Жарим TOAST в PostgreSQL
У нас не подгорит!

В этой статье мы разберем, как PostgreSQL хранит большие (длинные) значения колонок, рассмотрим некоторые связанные с этим особенности и проблемы СУБД и предложим способы решения этих проблем. Посчитаем байтики и залезем в потроха СУБД. Будет интересно!
1. Что такое TOAST и зачем он нужен?
В СУБД может храниться различная информация, и эта информация может состоять как из атомарных типов данных (символьного, чисел, дат), так и из более сложных (текст, бинарные последовательности, jsonb объекты и тому подобные). Хранение сложных типов данных, особенно тех, значения которых могут быть очень большого размера — непростая задача, и в разных СУБД эта задача решена различными способами. В PostgreSQL физический размер одной записи таблицы не может превышать размер страницы (по умолчанию — 8 кб), поэтому для хранения колонок большой длины используется механизм «TOAST» (аббревиатура от «The Oversized Attribute Storage Technique»).
TOAST представляет собой специальные таблицы («тост-таблицы»), невидимые для пользователя, в которые большие значения помещаются нарезанными на кусочки — «тосты». При этом оригинальное значение в исходной таблице подменяется на ссылку специального вида — TOAST Pointer (TOAST-указатель), содержащую служебную информацию — ID тост-таблицы, ID записи в тост-таблице, длины исходного и фактически хранимого значения (это необходимо для тех случаев, когда используется компрессия, и значение перед нарезкой сжимается) — пример приведен на рисунке ниже:
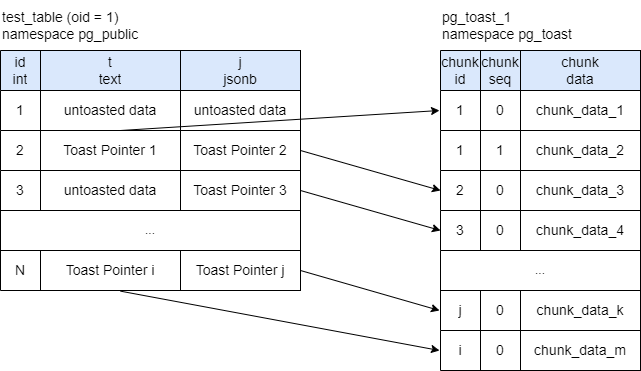
Весь этот механизм скрыт от пользователя, что имеет свои как положительные, так и отрицательные стороны.
2. Проклятие TOAST
Основным достоинством TOAST является то, что этот механизм очень надежный, и он просто работает, не требуя никакого вмешательства и каких-то специальных действий пользователя. Этот механизм существует давно и хорошо отлажен.
Однако, в силу того что механизм разработан довольно давно, в совершенно других реалиях, у него есть серьезные недостатки, затрудняющие эксплуатацию базы данных в сегодняшних условиях огромных объемов данных и постоянной высокой нагрузки на СУБД.
Механизм TOAST на сегодняшний день имеет следующие ограничения:
1) 2^32 уникальных ID значений. То есть, больше чем 2^32 значений просто не может попасть в тост-таблицу.
2) Механизм TOAST сам по себе не имеет операции UPDATE — при выполнении команды UPDATE старая запись, содержащаяся в тост-таблице, помечается как dead, и добавляется новая. Место в таблице и OID освободятся только если эта тост-таблица будет обработана вакуумом (OID записи является частью первичного ключа тост-таблицы и освобождается только при освобождении занимаемого записью пространства), что является причиной быстрого распухания (bloating) тост-таблиц при активной работе с основной таблицей.
3) Из 1) и 2) следует, что после вставки 2^32 значений вы не можете сделать INSERT или UPDATE в основной таблице, если хотя бы одна колонка попадет в тост.
4) Тост-таблица для каждой таблицы БД всего одна, вне зависимости от того, сколько колонок базовой таблицы в нее попадает. Таким образом, мы еще больше ограничены в количестве добавляемых и обновляемых записей основной таблицы, причем неявным для пользователя образом — это не описано нигде в документации, а достижение максимального значения счетчика приводит к необъяснимому, с точки зрения пользователя, поведению СУБД.
5) Тост-таблица имеет точно такое же ограничение в 32 Тб на размер, как и все остальные таблицы. Вместе с предыдущим ограничением это накладывает еще большее неявное ограничение на основную таблицу.
6) TOAST работает для всех колонок и типов данных одинаково, так как в силу требований универсальности механизма он не может использовать никакую информацию о структуре данных, попадающих в тост-таблицы.
7) Невозможность принудительного помещения данных в TOAST-таблицу, вне зависимости от длины значения.
8) TOAST является частью ядра PostgreSQL, что серьезно затрудняет его модификацию и делает его абсолютно не расширяемым.
Как уже было сказано выше, эти ограничения весьма серьезны — и мало того, что усложняют жизнь как пользователям, так и администраторам — приводят к непредсказуемому поведению СУБД. Вопросы производительности, связанные с TOAST, широко освещены в статьях Understanding JSON Performance, JSON на стероидах и Speed Up The JSONB. В общем, можно сказать, что этот тост, хотя и был для своего времени весьма хорош, но он уже изрядно подгорел, и пора готовить новый.
3. TOAST изнутри
Механизм TOAST является частью метода доступа к таблицам Heap Access Method (далее — Heap AM). Методы доступа в PostgreSQL (Table Access Methods) — это набор функций доступа к данным, вызываемый при выполнении команд SQL, задача которого — скрыть от Executor«а собственно способ хранения данных, предоставив общий для всех методов доступа интерфейс (Pluggable Storage API). Heap AM — единственный метод доступа к таблицам в ванильном PostgreSQL, используемый по умолчанию, и TOAST, как часть этого метода доступа, совершенно невидим для пользователя. Более того, пользователи могут даже не знать, что на самом деле их данные хранятся не в той таблице, с которой они работают, а в специальных системных сущностях. С одной стороны это хорошо, так как позволяет избежать излишних усложнений взаимодействия, а с другой — может приводить к совершенно неожиданному для пользователя поведению базы данных:
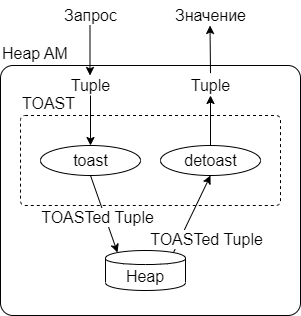
Заглянем внутрь штатного TOAST, и попробуем найти, как же его можно улучшить. На рисунке показано преобразование кортежа из обычного вида (несжатые значения, хранящиеся непосредственно в строке таблицы) в TOAST-указатели и значения, хранящиеся во внешней таблице (TOAST-таблице):
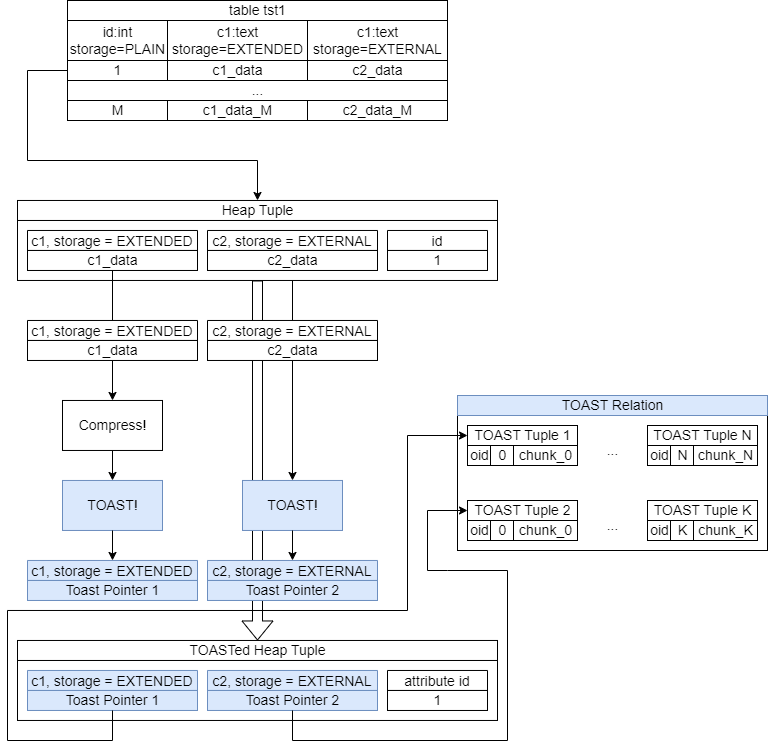
Преобразование кортежа выглядит следующим образом:
Если размер кортежа превышает допустимый для прямого хранения предел (обычно составляет около 2 кб, из расчета 4 кортежей на страницу, по умолчанию страница имеет размер 8 кб), то алгоритм проходит по атрибутам кортежа до тех пор, пока кортеж не будет удовлетворять этому условию. Для каждого атрибута проверяются 4 условия, и на каждом этапе также проверяется, превышает ли размер кортежа допустимый предел:
1) Атрибуты с типом хранения (STORAGE mode) EXTENDED сжимаются. Если размер сжатого атрибута превышает допустимый (2 кб), этот атрибут отправляется в тост-таблицу;
2) Атрибуты с типом хранения EXTERNAL отправляются в тост-таблицу несжатыми (отметим этот момент!);
3) Настает очередь атрибутов с типом хранения MAIN — на этом этапе Postgres пытается использовать для них компрессию;
4) И, наконец, если это не помогает, то атрибуты с типом хранения MAIN также отправляются в тост-таблицу. Однако, Postgres старается избегать этого, и в первую очередь обрабатывает атрибуты EXTENDED и EXTERNAL.
При этом в тост-таблицу могут попасть только атрибуты тех типов данных, которые являются TOASTable — это поля переменной длины, такие как text, json/jsonb, bytea и т.п…
Из этих 4 условий видно, что наибольшее преимущество мы получим, если сможем модифицировать механизм для более эффективной обработки данных со STORAGE mode = EXTERNAL, так как EXTENDED попадает в механизм TOAST уже сжатым, и у нас нет возможности использовать какие-то знания о структуре нарезаемых данных или способах работы с ними. Так как, к примеру, типы bytea и jsonb разные, и сценарии использования для них также значительно различаются — было бы здорово сделать эту часть расширяемой, и реализовать возможность подключения более эффективных алгоритмов хранения для различных атрибутов. Вот — идея подключаемого (Pluggable) TOAST!
Что же, для этого нам придется копнуть еще глубже и посмотреть, как устроен TOAST-указатель.
TOAST нарезает длинное значение на куски — чанки — и помещает эти чанки в отдельную таблицу, при этом оригинальное значение подменяется на специального вида ссылку, содержащую служебную информацию:
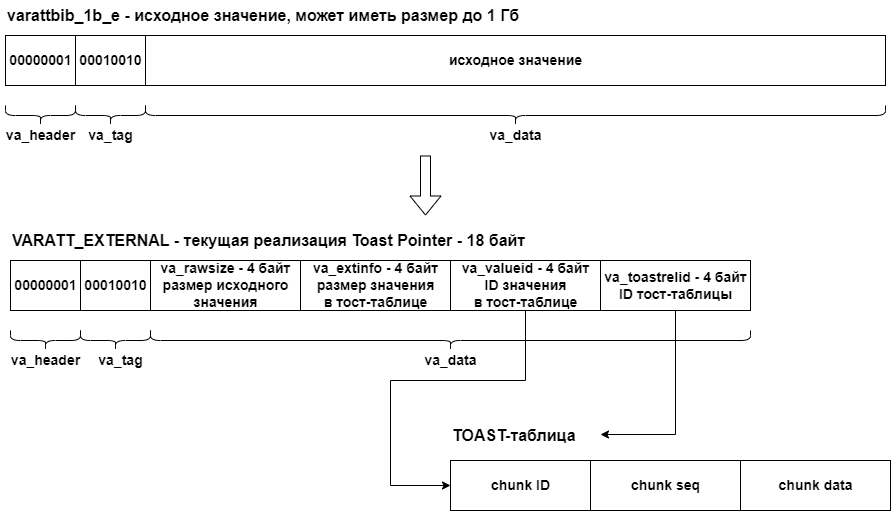
Как мы видим, эта структура содержит только поля фиксированной длины и не предполагает никакого способа хранения информации об алгоритме, использованном для преобразования значения, и другой служебной информации. И так мы подошли к тому, что для расширения возможностей TOAST необходимо модифицировать структуру тост-указателя.
4. А что, если…
…Добавить в эту структуру дополнительные данные — ID алгоритма, используемого для обработки данных, и поле изменяемой длины для хранения произвольной служебной информации, необходимой алгоритму для работы. Таким образом, мы получаем новый вид TOAST-указателя — custom TOAST pointer:

В нашем модифицированном указателе осталось 3 фиксированных поля — это ID алгоритма, при помощи которого были обработаны данные — для поиска его в системном каталоге, длина оригинального значения — для Executor-a, и длина последней, изменяемой части. Четвертое поле — переменной длины — предназначено для хранения служебной информации, необходимой конкретному алгоритму для восстановления оригинального значения (или даже части данных, к примеру, специального заголовка, как для геометрических данных, используемых в PostGIS), и может быть индивидуальным для каждого алгоритма, типа данных или сценария работы. Этот подход уже был предложен нами в статьях New TOAST in Town. One TOAST Fits All и One TOAST Fits All.
На рисунке появляются две новые сущности: PG_TOASTER и TOAST Storage. PG_TOASTER — новая таблица каталога, в которой хранятся ID, присвоенные TOAST-алгоритмам (назовем их для краткости «тостерами» — Toaster), их (алгоритмов) имена, под которыми они будут доступны через SQL, и функции-хендлеры, необходимые для вызова. С TOAST Storage все несколько сложнее. Если мы абстрагируем алгоритм сохранения длинных значений — мы уже не привязаны к какому-то конкретному формату тост-таблицы, да и вообще к хранению этих значений в таблице. Это могут быть цепочка тост-таблиц, таблицы другого формата, внешние файлы, или вообще внешнее хранилище данных.
Чтобы сделать этот механизм подключаемым, мы посмотрели на Table Access Methods API — интерфейс для подключения методов доступа к таблицам. Да, по факту в ванильной версии Postgres используется только один метод — Heap, но Pluggable Storage API существует уже довольно давно, Heap AM его реализует, и это решение вполне можно взять за основу. Так что наш API представляет собой виртуальный интерфейс, который необходимо реализовать разработчику нового TOAST-алгоритма в своем расширении, дополнение к SQL синтаксису, позволяющее подключать эти алгоритмы через SQL, и рефакторинг самого штатного механизма TOAST.
TOAST API, по сути, является таблицей функций, которые должна реализовывать любая реализация TOAST, и за счет унифицированной таблицы можно вызывать эти функции, не зная ничего о самой реализации. Непосредственно API представляет собой базовый фиксированный набор функций и возможность расширения этого набора при помощи виртуальной таблицы функций, на которую нет никаких ограничений. Модификация синтаксиса SQL позволяет подключать пользовательские алгоритмы TOAST через SQL без модификаций кода сервера — что очень важно для сохранения совместимости с ванильной версией PostgreSQL и совместимыми с ней форками. При разработке новых алгоритмов TOAST необходимо просто написать свою реализацию обязательных методов TOAST API, оформить эту реализацию как расширение (contrib), подключить расширение при помощи CREATE EXTENSION, зарегистрировать тостер в системном каталоге командой CREATE TOASTER «имя тостера», и назначить этот тостер на колонку таблицы при помощи опции SET TOASTER команды ALTER TABLE (аналогично SET STORAGE). Синтаксис и возможности интерфейса довольно подробно описаны в части Pluggable TOAST доклада New TOAST in Town.
Базовый набор методов тостера состоит из методов toast (), detoast (), вызываемых при сохранении и извлечении TOASTed-записи, в список необходимых входит метод init (), инициализирующий хранилище данных, используемое алгоритмом. И теперь обращение к механизму TOAST выглядит следующим образом:

А преобразование кортежа происходит не в Heap AM, а через вызов реализации TOAST, назначенной на столбец:
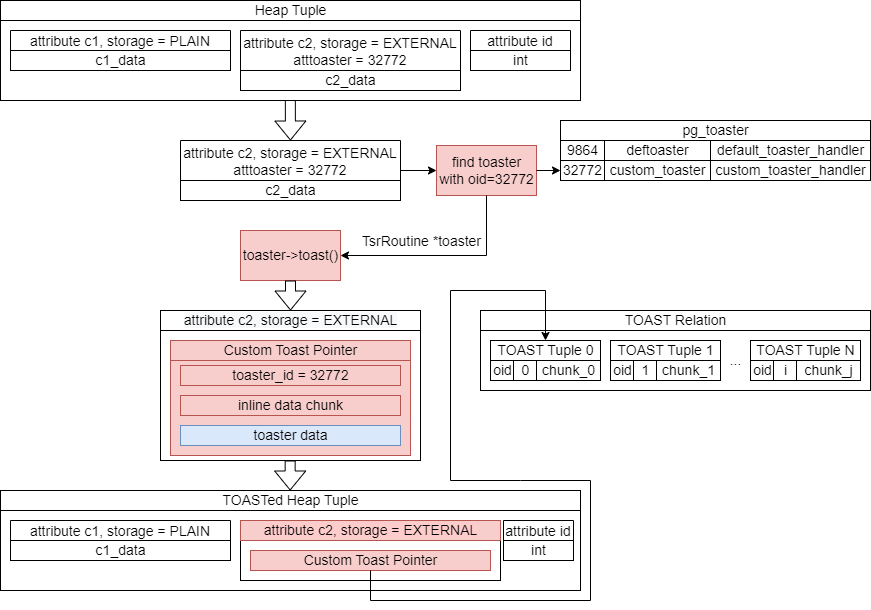
При восстановлении значения из TOAST-указателя (detoast) ID тостера берется из заголовка Custom-указателя (custom TOAST pointer).
Причем, даже завернув работу штатного механизма через новый API, мы сохраняем ее неизменной — это важно для совместимости и работы СУБД для всех данных, для которых не заданы пользовательские алгоритмы тоста.
Такой подход позволяет решить основные проблемы, связанные с TOAST, описанные в части 3, так как он отвязывает сам механизм от жестко заданного формата тост-таблиц, и ограничений, связанных с единственной тост-таблицей на все колонки базовой:
1) Ограничение на 2^32 уникальных ID значений — подключение тост-таблиц произвольного формата позволяет реализовывать в них любой способ идентификации.
2) Операция UPDATE — мало того что мы можем реализовать UPDATE наиболее эффективным для конкретного вида данных способом — это также позволит значительно уменьшить распухание тост-таблиц, так как данные теперь будут переиспользоваться, а не помечаться целиком как dead.
3) Проблема с INSERT при достижении максимального значения записей в тост-таблице решается вместе с предыдущими пунктами — можно ввести 64-битный идентификатор записи, автоматически расширять список тост-таблиц, или вообще применить какой-то иной способ идентификации.
4) При помощи Pluggable TOAST одна базовая таблица может иметь произвольное количество тост-таблиц — и одну таблицу на все атрибуты, и даже множество тост-таблиц на один атрибут.
5) Ограничение в 32 Тб легко обходится автоматическим расширением списка тост-таблиц, назначенных на атрибут — при заполнении одной просто создается новая. Это же позволяет более эффективно использовать vacuum — те таблицы, в которые в данный момент не выполняется вставка, можно чистить.
6) Индивидуальное подключение тостеров к колонкам и типам данных позволяет в каждом тостере реализовывать алгоритм, наиболее эффективный для данного типа данных.
7) Принудительное помещение данных в тост-таблицу предлагается контролировать при помощи опций столбца, что потребует незначительной модификации синтаксиса (ввода новой опции вида, например «SET TOAST FORCE»).
8) API позволяет вынести TOAST как отдельный модуль, что значительно облегчает его расширение и модификацию. Неизменным остается только штатный механизм, используемый по умолчанию, если не был подключен другой.
А теперь…
5. Pluggable TOAST в действии
Для подтверждения эффективности и проверки возможностей Pluggable TOAST с его помощью нами были разработаны несколько реализаций TOAST для наиболее сложных и востребованных типов данных — bytea, json (jsonb), реализован новый механизм хранения больших бинарных объектов — large objects, текущая реализация которого в PostgreSQL настолько устарела, что фактически такие объекты сейчас почти не используются.
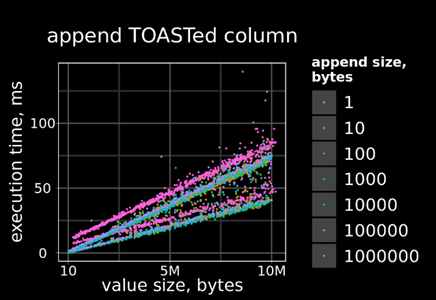
1) bytea appendable Toaster — реализация TOAST для данных типа bytea, с поддержкой операции append — когда к существующему значению дописывается «хвост», более подробное описание — в этой статье: Appendable bytea TOAST. В текущей реализации TOAST это приводит к тому, что все значение помечается как dead, и в таблицу пишется новое полностью, хотя фактически к старому добавился только «хвост», что приводит к очень быстрому распуханию тост-таблицы, и очень большому объему трафика в WAL. Ниже приведен график времени выполнения операции append для штатного тост-механизма:
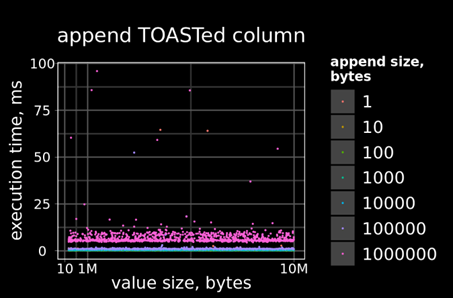
И для расширения bytea_appendable_toaster:
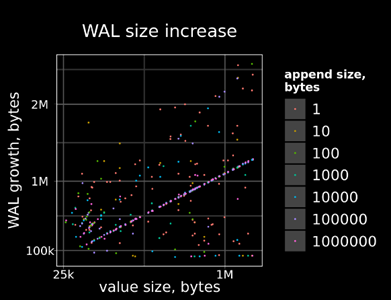
Аналогично, заметные изменения есть и в WAL. Штатный механизм:
bytea_appendable_toaster:
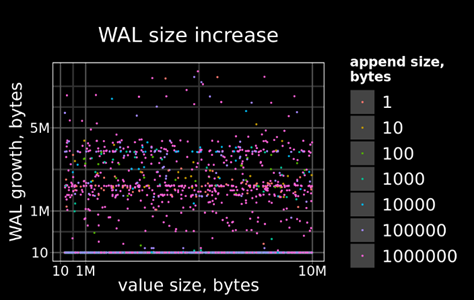
Для штатного механизма трафик WAL увеличивается линейно в зависимости от размера исходного значения, для модифицированного — только в зависимости от размера добавляемой части.
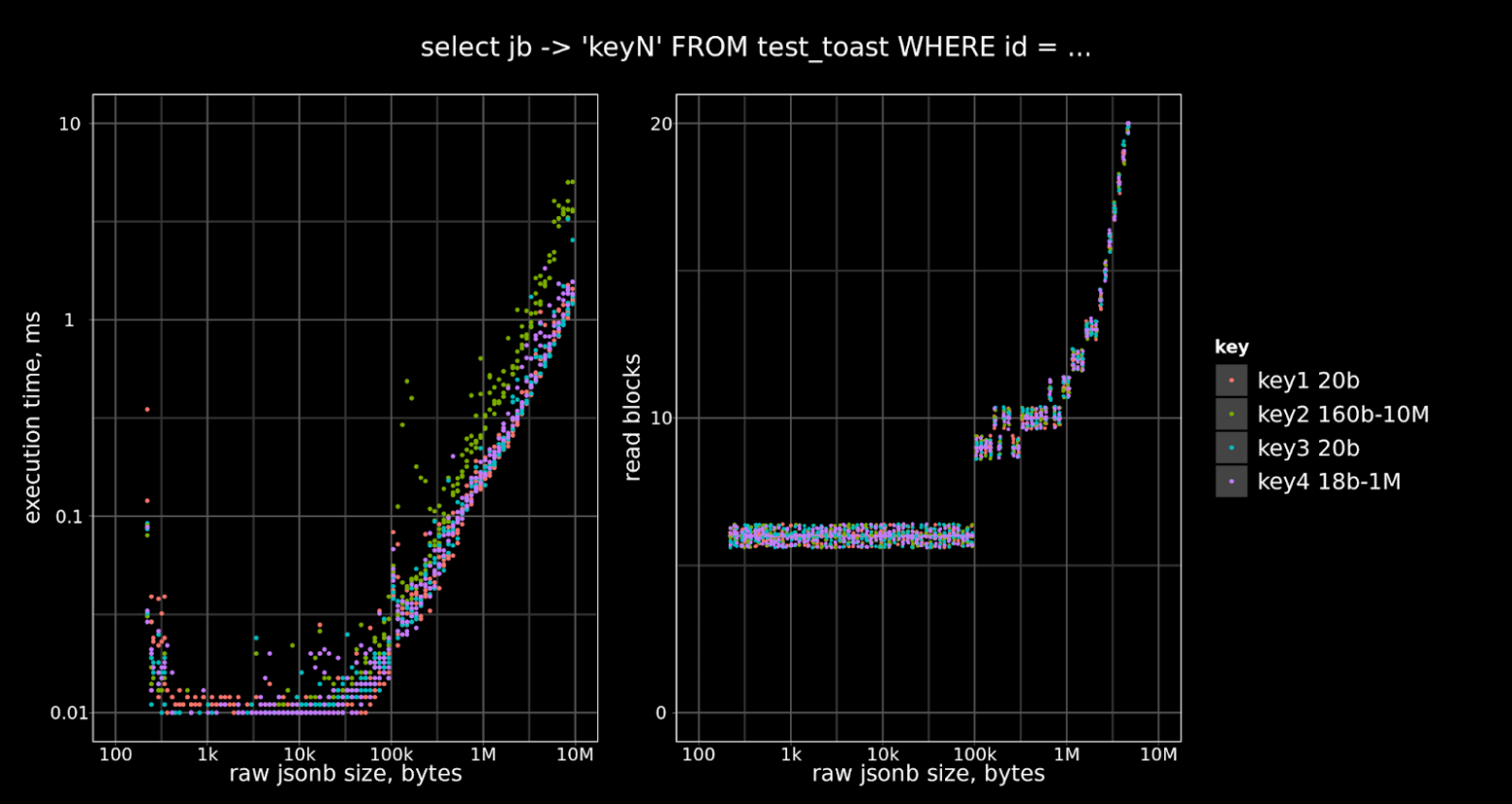
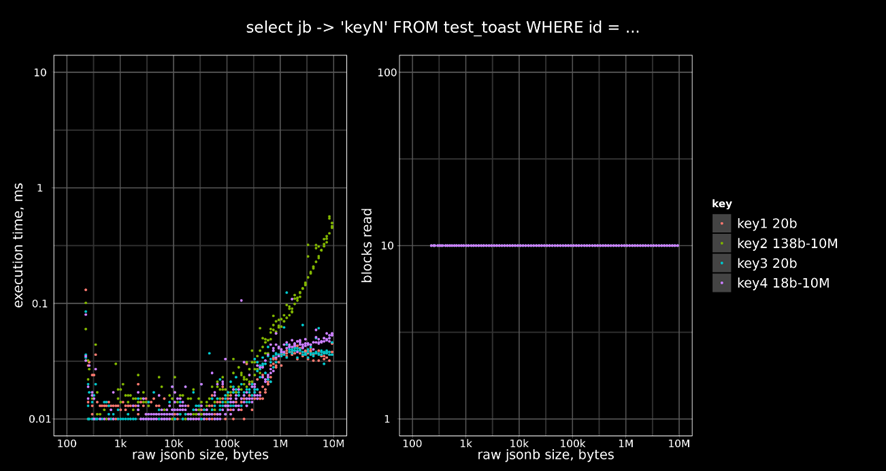
2) jsonb Toaster — еще более впечатляющие результаты были получены для алгоритма TOAST, специализированного для jsonb -значений. Работе с json и jsonb посвящено много статей — Speed Up The JSONB, JSONB на стероидах, JSONB изнутри, JSON or not JSON и другие. jsonb -тостер использует оптимизацию построения jsonb -объектов — ключи и значения в объектах хранятся не в том порядке, в котором были переданы, а в оптимизированном для более быстрого доступа — то есть значения отсортированы по возрастанию длины. Используются и другие оптимизации, такие как частичная декомпрессия, частичное извлечение TOASTed-значения — более подробно они разобраны в материалах по ссылкам выше. По времени выполнения команд выигрыш получился очень заметный — приведу график для выполнения команды SELECT (выборки по ключу). Первый график — это штатный TOAST, второй — оптимизированный.
штатный механизм:
jsonb toaster:
3) superfile Toaster — еще один эксперимент, результатам которого был посвящен доклад TOAST Large Objects на PgConf.Russia 2022. Иногда перед пользователями СУБД встает задача хранения больших бинарных значений в базе, и вот тут PostgreSQL значительно уступает конкурентам — в распоряжении пользователя есть только функциональный интерфейс largeobject, имеющий очень серьезные ограничения, и чрезвычайно неудобный в использовании. Мы решили попробовать реализовать такой функционал при помощи нашего API — ведь, как я уже упоминал, абстрагируясь от штатного механизма в пользу интерфейса, мы больше не связаны форматом и количеством таблиц. Это позволяет естественным образом избавиться от ограничения в 1 таблицу pg_largeobject на 1 экземпляр базы данных и от ограничения в 2 Тб на значение — в нашем случае значение может иметь длину вплоть до максимального размера таблицы, то есть 32 Тб. Также возможно расширить набор доступных функций, к примеру, функциями поиска последовательности, чтения произвольной части объекта, и далее по необходимости.
Ниже приведен график выполнения команды INSERT для прототипа SUPERFILE:
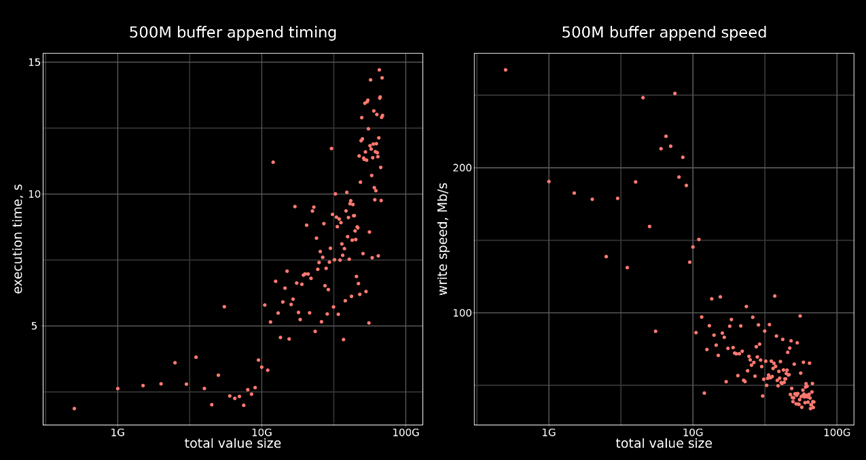
6. Заключение
Подход оказался чрезвычайно многообещающ, и открывает хорошие перспективы для развития PostgreSQL — использование различных алгоритмов компрессии, форматов и способов хранения данных, а для типа JSON — возможность связи JSON-объектов с JSON-схемой, и многое другое.
Маловероятно, что в ближайшие годы в Postgres изменится подход к способу хранения данных на дисках, а значит, TOAST будет жить еще довольно долго, и его доработка чрезвычайно актуальна. К сожалению, мы не смогли добиться включения нашего патчсета в ванильную версию PostgreSQL 15, и решили модифицировать наш API таким образом, чтобы его можно было включить в качестве расширения в релизы Postgres Pro Standard/Enterprise и сделать описанные в статье новые возможности доступными широкому кругу пользователей как можно раньше. Кстати, аналогичная ситуация постигла и доработку 64xid, описанную в статье Устройство 64-битных счетчиков транзакций в Postgres Pro, решающую проблему wraparound-а счетчиков, которая серьезно затрудняет работу СУБД в условиях высокой нагрузки. Похожая ситуация и с очень важной и нужной доработкой SQL/JSON [SQL/JSON in PG 15, SQL/JSON committed to PostgreSQL 15!], позволяющей работать с json-объектами из SQL — она была добавлена в PG15, потом изъята из него, потом снова добавлена, но в урезанном варианте.
Почти все упомянутые разработки размещены в Git под open-source лицензиями:
TOAST API с модификацией таблиц каталога + bytea appendable toaster
TOAST API с контрольной таблицей, без модификации таблиц каталога
jsonb Toaster
64-bit TOAST value id
