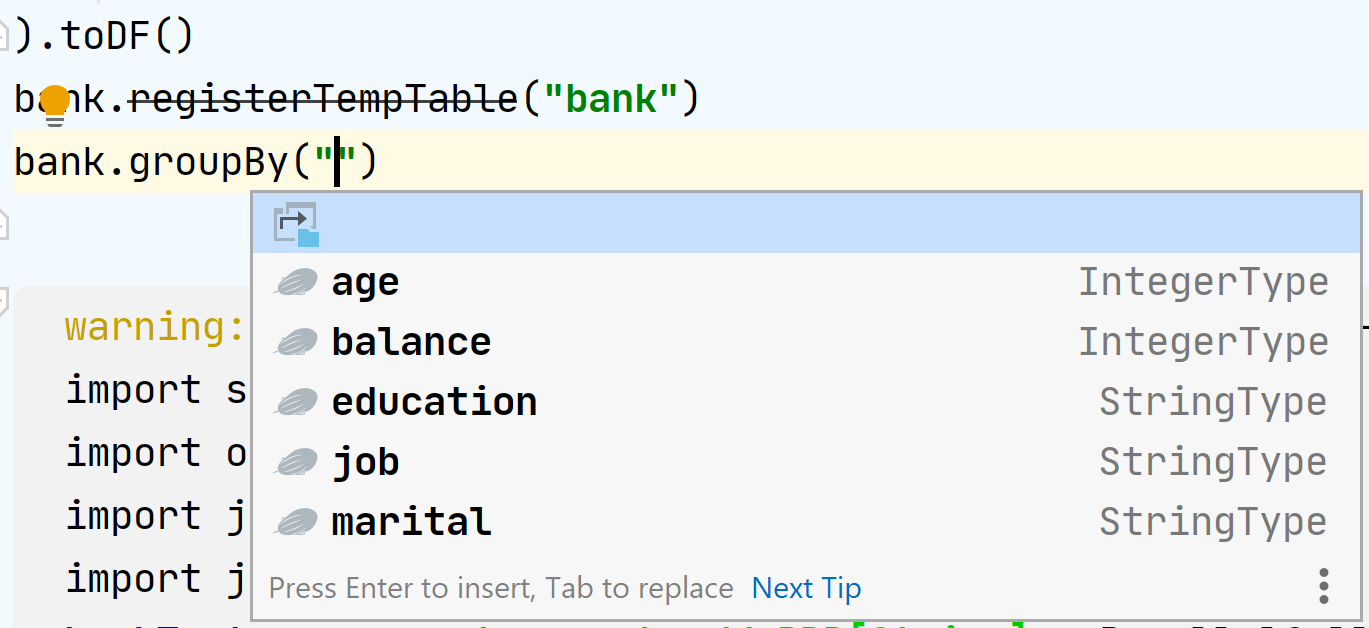
Звучит как магия.
Именно эту магию и предоставляет нам ZTools. В момент выполнения параграфа он анализирует контекст на сервере, вычленяет интересную информацию и отправляет на клиент.
Часть первая: взаимодействие сервера и клиента
Давайте попробуем понять, каким образом Zeppelin научился отдавать список локальных переменных и колонок.
Есть два пути. Можно пойти со стороны сервера (от которого у нас есть опенсорсный исходник на GitHub), либо пойти со стороны клиента (от которого исходника нет).
Второй способ вполне осуществим: можно перехватить трафик и посмотреть, какие запросы клиент посылает серверу, и что он ему отвечает. Начнем с него и посмотрим, насколько глубока кроличья нора. Кроме того, это научит нас одному интересному хаку, как можно писать клиенты для Zeppelin.
Отследить трафик можно разными способами, но мне по душе связка mitmproxy и Wireshark. Я опущу технические подробности настройки этой машинерии, если будет интересно — задайте вопрос в комментариях.
Давайте запустим какой-нибудь параграф из стандартного примера Zeppelin — «Spark Basic Features».
Заходим в mitmproxy и смотрим, как выглядит типичный ответ сервера Zeppelin к своему стандартному API /api/notebook (полный ответ есть в этом гисте).

Никаких интересных данных здесь нет, как и ожидалось. Где же наши локальные переменные, Лебовски? Наверное, они передаются через WebSocket?
Заходим в Wireshark и пристально смотрим на трафик:

Немного покопавшись в трафике видим, что, сразу после запуска параграфа, на сервер отправляется JSON с его полным текстом. Это ожидаемо.
Дальше нужно применить чудеса внимательности и заметить кое-что странное. Когда вы запускаете параграф в Big Data Tools, в интерфейсе IntelliJ IDEA, в вашем ноутбуке на секунду появляется и исчезает дополнительный параграф:

Давайте посмотрим, как это отражается на трафике.
Во-первых, этот временный параграф отправился на сервер. Полный текст запроса есть здесь, а нам из него интересен только вот этот кусочек:
%spark
// It is generated code for integration with Big Data Tools plugin
// Please DO NOT edit it.
import org.jetbrains.ztools.spark.Tools
Tools.init($intp, 3, true)
println(Tools.getEnv.toJsonObject.toString)
println("----")
println(Tools.getCatalogProvider("spark").toJson)"Собственно, это код того самого временного параграфа. Здесь происходит вызов ZTools, и это хорошая подсказка, с каких именно функций стоит изучать код в репозитории на GitHub.
Дальше на нас сваливаются несколько кусков данных.
- В одном из них содержится полная структура и значения локальных переменных bank и bankText.
- В другом находятся колонки датафрейма.
Мы нашли всё, что хотели: запросы клиента, данные с сервера и ответ на вопрос — как именно передаются дополнительные данные.
Дальше по тексту мы проверим, сможем ли мы с помощью самостоятельно написанной программы повторить ту же последовательность действий.
Выводы из первой части
- Благодаря сканированию трафика, мы научились важному приему при написании клиентов для Zeppelin с использованием ZTools: нужно добавлять временный параграф, вызывать ZTools, а потом сразу же удалять временный параграф (пока никто не заметил). Именно так работает плагин Big Data Tools.
- Внутри временного параграфа мы подсмотрели вызовы класса Tools. Именно с него мы и начнем изучение исходников ZTools.
Исходники ZTools лежат на GitHub
Репозиторий состоит из двух больших частей: «scala-repl» и «spark».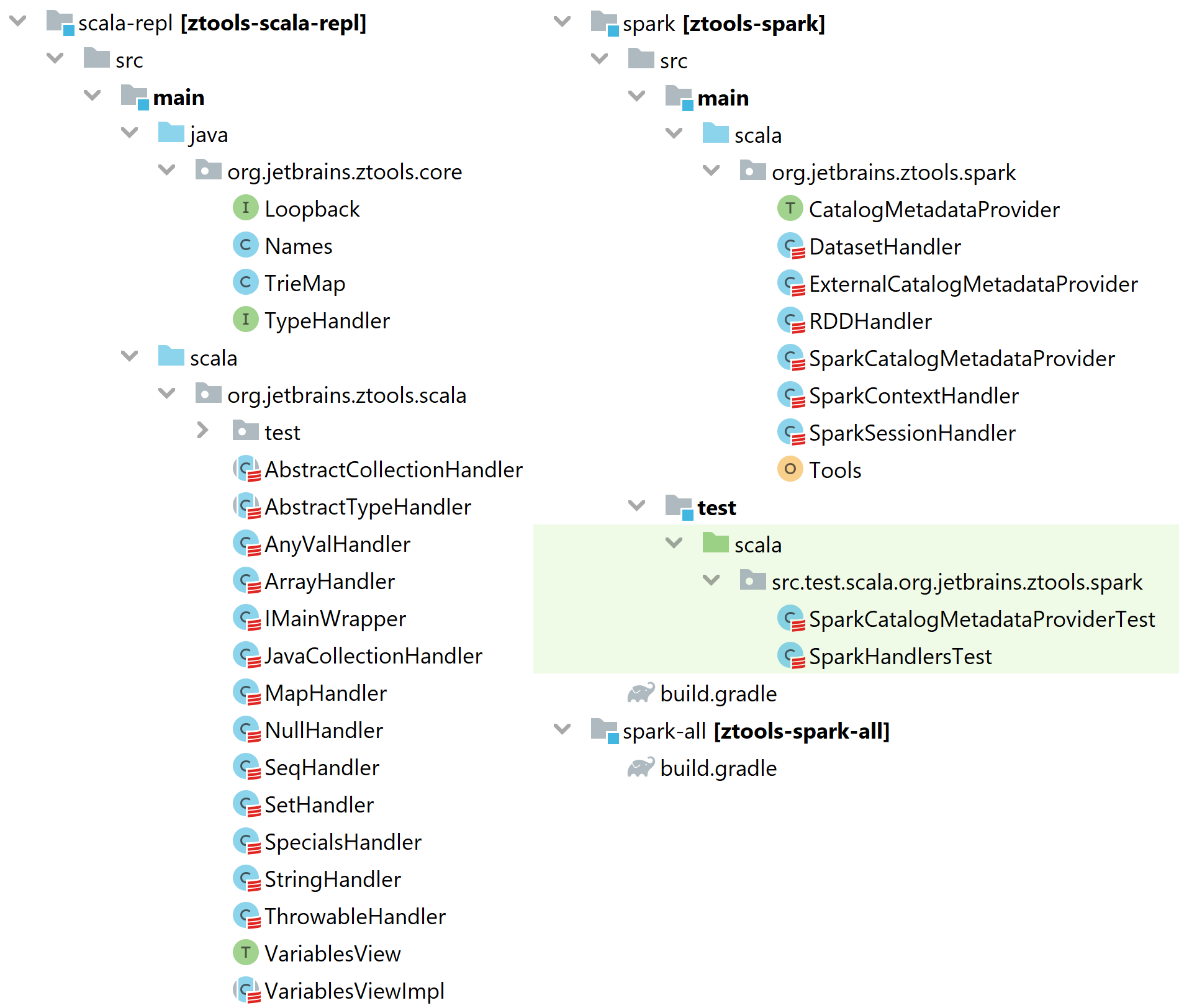
Напоминаю код нашего временного параграфа:
%spark
// It is generated code for integration with Big Data Tools plugin
// Please DO NOT edit it.
import org.jetbrains.ztools.spark.Tools
Tools.init($intp, 3, true)
println(Tools.getEnv.toJsonObject.toString)
println("----")
println(Tools.getCatalogProvider("spark").toJson)"Благодаря последней строчке, мы знаем о колонках в датафрейме. Результат получается с помощью спарковских функций Catalog.listTables (), и Catalog.listTables (), после чего заворачивается в JSON и отправляется на клиент.
Гораздо интересней, откуда берутся локальные переменные. При инициализации Tools, создается нечто под названием VariablesView, которому посвящен целый отдельный подпроект. Давайте заглянем в него.
Если взглянуть на тесты, становится понятно, как это использовать:
@Test
def testSimpleVarsAndCollections(): Unit = {
withRepl { intp =>
intp.eval("val x = 1")
val view = intp.getVariablesView()
assertNotNull(view)
var json = view.toJsonObject
println(json.toString(2))
val x = json.getJSONObject("x")
assertEquals(2, x.keySet.size)
assertEquals(1, x.getInt("value"))
assertEquals("Int", x.getString("type"))
assertEquals(1, json.keySet.size)
}Мы можем интерпретировать произвольный код на Scala и получать информацию о переменных в нём.
Интерпретация кода, в конечном счёте (если размотать все абстракции), ложится на плечи стандартного компилятора Scala, а точнее — пакета scala.tools.nsc.interpreter.
def withRepl[T](body: Repl => T): T = {
// ...
val iLoop = new ILoop(None, new JPrintWriter(Console.out, true))
iLoop.intp = new IMain(iLoop.settings)
// ...
}Вначале создается ILoop — главный цикл интерпретатора, а внутри него лежит IMain — это сам интерпретатор. У IMain вызывается метод interpret (code). Всё просто.
Информацию о переменных положено получать через такой трейт:
trait VariablesView {
def toJson: String
def toJsonObject: JSONObject
def toJsonObject(path: String, deep: Int): JSONObject
def variables(): List[String]
def valueOfTerm(id: String): Option[Any]
def registerTypeHandler(handler: TypeHandler): VariablesView
def typeOfExpression(id: String): String
}Из всех этих методов наиболее важно получение списка переменных. Но тут нас не ждет никаких сюрпризов. Оно реализовано прямым запросом к интерпретатору Scala, iMain: \
override def variables(): List[String] =
iMain.definedSymbolList.filter { x => x.isGetter }.map(_.name.toString).distinctА вот формирование JSON, который нам надо получать во «временном параграфе» — это уже куда более интересная функция. Внутри toJsonObject() накручена сложная магия, которая позволяет бродить по ссылкам между зависимыми переменными и ограничивать количество высылаемых коллекций и строк.
По-умолчанию, максимальный размер коллекции — 100 и максимальный размер строки — 400 символов. Можно не беспокоиться, что на клиента (плагин Big Data Tools или вашу самописную утилиту) прилетит терабайт запятых и всё навсегда повиснет. Сейчас эти лимиты жестко прописаны в коде, и будь моя воля, я перенес бы их куда-нибудь в настройки.
Если вы пользуетесь ZTools через класс Tools, то не все переменные вам доступны. В черный список отправляются такие штуки как $intp, sc, spark, sqlContext, z и engine. Если вы пишете запускалку самостоятельно, такой черный список тоже стоит предусмотреть.
Выводы из второй части
- С помощью ZTools можно доставать из Zeppelin разнообразные данные без необходимости захламлять публичный API;
- Сейчас доступны только те данные, которые существуют во время жизни нашего временного параграфа;
- Когда вы находитесь внутри Zeppelin, интерпретация кода на Scala — это просто. Особенно когда у вас уже есть обвязка REPL из проекта ZTools. Можно не ограничиваться идеями из ZTools, а добавить что-нибудь своё;
- Отдаваемые на клиент данные, если это делается с помощью класса Tools, ограничены разумными лимитами: 400 символов на строку, 100 элементов на коллекцию и ряд переменных из черного списка никогда не попадет в ваш JSON.
Часть четвертая: пишем свой клиент
Давайте воспользуемся тем, что ZTools могут работать без IntelliJ IDEA и напишем к ним собственную клиентскую часть. Рабочий пример можно будет найти в репозитории на GitHub.
Чтобы показать, что оно не зависит даже от Java, напишем всё на JavaScript (точнее, TypeScript) и Node.js. В качестве библиотеки для запросов по HTTP будем использовать Axios — у нее довольно красивый интерфейс с промисами.
Во-первых, давайте найдем какой-нибудь конкретный ноутбук на сервере, мне очень нравится «Spark Basic Features» из библиотеки примеров.
const notes = await axios.get(NOTE_LIST_URL);
let noteId: string = null;
for (let item: Object of notes.data.body) {
if ( item.path.indexOf('Spark Basic Features') >= 0 ) {
noteId = item.id;
break;
}
}Теперь, придумаем текст временного параграфа:
const PAR_TEXT = `%spark
import org.jetbrains.ztools.spark.Tools
Tools.init($intp, 3, true)
println(Tools.getEnv.toJsonObject.toString)
println("----")
println(Tools.getCatalogProvider("spark").toJson)`;Создадим его на стороне сервера:
const CREATE_PAR_URL = `${Z_URL}/api/notebook/${noteId}/paragraph`;
const par: Object = await axios.post(CREATE_PAR_URL, {
title: 'temp',
text: PAR_TEXT,
index: 0
});Запустим его:
const RUN_PAR_URL = `${Z_URL}/api/notebook/run/${noteId}/${parId}`;
await axios.post(RUN_PAR_URL);
Получим ответ:
const INFO_PAR_URL = `${Z_URL}/api/notebook/${noteId}/paragraph/${parId}`;
const { data } = await axios.get(INFO_PAR_URL);И удалим за ненадобностью:
const DEL_PAR_URL = `${Z_URL}/api/notebook/${noteId}/paragraph/${parId}`;
await axios.delete(DEL_PAR_URL);Полученный ответ нужно распилить на две части и распарсить как JSON:
const [varInfoData, dbInfoData] = (data.body.results.msg[0].data)
.replace('\nimport org.jetbrains.ztools.spark.Tools\n', '')
.split('\n----\n');
const varInfo = JSON.parse(varInfoData);
const dbInfo = JSON.parse(dbInfoData);Вот так можно посмотреть все переменные:
for (const [key, {type}] of Object.entries(varInfo)) {
console.log(`${key} : ${type}`);
}А вот так можно распечатать схему колонок:
for (const [key, database] of Object.entries(dbInfo.databases)) {
console.log(`Database: ${database.name} (${database.description})`);
for (const table of database.tables) {
const columnsJoined = table.columns.map(val => `${val.name}/${val.dataType}`).join(', ');
Logger.direct(`${table.name} : [${columnsJoined}]`);
}
}Как видите, это простейший код, который пишется за считанные минуты.
Часть третья: распространение
Недостаточно просто написать клиент для Zeppelin — нужно изменить настройки сервера Zeppelin, установить в него ZTools.
Печаль здесь в том, что на большом продакшене у вас, скорей всего, нет на это прав. Придется просить сисадминов. Этого совершенно никак не избежать.
Что касается самого процесса установки, если вы используете ZTools без своих модификаций, то можно воспользоваться нашим публичным репозиторием, добавить как артефакт Maven или отдельный JAR-файл.
Если же вам хочется расширить возможности ZTools самостоятельно, то можно собрать проект из исходников с помощью Gradle, получить JAR-файл и распорядиться им как захочется с учетом требований опенсорсной лицензии Apache License 2.0.
Big Data Tools автоматически устанавливают ZTools на подключенный Zeppelin. Делать так — хороший тон, всячески рекомендуем.
Выводы
- С помощью ZTools можно доставать из Zeppelin разнообразные данные без необходимости захламлять публичный API;
- Код, который это делает — довольно простой и понятный, и распространяется под очень удобной опенсорсной лицензией Apache License 2.0;
- При необходимости мониторинга трафика вашей службой безопасности — в статье показано, что содержимое трафика довольно понятно даже для людей без специальных навыков;
- С написанием клиентского кода придётся помучиться. Но теперь вы знаете трюк со «временным параграфом» и можете вдохновляться интерфейсом Big Data Tools.
