Заметки с MBC Symposium: еще о седловых точках
Напоследок, о второй части доклада Surya Ganguli — как теоретическое понимание процесса оптимизации может помочь на практике, а именно, какую роль играют седловые точки (первая часть вот тут, и она совершенно необязательна для чтения дальше).

Disclaimer: пост написан на основе отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы.
Чуть-чуть напомню, что такое седловые точки. В пространстве нелинейных функций есть точки с нулевым градиентом по всем координатам — именно к ним стремится градиентный спуск.
Если у точки градиент по всем координатам 0, то она может быть: 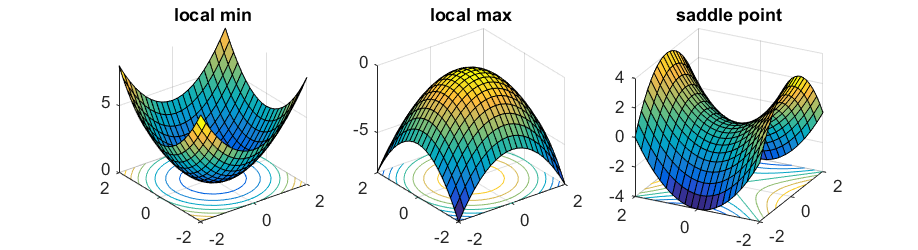
- Локальным минимумом, если по всем направлениями вторая производная положительна.
- Локальным максимумом, если по всем направлениям вторая производная отрицательна.
- Седловой точкой, если по каким-то направлениям вторая производная положительна, а по другим отрицательна.
Итак, нам рассказывают хорошие новости для градиентного спуска в очень многомерном пространстве (каким является оптимизация весов глубокой нейросети).
- Во-первых, подавляющее большинство точек с нулевым градиентом — это седловые точки, а не минимумы.
Это можно легко понять интуитивно — чтобы точка с нулевым градиентом была локальным минимумом или максимумом, вторая производная должна быть одного знака по всем направлениям, но чем больше измерений, тем больше шанс, что хоть по какому-то направлению знак будет другим.
И поэтому большинство сложных точек, которые встретятся — будут седловыми. - Во-вторых, с ростом количества параметров оказывается, что все локальные минимумы довольно близко друг к другу и к глобальному минимуму.
Оба этих утверждения были известны и теоретически доказаны для случайных ландшафтов в больших измерениях.
В сотрудничестве с лабой Yoshua Bengio их получилось экспериментально продемонстрировать и для нейросетей (теоретически пока не осилили).
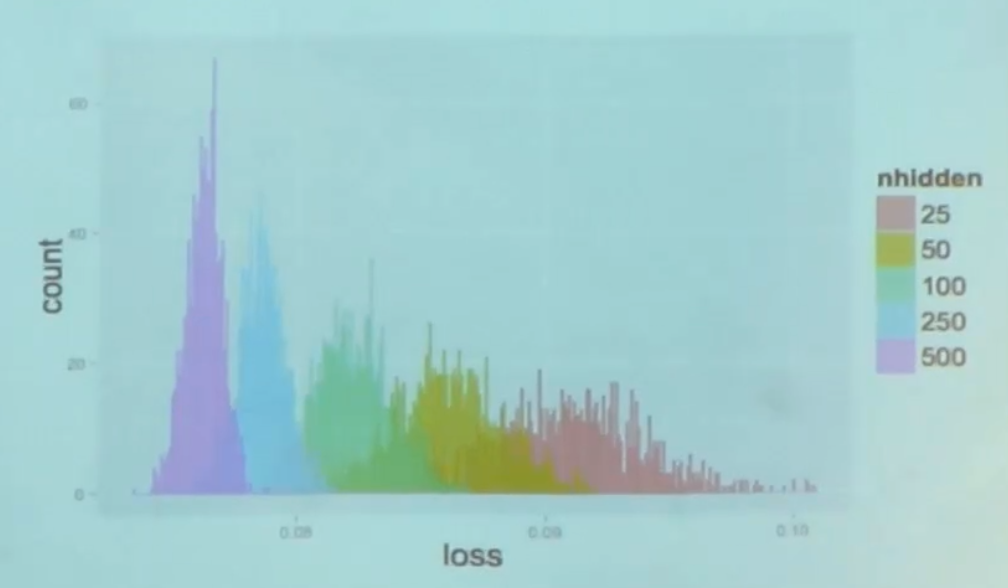
Это гистограмма значений cost function в локальных минимумах, которые получились многократными попытками тренировок из разных точек — чем меньше параметров, тем меньше разброс значений в локальных минимумах. Когда параметров много, разброс резко уменьшается и становится очень близким глобальному минимуму.
Главный вывод — что локальных минимумов бояться не нужно, основные проблемы — с седловыми точками. Раньше, когда мы плохо умели тренировать нейросети, мы думали, что это из-за того, что система скатывается в локальный минимум. Оказывается, нет, мы просто не могли выбраться из седловой точки.
И вот они придумали твик градиентного спуска, который хорошо избегает седловых точек. К сожалению, у них там используется гессиан.
Для необразованных как я, гессиан — это матрица значений попарных вторых производных в точке. Если думать о градиенте как о первой производной для функции от многих переменных, гессиан — вторая.
Александр Власов вот написал хороший туториал про так называемые second order optimizations, к которым относится работа с гессианом.
Разумеется считать гессиан — страшно непрактично для современных нейросетей, поэтому я не знаю как их решение на практике применять.
Второй момент — это они придумали некую теоретически кошерную инициализацию, которая в случае просто линейных систем решает проблему vanishing gradients и дает тренировать сколь угодно глубокую линейную систему за одинаковое количество градиентных шагов.
И мол утверждается, что и для нелинейных систем это тоже помогает. Я, правда, пока не видел упоминаний в литературе успешного использования этой техники.
Ссылки на полные статьи: про оптимизацию градиентного спуска и про улучшенную инициализацию.
В интересное время живем.
