Записки оптимизатора 1С (Часть 3). Распределенные взаимоблокировки в 1С системах

Назрела небольшая статья, скорее даже пост о распределенных взаимоблокировках в системах 1С. Мы периодически сталкиваемся с такими ситуациями у наших заказчиков и хочется поделиться с сообществом информацией, т.к. далеко не все могут увидеть и правильно интерпретировать природу таких блокировок.
Взаимоблокировки — это частный случай блокировки; при этом две или более транзакции образуют «круг ожидания»: первой транзакции нужны ресурсы второй транзакции, вторая ждет освобождения ресурсов, занятых первой транзакцией. Такая цепочка ожиданий не может завершиться успешно, единственный выход из ситуации — оборвать одну из транзакций. Таким образом, при обнаружении взаимоблокировки монитор блокировок назначает жертву, производит откат ее транзакции и возвращает приложению ошибку. Остальные транзакции имеют возможность успешно завершиться.
На рисунке ниже приведен пример графического отображения взаимоблокировки, на котором видно, что причиной являлся ключ индекса »_AccumRgTn86916_1» таблицы »_AccumRgTn86916»
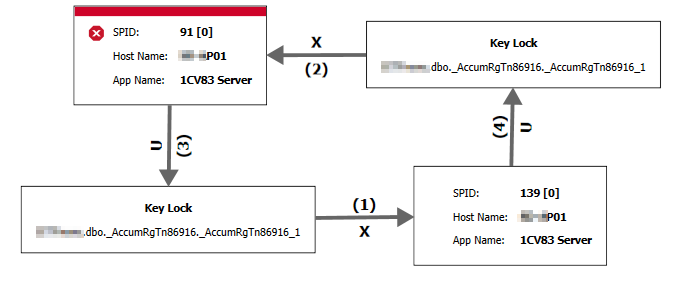
Вышеописанное относится к SQL-блокировкам. Похожие взаимоблокировки могут возникать и в пространстве управляемых блокировок 1С, и механизм 1С также их обрабатывает. Но есть и другой интересный случай взаимоблокировок, который имеет иную природу — распределенные взаимоблокировки.
Особенность распределенной взаимоблокировки в том, что разные части «круга ожидания» находятся в разных пространствах блокировок: сессия А ждет сессию Б на SQL-блокировках, а сессия Б ждет сессию А на уровне управляемых блокировок, «живущих» на сервере 1С. Ни 1С, ни SQL Server не понимают серьезности ситуации: с точки зрения каждого приложения происходит обычная блокировка. В случае обычной, не распределенной взаимоблокировки, приложения сразу верно оценивают ситуацию и обрывают одну из сессий. Здесь же начинается «соревнование»: «у кого таймаут блокировки длиннее» — проигравшее приложение первым выдаст сообщение о долгой блокировке, но никак не поможет понять, что ситуация гораздо сложнее и интереснее.
Отловить такие блокировки без хорошего инструментария очень сложно, т.к. нужно точно синхронизировать периоды начала и окончания этих двух видов блокировок.
Покажу пример, который хорошо можно увидеть с помощью мониторинга Perfexpert, где по каждому виду блокировок уже есть готовые счетчики.

На графиках, за календарную неделю сразу и хорошо видны периоды времени, когда взаимоблокировки sql совпадают по времени с управляемыми блокировками 1С.
Теперь масштабируем (приближаем) графики и получаем довольно точно искомый промежуток времени:

На следующем рисунке приведен более крупный фрагмент предыдущего рисунка с панелями сессий SQL и сессиями 1C, где видны деревья блокировок на выбранный момент времени.
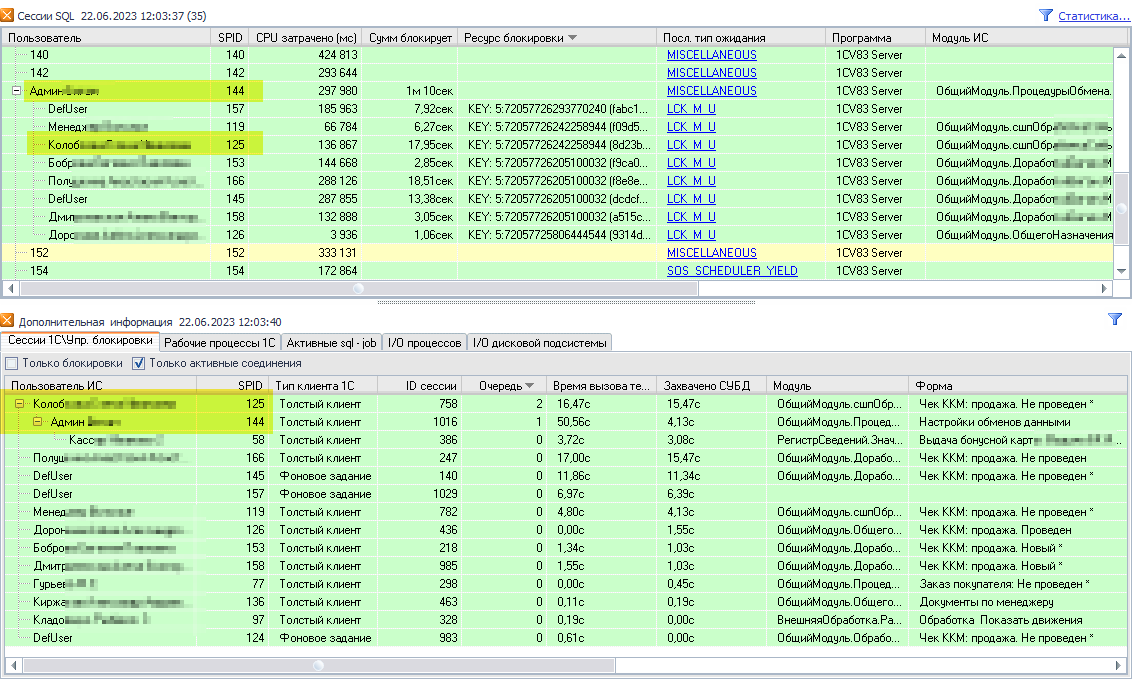
На уровне СУБД (верхняя панель на рисунке) пользователь Колоб… (spid 125) ожидает завершения операции пользователя Админ… (spid 144).
А на уровне 1С (нижняя панель на рисунке) картина выглядит в точности наоборот, пользователь Админ… (spid 144) висит на управляемой блокировке 1С и ожидает завершения операции пользователя Колоб… (spid 125).
Более того, на уровне СУБД за пользователем Админ… (spid 144) скопилась достаточно внушительная очередь из других ожидающих (заблокированных) пользователей. Но, фактически, они ждут не завершения операции пользователя Админ… (spid 144), а её прерывания по таймауту, так как, по сути, он тоже является заблокированным (на уровне 1С).
Выводы
Этот пример я привел для того, чтобы показать, как видят одну и ту же ситуацию администратор СУБД и разработчик 1С.
Администратор со своей стороны видит блокировку, видит, что сессия sql ничего не делает и открыла транзакцию. Может утверждать, что это явная транзакция на 1С, которая не закрылась, например, какой-то диалог в транзакции. А разработчик 1С видит управляемую блокировку, сессию, которая открыла транзакцию на СУБД и зависла, например, по причине долгого выполнения какого-то запроса на сервере СУБД или зависания sql-сессии.
То есть, для решения таких проблем должна быть возможность видеть блокировочную картину со стороны СУБД и со стороны 1C: Предприятие одновременно. И станет понятным как интерпретировать ситуацию правильно.
С «кто виноват?» разобрались. Теперь «что делать?». Если такие блокировки не единичные и действительно мешают работе пользователей, то вот несколько вариантов как их снизить. Это, конечно, не серебряная пуля, но с этого можно начать.
На стороне 1С:
— Уменьшать гранулярность управляемой блокировки;
— Изменить порядок блокировок 1С с учетом той последовательности таблиц, в которой они используются в коде программы.
— Уменьшить таймаут, а может быть даже отказаться от блокировки на этом участке кода.
На стороне СУБД:
— отключить эскалацию блокировок (например, до уровня записи или страницы)
— проверить индексы — возможно не хватает полностью покрывающего индекса в запросе
— уменьшить таймаут.
Это был пример, демонстрирующий распределенную взаимоблокировку таблиц БД в связке MS SQL — 1С, но конкуренция за ресурсы может быть при доступе к файлам на диске, памяти и другим ресурсам любой природы. То есть, для того чтобы расследовать какой-либо инцидент просадки производительности далеко не всегда достаточно посмотреть на проблему лишь с одного ракурса (со стороны СУБД, со стороны ОС, со стороны приложения и т.д.). Лучше видеть картину целиком, иначе можно стать заложником неправильно и поспешно принятых решений.
Надеюсь, вам понравилась статья и она поможет качественно анализировать и решать сложные проблемы производительности ваших информационных систем.
Ссылка на описание мониторинга Perfexpert: https://softpoint.ru/solutions/perfexpert/.
Ссылки на остальные части Записок оптимизатора1С:
Записки оптимизатора 1С (часть 1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
Записки оптимизатора 1С (часть 2). Полнотекстовый индекс или как быстро искать по подстроке
