Жизнь проекта на production: советы по эксплуатации

Немаловажный пункт, который очень часто упускают из вида разработчики — это эксплуатация проекта. Как выбрать дата-центр? Как прогнозировать угрозы? Что может произойти на уровне фронтенда? Как балансировать фронтенд? Как мониторить? Как настраивать логи? Какие нужны метрики?
И ведь это только фронтенд, а есть ещё бекенд и база данных. Везде разные законы и логика. Подробнее об эксплуатации highload-проектов в докладе Николая Сивко (Head Hunter) с конференции HighLoad++ Junior.
Жизнь проекта на production: советы по эксплуатации
Николай Сивко (okmeter.io)
Я хочу рассказать вам про эксплуатацию. Да, конференция «HighLoad» больше про разработку, про то, как справляться с высокими нагрузками и т.д. и т.п.– мне такую вводную организаторы дали, но я хочу поговорить про отказоустойчивость, потому что, на мой взгляд, это тоже важно.
Начинать надо с постановки задачи — определения того, чего мы хотим.

Никакого rocket science«а не будет, никаких особо сверхсекретных рецептов я не дам. Буду основываться на том, что предполагаемая публика — это начинающие эксплуататоры. Поэтому будет просто свод того, как надо планировать отказоустойчивость.
На входе у нас есть сайт, и будем предполагать, что он зарабатывает деньги. Соответственно, если сайт выключен и не доступен для пользователей, то деньги он не зарабатывает, и это проблема. Вот ее мы и будем решать. Насколько много он зарабатывает денег — это вопрос, но мы постараемся сделать все, что можем за не колоссальные деньги, т.е. у нас есть небольшой бюджет, и мы решили потратить сколько-то времени на отказоустойчивость.

Надо себя сразу ограничить в желаниях, т.е. сделать четыре девятки, пять девяток сразу не стоит. Будем опираться на все, что нам предлагают дата-центры — у них разный уровень сертификации, сертифицируется дизайн дата-центра, т.е. насколько там все отказоустойчиво, и мы, наверное, не будем пытаться запрыгнуть дальше чем TIER III, т.е. восемь минут простоя в месяц, 99–98% uptime нам сойдет. Т.е. резервировать дата-центр мы пока не будем.

В реальности, когда дата-центр сертифицирован чуть ниже, чем TIER III (вернее, я не помню, какой порядок), то по факту дата-центры в современном мире работают достаточно хорошо. Т.е. в Москве найти дата-центр, который стабильно работает из года в год, как говориться, без единого разрыва, не составляет труда. Можно погуглить, можно поспрашивать отзывы. В итоге вы куда-то встали и поставили свое железо. А вот все, что ломается внутри дата-центра — это более вероятные поломки, т.е. ломается железо, ломается софт. Тот софт, который писали не вы, ломается чуть реже, потому что есть комьюнити, бывает, есть вендор, который следит за отказоустойчивостью, а вот софт, который писали вы, скорее всего, ломается чаще.

Нужно с чего-то начать. Допустим, есть dedicated сервер за 20 тыс. рублей в месяц, от этого будем плясать. На нем у нас в кучу собрано все: фронтенд, бэкенд, база, какие-то вспомогательные сервисы, memcashed, очередь с асинхронными тасками и обработчики, которые их выгребают и делают. Вот? будем с этим работать, причем, по порядку.

Примерный алгоритм — берем каждую подсистему, примерно прикидываем, как она может сломаться, и думаем, как это можно чинить.
Сразу скажу — починить все нереально. Если бы можно было починить все, там был бы 100% uptime, и все это было бы не нужно. Но давайте попробуем все, что сможем, быстро закрыть.
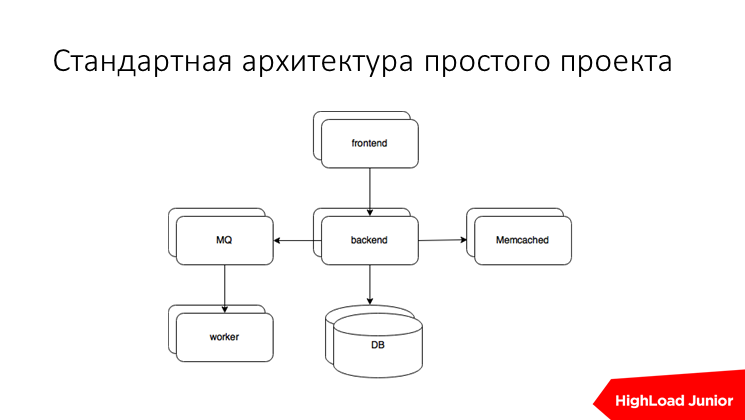
Соответственно, как устроен среднестатистический проект, начиная с 2000-го года? Есть бэкенд, есть фронтенд, memcashed часто, но это не принципиально, очередь сообщений, обработчики и база. Если есть что-то еще, что мы не покрыли, примерно понимая алгоритм, можете сами сделать.

Фронтенд. Для чего он нужен? Он принимает все входящие запросы, занимается тем, что обслуживает медленных клиентов, как-то оптимизируя нагрузку на наш более жирный бэкенд, отдает статику самостоятельно с диска, занимается тем, что обслуживает Transport Layer Security, в данном случае, к сайтам применительно https, проксирует запросы на бэкенды, занимается балансировкой между бэкендами, иногда там есть встроенный кэш.

Что может произойти? Может тупо сломаться железка, на которой у вас Nginx или другой фронтендовый сервер. Может умереть сам Nginx или что-то на этой машине по разным причинам. Может все затупить, например, вы уперлись в ресурсы, уперлись в диск и т.д. И по итогам все тормозит. Давайте начнем это решать.

Фронтенд сам по себе никакого состояния, как правило, не несет. Если это не так, то я советую вам срочно это починить. Если он stateless, т.е. он не хранит данные, клиент не обязан приходить со своими запросами только на него, вы можете поставить таких железок несколько и, собственно, между ними организовать балансинг.
Какие тут сложности? Как правило, все, что происходит выше — это не наша зона ответственности, мы не можем там ничего подкрутить, там уже провайдер, который выдал нам шнурок, который мы воткнули в свой сервер.

Есть способы с этим тоже чего-то сделать. Первый, самый примитивный, что можно сделать, не обладая никакими навыками — это DNS round robin. Просто для своего домена указываете несколько IP, один IP одного фронтенда, другой — другого, и все работает.
Проблема тут в том, что DNS не знает о том, работает сервер, который вы там прописали, или нет. Если вы даже научите DNS знать об этом и не отдавать в ответе битый IP, все равно есть кэш DNS«a, есть криво настроенные кэши у провайдеров разных и т.д. В общем, не стоит закладываться на то, что вы быстро поменяете DNS. Реальность такова, что даже если у вас низкий TTL в DNS прописан, все равно будут клиенты ломиться на неработающий IP.
Есть технологии, которые в общем случае называются Shared IP, когда между несколькими серверами шарится один IP адрес, который вы и прописываете в DNS. Реализация таких протоколов как VRRP, CARP и т.д. Просто погуглите, как это сделать, потом уже будет понятно.
Проблема тут какая? Вам от провайдера нужно добиться, чтобы оба сервера были в одном Ethernet-сегменте, чтобы они могли перекидываться служебными heartbeat«ами и прочее.
И еще — это не обеспечивает вам балансировку нагрузки, т.е. резервный сервер будет у вас постоянно простаивать. Решение простое — мы берем два сервера, берем два IP, один мастер для одного, другой мастер для другого. И они друг друга страхуют. А в DNS прописываем оба, и все хорошо.

Если есть у вас перед этими серверами какой-то свой роутер или другая сетевая железка, которая умеет делать маршрутизацию, вы можете для Cisco такие простенькие хинты прописать, допустим, равнозначные маршруты и как-то сделать так, чтобы эти маршруты убирались с железки, если сервер не работает. Для Juniper это можно сделать с помощью BFDd. Но, в общем, эти слова доступны будут — гуглите и осилите это сделать.
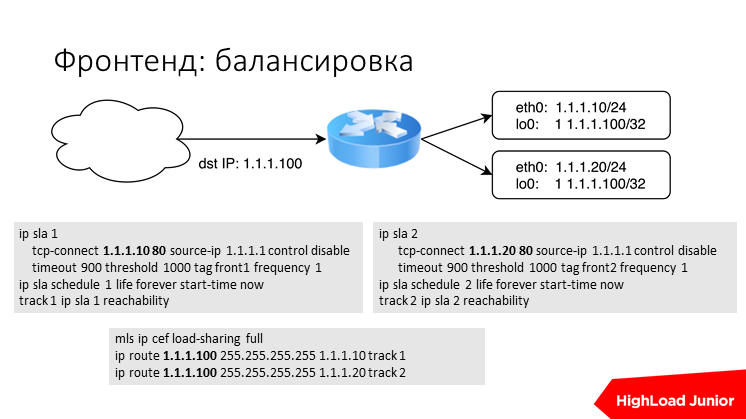
Примерно вот так это работает через Cisco. Это куски конфига. Вы анонсируете один IP-адрес, и у него два маршрута — через один сервер и через другой. На каждом фронтенде на lowback интерфейсе висит целевой IP? и как-то обеспечена логика проверки чеков. Cisco сама умеет проверять статус маршрутизатора, допустим она может проверить CB-коннект на Nginx«овский порт или еще как-то, или просто банально ping. Тут все просто, вряд ли у кого-то в маленьком проекте есть роутер свой.

Все, что мы делаем, нужно покрывать попутно мониторингом потому что, несмотря на то, как оно само себя резервирует, вам нужно понимать, что происходит в вашей системе.
В случае фронтендов очень хорошо работает мониторинг по логам, т.е. ваш мониторинг читает логи, строит гистограммы, вы начинаете видеть, какое количество ошибок вы отдаете своим пользователям и видите, как быстро работает ваш сайт.
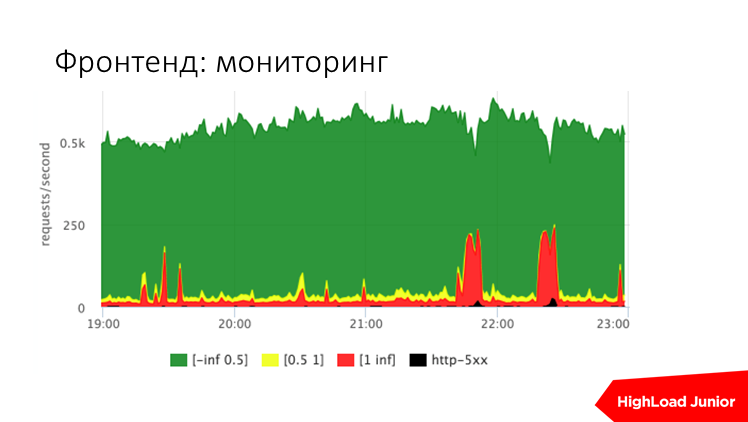
Примерно вот такая картинка очень показательна. Вы видите по оси Y запросы в секунду к вашему сайту. В данном случае около 500 запросов в секунду идет. В нормальной ситуации есть медленные запросы — они помечены красным — это запросы, которые дольше секунды обрабатываются. Зеленые — это те, которые быстрее 500 мс, желтые — это что-то по серединке, и черное — это ошибки. Т.е. сразу вы видите, как работает ваш сайт — так же, как 5 минут назад или нет. Тут два красных выброса — это, как раз, проблемы. Это тормозил сайт, где-то на глаз 30–40% пользовательских запросов были тупящими.

Итого, по этим метрикам можно настроить алерты, которые будут однозначно говорить, как работает ваш сайт — хорошо или плохо. Для примера вот такие пороги. Т.е. если для сайта с 200 запросами в секунду ошибок больше 10 запросов в секунду, то это критикал алерт. Если процент медленных запросов, которые больше секунды, больше пяти, допустим, то это тоже критикал алерт.
Так, мы покрыли весь сайт мониторингом. Ну, не весь сайт, а, в принципе, состояние сайта и, в общем, можем идти дальше.

Итого, на данном слое мы как-то закрыли две проблемы путем резервирования фронтендов, мы по пути проверяем, живы ли фронтенд и сервис на нем. Две проблемы мы закрыли, третью проблему мы решать не будем, потому что это сложно, потому что нужно опираться на метрики в принятии решений. Мы ее просто мониторим, и если у нас случается какая-то проблема, мы приходим и руками разбираемся. Это уже в 10 раз лучше, чем ничего.

Идем дальше. Бэкенд. Для чего нужен бэкенд? Он собирает, получает данные, как правило, из каких-то хранилищ, из базы данных, как-то их преобразует и отдает ответ пользователю. Соответственно, есть какая-то часть запросов, когда мы кого-то ждем. Есть часть, когда мы что-то вычисляем, допустим, рендерим шаблон и просто отдаем ответ пользователю.

Выписываем риски: сломалась железка, умер сам сервер аплекейшн, есть проблемы с сервисами, из которых бэкенд берет данные, т.е. тупит база данных, тупит еще чего-то, тупим из-за того, что нам самим не хватает ресурсов, тупим от того, что нам пришло больше запросов, чем мы физически можем обслужить. Я это выписал, но, может быть, не все, я даю вам примерный алгоритм.

Начинаем думать и закрывать.
Бэкенд тоже лучше делать stateless и хранить пользовательские сессии на диске и т.д. Тем самым вы упрощаете задачу балансировки, т.е. вы можете не париться, куда отправить следующий запрос пользователя. Можем поставить несколько железок и сделать балансировку на фронтенде.

Чтобы оградить себя от большого количества запросов на каждый бэкенд, нужно понять, каков предел производительности бэкенда и настроить лимиты в нем самом. Допустим, в apache есть предел, который вы можете настроить, т.е., например, «Я беру только 200 параллельных запросов, больше не беру. Если больше пришло, я отдаю »503» — это внятный статус, что я сейчас больше не могу запрос обслужить». Тем самым мы показываем балансировщику или в нашем случае фронтенду, что запрос можно отправить на другой сервер. Тем самым вы не страдаете перегрузом — если ваша система целиком перегружена, вы отдаете пользователю »503» — внятную ошибку типа «Чувак, не могу». Это вместо того, чтобы все запросы затупили и повисли в ожидании, а клиенты вообще не понимали, что происходит.
Также момент, который все забывают. В проектах, которые развиваются стремительно, забывают проверять таймауты на все, т.е. ставить таймауты. Если вход вашего бэкенда идет куда-то наружу, допустим в memcashed базу, нужно ограничивать, сколько вы будете ждать ответа. Нельзя ждать вечно. Вы, ожидая, допустим, ответа postgress, занимаете коннекшн с ним, занимаете какие-то ресурсы, и нужно вовремя отвалиться, сказать: «Все, я больше ждать не могу» и отдать ошибку наверх. Тем самым вы исключаете ситуации, когда у вас все тупит, в логах ничего нет, потому что все операции in progress, и вы не понимаете, что происходит. Нужно ограничивать таймауты и очень трепетно к ним относиться, тогда вы получите более управляемую систему.

Балансировка. В данном случае просто. Если у вас на фронтенде стоит Nginx, то просто прописываете несколько upstream«ов. Опять же про таймауты — для локалки коннекшн таймаут должен быть не секунды, а десятки миллисекунд, а то и меньше, надо смотреть на свою ситуацию. Говорите, в каких случаях запросы повторять на соседний сервер. Ограничиваете количество ретраев, чтобы не вызвать шторм. Большой вопрос — ретраить ли запросы на модификацию данных, посты и т.д. Вот, с Nginx свежих версий, они не ретраят по умолчанию такие запросы как POST, т.е. не идемпотентные запросы. И это, в принципе, хорошо, эту ручку все долго ждали и, наконец, она появилась. Там можно настроить другое поведение, если вы хотите ретраить посты.

Про бэкенд — тоже пытаемся заодно покрыть его мониторингом. Мы хотим понимать, жив ли процесс, открыт ли listen socket TCP«шный, который мы ждем, что сервис обслуживает, отвечает ли он на какую-то специальную ручку, проверяющую его статус, сколько сервис потребляет ресурсов, сколько он использует CPU, сколько он зааллоцировал памяти, насколько он сидит в swap, количество файлов-дескрипторов, которые он открыл, количество операций ввода/вывода на диск, в штуках, в трафике и т.д., чтобы понимать, больше он потребляет или как обычно. Это очень важно понимать, причем это важно понимать во времени, чтобы сравнивать с предыдущими периодами.
Специфичные runtime метрики для Java — это состояние heap, использование мемори пулов, garbage collection, сколько там их в штуках было, сколько их было в занимаемых секундах, в секунду и т.д.
Для Python там свои, для GO«шки — свои, для всего, что связано с runtime, там свои отдельные метрики.

Вам нужно понимать, чем был занят бэкенд, сколько он запросов принял. Это можно отстреливать в лог, это можно отстреливать в statsd, тайминги по каждому запросу, нужно понимать, сколько времени тратилось на тот или иной запрос, сколько было ошибок. Часть этих метрик, в принципе, видит фронтенд, потому что он для бэкенда выступает клиентом, и он видит, была ли ошибка, или был нормальный ответ. Он видит, сколько он ждал ответа. Обязательно мы должны мерить и логировать, сколько бэкенд ждал всех сервисов, которые от него снаружи стоят, т.е. это база, memcashed, nosql, если он работает с очередью, сколько заняло поставить задачу в очередь. И время, которое заняли какие-то ощутимые куски CPU, допустим, рендеринг шаблона. Т.е. мы в лог пишем: «Я рендерю такой шаблон, у меня это заняло 3 мс», все. Т.е. мы видим и можем сравнивать эти метрики.
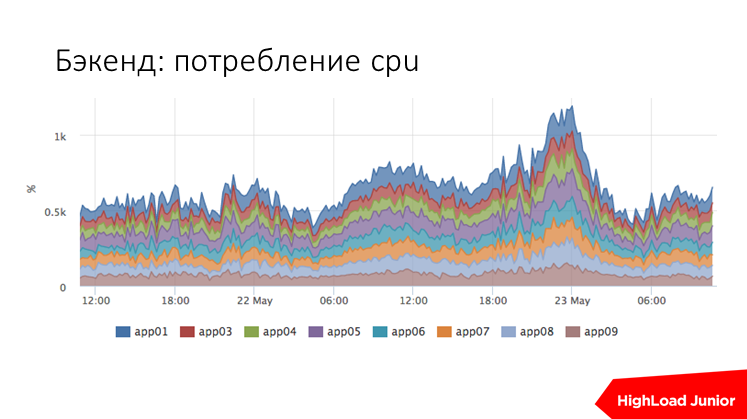
Тут пример того, как мы меряем CPU usage ruby в одном из проектов. Это сводный график по всем хостам, их тут девять бэкендов. Сразу видно, есть у нас тут какое-то аномальное потребление ресурсов или нет.
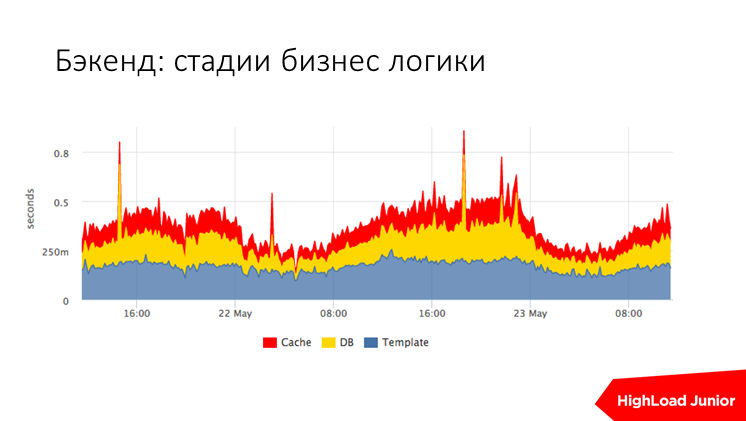
Или, допустим, стадии обработки запросов. Тут треть времени занимает шаблонизация, мы ее замерили. И остальные примерно по трети, это ожидание базы и ожидание кэша. Сразу видно, если у нас есть выброс, допустим. Вот там есть выброс в серединке, когда у нас притупил кэш, в другом всплеске у нас притупила база, допустим, она желтая, т.е. сразу понятно, кто виноват, и не надо ничего долго искать.

Итого, мы закрыли кейс с поломкой железа, мы закрыли кейс с тем, что умер сервис, потому что балансер перестает балансировать на этот хост, и нет проблем. Мы замониторили кейс, когда тупит база и другие ресурсы, потому что мы померили, и померили также количество ошибок. Мы померили потребление ресурсов и понимаем, что, допустим, если у нас тормозит рендеринг, мы смотрим, насколько больше стала есть CPU процесс, там, ruby или еще что-то. Мы это тоже мониторим. В принципе, у нас все под контролем. Из-за большего количества запросов мы закрылись ограничениями, лимитами, поэтому тут, в принципе, тоже все неплохо.

По базе данных. Какая у нее задача? Она хранит ваши данные, т.е., как правило, центральная точка хранения данных — это база. Может быть, nosql, но мы пока не берем это во внимание. Она отвечает на realtime-запросы от пользователя, т.е. от бэкенда на те страницы, которые пользователь ждет, и она занимается какой-то аналитической обработкой запросов, т.е. где-то там у вас ночью срабатывает крон, высчитывает, сколько вы там чего напроцессили и т.д.

Что может произойти с базой? Как всегда — сломалась железка, без этого никуда, железки ломаются. Кстати, статистика говорит о том, что рассчитывать, что ваша железка будет работать вечно, несмотря на все резервы и прочее, нельзя, надо всегда допускать этот риск, и это будет правильно и умно.
Потеря данных из-за железок, когда у нас данные были в единственной копии, и железка сдохла, мы все потеряли… Или же железка жива и пришел какой-нибудь delete, или еще как-то покрэшились данные — это совершенно отдельный риск.
Умер сервис, ну, postgress прибило oom killer«ом или mysql — тоже нам нужно как-то понимать, что такое происходит.
Тормоза из-за нехватки ресурсов, когда вы запросов базе прислали столько, что она в принципе по CPU не справляется или по диску и т.д.
Из-за того, что вы прислали в 10 раз больше запросов, чем расчетные, допустим, прислал там трафик какой-то и т.д.
Тормоза из-за кривых запросов — если вы не используете индексы, или ваши данные лежат как-то неправильно, вы тоже получаете тормоза.

Попробуем с этим чего-то сделать.
Репликация. Репликация нужна всегда. Практически нет случаев, когда можно обойтись без репликации. Мы ее просто берем и настраиваем на другой сервер в режиме мастер-слэйв и больше ничего пока не надо придумывать.
Основная нагрузка большинства проектов — чтение. В принципе, если вы обеспечите read only постоянную, стабильную работу вашего сайта, то ваше начальство или вы будете безмерно рады. Это уже в 100500 раз лучше, чем ничего, чем падать.

Можно в реплику сразу сгружать все SELECT«ы, не чувствительные к replication lag. Что это такое? Данные на реплику попадают не сразу, а с определенной задержкой в зависимости от разных причин, начиная от пропускной способности каналов, заканчивая тем, насколько реплика там поблочилась. Запросы, которые запрашивают анонимные пользователи, состояние, допустим, каталог — они не чувствительны к replication lag. Если данные задержаться и попадут пользователю неактуальные, ничего плохого не произойдет. А если пользователь заполняет свой профиль и жмет submit на форму, а вы ему показываете данные, которые еще не изменились, допустим, взяли их с реплики, то это уже проблема. В таком случае SELECT надо делать с мастера. Но большинство нагрузки все равно идет на реплику. И приложения нужно обучать тому, что есть реплика, что она отстает, при этом, вы помимо отказоустойчивости решаете задачу масштабирования по нагрузке на операцию чтения.
Для доступа к реплике вы можете поставить реплик много, и это проще простого. Вы можете либо разбалансить входящие запросы к этим репликам, либо научить приложение знать, что реплик у нее 10 штук. Это достаточно сложно и, как я понимаю, стандартные средства и всякие фреймворки не умеют так делать, нужно чуть-чуть программировать. Но вы получаете возможность балансировать, делать ретраи, т.е. если вы делаете пользовательский запрос и, допустим, реплики у вас стоят за балансером, вы получили ошибку или таймаут, вы не можете сделать попытку, потому что есть вероятность, что вы попадете на тот же дохлый сервер. Соответственно, вы можете научить бэкенд знать про 10 реплик и в случае, если одна из реплик лежит, попытаться на другой и, если она живая, пользователю отдать его ответ без ошибки, и это классно. Это вычищение таких мелких-мелких проблем, т.е. тоже работа на uptime.
Надо понимать, что делать, если мастер сдох, а у вас есть реплика. Во-первых, нужно принять решение о том, что вы будете переключаться.

Допустим, у вас сервер сдох, у него там паника, он дохнет у вас раз в три года. Тогда вам просто целесообразнее заребутить его, дождаться, пока он поднимется, и не затевать всю эту фигню с переключением, потому что она не бесплатная, она требует и времени, и она достаточно рискованная.
Если вы все-таки решились переключаться, то мы свои бэкенды перенастраиваем на реплику, т.е. на одну из реплик мы отправляем всю запись. Если это нормальная база данных (postgress), то в режиме реплики она будет возвращать ошибки на все модифицирующие запросы, на инсерты, апдейты и т.д. И это не беда. Потом вы, если нужно, дожидаетесь, пока с мастера на реплику все долетит до конца. Если он живой. Если он как бы неживой, то ждать уже ничего не приходится.
Вы добиваете обязательно мастер, если он живой. Т.е. его лучше добить, чтобы не произошло такого казуса, что кто-то пишет в отключенный, старый мастер и тем самым не потерять данные. Таким образом апгрейдим слэйв до мастера. Это в разных решениях систем управления с базами данных делается по-разному, но есть отлаженная процедура.
Если еще есть реплики, их нужно переключить на новый мастер и, если вы старый сервер хотите куда-то пристроить, потом включите его в виде реплики.

Итого, мы примерно рассмотрели, что происходит и, на мой взгляд, то, что мы проговорили, это достаточно стремная операция, и делать на автомате ее не хочется, ну, лично мне. Я бы не рискнул. Лучше, все-таки минимизировать вероятность того, что вам придется переключиться и купить либо арендовать железо получше, либо еще чего-то сделать. Т.е. мы тупо снижаем вероятность того, что мастер сдох.
Обязательно пишем инструкцию, как переключить мастер по шагам. Это должен будет делать полусонный человек в четыре часа утра, который находится в стрессовой ситуации, у него лежит бизнес, связанный с сайтом, и он должен не особо париться над тем, чтобы думать, что он делает. Он должен, конечно, думать, мы все-таки не совсем валенков на работу нанимаем, но включать мозг по минимуму. Потому что это стрессовая ситуация.
Обязательно эту инструкцию тестировать. Непротестированная инструкция — это не инструкция. Так, мы тестируем инструкцию, устраиваем учения, т.е. мы написали инструкцию, вырубаем мастер, и тренируемся, делаем все строго по инструкции и ничего по ходу не придумываем. Если у вас чего-то не получается, сразу в инструкцию дописываем.
Попутно, мы замеряем время. Время нам нужно замерять, чтобы гарантировать, что с подобной проблемой мы справляемся за 30 или за 15 минут, или суммарный downtime получается полторы минуты, после того, как человек пришел, открыл ноутбук, за-ssh«шился и погнали.
В следующий раз, если вы инструкцию меняли, нужно провести повторные учения. Если вас не устраивает время, которое получилось в итоге downtime, вы можете попытаться с этим что-то сделать, какие-то шаги оптимизировать, где-то там параллельное копирование файлов обеспечить или еще чего-то. Просто, когда вы посмотрите по шагам, померяете, сколько каждый шаг занимает, и замутите какую-то оптимизацию.

Отдельно стоит отметить такую капитанскую штуку, что репликация — это не бэкап. Если вам пришел запрос, который убивает данные, он на реплику попадет тоже, и вы потеряете все. Если вам нужно данные сохранять вообще, то надо делать бэкап.
Бэкапы, опять же, у разных баз данных делаются по-разному. Есть полные бэкапы, которые делаются, как правило, не каждую секунду, есть возможность бэкап, который ежедневный dump или ежедневную копию датафайлов догнать с помощью write ahead log или bin log или еще чего-то… Эти bin log«и нужно копировать в сторонку аккуратненько.
И, опять же, восстановление нужно тестировать все время, потому что бэкап, который вы не разу не разворачивали и не ресторили из него базы — это не бэкап, а просто какая-то штука, которая может с определенной вероятностью вас спасти, но не факт.
Бэкап лучше копировать в другой ДЦ, потому что, если вы собираетесь из него восстанавливаться, а он только в удаленном ДЦ, который на самом деле находится через Атлантику от вашего — это долгое копирование. Лучше держать и там, и там. Т.е. в случае, если ваш ДЦ жив, и вы хотите восстановиться, вы становитесь копией, которая уже при вас. Если ваш ДЦ помер, вы будете восстанавливаться у другого хостера, который где-то, и там уже придется ждать, что поделать?

Про базу — тоже лучше мониторить, чтобы понимать, что происходит, нужно понимать, насколько она, вообще, жива/не жива по меркам операционной системы, жив ли процесс, открыт listen socket, сколько этот процесс потребляет каких ресурсов.
Дальше вам нужно уметь понимать, чем занята база прямо сейчас и чем она была занята 5 минут назад. Лучше всего это смотреть в терминах запросов. Где-то это реально снять, где-то нереально, допустим в postrgess можно понимать, какие запросы жрут CPU, какие запросы создают нагрузку на диск. Если вы все-таки настроили репликацию, вам нужно понимать, насколько она отстает, потому что от этого может зависеть, если она у вас в среднем в году отстает на 500 мс, то, может быть, стоит считать, что репликейшин лага нет? Но если вам очень хочется для какого-нибудь специфического случая, если реплика сильно отстала, а репликация разломалась, вы должны обязательно знать об этом и починить. Надо понимать, сколько идет запросов, больше или меньше на базу, чтобы сравнивать два периода, потому что если вы выпустили кривой код, который делает в два раза больше запросов, они отжирают в два раза больше CPU, то вы сразу это увидите и будете чинить.
Вообще джедайская техника — мониторинг бэкапов. Как правило, совсем хорошо сделать — проверить, что бэкапы целостные в мониторинге — это следить, но я мало видел таких штук. Но хотя бы понять, что у вас за бэкап лежит сегодня на диске в обоих дата-центрах, и его размер больше чем 1 Гб — это уже достаточно. Надо понимать, мерить только сегодняшний файл, т.е. мерить размер прошлогоднего файла не надо. И тогда, в случае если что-то разваливается по любым причинам, вы хотя бы увидите лампочку.
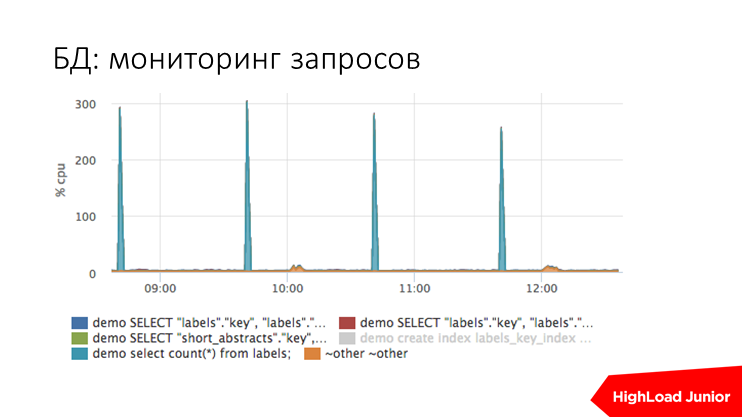
Мониторинг запросов по postgress выглядит примерно так. Тут есть спайки — это какой-то аномальный запрос. Вы на него смотрите, принимаете решение, что с ним делать, как оптимизировать, как заменять и т.д.
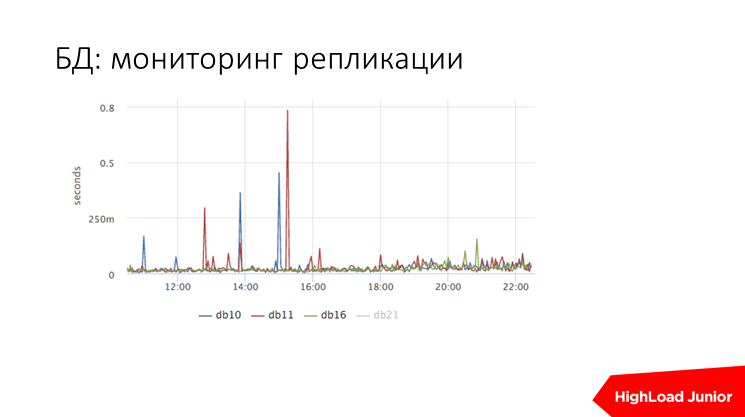
Мониторинг репликации выглядит примерно так. Т.е. есть четыре сервера, один там сейчас задизейблен, отстают они по-разному, бывают какие-то выбросы, что репликация отстает на 800 мс, но в среднем они на 50 мс отстают.

Итожим по базам.
Потеря данных из-за железа и delete«ы — мы закрыли это репликацией, мы закрыли это бэкапом, мы закрыли частично мониторингом и инструкцией с проведенными поверх учениями. Уже рисков меньше, если б мы всего этого не сделали.
Умер сервис, кэш, все такое — мы умеем переключаться, мы умеем ходить на реплики, и жить в read only режиме.
Тормоза из-за нехватки ресурсов — закрыто мониторингом. Тормоза из-за большего количества запросов тоже мы закрыли мониторингом. Потому что на автомате на самом деле непонятно, что с ним делать. Тормоза из-за кривых запросов мы закрыли мониторингом.
Если мы говорим, что нам приходят в релизе новые запросы, то мы это детектим за 3 минуты, чиним еще откатом, это занимает 5 минут, итого мы обещаем за 8 минут закрыть эти проблемы. Вообще, любой бизнес это устроит. Это, типа, «я умею побеждать эту проблему в течение 15 минут» — это хороший аргумент для того, чтобы доказать вашему руководству, что вы ситуацию контролируете.

Рассмотрим memcached, хотя это не особо хипстерская технология, она давнишняя, но все равно часто есть. На примере memcached я расскажу, как быть со вспомогательными сервисами.
Это распределенный кэш в памяти, и общий доступ к этому кэшу по сети. Т.е. к бэкенду цепляется список серверов, бэкенд к ним ходит и забирает оттуда данные, предполагая, что из кэша он данные достает в 10 раз быстрее, чем из базы.

Может, как всегда, сломаться железка, может умереть сервис, может тормозить сеть от бэкенда до memcached, или где-то там что-то затупить из-за нехватки ресурсов. Быстренько попробуем закрыть.

Мemcached всегда ставят несколько, клиент умеет знать про все, он умеет ходить во все. Там есть какой-то алгоритм шардирования, разные они есть. Если умирает один, происходит что-то, клиент переживает эту ситуацию, он, допустим, идет в новую базу и по новой группе серверов раскладывает, сетит в кэш новые значения. Обязательно нужно настраивать таймаут, потому что ситуация, когда тупит memcached редка, а ситуация, когда тупит сеть, более вероятна.
И проверяем логику инвалидации, потому что может быть ситуация, что у вас один сервак выпал, но он не умер, а, допустим, сеть для него стала недоступна, ваш код, который, вроде бы, должен пойти и заинвалидировать данные, пошел в другой сервак это делать, потому что уже изменилось шардирование, а потом этот сервак вернулся, и там лежит протухшее значение. Но тоже нужно проверить, насколько ваш алгоритм шардирования не доставит вам таких проблем. И лучше, все равно, если вы даже хотите сделать долгоживущий объект в кэше, все равно ставить expire, пусть большой, но все равно ставить, чтобы когда-нибудь само восстановилось.

Еще вопросы, которые нужно задавать про кэш, которые забывают все. А что будет, если наши кэши будут холодными, что будет, если все memcached перезапустить сейчас, выдержит ли база? Вообще, строго говоря, она должна выдерживать, если она не выдерживает, то все, вы попадаете на то, что всегда должны иметь n прогретых кэшей, и это отдельный гемор. Если ваша база в режиме полностью холодного кэша выдерживает, то зачем тогда вам, вообще, memcached? Потому что, допустим, сегодня она выдерживает, а завтра у вас рост нагрузки пятикратный, и база такую ситуацию уже не выдерживает. Проще убрать кэш и оптимизировать, а не заметать проблемы под ковер. Т.е. подумайте, может быть, простое решение — это, вообще, выкинуть эту подсистему?
И всегда надо понимать, эффективен ли кэш. Т.е. вы все-таки делаете, как правило, лишний поход по сети,
