Знакомство с облаком: как работают статические методы распределения трафика
Распределение нагрузки в облаке IaaS-провайдера помогает эффективно использовать ресурсы виртуальных машин. Существует множество методов распределения нагрузки, но в сегодняшнем материале мы подробно остановимся на одних из самых популярных статических методах: round-robin, CMA и threshold algorithm. Под катом поговорим о том, как они устроены, в чем их характерные особенности и где они используются.

/ Flickr / woodleywonderworks / CC
Статические методы распределения нагрузки подразумевают, что при распределении трафика не учитывается состояние отдельных узлов. Информация об их параметрах «прописывается» заранее. И получается так, что здесь есть «привязка» к определенному серверу.
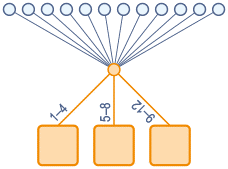
Статическое распределение — привязка к одной машине
Выбор сервера может быть обусловлен различными факторами, например, географическим расположением клиента, а может выбираться случайным образом.
Round-robin
Этот алгоритм распределяет нагрузку равномерно между всеми узлами. В этом случае задачи не имеют приоритетов: первый узел выбирается случайным образом, а остальные — далее по порядку. Когда количество серверов заканчивается, очередь возвращается обратно к первому.
Одной из реализаций этого алгоритма является round-robin DNS. В этом случае DNS отвечает на запросы не одним IP-адресом, а списком из нескольких адресов. Когда пользователь делает запрос на разрешение имени для сайта, DNS-сервер назначает новое соединение первому серверу в списке. Это постоянно перераспределяет нагрузку на серверную группу.
Сегодня этот подход используется для распределения ресурсов как внутри дата-центра, так и между отдельными ЦОД. Round-robin обычно реализуется с помощью обратных прокси, haproxy, apache и nginx. Приложение-посредник принимает все входящие сообщения от внешних клиентов, поддерживает список серверов и следит за трансляцией запросов.
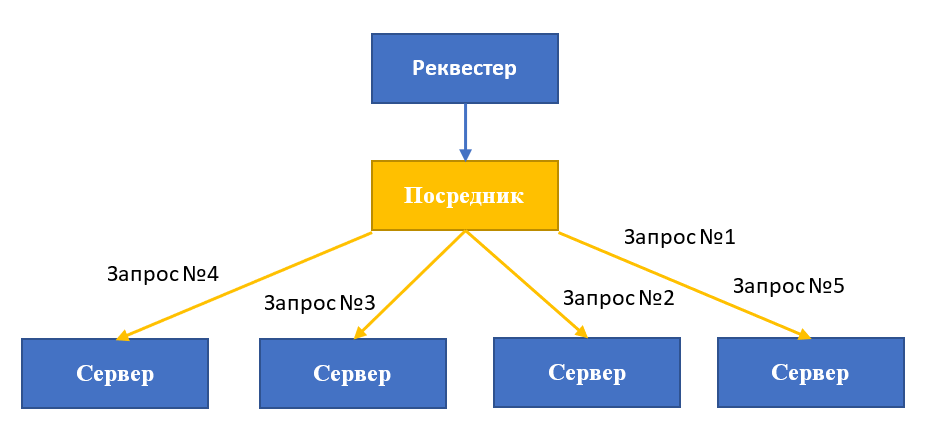
Представим, что у нас развернуты две среды с высокодоступными серверами приложений Tomcat 7 и балансировщиками nginx. DNS-серверы «привязывают» к доменному имени несколько IP-адресов, добавляя внешние адреса балансировщиков в ресурсную запись типа А. Далее DNS-сервер пересылает список IP-адресов доступных серверов, а клиент «пробует» их по порядку и устанавливает соединение с первым ответившим.
Отметим, что такой подход не лишен недостатков. Например, DNS не проверяет серверы на наличие ошибок и не исключает из списка IP-адресов идентификаторы отключённых ВМ. Поэтому, если один из серверов оказывается недоступным, могут возникать задержки в обработке запросов (порядка 10–30 секунд).
Другая проблема — нужно подстраивать время жизни кеша таблицы с адресами. Если значение будет слишком большим, клиенты не узнают об изменениях в группе серверов, а если слишком маленьким — серьезно возрастет нагрузка на DNS-сервер.
Central Manager Algorithm
В этом алгоритме центральный обработчик (CM) определяет хоста для нового процесса, выбирая наименее загруженный сервер. Центральный обработчик делает выбор на основании информации, которую ему присылают серверы каждый раз при изменении количества обрабатываемых задач (например, при создании дочернего процесса или его прекращении).
Подобный подход используется IBM в решении Guardium. Приложение собирает и постоянно обновляет информацию обо всех управляемых модулях и создает на её основе так называемую нагрузочную карту. С её помощью и выполняется управление потоками данных. Балансировщик принимает HTTPS-запросы от S-TAP — инструмента мониторинга трафика — прослушивая порт 8443 и используя Transport Layer Security (TLS).
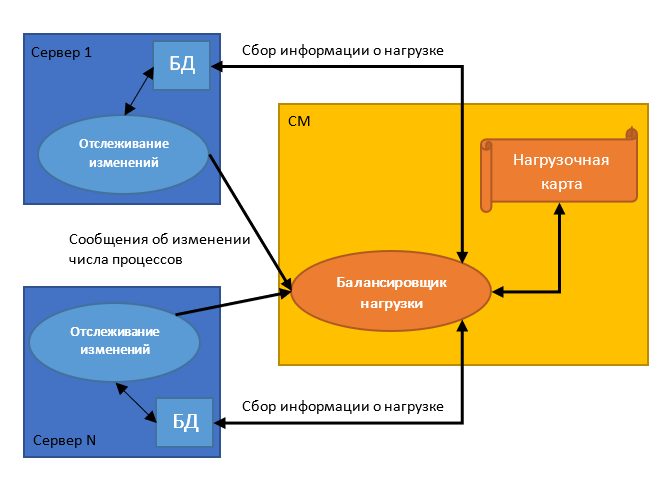
Central Manager Algorithm позволяет ровнее распределять нагрузку, так как решение о назначении процесса серверу выполняется в момент его создания. Однако подход имеет один серьезный недостаток — это большое количество межпроцессных взаимодействий, что приводит к возникновению «бутылочного горлышка». При этом сам центральный обработчик представляет собой единую точку отказа.
Threshold Algorithm
Процессы назначаются хостам сразу при их создании. При этом сервер может находиться в одном из трех состояний, определяемых двумя пороговыми величинами — t_upper и t_under.
- Не загружен: нагрузка < t_under
- Сбалансирован: t_under ≤ нагрузка ≤ t_upper
- Перегружен: нагрузка > t_upper
Если система находится в сбалансированном состоянии, то никакие дополнительные действия не предпринимаются. Если наблюдается дисбаланс, то система предпринимает одно из двух действий: посылает запрос на увеличение нагрузки или, наоборот, её снижение.
В первом случае центральный сервер оценивает, какие задачи, которые еще не начали выполняться другими хостами, можно делегировать узлу. Индийские ученые из университета Гуру Гобинд Сингх Индрапраста в своем исследовании, которое они посвятили оценке эффективности работы threshold-алгоритма в неоднородных системах, приводят пример функции, которую могут использовать узлы для отправки запроса на повышение нагрузки:
UnderLoaded()
{
// validating request made by node
int status = Load_Balancing_Request(Ni);
if (status = = 0 )
{
// checking for non executable jobs from load matrix
int job_status = Load_Matrix_Nxj (No);
if (job_status = =1)
{
// checking suitable node from capability matrix
int node_status=Check_CM();
if (node_status = = 1)
{
// calling load balancer for balancing load
Load_Balancer()
}
} } }
Во втором случае центральный сервер может забрать у узла те задачи, которые тот еще не начал выполнять, и по возможности передать их другому серверу. Для запуска процесса миграции ученые использовали следующую функцию:
OverLoaded()
{
// validating request made by node
int status = Load_Balancing_Request(No);
if (status = = 1)
{
// checking load matrix for non executing jobs
int job_status = Load_Matrix_Nxj (No);
if (job_status = =1)
int node_status=Check_CM();
if (node_status = = 1)
{
// calling load balancer to balance load
Load_Balancer()
}
} } }
Когда выполняется перераспределение нагрузки, серверы посылают сообщение об изменении своего счетчика процессов другим хостам, чтобы те обновили свою информацию о состоянии системы. Достоинством такого подхода является то, что обмен подобными сообщениями происходит редко, так как при достаточном количестве ресурсов сервера он просто запускает новый процесс у себя — это повышает производительность.
Еще материалы из корпоративного блога 1cloud:
- Балансировка нагрузки: трудности прогнозирования
- Безопасность данных в облаке: угрозы и способы защиты
- Чем отличается сеть от подсети: где граница
- Как создать компьютерный класс в облаке
