Заповеди начинающего DS

Привет! Меня зовут Mashkka Тихонова. Я — Senior Data Scientist, а еще я активно преподаю все, что связано с ML, DS и DL — помогаю людям начать свой путь в Data Science!
За годы преподавания у меня накопилось много советов для тех, кто только-только начинает свой путь в DS. Этими советами я всегда делюсь со студентами, а теперь решила собрать их в одном посте, написанном по мотивам моей серии постов в tg .
Советы эти совсем простые (уровня не заваливай горизонт на фото, когда фоткаешь пейзаж), но очень часто именно про такие базовые вещи на первых этапах забывают рассказать.В свое время я сама наступала на эти грабли, так как мне их никто не рассказал. Буду рада, если помогу вам этих ошибок избежать!
Замечение: и не заваливайте горизонт без нужды на фото, пожалуйста, сделать его ровным — это всего пара секунд!
Заповедь 1. Гуглить, гуглить, гуглить и еще раз гуглить!

Самый важный навык, который первым делом должен освоить любой DS — это гуглить!
Ищешь ответ на вопрос? — Гугли, а только потом спроси!
Не работает код? — Гугли!
Выбираешь алгоритм? — Гуглить!
Нужен пример кода? — Гугли!
Не знаешь, как правильно закодить? — Гугли!
Нужны статьи по теме? — Гугли!
и т. д. и т. п.
Гугл, конечно, знает не все, но ооооочень многое. И прежде, чем бежать с вопросами к коллегам, знакомым, преподавателям — загуглите. Скорее всего вы найдете ответ.
И помните не забывайте золотые правила Гуглежа: ⬇
Гуглить только в Гугле, лучше на ванильном Google.com. Никакого поиска в Яндексе, Mail или Bing, если вы ищите что-то по Data Science. Не хочу обидеть другие поисковики, я сама люблю поиск Яндекса, но для целей Data Science — это Google и только он.
Гуглить только на английском: не пытайтесь что-то искать на русском языке — это боль. Даже если не знаете английский, лучше перевести ваш запрос на английский и загуглить так.
Гуглить по ключевым словам: при формулировке запроса старайтесь выделить ключевые слова (на английском) и загуглить именно их. Вероятность найти то, что вы ищите, намного выше, чем когда вы формулируете предложение целиком.
Заповедь 2. Всегда фиксируйте random_state
Если у вас в коде есть какая-то случайность (случайное разбиение на train и test, случайная инициализация и т. д.), то лучше эту случайность зафиксировать. Для этого у всех методов обычно есть специальные параметры типа ransdom_state, seed, random_seed и т.п.
Согласитесь, обидно: перезапустил ноутбук и скор упал или вообще все сломалось? Поэтому старайтесь, чтобы ваш код работал детерминировано и всегда выдавал один и тот же результат.
Всем рассказываю страшилку про своего стажера. Он долго-долго обучал нейросеть, а когда я попросила его оценить качество и прогнать модель на тесте, он с ужасом понял, что забыл зафиксировать random_state при разбиении на train и test, а код с разбиением заглушил. Странная ситуация: есть модель, есть данные, а оценить ее нельзя — непонятно, какие данные использовались при обучении и на чем её тестировать. Пришлось переобучать.
train_X, test_X, train_Y, test_Y = train_test_split(X, Y,
test_size=0.2,
random_state=42)Итог: random_state = 42 наше все!
Заповедь 3. Читайте логи
Не надо бояться страшных логов ошибок. Часто в них содержится та самая информация, которая поможет понять, что не так в коде.
Единого «правила чтения» логов нет, у каждого здесь свой «авторский» подход. Я обычно вначале смотрю, на какой строчке все сломалось, а потом прокручиваю в самый конец — в последней строчке как правило содержится ключевая информация, что не так. Если этого оказалось недостаточно, то начинаю читать логи снизу вверх, постепенно раскручивая ошибку из недр Python вверх как спираль. А еще чаще гуглю (в Google! по правилу 1) самую последнюю строчку ошибки и в большинстве случаев на Stack Overflow нахожу ответ.
Кстати, у sklearn очень хорошие подсказки в логах, которые зачастую напрямую говорят, что не так и как это исправить.
Например:
На картинке sklearn прямо пишет о том, что в наших обучающих данных содержится всего один признак или пример надо попросту сделать train_X.reshape
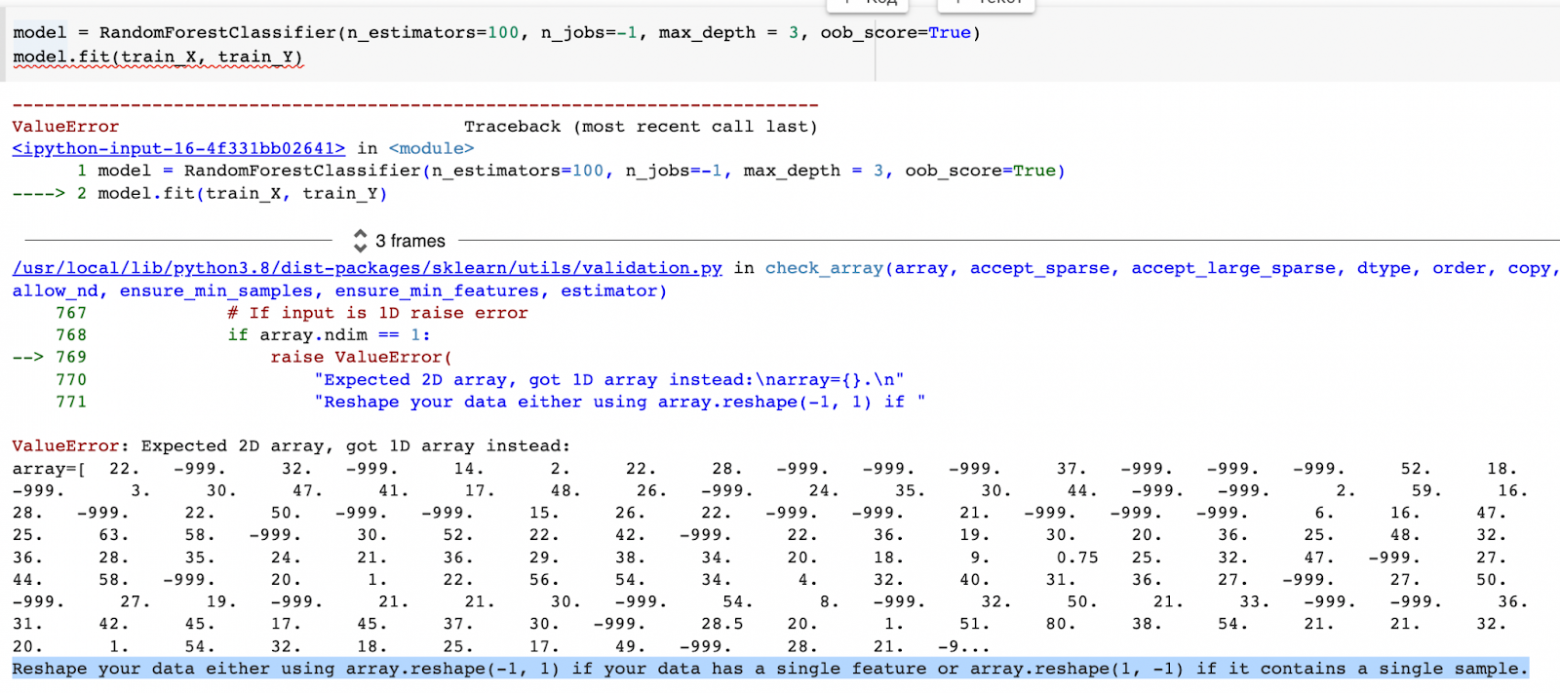
А дальше просто смотрим на размерность X_train и обнаруживаем, что да, в данных действительно всего один признак:

Значит, по совету sklearn из логов надо написать так:
model.fit(train_X.reshape(-1, 1), train_Y)Или пример чуть посложнее:
При попытке зафитить GridSearch на ирисах Фишера (задача классификации на 3 класса), оценивая качество с помощью F1:
clf = GridSearchCV(svc, parameters, scoring = 'f1')
clf.fit(iris.data, iris.target)sklearn подскажет нам, что необходимо указать тип агрегации, среди прочего выдав в логах вот такую подсказку:
ValueError: Target is multiclass but average='binary'. Please choose another average setting, one of [None, 'micro', 'macro', 'weighted'].нам остается просто последовать его совету и поменять scoring = 'f1' на scoring = 'f1_micro':
clf = GridSearchCV(svc, parameters, scoring = 'f1_micro')
clf.fit(iris.data, iris.target)Заповедь 4. Едим слона по частям — дебажим по кускам
Как часто бывает, что код не работает и не понятно почему. Или еще хуже, работает неверно и в переменных оказывается записано что-то непонятное совсем с потолка.
Например, такое нередко случается, если вы пытаетесь разом совместить всю предобработку данных вместе с обучением модели и запихиваете все это в одну ячейку кода, оборачивая в ColumnTransformer, Pipeline, и GridSearchCV.
В этом случае дебаг вам в помощь! И если вы пока еще не освоили базовые логгеры и такую удобную штуку как VS Code (а я очень рекомендую вам это сделать и как можно скорее), то самое простое — это понаставить побольше принтов — print (можно прямо после каждой строчки кода), чтобы отследить что оказалось в каждой переменной на каждом шагу. Чаще всего это помогает найти ту самую строчку, где все пошло не так.
А еще можно разбить одну ячейку с кодом на несколько (чем детальнее, тем лучше), выводя в конце каждой клетки значения переменных и проверяя их корректность.
Что касается ColumnTransformer и Pipeline, то на этапе первично написания кода, я обычно обхожусь без них, так как они очень усложняют дебаг. А оборачиваю в них все уже в конце, после первичной отладки кода. Но тут уже вкусовой вопрос.
Замечание: еще раз подчеркну, что специально сейчас не касаюсь сейчас всяких логгеров и прочих более продвинутых фишек откладки кода, а говорю про самый упрощенный дебаг на уровне принтов. Такой дебаг доступен всем, даже самым-самым начинающим DS, которые работают в GoogleColab. Если хотите начинать трушно, я только за!
Заповедь 5. Никогда не обучайтесь на тесте
Никогда, никогда, никогда не обучайте модель на тесте! То, что модель ни в каком виде не должна видеть тест на этапе обучения вы должны запомнить как 2×2 = 4.* Показать (или дать подглядеть) модели тест — это все равно, что прорешать со школьником его вариант ЕГЭ в классе, а потом радоваться, что он получил высокий балл. Это, конечно, здорово, но к реальным знаниям, то есть качеству модели, этот результат на таком утекшем тесте отношения не будет иметь.
*В примере 2×2 = 4 я предполагаю, что мы находимся в кольце целых чисел со стандартной операцией умножения.
Но если с обучением модели и тестом все ясно, на то он и тест, то с обучением трансформаций типа StandardScaler или CountVectorizer и т. п. есть еще один нюанс. Метод fit_transform для них можно вызывать только от обучающих данных (то есть от train), а для теста всегда используем лишь transform:
X_train_scaled = scaler.fit_trasnform(X_train)
(Эту строчку сделать зачеркнутой!) X_test_scaled = scaler.fit_trasnform(X_test)
X_test_scaled = scaler.trasnform(X_test)Строчка X_test_scaled = scaler.fit_trasnform(X_test) может полностью испортить ваш эксперимент, ведь обучение на тесте приведет к тому, что на обучающей и тестовых выборках данные будут отмасштабированы по-разному, а значения train и test не будут биться между собой.
Пример:
Допустим у нас есть набор данных x_train = [0, 10, 20], x_test = [0, 5, 10], к которому мы хотим применить минимаксное преобразование (это преобразование приводит данные в диапазон [0–1]).
Отталкиваясь от значений в x_train, получаем вот такое соответствие:
0 => 0
5 => 0.25
10 => 0.5
20 => 1
В итоге получаем, что X_train_scaled = [0, 0.5, 1], X_test_scaled = [0, 0.25, 0.5].
Но стоит руке дрогнуть и случайно написать: X_test_scaled = scaler.fit_trasnform(X_test) и, о ужас, соответствие на тесте изменится и для теста мы получим вот такую вещь:
0 => 0
5 => 0.5
10 => 1
и в итоге получим X_train_scaled = [0, 0.5, 1], X_test_scaled = [0, 0.5, 1], что полностью собьет с толку вашу модель.
Заповедь 6. Не называйте переменные также как библиотеки или функции
Не самая частая, но очень неприятная ошибка: загрузил пакет или функцию, а потом нечаянно назвал переменную тем же именем. Как итог, тщетно пытаешься применить эту функцию, получая странный error, в котором непонятно ничего. Обычно выглядит это как-то так:
TypeError: 'ResultSet' object is not callable. Как это связано с функцией/пакетом? НепАнЯтнА! А загулить такое по названию метода не получается никак… Тяжело…
Помню, одна студентка парсила данные и импортировала BeautifulSoup — библиотеку для работы с html-документами по именем soup:
from bs4 import BeautifulSoup as soupПотом в совершенно другой ячейке написала:
soup = soup(html, 'html.parser')
print(soup.prettify()[:2000])А потом долго недоумевала, почему при первом запуске все окей, но если перезапустить ячейку, то все ломается и что не так.
А дело было в том, что после выполнения soup = soup(html, 'html.parser'), имя soup превращается в обычную переменную. Вот такие дела…
Заповедь 7. Со StackOverflow копировать код надо из ответа, а не из вопроса

Заповедь эта немного шуточная и написана под вдохновением одного из подкастов Андрея Себранта, а ее название говорит само за себя, к нему и добавить-то нечего. Разве что прочитайте все ответы на вопрос и найдите тот, который действительно даёт правильный ответ!
Заповедь 8. Не забывайте про бэкап — делайте промежуточные чекпоинты
Как же приятно запустить код на выходные/поставить обучаться большую модель, а потом в понедельник обнаружить, что вычисления посчитались почти до конца, но в последний момент код упал. Например, на выходные перезапустили сервер, когда ваш прогресс был уже 99%!
Или при парсинге огромного сайта после тысячной страницы вас забанили по API, а ваш код упал.
Подобных случаев, увы, в практике любого DS-ника не избежать. Но от них можно хотя бы частично обезопасить себя, если делать промежуточные чекпоинты модели, сохранять раз в несколько итераций обработанные данные и логгировать прогресс. Тогда вам не придется перезапускать все с нуля, и вы сможете частично восстановить результат.
Совет, казалось бы, очевидный, но почему-то очень часто многие забывают про него. Но помните, поленившись написать пару строк кода с сохранением, вы всегда рискуете потом об этом пожалеть!
Заповедь 9. Трепещите перед мощью и коварностью регулярок

Регулярные выражения — очень мощный и удобной инструмент для работы с текстами. Они позволяют эффективно искать/заменять в текстах фрагменты, удовлетворяющие определенному шаблону. С помощью регулярок можно действительно решить кучу разных задач, связанных с поиском по тексту, но не стоит недооценивать их коварство.
Ведь не зря говорят, когда некоторые люди сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы ©
У регулярок обожают вылезать крайние случаи, в которых они работают неправильно (спецсимволы, выражения, не удовлетворяющее шаблону в конце/начале строки и т. п.). А потом начинается бег по кругу: вы пытаетесь учесть крайний случай и регулярка начинает неправильно работать в другом месте и т. д. и т. п. Как итог, она разрастается до монструозных размеров, и вообще становится непонятно, когда она работает, а когда нет.
Надеюсь, я вам не слишком напугала. Не стоит боятся регулярок, они действительно удобные, но с ними надо всегда быть аккуратными, вот и все!
Заповедь 10 (заключительная). Встав перед выбором, проводите эксперимент
Если вы не знаете, как правильно, то Google, как вы знаете, знает все. Поэтому, в любой непонятной ситуации, по заповеди 1, мы гуглим. Но что делать, если у вас есть два варианта, оба правильные, но вы не знаете какой из них лучше взять?
Встав перед таким выбором настоящий Data Scientist проведет эксперимент: попробует оба варианта и выбирете тот, который окажется в данной ситуации лучше (например, на валидации).
Студенты часто спрашивают: «Мария, вот у меня есть какой-то там датасет (который я лично никогда и в глаза не видела) и какая-то там задача (о которой я пока имею очень смутное представление только с их слов), как мне лучше всего заполнить пропуски в данных, медианой или средним? А какой метод снижения размерности выбрать?»
На подобные вопросы я всегда отвечаю так: «Сравните и выберете то, что даст лучший результат! Только эксперимент даст вам ответ, что будет лучше в вашем конкретном случае!»
Warning: только не переборщите с количеством вариантов, особенно при переборе гиперпараметров методом GridSearchCV. Помните, с ростом количества перебираемых фичей, количество вариантов возрастает мультипликативно, то есть в разы. Поэтому всегда прикидывайте, сколько вариантов у вас получится и сколько вы готовы ждать результат.
Итого: в любой непонятной ситуации — гугли, а в любой неоднозначной — проводи эксперимент!
Заключение:
Буду рада, если эти советы помогут вам избежать самых типичных ошибок на пути начинающего Data Scientist. А возможно, если вы уже опытный DS-ник, они вас позабавят и вы с улыбкой вспомните, как сами через это прошли. А еще обязательно прочитайте мои вредные советы Айтишнику!
Также приглашаю всех посетить открытый урок для новичков в ML на тему «Первичный анализ данных с Pandas», который пройдет я проведу уже сегодня. На встрече обсудим, зачем нужен первичный анализ данных в машинном обучении, какие существуют инструменты для первичного анализа данных в Python, как визуализировать данные и какая преобработка данных нужна в ML. Запись на урок доступна по ссылке ниже. А для тех, кто не успеет зарегистрироваться, по этой же ссылке будет доступна запись урока.
