Захватывающая ловля багов, которые портили работу Unbound

Привет, меня зовут Сергей Качеев, я старший разработчик в отделе сетевой инфраструктуры Яндекса. Сегодня я расскажу целый сетевой детектив о том, как мы искали баг, который убивал DNS сервер Unbound. Приготовьтесь, он будет долгим.
Всё началось с того, что мне предложили помочь ребятам из команды DNS найти такие метрики и наборы запросов, по которым будет однозначно понятно, какие настройки влияют на производительность Unbound и какие запросы вызывают у него проблемы.
В самом начале на графиках нагрузочного тестирования я увидел очень плохие результаты: случайным образом абсолютно все запросы нагрузочного теста таймаутились, но сервер, который был под нагрузкой, никак не реагировал на проблему. Как выяснилось позже, по чистой случайности я допустил ошибку в конфигурации нашего плагина Pandora, и в итоге он сам ходил в DNS на каждый запрос, чтобы узнать ip адрес тестируемого сервера. Возможно, это сыграло мне на руку и помогло найти первую из проблем, а потом и вовсе задало вектор поисков остальных багов. А в Unbound их накопилось достаточно.
Уточню, что тестирование проводилось в LXC-контейнере, которому было доступно 48 ядер и 128 Гб памяти. У сервера, на котором запущен контейнер, были следующие характеристики:
CPU: x2 Intel(R) E5-2660 v4 @ 2.00GHz - total Cores: 28 Threads: 56
MEM: x4 Samsung 32GiB 2933MHz - total 128GiB
NET: Intel 82599 10Gbit/sНагрузка подавалась по сети с контейнеров, расположенных на отдельных физических серверах.
Архитектура worker в Unbound
Начнём с того, как устроен Unbound. По сути, это демон, который запускает несколько тредов. Каждый тред запускает свой event loop. В библиотеку обработки событий Unbound передаёт набор callback-функций, которые реагируют на различные сетевые события: например, запрос от пользователя, передача файловых зон, ответ на рекурсивный запрос и другие.

Вот так работает Unbound
Для балансировки между тредами Unbound использует опцию при создании прослушивающего сокета SO_REUSEPORT. С ней ядро Linux само решает, в какой тред направить тот или иной запрос пользователя. Об этом подробнее написано в статье Linux TCP SO_REUSEPORT — Usage and implementation.
Далее event loop получает от операционной системы уведомления о пришедших пакетах и запускает callback-функции. Всё просто.
Ещё одна важная деталь. Для ускорения ответов из кэширующих серверов мы используем конфигурацию hyperlocal zone. Она подразумевает, что на DNS серверах хранится копия auth-zone — то есть файла, в котором хранятся DNS-записи. За счёт этого ответы пользователям отдаются быстрее, потому что данные считываются на месте, а не создаётся отдельный запрос в authority-сервер. Передаются эти файлы с мастера на реплики через механизмы, встроенные в Unbound.
Вздрыжни. И причём тут файловые Authority Zone
В самом начале я упомянул про интересный случай. Инструмент для тестирования перед каждым запросом резолвил адрес тестируемого сервера. Иногда такие запросы в DNS таймаутились.
Проблема была в том, что я не знал истинную причину таймаутов. Я не мог понять, что не так именно с моим стендом: почему тестирование у других коллег проходит без таких всплесков 100% таймаутов. Какая же была взаимосвязь между этими таймаутами и поведением load-стенда?
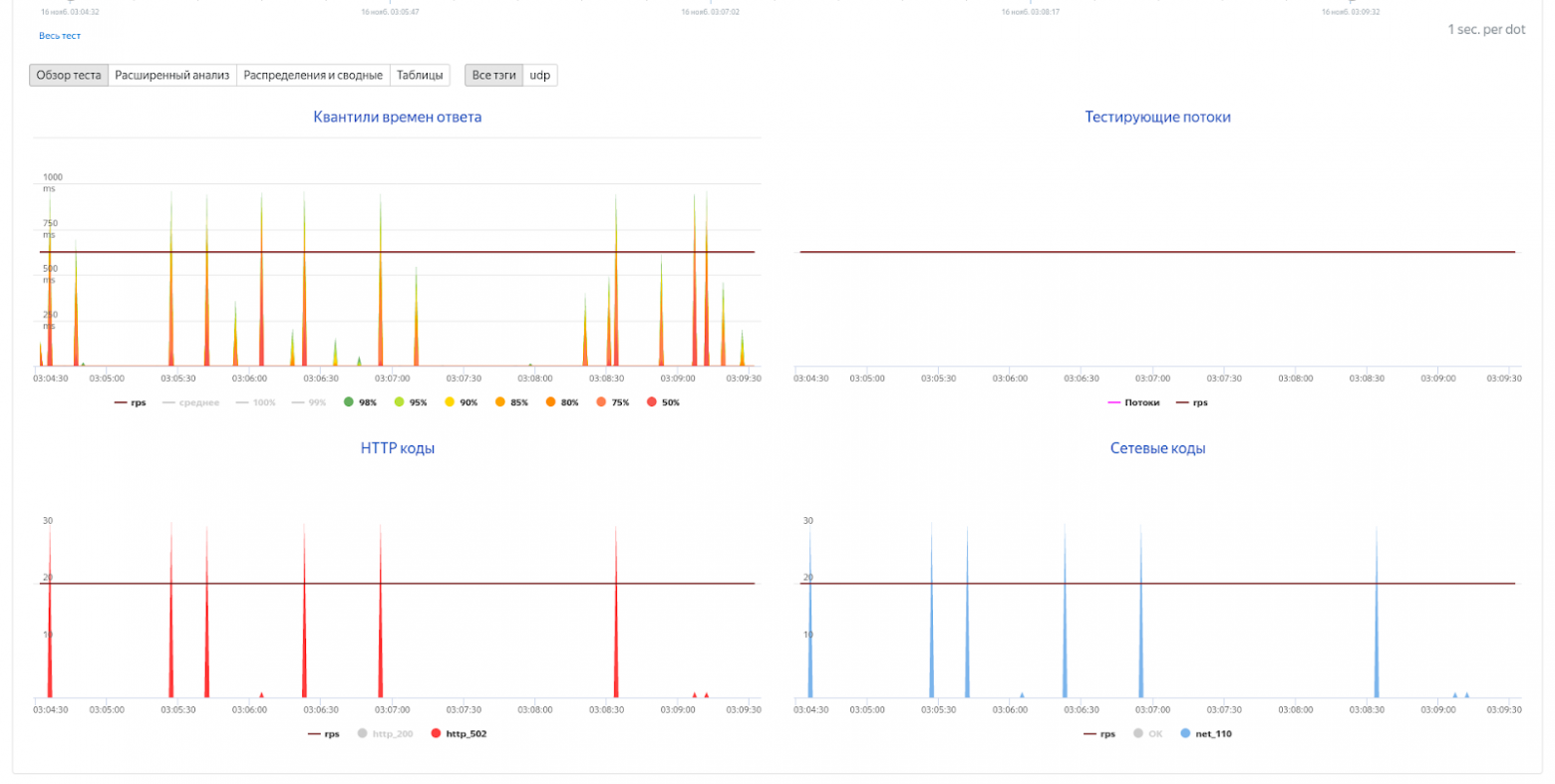
Пример плохого результата нагрузочного теста
Поясню, что происходит на графиках. Тайминги запросов иногда очень большие и в это же время появляются 502 ошибки. Уточню, что изначально overload.yandex.net специализировался на показе результатов тестирования http-сервисов, и поэтому коды ответа показываются как HTTP. Но на самом деле в плагине Pandora мы используем такую трансляцию ошибок:
DnsServerTimeout: 502,
DnsAmmoNotSupported: 503,
dns.RcodeSuccess: 200,
dns.RcodeFormatError: 400,
dns.RcodeServerFailure: 401,
// NXDOMAIN
dns.RcodeNameError: 402,
dns.RcodeNotImplemented: 403,
dns.RcodeRefused: 404,
dns.RcodeYXDomain: 405,
dns.RcodeYXRrset: 406,
dns.RcodeNXRrset: 407,
dns.RcodeNotAuth: 408,
dns.RcodeNotZone: 409,
dns.RcodeBadSig: 410,
dns.RcodeBadKey: 411,
dns.RcodeBadTime: 412,
dns.RcodeBadMode: 413,
dns.RcodeBadName: 414,
dns.RcodeBadAlg: 415,
dns.RcodeBadTrunc: 416,
dns.RcodeBadCookie: 417,Я крутил всё, что только мог в настройках LXD-контейнера, в котором крутился стенд. Я переносил стенд на выделенные ядра и перемещал данные Unbound в tmpfs. Не помогало. Больше всего смущало то, что эффект совершенно не зависел от нагрузки: 1rps, 1Krps, 5Krps — неважно! Всё так же появлялись 100% таймаутов.
Я изучил все сомнительные места в коде Unbound: смотрел на всё, что только мог тулами из bcc-tools, bpf-tools и atop. И ведь нашёл что-то подозрительное! Иногда моменты вздрыжней (так мы назвали этот эффект в команде DNS) совпадали с моментом записи файловых зон.
В документации об этом написано так:
Authority zones can be read from zonefile. And can be kept updated via AXFR and IXFR. After update the zonefile is rewritten.
Я начал копать в этом месте. Очередная попытка: atop и bpftrace запущены, netdata открыта. Смотрим, ждём.
ns-load.name:~$ sudo bpftrace -e 'tracepoint:syscalls:sys_enter_openat
// |,---------------^
// какое событие в системе мы собираемся мониторить.
// Про это можно почитать в документации man bpftrace,
// и там же про kprobe и uprobe.
// // - это комментарий в коде bpftrace-скрипта.
// ,- filter, ловить события только от Unbound,
// | запущенного в этом lxc-контейнере,
// | а если точнее — только в cgroup,
// | созданной этим systemd-сервисом.
/cgroup == cgroupid("/sys/fs/cgroup/unified/system.slice/unbound.service")/
// Однострочник, срабатывающий на каждое системное событие — в данном случае tracepoint
{ printf("%s %s %s\n", strftime("%H:%M:%S", nsecs), comm, str(args->filename)); }' | grep slave # нам интересны только зоны
14:03:22 unbound /etc/unbound/slave/db.yandex.net.tmp2136807
14:03:29 unbound /etc/unbound/slave/cloud.yandex.net.tmp2136807
14:03:33 unbound /etc/unbound/slave/db.yandex.net.tmp2136807
14:03:41 unbound /etc/unbound/slave/cloud-preprod.yandex.net.tmp2136807
14:03:45 unbound /etc/unbound/slave/db.yandex.net.tmp2136807
14:03:53 unbound /etc/unbound/slave/db.yandex.net.tmp2136807
14:03:59 unbound /etc/unbound/slave/yandexcloud.net.tmp2136807Хорошо, какую-то случайную корреляцию я поймал. Пусть она не стабильна, но это хоть какой-то результат.
В atop/htop видно, что при записи файловой зоны тред, который этим занимается, на несколько секунд съедал всё процессорное ядро под 100%. А самая большая из этих зон занимает приблизительно 70 МБ на диске — на ней проблема проявляется ярче всего.
Для проверки я решил отключить auth-zone и заменить одну из них на local-zone, которые не пишутся на диск. Попробовал провести нагрузку запросами, ходящими только в эту local-zone. И каково было моё удивление, когда первый тест выдал мне желаемый результат, а следующий был даже хуже предыдущих — вздрыжни не прошли.
В этот момент я начал сомневаться во всех инструментах, и во всех предыдущих догадках. Постепенно я перешёл к дебагу Pandora. Спустя время я нашёл проблему в конфигурации и поправил плагин, чтобы он не разрешал указывать DNS имя в качестве target. Получается, что я ловил те самые вздрыжни, но со стороны плагина, который ходил в DNS. Нагрузочное тестирование в local-zone и auth-zone тоже показало желаемое — проблемы в local-zone нет, а в auth-zone есть.
Возвращаемся к дебагу auth-zone. У меня было чёткое совпадение небольшого фона таймаутов с моментом перезаписи файла файловой зоны.
15:38:59: open path: slave/db.yandex.net.tmp926625 # << сброс файловой
# зоны во временный файл,
# тут начинает гореть CPU у треда
7 2022-11-18T15:38:59 # << кол-во ошибок
32 2022-11-18T15:39:00
15:39:03: open path: slave/cloud.yandex.net.tmp926625
15:39:12: open path: slave/cloud.yandex.net.tmp926625
15:39:15: open path: slave/yandexcloud.net.tmp926625
15:39:19: open path: slave/cloud.yandex.net.tmp926625
15:39:21: open path: slave/db.yandex.net.tmp926625
2 2022-11-18T15:39:21
22 2022-11-18T15:39:22
3 2022-11-18T15:39:23
15:39:28: open path: slave/cloud.yandex.net.tmp926625
15:39:33: open path: slave/yandexcloud.net.tmp926625
15:39:37: open path: slave/db.yandex.net.tmp926625
29 2022-11-18T15:39:37
13 2022-11-18T15:39:38
Из кода я понял, какой callback-функцией Unbound отвечает пользователю: comm_point_udp_callback. Чтобы увидеть медленные ответы на запросы, достаточно замерить время работы её внутренней функции worker_handle_request.
Смотрим на её тайминги:
srv58:~$ sudo funclatency-bpfcc -u /usr/sbin/unbound-1.17.0-release:worker_handle_request -p 1953108
Tracing 1 functions for "/usr/sbin/unbound-1.17.0-release:worker_handle_request"... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 3 | |
2 -> 3 : 304 | |
4 -> 7 : 5630 |****** |
8 -> 15 : 35734 |****************************************|
16 -> 31 : 12844 |************** |
32 -> 63 : 1281 |* |
64 -> 127 : 215 | |
128 -> 255 : 53 | |
256 -> 511 : 46 | |
512 -> 1023 : 26 | |
1024 -> 2047 : 0 | |
2048 -> 4095 : 1 | |
Detaching...Все ответы выполняются в пределах одной миллисекунды — где же таймауты?
Вспоминаем, что Unbound использует разные виды callback-функций и для записи файловых зон используется функция auth_xfer_transfer_tcp_callback:
ns-load.name:~$ sudo bpftrace -e '
uprobe:/usr/sbin/unbound-1.17.0-release:auth_xfer_transfer_tcp_callback { @start[tid] = nsecs; }
uretprobe:/usr/sbin/unbound-1.17.0-release:auth_xfer_transfer_tcp_callback /@start[tid]/ { @ns[comm,pid] = hist((nsecs - @start[tid]) / 1e3); delete(@start[tid]); }'
Attaching 2 probes...
^C
@ns[unbound, 2020368]:
[64K, 128K) 4 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[128K, 256K) 6 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[256K, 512K) 3 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[512K, 1M) 0 | |
[1M, 2M) 0 | |
[2M, 4M) 2 |@@@@@@@@@@@@@@@@@ |
# K — миллисекунды, M — секундыВ выводе видно, что большинство вызовов функции auth_xfer_transfer_tcp_callbackвыполняется примерно за 256 миллисекунд — это относительно быстро. Но есть и такие, которые занимают по 4 секунды, и это очень долго.
Когда я снова вернулся к архитектуре и коду Unbound, выяснилось, что ответ пользователю comm_point_udp_callback с worker_handle_request внутри и auth_xfer_transfer_tcp_callback с auth_zone_write_file — это два разных callback, которые не могут одновременно работать в треде.
Вот как это работает. Когда Ядро Linux принимает udp/tcp-пакет, оно отправляет его в очередь на приём случайного треда из-за включенной опции SO_REUSEPORT. Затем libevent получает нотификацию и запускает callback, а другие udp/tcp пакеты в очереди этого треда ждут его выполнения. Поэтому важно, чтобы callback выполнялся быстро.
Я выяснил, что в случае auth_xfer_transfer_tcp_callback его тормозит auth_zone_write_file. Получается, что запросы ждут записи файловой зоны. При этом перемещение файловых зон в tmpfs не даёт желаемого эффекта, потому что основное время уходит на сериализацию и бесконечное множество вызовов write.
Посоветовавшись, мы вынесли запись файловых зон в отдельный тред, который ничем другим не будет заниматься. Мы подготовили патчи в наш локальный форк и в upstream PR#794 (правда, пока он требует доработки под все поддерживаемые платформы).
Продолжаем поиски ошибок
Как мы знаем, баги не приходят поодиночке, поэтому я приступил к поискам остальных. После очередного разбора инцидента c Unbound ребята из команды DNS добавили во внутренний инструмент автоматизации несколько функций:
автоматическое снятие дампа памяти процесса Unbound;
снятие стек трейсов по всем тредам (не через
thread apply all bt, а индивидуально для каждого треда);замер производительности perf утилитой;
сбор логов.
Всё, что оставалось — дождаться момента активации триггера на аномальное повышение Load Average системы и изучить всё собранное. А я продолжил заниматься лоад-стендом.
Немного спустя у нас появился дамп памяти, собранный при аномальном повышении Load Average, и тут начинается самое интересное. Первое, что бросилось в глаза при осмотре снятых stack trace — почти все треды висели на pthread_spin_lock. Unbound использует их в местах, где, по его мнению, будет очень быстрый доступ.
Для наглядности покажу, как это выглядело в coredump
gdb /usr/sbin/unbound
(gdb) core-file core_534009.gdb
warning: core file may not match specified executable file.
[New LWP 534009]
...
#0 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
[Current thread is 1 (Thread 0x7f8fa1557dc0 (LWP 534009))]
(gdb) info threads
Id Target Id Frame
* 1 Thread 0x7f8fa1557dc0 (LWP 534009) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
// тут много тредов относящиеся к yp_dns, нам они неинтересны
...
87 Thread 0x7f8f68f74700 (LWP 535239) 0x00007f8fa0d22d12 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
88 Thread 0x7f8f68773700 (LWP 535240) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
89 Thread 0x7f8f6715f700 (LWP 535241) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
90 Thread 0x7f8f6695e700 (LWP 535242) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
91 Thread 0x7f8f6615d700 (LWP 535243) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
92 Thread 0x7f8f650f3700 (LWP 535244) 0x0000000002fef501 in bin_find_entry (table=0x75b7fb42c80, bin=, hash=2852359060, key=0x75f1ab5cdd0) at /-S/contrib/tools/unbound/util/storage/lruhash.c:223
93 Thread 0x7f8f648f2700 (LWP 535245) 0x00007f8fa0d22d12 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
... // Все треды, висящие на pthread_spin_lock
104 Thread 0x7f8f5db8d700 (LWP 535256) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
105 Thread 0x7f8f5d38c700 (LWP 535257) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
... // Все треды, висящие на pthread_spin_lock
117 Thread 0x7f8f18385700 (LWP 535269) 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f8fa0d22d15 in pthread_spin_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x0000000002fef852 in lruhash_lookup (table=0x75b7fb42c80, hash=2948070628, key=key@entry=0x7fff134b2ae8, wr=wr@entry=0) at /-S/contrib/tools/unbound/util/storage/lruhash.c:362
#2 0x0000000002ff0dae in slabhash_lookup (sl=sl@entry=0x75b7f1a68c0, hash=2948070628, key=0x7fff134b2a01, key@entry=0x7fff134b2ae8, wr=wr@entry=0) at /-S/contrib/tools/unbound/util/storage/slabhash.c:125
#3 0x0000000002f849e6 in rrset_cache_lookup (r=0x75b7f1a68c0, qname=, qnamelen=, qtype=qtype@entry=1, qclass=qclass@entry=0, flags=flags@entry=0, timenow=1670937529, wr=0) at /-S/contrib/tools/unbound/services/cache/rrset.c:293
... // Остальное нам пока неинтересно.
(gdb) thread 92
[Switching to thread 92 (Thread 0x7f8f650f3700 (LWP 535244))]
#0 0x0000000002fef501 in bin_find_entry (table=0x75b7fb42c80, bin=, hash=2852359060, key=0x75f1ab5cdd0) at /-S/contrib/tools/unbound/util/storage/lruhash.c:223
223 /-S/contrib/tools/unbound/util/storage/lruhash.c: No such file or directory.
(gdb) bt
#0 0x0000000002fef501 in bin_find_entry (table=0x75b7fb42c80, bin=, hash=2852359060, key=0x75f1ab5cdd0) at /-S/contrib/tools/unbound/util/storage/lruhash.c:223
#1 lruhash_insert (table=0x75b7fb42c80, hash=hash@entry=2852359060, entry=entry@entry=0x75f1ab5cdd0, data=0x75f31a7f4e0, cb_arg=cb_arg@entry=0x75b60f3c088) at /-S/contrib/tools/unbound/util/storage/lruhash.c:320
#2 0x0000000002ff0d8e in slabhash_insert (sl=sl@entry=0x75b7f1a68c0, hash=448122320, hash@entry=2852359060, entry=0x75f30e5e366, entry@entry=0x75f1ab5cdd0, data=0x75f31a7f4e0, arg=arg@entry=0x75b60f3c088) at /-S/contrib/tools/unbound/util/storage/slabhash.c:119
#3 0x0000000002f84685 in rrset_cache_update (r=0x75b7f1a68c0, ref=ref@entry=0x7f8f650f0d60, alloc=0x75b60f3c088, timenow=1670937529) at /-S/contrib/tools/unbound/services/cache/rrset.c:227
... Итак, я обнаружил два узких места: выполнение bin_find_entry и ожидание лока в функции lruhash_lookup.
Снова про архитектуру — кэши
Я вновь погрузился в изучение кода — на этот раз в архитектуру кэшей. В Unbound есть самописная concurrent hash map для хранения кэшей запросов. Это структура в lruhash.h#L147, которая выглядит вот так:
struct lruhash {
lock_quick_type lock; /** lock for exclusive access, to the lookup array */
struct lruhash_bin* array; /** lookup array of bins */
size_t num; /** the number of entries in the hash table. */
size_t size; /** the size of the lookup array */
size_t space_used; /** the amount of space used, roughly the number of bytes in use. */
size_t space_max; /** the amount of space the hash table is maximally allowed to use. */
// ... я оставил только полезные нам поля
};Внутри lruhash хранится массив бинов, в которые и помещаются записи кэш запросов — классическая хэш-таблица с linked list. Один lruhash_bin (для краткости просто BIN) выглядит так:
struct lruhash_bin {
lock_quick_type lock; /* Lock for exclusive access to the linked list */
struct lruhash_entry* overflow_list; /* linked list of overflow entries */
};lruhash_entry (для краткости просто ENTRY) — это запись нашего запроса в кэше. В детали тут можно не вдаваться.
Доступ к разным lruhash выполняется без локов. Все lruhash спрятаны внутри slabhash. Хэш мап — фиксированного размера и работает только на чтение. slabhash-структура в slabhash.h#L57 выглядит вот так:
struct slabhash {
// Просто предаллоцированный массив lruhash,
// доступ к которым идёт по кусочку от хэша данных из запроса/ответа
struct lruhash** array; /** lookup array of hash tables */
// это используется для адресации
size_t size; /** the size of the array - must be power of 2 */
uint32_t mask; /** size bitmask - uses high bits. */
unsigned int shift; /** shift right this many bits to get index into array. */
};Любимые самописные хэш таблицы с такими любимыми багами и фичами! Ниже я попытался схематично изобразить структуру slabhash:
,- Доступ по этому индексу выполняется без локов,
/ потому что этот массив фиксированного размера, заданного на старте,
/ а индекс используется только для чтения массива.
/
slabhash->array[-size]
,------ Для доступа по этому индексу уже используется spin_lock(*1), потому-что
/ этот массив может быть реаллоцирован и это операция на запись. Для экономии
[0]lruhash->array [...] места на старте процесса этот массив маленького размера — всего 1024.
Когда массив заполняется (lruhash->num >= lruhash->size) он реаллоцируется
по мере заполнения кэша. Например, для 10G, этот размер может вырасти до
1048576. А это значит, что после очередной реаллокации придётся
скопировать по новому массиву 1048576/2 BIN-ов из старого.
Эта операция не требует перевычисления хэша или вызова `strcmp`.
Её сложность О(N) от размера массива, но делается она под локом!
[1]lruhash->array [BIN, BIN, BIN, BIN, _, ...] - массив, реаллоцируемый при необходимости.
[2]... 8 8 8 \
8 8 ` - на BIN тоже берётся spin_lock (*2)
8
[3]... `- linked-list из ENTRY, используется для разрешения коллизий в нижней части хэша,
[4]... которая нужна для адресации внутри `lruhash->array`.
Unbound, как и все хэш таблицы, старается держать по одному элементу в бине,
но хэш функция, как правило, даёт коллизии,
и в бине хранится от 0 до 13 entry (выяснено на практике).
Для изменения ENTRY защищены (*3)mutex-ом.
Размер linked-list ограничен по следующей формуле:
CACHE-SIZE / -SLABS / len(LRUHASH->ARRAY.)
Видно, что это значение контролируется на старте через количество
-SLABS(параметр в конфигурации), а дальше — в runtime через длину
len(LRUHASH-ARRAY) после каждой реаллокации.
[5]...
[6]lruhash->array
[7]lruhash->array [...] Для уменьшения lock contention (то есть попыток захватить уже захваченный другим тредом лок) используется slabhash->array — глобальный lock-free объект. Каждый отдельный lruhash->array — это тоже глобальный объект и все треды работают с ним конкурентно. Но каждый lruhash работает со своим набором локов. То есть два lruhash могут работать параллельно на двух тредах, не блокируя друг друга.
Немного подробностей про способ адресации в этих структурах. Допустим, есть некий хэш 1234567890. В зависимости от количества выбранных слабов Unbound выбирает mask и shift. Это нужно, чтобы определять, в какой lruhash и bin попадает запись. Условно, для размера 32 Unbound делит хэш примерно так:
, - Верхняя часть хэша берётся для адресации внутри slabhash->array[N] — то есть, между слабами.
/ ,- Нижняя часть хэша урезается по текущему размеру LRU и определяет
/ / индекс в lruhash->array, в какой bin попадёт entry.
12 | 34567890
\
` - Формируется так: битовая маска, рассчитанная на основе размера slabhash->array
(hash & 0b11111000000000000000000000000000) >> shift (на количество нулей в маске)Слабы защищены набором локов: pthread_spin_lock для slab->array->lock / bin->lock и pthread rw lockна entry->lock.
Итак, при большом количестве SLABS (lruhash-таблиц внутри slabhash->array) поток запросов будет меньше блокироваться, потому что в разные lruhash запросы пройдут без лока. А это значит, что на каждый lruhash придётся меньше запросов в единицу времени, и lock contention на *1-spin → *2-spin → *3-mutex в lruhash->array будет меньше.
| | | | | | | | | | | | | | | |
slabhash [ -size ]
| | | | | | | | | | | | | | | |
| | | | | | | | | | | | ...
\/ | | | | | | | | | |
[1]lruhash->array \/ | | | | | |
[2]lruhash->array \/ | | | |
[3]lruhash->array | | ...
... А для малого количества SLABS больше запросов будут утекать в один lruhash, увеличивая lock contention на его spinlock.
| | | | | | | | | | | | | | | |
\| | | | | | | | | | | | | |/
\| | | | | | | | | | | |/
\| | | | | | | | | |/
\| | | | | | | |/
\| | | | | |/
\| | | |/
slabhash [size]
||| |||
[1]lruhash->array |||
[2]lruhash->array ...
`- напомню, что тут spin_lockКонечно, минусы у больших значений SLABS тоже есть. Они заключаются в размере кэша на старте, и, как показала практика, в накладных расходах на сбор статистики слабов. При большом значении SLABS Unbound должен на старте аллоцировать огромный массив slabhash->array и создать кучу lruhash->array, у каждого из которых есть стартовый размер 1024. Но этот минус даёт и плюс: из-за большого размера slabhash->array каждый linked-list внутри lruhash->array[BIN] ограничен формулой, которую я привёл на диаграмме. То есть, вот такого не произойдёт:
entry->entry->entry->entry-> x278555 entry->entry->entry->entry->entry->...Поиск по такому linked-list требует для каждого entry->dname вызывать strcmp.
Каждый запрос проходит через кэш как минимум один раз, при этом локи на кэш берутся многократно. Unbound местами слишком оптимистично берёт лок на lruhash→array на всю операцию c ENTRY внутри BIN и порой не отпускает его очень долго. Другими словами: поле для ускорения Unbound всё ещё есть!
Почему важно чаще отпускать лок? Дело в том, что хоть Unbound и старается держать в бинах по одному элементу, иногда случается коллизия хэш-функции и в бин может попасть несколько элементов. Для поиска элемента в бине используется самописный strcmp [slabhash.c#L50]→[daemon.c#L991]→[msgreply.c#L623]→[dname.c#L100], который находится очень далеко в плане скорости от spinlock.
В какой-то из книжек по Linux я читал, что нормальное использование спинлока — это защититься для взятия указателя, и не более. Потом я нашёл замечательную статью spinlock vs mutex performance, которая подтвердила мои догадки, описанные ниже.
Итак, пока выполняется сравнение строк DNS записей для поиска нужного элемента, в BIN все треды ждут на spin_lock lruhash->array, где находится данный BIN. Если вдруг linked-list из ENTRY в нём длиннее десяти записей, все треды ждут ощутимый промежуток времени и здорово греют воздух. На этом этапе должно быть очевидно, что больше слабов — хорошее решение.
На этом же этапе можно возразить: «Да ладно, обход коллизии даже в 1000 элементов не должен взрывать Unbound так, чтобы вызвать отказ в обслуживании. Греть воздух будет здорово, но не взрывать».
И тут я спешу напомнить про реаллокацию [lruhash.c#L338]→[lruhash.c#L231]→[lruhash.c#L117]. Особенность реализации lruhash->array такова, что какой бы большой кэш мы не выбрали, на старте у него будет размер 1024 элементов HASH_DEFAULT_STARTARRAY. Когда этот массив заполняется, Unbound аллоцирует новый массив в два раза большего размера и копирует под spinlock старый массив в новый. Теперь точно не должно быть возражений :)
Как действуют SLABS
Предыдущая часть была немного утомительной — настало время размяться. Берём наши текущие настройки:
msg-cache-size: 4G # В проде замечено 14 - 16 М записей
msg-cache-slabs: 32 # По рекомендации из официальной докиПолучаем, что у нас в одном lruhash->array может быть 14М / 32 = 437500 элементов. Доступ до элемента slabhash->array[hash(левая часть хэша) % modulo]->lruhash->array[hash(правая часть хэша) % modulo]везде идёт по смещению — кажется, тут нечему тупить. Вспоминаем, что под локом ещё выполняется strcmp.
Дальше представляем, что есть не одна коллизия и есть бины больше одного элемента. В итоге получаем, увеличенный фон LA. Проверяем эту теорию. Ставим четыре слаба, чтобы стало заметнее, берём примерно 900к уникальных записей, добавляем 60% попадания в кэш.
awk -v cache=dns-30k.ammo '
{
print; n=0;
while(n < 2){
ret=getline < cache;
if (!ret){close(cache);}else{n++; print;}
}
}' < dns.ammo > dns-870k+60prc-hits.ammoЗапускаем тестирование постоянной нагрузкой в 5Krps. Видим, что реаллокации портят тайминги.
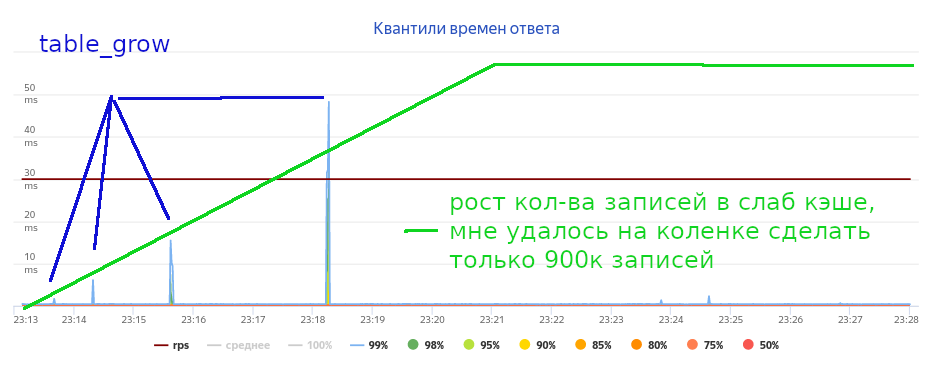
Зелёным отмечен рост кэша.
Если взять msg-cache-slabs: 1024, то каждый слаб будет содержать примерно по 10к сообщений размером 512 байт. Это сильно сокращает накладные расходы на реаллокацию и поиск в случае коллизий.
Перезапускаем Unbound, подаём ту же нагрузку — и теперь не страшно посмотреть даже на 100-ый перцентиль ответов.
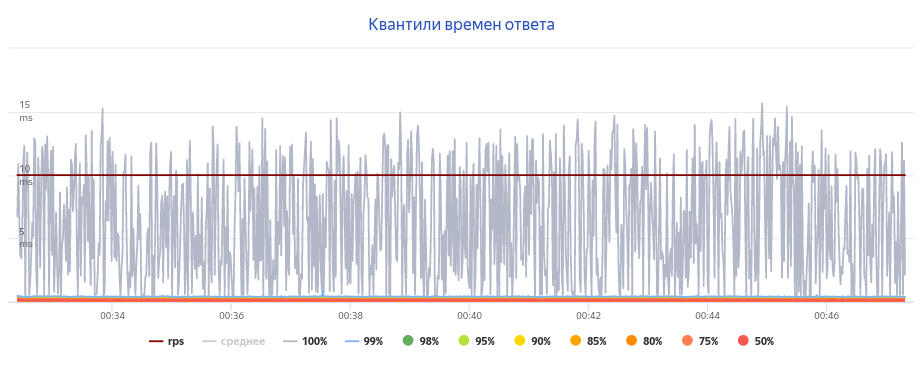
Тайминги при msg-cache-slabs: 1024
Казалось, вот она — победа! Правильные настройки найдены, дальше только патчить Unbound — то есть ювелирно отпускать лок на lruhash->array во всех местах, где это возможно, в том числе при реаллокации массива.
Больше доказательств!
А вот ещё замеры моментов сработки table_growчерез bpftrace и её тайминги. Тут представлены времена реаллокаций:
ns-load.name:~$ sudo bpftrace -e '
BEGIN { printf("%s GO go go!\n", strftime("%H:%M:%S", nsecs)); } uprobe:/usr/sbin/unbound-1.17.0-release-threaded-zone-write:table_grow {printf("%s Oops! table_grow!\n", strftime("%H:%M:%S", nsecs)); }'
Attaching 2 probes...
11:11:29 GO go go!
11:11:48 Oops! table_grow!
11:11:48 Oops! table_grow!
11:11:48 Oops! table_grow!
11:11:48 Oops! table_grow!
11:11:48 Oops! table_grow!
11:11:48 Oops! table_grow!
11:11:48 Oops! table_grow!
11:11:48 Oops! table_grow!
11:11:50 Oops! table_grow!
11:11:50 Oops! table_grow!
11:11:50 Oops! table_grow!
11:11:50 Oops! table_grow!
…А тут — тайминги работы table_grow (всего на 900к записях, это далеко не 18М):
ns-load.name:~$ sudo bpftrace -e '
uprobe:/usr/sbin/unbound-1.17.0-release-threaded-zone-write:table_grow { @start[tid] = nsecs; } uretprobe:/usr/sbin/unbound-1.17.0-release-threaded-zone-write:table_grow /@start[tid]/ { @ns[pid] = hist((nsecs - @start[tid]) / 1e6); delete(@start[tid]); }'
Attaching 2 probes...
^C
@ns[3540330]:
[0] 8 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[1] 5 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[2, 4) 3 |@@@@@@@@@@@@@@@@@@@ |
[4, 8) 6 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 2 |@@@@@@@@@@@@@ |
[16, 32) 4 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 64) 4 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[64, 128) 4 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
# | `- Количество вызовов. По нему можно судить о том,
# | что растут msg-, rrset- и ещё какие-то слабы
# `- Миллисекунды!
# 128 миллисекунд!
# Все CPU, которые захотели в реаллоцируемый слаб,
# ждали на spinlock до 128 миллисекунд!Это всё подтверждает flamegraph. Ниже представлен итог, собранный инструментом автоматизации, вместе с интересным coredump.

Обратите внимание на процент времени CPU, который занимают подсвеченные функции (правый нижний угол Matched)

А вот flamegraph под нагрузкой с малым значением msg-cache-slabs. Всего 4Krps, но в gdb и perf уже видно контеншен на лок

И flamegraph под нагрузкой с большим значением msg-cache-slabs. Картинка улучшается почти в два раза: при больших rps и большем наполнении кэша разница будет ещё больше не в пользу slabs: 32
Мы сразу решили проверить всё это на практике и выкатили настройку на проблемный хост.
Самый говорящий график — это, конечно же, LA. Я думаю, ни у кого не будет сомнений, что эффект очевиден.
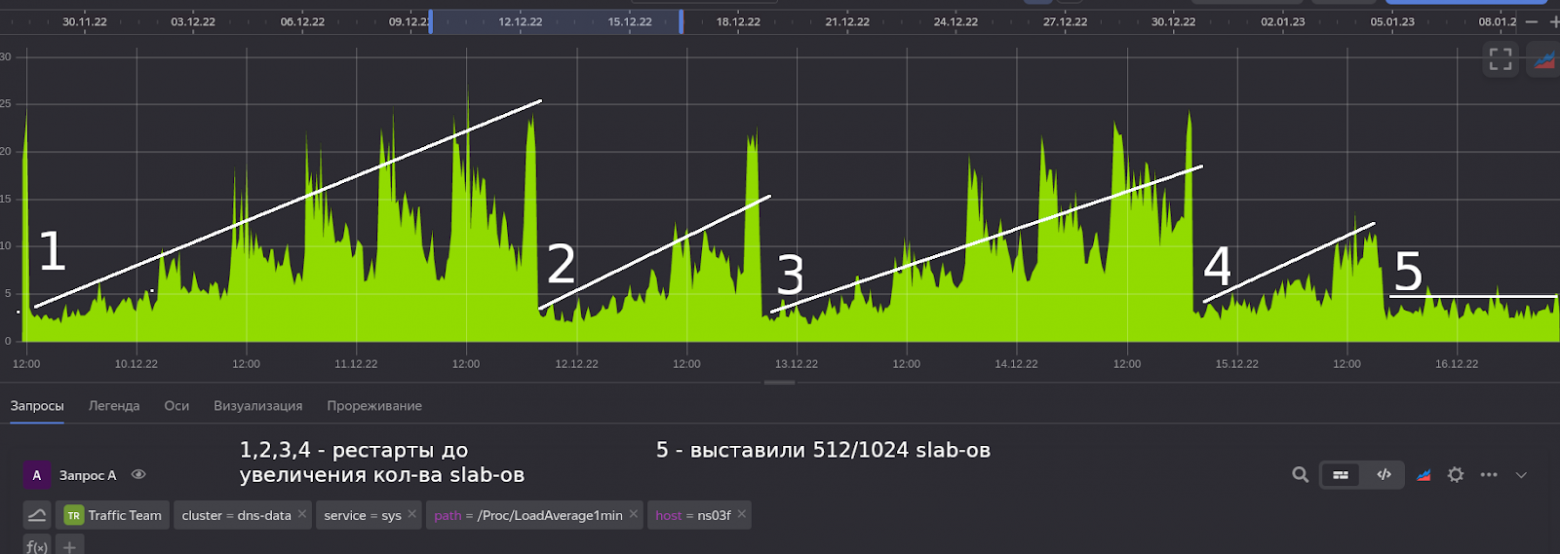
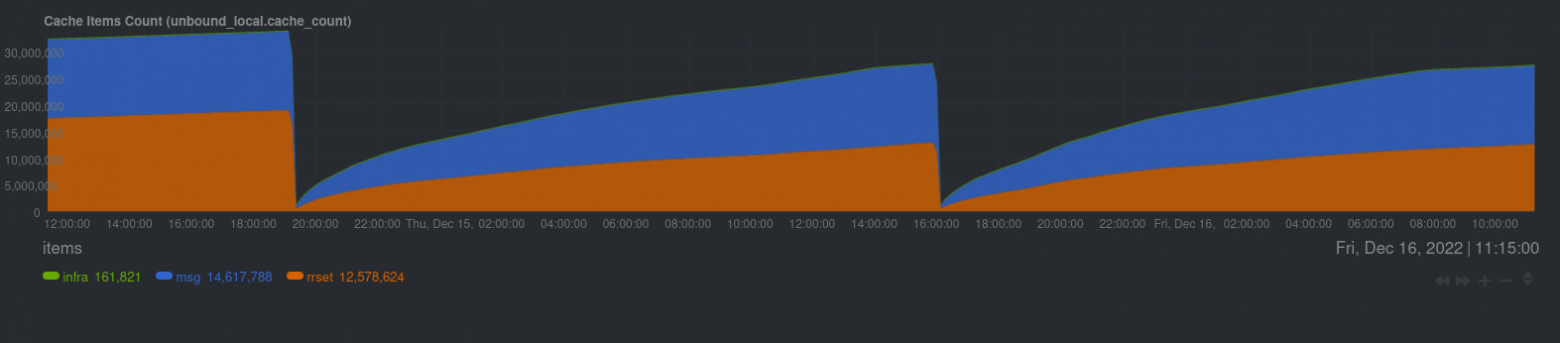
Дальше я покажу скрины netdata про последние два рестарта: первый до увеличения количества слабов, второй — после.




Суровая реальность: сколько rps убивает Unbound
И на этом моменте читатель может задаться вопросом: «Но ведь тут такая интересная корка! Почему о ней ничего нет?» Настало время рассказать и про неё. Coredump здесь и правда очень интересный. Прежде всего тем, что в нём можно покопаться и увидеть реальную картину происходящего.
Итак, параллельно с изучением кода и проведением нагрузочных тестов я занимался изучением дампа памяти процесса. Напомню, что Unbound пытается держать размеры бинов равными единице и это условие успеха: тогда лок на lruhash->array всегда будет браться и отпускаться моментально, кроме случая table_grow.
С помощью coredump можно оценить, насколько долго будет держаться лок взятый на lruhash->array, исследуя размеры бинов. Чтобы выяснить, насколько Unbound удаётся выполнить условие «один бин — одна запись», нужно взять корку с плохой ноды (у нас как раз такая есть) и посмотреть на реальные размеры бинов. Но возникает вопрос — как?
Я знал, что в gdb есть поддержка Python. Пишем простенький скрипт gdb_traverse.py.
Код скрипта gdb_traverse.py
import gdb
class TraverseNodesPrinter(gdb.Command):
"""Prints the ListNode from our example in a nice format!"""
def __init__(self):
super(TraverseNodesPrinter, self).__init__("walklist", gdb.COMMAND_USER)
def invoke(self, args, from_tty):
# You can pass args here so this routine could actually evaluate different
# variables at runtime
print("Args Passed: %s" % args)
# Let's walk through the list starting with the head
#
# We can access value info by looking at:
# https://sourceware.org/gdb/onlinedocs/gdb/Values-From-Inferior.html#Values-From-Inferior
argv = args.split()
ref = argv.pop(0)
silent = bool(argv)
slab_ptr = gdb.parse_and_eval(ref)
slab_size = slab_ptr["size"]
print("slab_size=%s" % slab_size)
total = {}
for si in range(slab_size):
slab_max = 0
percent_max = 0
count = 0
node_ptr = slab_ptr["array"] + si
array = node_ptr["array"]
size = int(node_ptr["size"])
next_prc = 10
if not silent:
print("slab-%s" % si)
most_overloaded_bin = 0
mob_prc = 0
for i in range(size):
elem = array + i
if elem == 0:
continue
overflow_list = elem["overflow_list"]
local_max = 0
while overflow_list != 0:
local_max += 1
overflow_list = overflow_list["overflow_next"]
if local_max > slab_max:
slab_max = local_max
most_overloaded_bin = i
if local_max > percent_max:
percent_max = local_max
mob_prc = i
count += local_max
prc = float(i) / size * 100
if prc > next_prc:
next_prc = prc + 10 # every N%
if not silent:
print("%s prc current max bin(%s).length %s count %s" % (int(prc), mob_prc, percent_max, count))
percent_max = 0
total[si] = (most_overloaded_bin, slab_max, count)
if not silent:
print("100 prc max bin(%s).length %s, count %s nodes" % (most_overloaded_bin, slab_max, count))
print("")
total_sum = 0
global_max = 0
for si in total:
most_overloaded_bin, slab_max, count = total[si]
total_sum += count
global_max = max(slab_max, global_max)
if not silent:
print("slab-%s max bin(%s).length %s count %s" % (si, most_overloaded_bin, slab_max, count))
print("Found total-max bin.length %s, total=%s nodes" % (global_max, total_sum))
TraverseNodesPrinter()Загружаем gdb и корку — удачно оказываемся в треде почти в нужном нам контексте (но это сыграет с нами злую шутку).
Вот, что получаем в итоге
$ gdb unbound-1.17.0-r10415458-spinlock
...
Reading symbols from unbound-1.17.0-r10415458-spinlock...
...
(gdb) core core_534009.gdb
warning: core file may not match specified executable file.
[New LWP 534009]
[New LWP 534066]
...
(gdb) bt
#0 0x00007f8fa0d22d15 in ?? ()
#1 0x0000000002fef852 in lruhash_lookup (table=0x75b7fb42c80, hash=2948070628,
key=key@entry=0x7fff134b2ae8, wr=wr@entry=0)
at /-S/contrib/tools/unbound/util/storage/lruhash.c:362
#2 0x0000000002ff0dae in slabhash_lookup (sl=sl@entry=0x75b7f1a68c0, hash=2948070628, <<<<< нам нужно сюда
key=0x7fff134b2a01, key@entry=0x7fff134b2ae8, wr=wr@entry=0)
... # остальное можно опустить
(gdb) up 2
#2 0x0000000002ff0dae in slabhash_lookup (sl=sl@entry=0x75b7f1a68c0, hash=2948070628,
key=0x7fff134b2a01, key@entry=0x7fff134b2ae8, wr=wr@entry=0)
at /-S/contrib/tools/unbound/util/storage/slabhash.c:125
125 return lruhash_lookup(sl->array[slab_idx(sl, hash)], hash, key, wr);
(gdb) print *sl
$2 = {size = 32, mask = 4160749568, shift = 27, array = 0x75b7f980200}
# ОК, видим 32 слаба и массив слабов
# array тут — это slabhash->array[32]
...
# один lruhash внутри slabhash->array выглядит так
(gdb) print *sl->array[0]
$6 = {lock = 1, sizefunc = 0x2fdf9c0 ,
compfunc = 0x2fdfa10 , delkeyfunc = 0x2fdfa90 ,
deldatafunc = 0x2fdfad0 , markdelfunc = 0x2f843c0 ,
cb_arg = 0x75b7f340078, size = 524288, size_mask = 524287, array = 0x75e00800000,
lru_start = 0x75b4c0c19e0, lru_end = 0x75c9c818ff0, num = 424038, space_used = 145144085,
space_max = 268435456}
# один bin выглядит так
(gdb) print sl->array[0]->array[0]
$7 = {lock = 1, overflow_list = 0x75e5da92e10}
# Загружаем наш чудо-инструмент и запускаем его
(gdb) source gdb_traverse.py
(gdb) set pagination off
(gdb) walklist sl
# без silent-режима для большого количества слабов этот инструмент
# напечатает очень много текста, поэтому я сократил вывод
# ,- N номер слаба в slabhash->array[N]
# / , - M номер бина в slabhash->array[0](lruhash)->array[M]->lruhash_bin
# | / ,- размер linked-list у lruhash_bin->overflow_list
slab-0 max bin(309871).length 2748 count 424038 # <- сколько всего записей в этом lruhash
slab-1 max bin(436426).length 164 count 421672
slab-2 max bin(329311).length 18 count 420069
slab-3 max bin(261246).length 8 count 420491
slab-4 max bin(280420).length 33 count 421381
slab-5 max bin(285169).length 905 count 422057
slab-6 max bin(346884).length 6621 count 428844
slab-7 max bin(149391).length 44 count 420415
slab-8 max bin(475314).length 64 count 420950
slab-9 max bin(271580).length 25 count 419529
slab-10 max bin(372061).length 13 count 419983
slab-11 max bin(156506).length 50 count 421106
slab-12 max bin(65704).length 10 count 421407
slab-13 max bin(405913).length 31 count 421779
slab-14 max bin(182546).length 1383 count 422440
slab-15 max bin(51181).length 8 count 420793
slab-16 max bin(305677).length 10 count 420843
slab-17 max bin(229787).length 278 count 420631
slab-18 max bin(383134).length 98 count 420769
slab-19 max bin(278627).length 17 count 419738
slab-20 max bin(243904).length 59 count 421958
slab-21 max bin(232340).length 278555 count 707175
slab-22 max bin(108784).length 30 count 420950
slab-23 max bin(378505).length 190 count 420991
slab-24 max bin(244475).length 78 count 421245
slab-25 max bin(158331).length 8 count 421249
slab-26 max bin(294639).length 8 count 421501
slab-27 max bin(151957).length 13 count 421052
slab-28 max bin(362737).length 64837 count 486955
slab-29 max bin(344255).length 3920 count 424799
slab-30 max bin(399645).length 223 count 422094
slab-31 max bin(419568).length 127725 count 548963
Found total-max bin.length 278555, total=13967867 nodes
# | `- сколько всего записей в данном слаб
# | -кэше (slabhash)
# `- самый большой список linked-list, найденный среди всех бинов Согласитесь, что с первого взгляда и даже со второго totalнам явно показывает, что хэш-функция Unbound, мягко говоря, ненормальная.
Found total-max bin.length 278555, total=13967867 nodesОна даёт жуткие перекосы на некоторые бины. Из-за таких перекосов обращение в бин с большим linked-list тормозит все треды на жгучем spinlock. Это и заставляет Unbound в агонии просить помощи через алерты на load-average системы. А взрываться оно начинает тогда, когда все жирные слабы (даже в небольшом количестве) насыщаются одновременно и начинают триггерить table_grow.
Эта корка как раз ловит такой момент: у большинства тредов по ~420631 записей в слабах, а это очень близко к следующему table_grow.
Рассчитать моменты реаллокации можно так.
# lruhash->array должен иметь размер степени двойки
# при этом стартовый размер у него 1024
1024*2^9 = 524288 -> 1024*2^10 = 1048576A некоторые lruhash->array его уже перевалили: у слаба slab-21 — 548963 записей. Вангую, что на десятом реаллокейте вообще всё умрёт :)
Важно: быстрое предположение и неудачное совпадение может повести вас по ложному пути и в итоге привести к ложным выводам. Будьте внимательны и осторожны! Мне повезло, потому что вовремя пришёл коллега с очень интересными примерами запросов, но об этом ниже.
По логике хэш-функцию Unbound надо бы выкинуть и вставить туда какой-нибудь xxhash или whyhash. Либо использовать вариант для бедных: жить с большим количеством мелких слабов.
При маленьких слабах по 8 мб по моим (как выяснилось позже не совсем точным) расчётам в один BIN->linked-list не должно налиться больше 20к записей. Это значит, что даже при очень аномальном поведении хэш функции Unbound, обойти один бин в 20к записей в разы легче, чем один бин в 278k записей.
Жаль, что Unbound между слабами раскидывается той же кривой хэш-функцией slabhash.c#L111→dname.c#L287→lookup3.c#L346. Но делает он это по перво
