Загубить производительность
Эта заметка является писанной версией моего доклада «Как загубить производительность с помощью неэффективного кода» с конференции JPoint 2018. Посмотреть видео и слайды можно на странице конференции. В расписании доклад отмечен обидным стаканчиком смузи, так что ничего сверхсложного не будет, это скорее для начинающих.
Предмет доклада:
- как смотреть на код, чтобы найти в нём узкие места
- распространённые антипаттерны
- неочевидные грабли
- обход граблей
В кулуарах мне указали на некоторые неточности/упущения в докладе, они здесь отмечены. Замечания также приветствуются.
Влияние порядка исполнения на производительность
Есть класс пользователя:
class User {
String name;
int age;
}
Нам нужно сравнивать объекты между собой, поэтому объявим методы equals и hashCode:
import lombok.EqualsAndHashCode;
@EqualsAndHashCode
class User {
String name;
int age;
}
Код работоспособен, вопрос в другом: будет ли производительность данного кода наилучшей? Чтобы ответить на него давайте вспомним об особенности метода Object::equals: он возвращает положительный результат лишь тогда, когда все сравниваемые поля равны, в противном же случае результат будет отрицательным. Иными словами, одного отличия уже достаточно для отрицательного результата.
Посмотрев код, создаваемый для @EqualsAndHashCode увидим примерно вот это:
public boolean equals(Object that) {
//...
if (name == null && that.name != null) {
return false;
}
if (name != null && !name.equals(that.name)) {
return false;
}
return age == that.age;
}
Порядок проверки полей соответствует порядку их объявления, что в нашем случае не лучшее решение, ведь сравнение объектов с помощью equals «тяжелее» сравнения простых типов.
Хорошо, попробуем создать методы equals/hashCode с помощью «Идеи»:
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
User that = (User) o;
return age == that.age && Objects.equals(name, that.name);
}
«Идея» создаёт более умный код, который знает о сложности сравнения разных видов данных. Ну хорошо, мы выбросим @EqualsAndHashCode и будем явно прописывать equals/hashCode. Теперь посмотрим, что происходит при расширении класса:
class User {
List props;
String name;
int age;
}
Пересоздадим equals/hashCode:
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
User that = (User) o;
return age == that.age
&& Objects.equals(props, that.props) // <----
&& Objects.equals(name, that.name);
}
Сравнение списков выполняется до сравнения строк, что бессмысленно, когда строки разные. На первый взгляд, особой разницы нет, ведь строки равной длины сравниваются познаково (т. е. время сравнение растёт вместе с длиной строки):
Метод java.lang.String::equals интринзифицирован, поэтому познакового сравнения при исполнении не происходит.
//java.lang.String
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) { // <----
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
Теперь рассмотрим сравнение двух ArrayList-ов (как наиболее часто используемой реализации списка). Исследовав ArrayList с удивлением обнаружим, что собственной реализации equals у него нет, а используется унаследованная реализация:
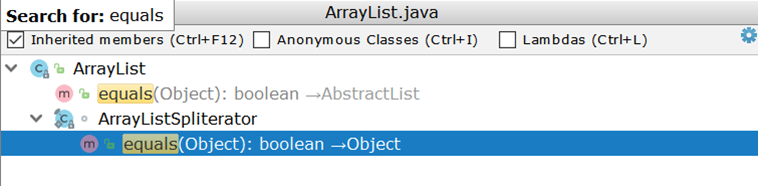
//AbstractList::equals
public boolean equals(Object o) {
if (o == this) {
return true;
}
if (!(o instanceof List)) {
return false;
}
ListIterator e1 = listIterator();
ListIterator e2 = ((List) o).listIterator();
while (e1.hasNext() && e2.hasNext()) { // <----
E o1 = e1.next();
Object o2 = e2.next();
if (!(o1 == null ? o2 == null : o1.equals(o2))) {
return false;
}
}
return !(e1.hasNext() || e2.hasNext());
}
Важным здесь является создание двух итераторов и попарный проход по ним. Предположим, есть два ArrayList-а:
- в одном числа от 1 до 99
- во втором числа от 1 до 100
В идеале было бы достаточно сравнить размеры двух списков и при несовпадении сразу вернуть отрицательный результат (как это делает AbstractSet), в действительности же выполнится 99 сравнений и лишь на сотом станет понятно, что списки отличаются.
Чё там у котлиновцев?
data class User(val name: String, val age: Int);
Тут всё как у ломбока — порядок сравнения соответствует порядку объявления:
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o instanceof User) {
User u = (User) o;
if (Intrinsics.areEqual(name, u.name) && age == u.age) { // <----
return true;
}
}
return false;
}
В качестве обхода можно вручную упорядочивать объявления полей.
Усложним задачу
void check(Dto dto) {
SomeEntity entity = jpaRepository.findOne(dto.getId());
boolean valid = dto.isValid();
if (valid && entity.hasGoodRating()) { // <----
//do smth
}
}
Код предполагает обращение к БД даже тогда, когда итог проверки отмеченного стрелкой условия заранее предсказуем. Если значение переменной valid ложно, то код в блоке if никогда не выполнится, а значит можно обойтись без запроса:
void check(Dto dto) {
boolean valid = dto.isValid();
if (valid && hasGoodRating(dto)) {
//do smth
}
}
// отложенное исполнение можно построить и на предикате, это дело вкуса
boolean hasGoodRating(Dto dto) {
SomeEntity entity = jpaRepository.findOne(dto.getId());
return entity.hasGoodRating();
}
Проседание может быть незначительным, когда возвращаемая из JpaRepository::findOne сущность уже находится в кэше первого уровня, — тогда запроса не будет.
Похожий пример без явного ветвления:
boolean checkChild(Dto dto) {
Long id = dto.getId();
Entity entity = jpaRepository.findOne(id);
return dto.isValid() && entity.hasChild();
}
Быстрый возврат позволяет отложить запрос:
boolean checkChild(Dto dto) {
if (!dto.isValid()) {
return false;
}
return jpaRepository.findOne(dto.getId()).hasChild();
}
Представьте, что некая проверка использует подобную сущность:
@Entity
class ParentEntity {
@ManyToOne(fetch = LAZY)
@JoinColumn(name = "CHILD_ID")
private ChildEntity child;
@Enumerated(EnumType.String)
private SomeType type;
Если проверка использует одну и ту же сущность, то стоит позаботится о том, чтобы обращение к «ленивым» дочерним сущностям/коллекциям выполнялось после обращения к полям, которые уже загружены. На первый взгляд один дополнительный запрос не окажет значительного влияния на общую картину, но всё может изменится при выполнении действия в цикле.
Вывод: цепочки действий/проверок стоит упорядочивать в порядке возрастания сложности отдельных операций, возможно часть из них выполнять не придётся.
Циклы и массовая обработка
Следующий пример в особых пояснениях не нуждается:
@Transactional
void enrollStudents(Set ids) {
for (Long id : ids) {
Student student = jpaRepository.findOne(id); // <---- O(n)
enroll(student);
}
}
Из-за множественных запросов к БД код работает медленно.
Производительность может просесть ещё сильнее, если метод enrollStudents исполняется вне транзакции: тогда каждый вызов o.s.d.j.r.JpaRepository::findOne будет выполнятся в новой транзакции (см. SimpleJpaRepository), что означает получение и возврат соединения с БД, а также создание и сброс кэша первого уровня.
Исправим:
@Transactional
void enrollStudents(Set ids) {
if (ids.isEmpty()) {
return;
}
for (Student student : jpaRepository.findAll(ids)) {
enroll(student);
}
}
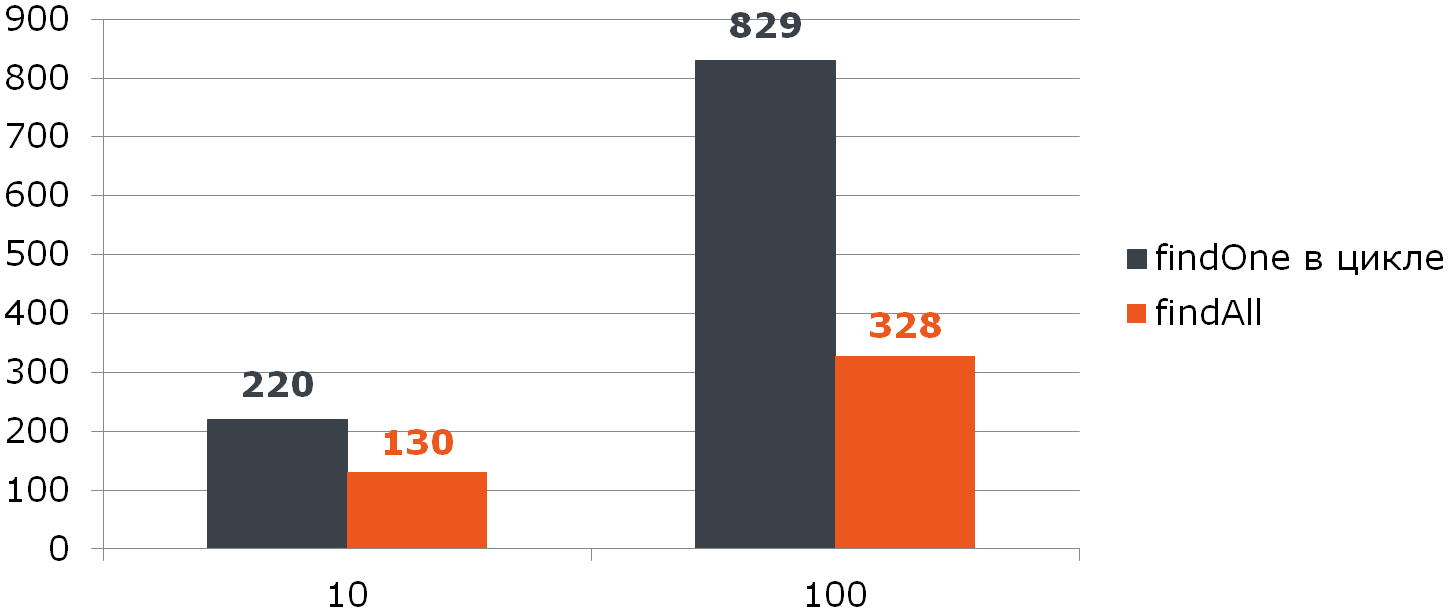
Бенчмарк
Если вы используете Oracle и передаёте более 1000 ключей в findAll, то вы получите исключение ORA-01795: maximum number of expressions in a list is 1000.
Также выполнения тяжелого (со множеством ключей) in-запроса может оказаться хуже, чем n запросов. Тут всё сильно зависит от конкретного приложения, поэтому механическое замена цикла на массовую обработку может ухудшить производительность.
Более сложный пример на ту же тему
for (Long id : ids) {
Region region = jpaRepository.findOne(id);
if (region == null) { // <---- затруднение
region = new Region();
region.setId(id);
}
use(region);
}
В данном случае мы не можем заменить цикл на JpaRepository::findAll, т. к. это сломает логику: все значения полученные из JpaRepository::findAll будут не null и блок if не отработает.
Разрешить это затруднение нам поможет то обстоятельство, что для каждого ключа БД
возвращает либо действительное значение, либо его отсутствие. Т. е. в некотором смысле БД — это словарь. Ява из коробки даёт нам готовую реализацию словаря — HashMap — поверх которой мы и построим логику подмены БД:
Map regionMap = jpaRepository.findAll(ids)
.stream()
.collect(Collectors.toMap(Region::getId, Function.identity()));
for (Long id : ids) {
Region region = map.get(id);
if (region == null) {
region = new Region();
region.setId(id);
}
use(region);
}
Пример в обратную сторону
// class Saver
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void save(List entities) {
jpaRepository.save(entities);
}
Этот код всегда создаёт новую транзакцию для сохранения списка сущностей. Проседание начинается при множественных вызовах метода, открывающего новую транзакцию:
// другой класс
@Transactional
public void audit(List inserts) {
inserts.map(this::toEntities).forEach(saver::save); // <----
}
// class Saver
@Transactional(propagation = Propagation.REQUIRES_NEW) // <----
public void save(List entities) {
jpaRepository.save(entities);
}
Решение: применять метод Saver::save сразу для всего набора данных:
@Transactional
public void audit(List inserts) {
List bulk = inserts
.map(this::toEntities)
.flatMap(List::stream) // <----
.collect(toList());
saver.save(bulk);
}
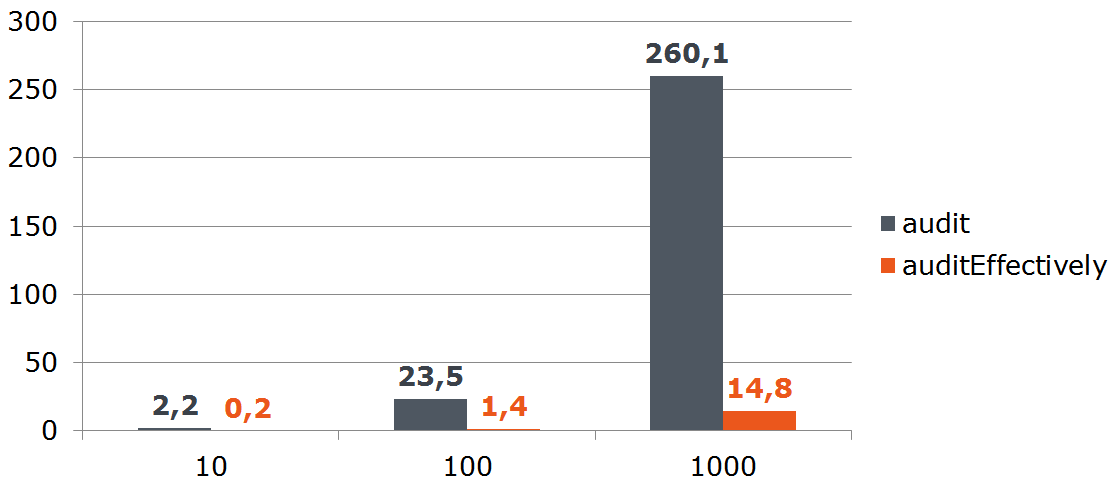
Бенчмарк
Пример со множественными транзакциями сложно формализовать, чего не скажешь о вызове JpaRepository::findOne в цикле.
Подход применим не только к БД, поэтому Тагир lany Валеев пошел дальше. И если раньше мы писали вот так:
List list = new ArrayList<>();
for (Long id : items) {
list.add(id);
}
и всё было хорошо, то теперь «Идея» предлагает исправиться:
List list = new ArrayList<>();
list.addAll(items);
Но даже этот вариант удовлетворяет её не всегда, ведь можно сделать ещё короче и быстрее:
List list = new ArrayList<>(items);
Для ArrayList-а это улучшение даёт заметный прирост:
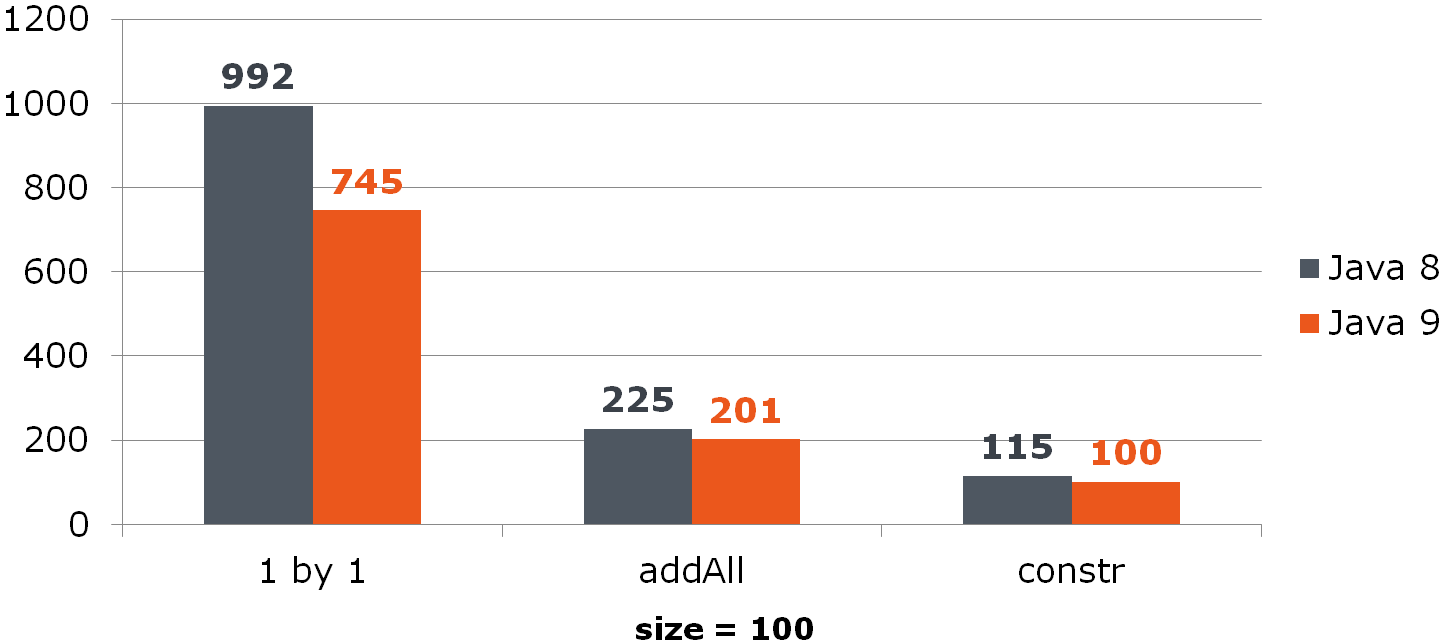
Для HashSet-а всё не так радужно:

Бенчмарк
Удаление из ArrayList-а
for (int i = from; i < to; i++) {
list.remove(from);
}
Проблема в реализации метода List::remove:
public E remove(int index) {
Objects.checkIndex(index, size);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0) {
System.arraycopy(array, index + 1, array, index, numMoved); // <----
}
array[--size] = null; // clear to let GC do its work
return oldValue;
}
Решение:
list.subList(from, to).clear();
Но что если в исходном коде удалённое значение используется?
for (int i = from; i < to; i++) {
E removed = list.remove(from);
use(removed);
}
Теперь нужно предварительно пройти по очищаемому подсписку:
List removed = list.subList(from, to);
removed.forEach(this::use);
removed.clear();
Если же очень хочется удалять в цикле, то облегчить боль поможет смена направления прохода по списку. Смысл его в том, чтобы сдвигать меньшее количество элементов после очистки ячейки:
//прямой проход менее эффективен, т. к. сдвигаются все элементы справа от удаляемого
for (int i = from; i < to; i++) {
E removed = list.remove(from);
use(removed, i);
}
//обратный проход быстрее, т. к. сдвиг всегда постоянный
for (int i = to - 1; i >= from; i--) {
E removed = list.remove(i);
use(removed, reverseIndex(i));
}
Сравним все три способа (под столбцами указан % удаляемых элементов из списка размером 100):
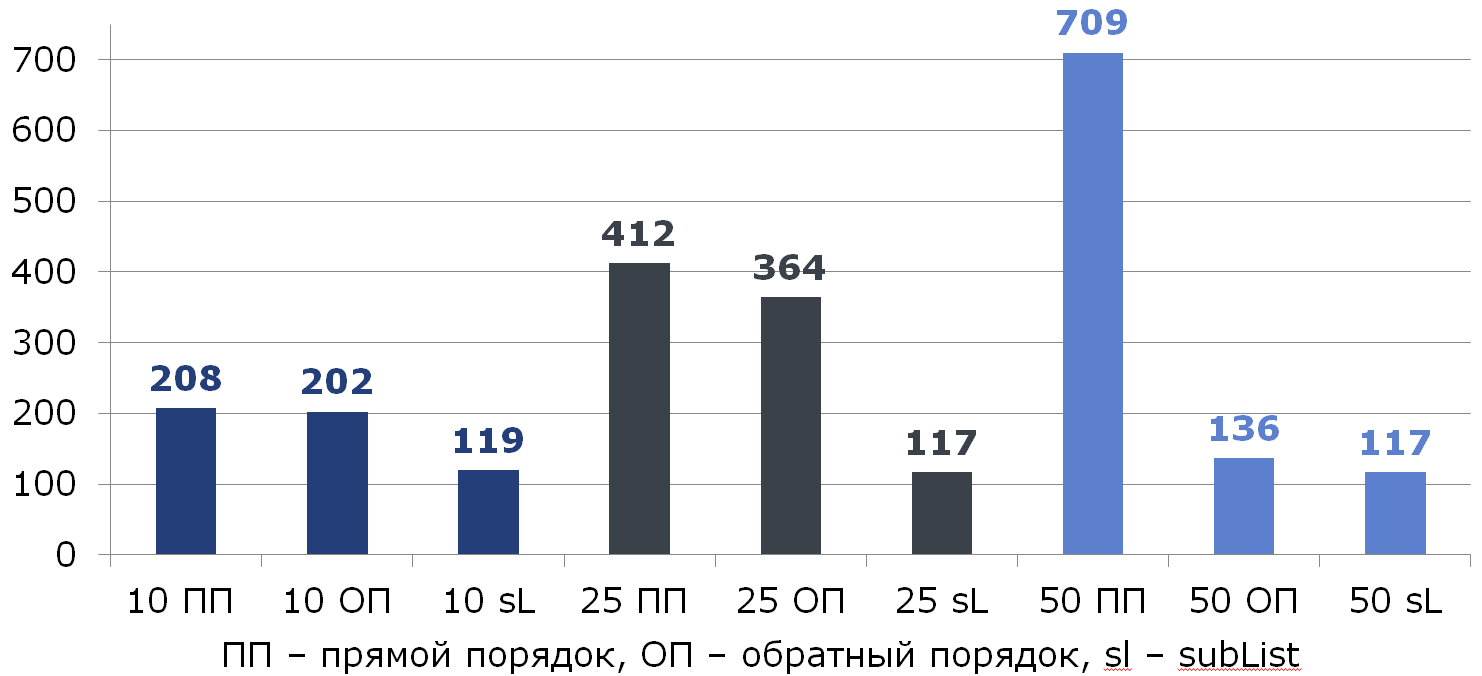
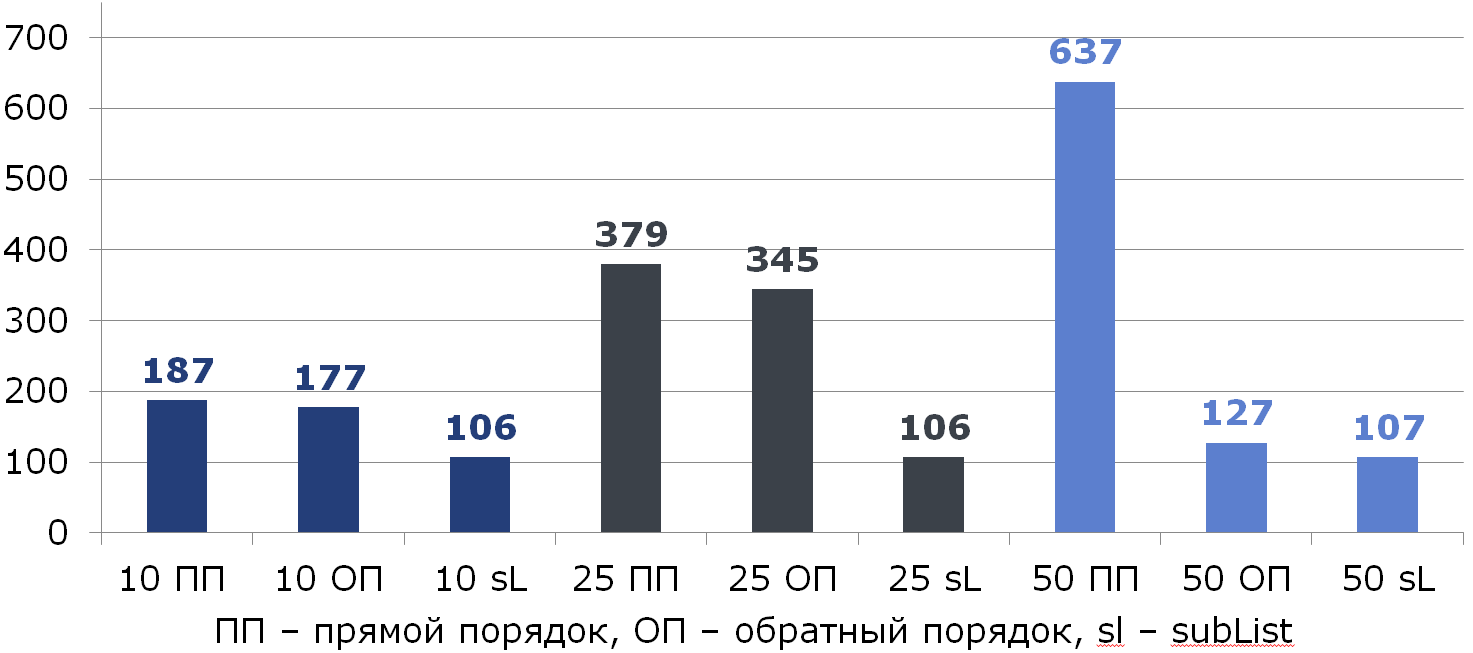
Кстати, кто-то заметил аномалию?

Если мы удаляем половину всех данных, двигаясь с конца, то удаляется всегда последний элемент и сдвига не происходит:
// ArrayList
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0) { // <---- условие никогда не выполняется
System.arraycopy(elementData, index+1, elementData, index, numMoved);
}
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
Бенчмарк
Вывод: массовые операции часто быстрее одиночных.
Область видимости и производительность
Этот код в особых пояснениях не нуждается:
void leaveForTheSecondYear() {
List naughty = repository.findNaughty();
List underAchieving = repository.findUnderAchieving(); // <----
if (settings.leaveBothCategories()) {
leaveForTheSecondYear(naughty, underAchieving); // <----
return;
}
leaveForTheSecondYear(naughty);
}
Сужаем область видимости, что даёт минус 1 запрос:
void leaveForTheSecondYear() {
List naughty = repository.findNaughty();
if (Settings.leaveBothCategories()) {
List underAchieving = repository.findUnderAchieving(); // <----
leaveForTheSecondYear(naughty, underAchieving); // <----
return;
}
leaveForTheSecondYear(naughty);
}
И тут внимательный читатель должен спросить:, а как же статический анализ? Почему «Идея» нам не подсказала о лежащем на поверхности улучшении?
Дело в том, что возможности статического анализа ограничены: если метод сложный (тем более взаимодействующий с БД) и влияет на общее состояние, то перенос его исполнения может сломать приложение. Статический анализатор в состоянии сообщить об очень простых исполнениях, перенос которых, скажем, внутрь блока ничего не сломает.
В качестве эрзаца можно использовать подсветку переменных, но, повторюсь, использовать осторожно, т. к. всегда возможны побочные эффекты. Можно использовать аннотацию @org.jetbrains.annotations.Contract(pure = true), доступную из библиотеки jetbrains-annotations для обозначения методов, не изменяющих состояние:
// com.intellij.util.ArrayUtil
@Contract(pure = true)
public static int find(@NotNull int[] src, int obj) {
return indexOf(src, obj);
}
Вывод: чаще всего лишняя работа только ухудшает производительность.
Самый необычный пример
@Service
public class RemoteService {
private ContractCounter contractCounter;
@Transactional(readOnly = true) // <----
public int countContracts(Dto dto) {
if (dto.isInvalid()) {
return -1; // <----
}
return contractCounter.countContracts(dto);
}
}
Эта реализации открывает транзакцию даже в том случае, когда транзакционность не нужна (быстрый возврат -1 из метода).
Всё что нужно сделать, это убрать транзакционность внутрь метода ContractCounter::countContracts, где она необходима, а из «внешнего» метода её убрать.
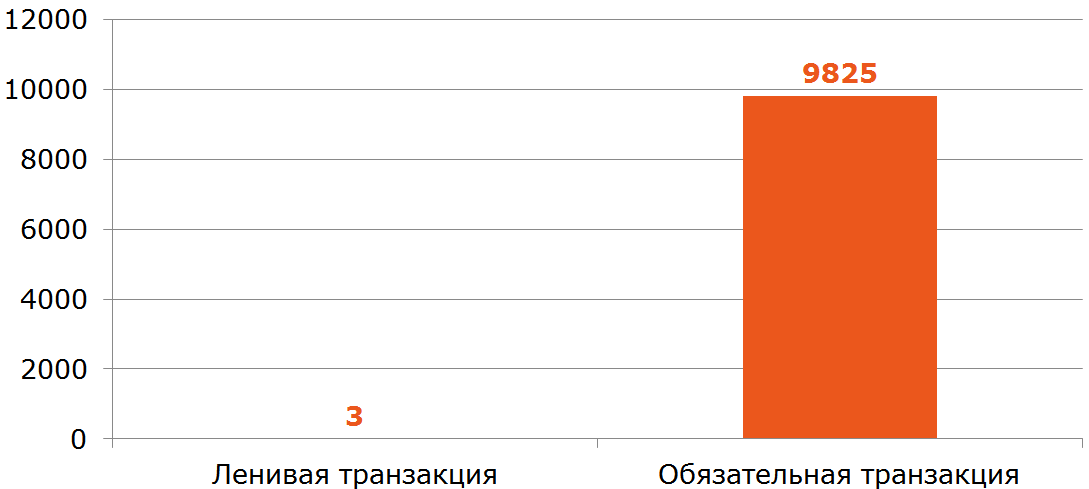
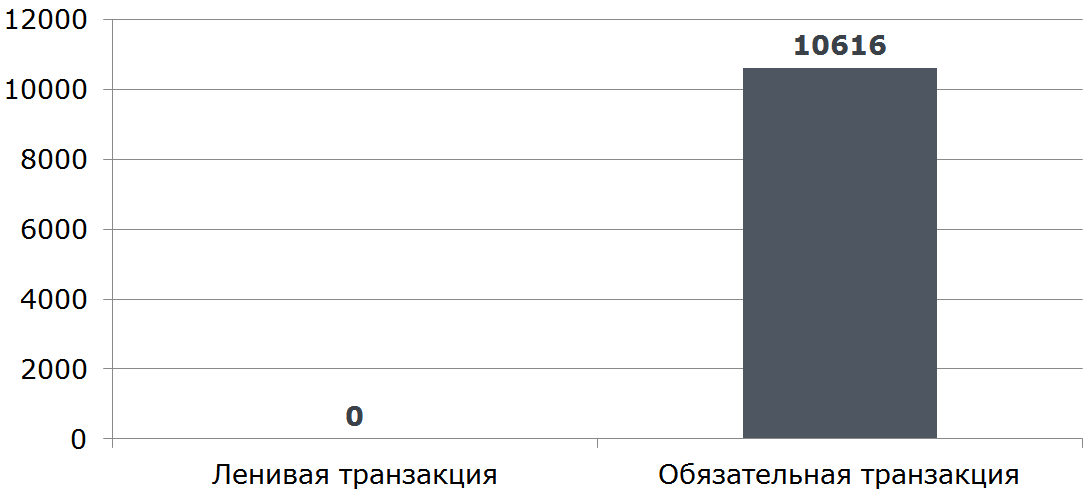
Бенчмарк
Вывод: контроллеры и смотрящие «наружу» сервисы нужно освобождать от транзакционности (это не их ответственность) и выносить туда всю логику проверки входных данных, не требующую обращения к БД и транзакционным компонентам.
Преобразование даты/времени в строку
Одна из вечных задач — превращение даты/времени в строку. До «восьмёрки» мы делали так:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy");
String dateAsStr = formatter.format(date);
С выходом JDK 8 у нас появился LocalDate/LocalDateTime и, соответственно, DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy");
String dateAsStr = formatter.format(localDate);
Измерим его производительность:
Date date = new Date();
LocalDate localDate = LocalDate.now();
SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy");
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy");
@Benchmark
public String simpleDateFormat() {
return sdf.format(date);
}
@Benchmark
public String dateTimeFormatter() {
return dtf.format(localDate);
}
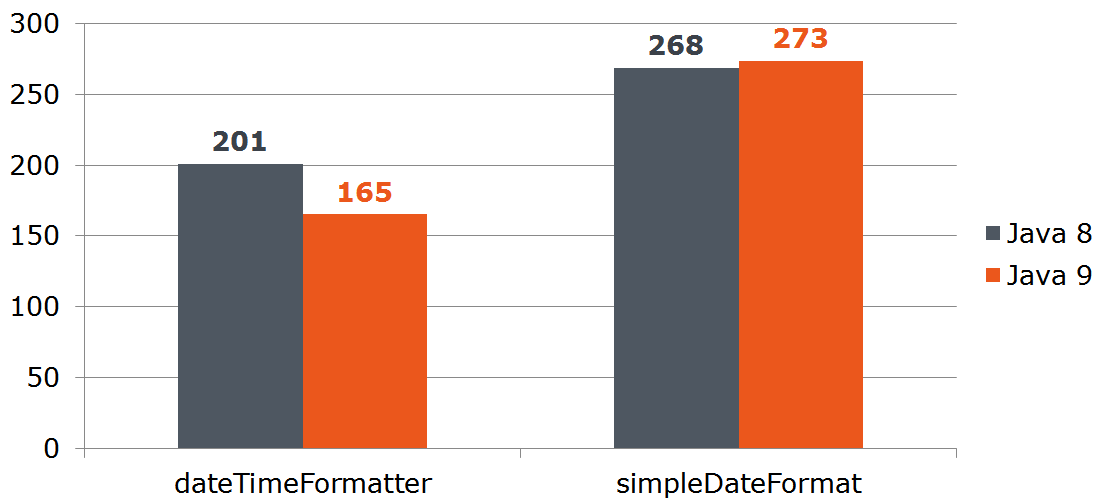
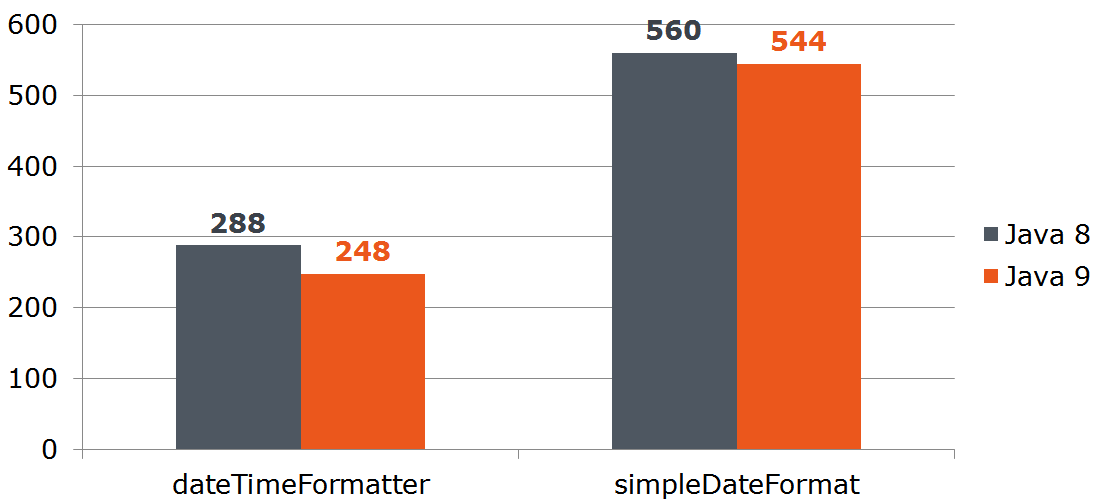
Вопрос: допустим наш сервис получает данные извне и мы не можем отказаться от java.util.Date. Будет ли выгодно нам преобразовать Date в LocalDate, если последний быстрее преобразовывается в строку? Посчитаем:
@Benchmark
public String measureDateConverted(Data data) {
LocalDate localDate = toLocalDate(data.date);
return data.dateTimeFormatter.format(localDate);
}
private LocalDate toLocalDate(Date date) {
return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate();
}
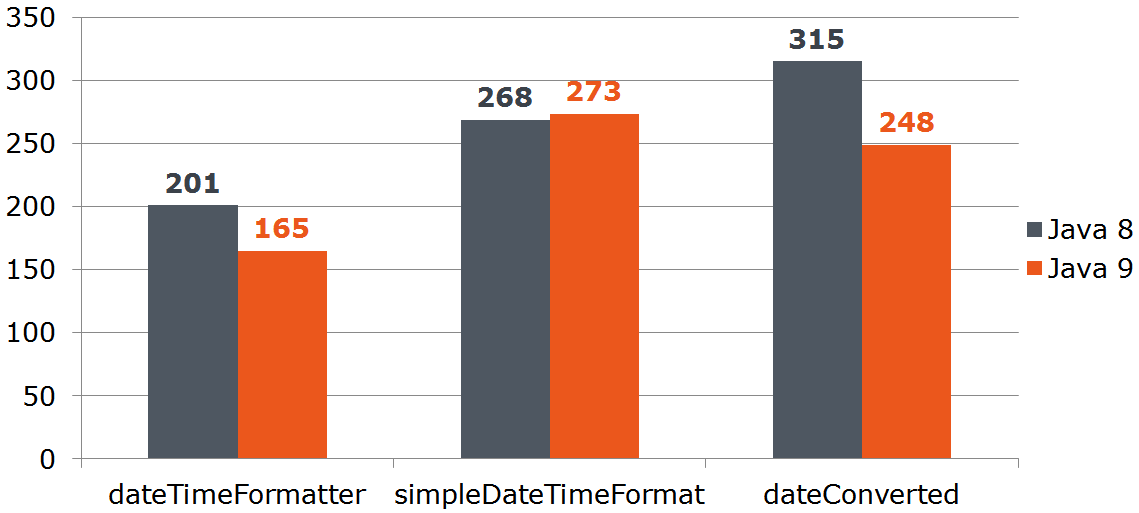

Таким образом преобразование Date → LocalDate выгодно при использовании «девятки». На «восьмёрке» затраты на преобразование сожрут всё преимущество DateTimeFormatter-a.
Бенчмарк
Вывод: используйте преимущества новых решений.
Ещё «восьмёрка»
В этом коде видим очевидную избыточность:
Iterator iterator = items // ArrayList
.stream()
.map(Long::valueOf)
.collect(toList()) // <---- зачем нам промежуточный список?
.iterator();
while (iterator.hasNext()) {
bh.consume(iterator.next());
}
Уберём её:
Iterator iterator = items // ArrayList
.stream()
.map(Long::valueOf)
.iterator();
while (iterator.hasNext()) {
bh.consume(iterator.next());
}


Удивительно, не так ли? Выше я утверждал, что лишняя работа ухудшает производительность. Но вот мы убираем лишнее — и (внезапно) становится хуже. Чтобы разобраться в происходящем, возьмём два итератора и посмотрим на них под лупой:
Iterator iterator1 = items.stream().collect(toList()).iterator();
Iterator iterator2 = items.stream().iterator();

Первый итератор — это обычный ArrayList$Itr.
public boolean hasNext() {
return cursor != size;
}
public E next() {
checkForComodification();
int i = cursor;
if (i >= size) {
throw new NoSuchElementException();
}
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
cursor = i + 1;
return (E) elementData[lastRet = i];
}
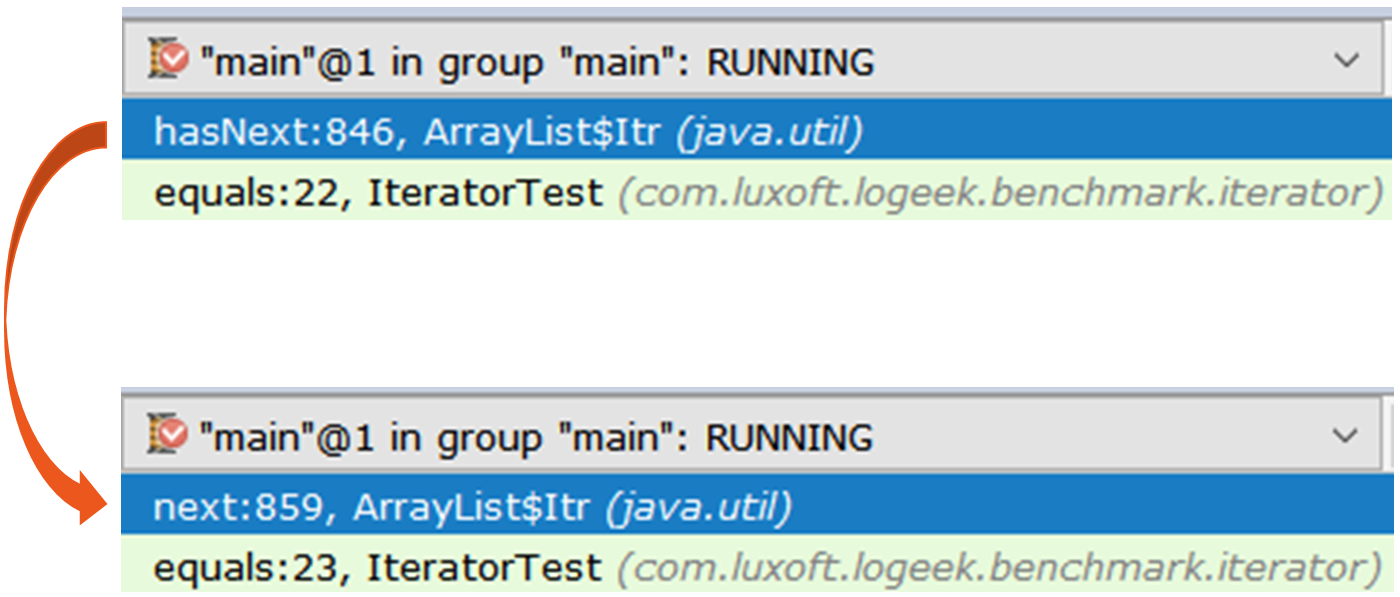
Второй любопытнее, это Spliterators$Adapter, в основе которого — ArrayList$ArrayListSpliterator.
// java.util.Spliterators$Adapter
public boolean hasNext() {
if (!valueReady)
spliterator.tryAdvance(this);
return valueReady;
}
public T next() {
if (!valueReady && !hasNext())
throw new NoSuchElementException();
else {
valueReady = false;
return nextElement;
}
}
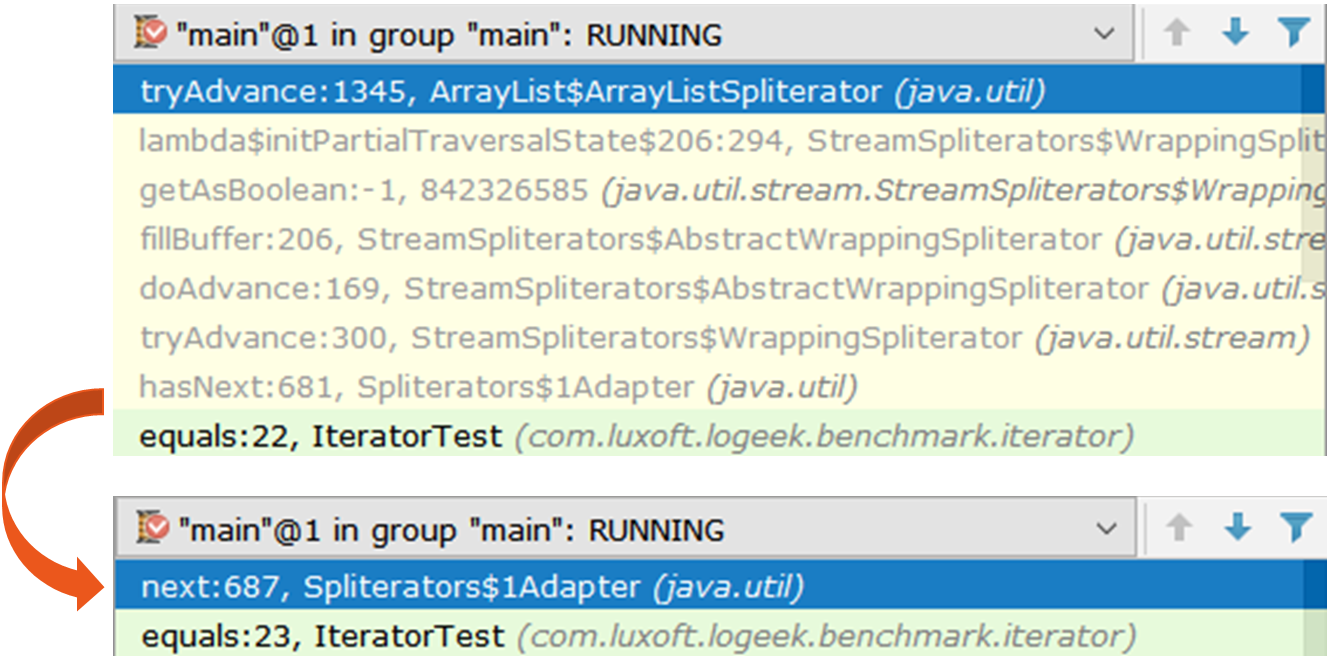
Посмотрим на перебор итератором через async-profiler:
15.64% j.u.ArrayList$ArrayListSpliterator.tryAdvance
10.67% j.u.s.SpinedBuffer.clear
9.86% j.u.Spliterators$1Adapter.hasNext
8.81% j.u.s.StreamSpliterators$AbstractWrappingSpliterator.fillBuffer
6.01% o.o.j.i.Blackhole.consume
5.71% j.u.s.ReferencePipeline$3$1.accept
5.57% j.u.s.SpinedBuffer.accept
5.06% c.l.l.b.ir.IteratorFromStreamBenchmark.iteratorFromStream
4.80% j.l.Long.valueOf
4.53% c.l.l.b.i.IteratorFromStreamBenchmark$$Lambda$8.885721577.apply
Видно, что большая часть времени затрачивается на проход по итератору, хотя по большому счёту, он нам не нужен, ведь перебор можно сделать и так:
items
.stream()
.map(Long::valueOf)
.forEach(bh::consume);

Stream::forEach явно в выигрыше, а ведь это странно: в основе по-прежнему лежит ArrayListSpliterator, но производительность его использования существенно улучшилась.
29.04% o.o.j.i.Blackhole.consume
22.92% j.u.ArrayList$ArrayListSpliterator.forEachRemaining
14.47% j.u.s.ReferencePipeline$3$1.accept
8.79% j.l.Long.valueOf
5.37% c.l.l.b.i.IteratorFromStreamBenchmark$$Lambda$9.617691115.accept
4.84% c.l.l.b.i.IteratorFromStreamBenchmark$$Lambda$8.1964917002.apply
4.43% j.u.s.ForEachOps$ForEachOp$OfRef.accept
4.17% j.u.s.Sink$ChainedReference.end
1.27% j.l.Integer.longValue
0.53% j.u.s.ReferencePipeline.map
В этом профиле большая часть времени затрачивается на «проглатывания» значения внутри Blackhole. По сравнению с итератором значительно большая часть времени затрачивается непосредственно на исполнение ява-кода. Можно предположить, что причиной является меньший удельный вес сборки мусора, по сравнению с перебором итератором. Проверим:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op
iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
И действительно, Stream::forEach даёт вдвое меньшее потребление памяти.
Цепочка вызовов от начала и до «чёрной дыры» выглядит так:
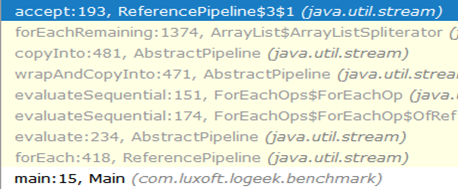
Как видим, из цепочки пропал вызов ArrayListSpliterator::tryAdvance, а вместо него появился ArrayListSpliterator::forEachRemaining:
// ArrayListSpliterator
public void forEachRemaining(Consumer action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i]; // <----
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
Высокая скорость ArrayListSpliterator::forEachRemaining достигается использованием прохода по всему массиву за 1 вызов метода. При использовании итератора проход ограничен одним элементом, поэтому мы всё время упираемся в ArrayListSpliterator::tryAdvance.ArrayListSpliterator::forEachRemaining имеет доступ ко всему массиву и перебирает его счётным циклом без дополнительных вызовов.
Обратите внимание, что механическая замена
Iterator iterator = items
.stream()
.map(Long::valueOf)
.collect(toList())
.iterator();
while (iterator.hasNext()) {
bh.consume(iterator.next());
}
на
items
.stream()
.map(Long::valueOf)
.forEach(bh::consume);
не всегда равнозначна, т. к. в первом случае мы используем для прохода копию данных, не затрагивая сам стрим, а во втором данные берутся непосредственно из стрима.
Бенчмарк
Вывод: имея дело со сложными представлениями данных будьте готовы к тому, что даже «железные» правила (лишняя работа вредит) перестают работать. Пример выше показывает, что кажущийся лишним промежуточный список даёт преимущество в виде более быстрой реализации перебора.
Два подвоха
StackTraceElement[] trace = th.getStackTrace();
StackTraceElement[] newTrace = Arrays
.asList(trace)
.subList(0, depth)
.toArray(new StackTraceElement[newDepth]); // <----
Первое, что бросается в глаза — протухшее «улучшение», а именно передача в метод Collection::toArray массива ненулевой длины. Здесь очень обстоятельно рассказывается почему это вредит.
Вторая проблема не столь очевидна, и для её понимания можно провести параллель между работой ревьюера и историка.
Предположим, например, что он [историк] читает Кодекс Феодосия и перед ним — эдикт императора. Простое чтение слов и возможность их перевести еще не равносильны пониманию их исторического значения. Чтобы оценить его, историк должен представить себе ситуацию, которую пытался разрешить император…
Вычитывая код очень важно за тем что сейчас делает код увидеть намерение разработчика. В нашем случае происходит вот это:
1) список заворачивается в массив
2) часть списка отрезается
3) отрезанный подсписок преобразуется обратно в массив
Иными словами разработчик намеревался создать подмассив, а это гораздо проще сделать так:
StackTraceElement[] trace = th.getStackTrace();
StackTraceElement[] newTrace = Arrays.copyOf(trace, depth); // неявный отсчёт с 0
// или
StackTraceElement[] newTrace = Arrays.copyOfRange(trace, 0, depth); //явный отсчёт с 0
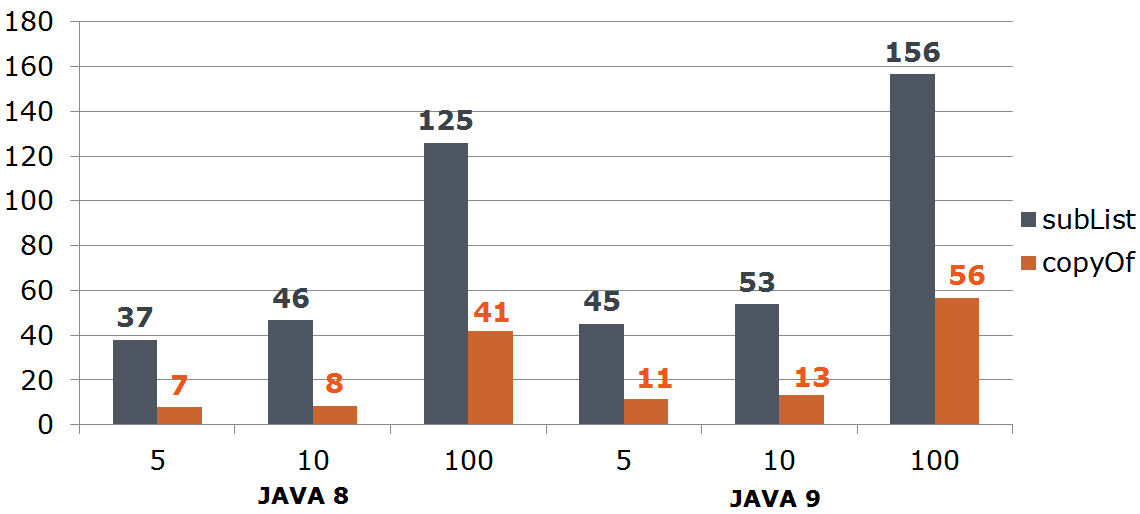
Бенчмарк
Стримоз головного мозга
List list = getList();
Set set = getSet();
return list.stream().allMatch(set::contains); // что проверяется на самом деле?
Проверяется вхождение всех элементов списка в набор, но этот код можно значительно упростить, одновременно улучшив его производительность:
List list = getList();
Set set = getSet();
return set.containsAll(list);

Бенчмарк
Ненужные обёртки
Есть интерфейс:
interface FileNameLoader {
String[] loadFileNames();
}
и использование некой его реализации:
private FileNameLoader loader;
void load() {
for (String str : asList(loader.loadFileNames())) { // <---- ненужное заворачивание
use(str);
}
}
Часто разработчики считают, что сахарок forEach используется только с коллекциями, хотя с массивом его тоже можно:
private FileNameLoader loader;
void load() {
for (String str : loader.loadFileNames()) { // <---- проще и быстрее
use(str);
}
}

Бенчмарк
Вывод: в несложных случаях более производительный код также:
- короче
- надёжнее
- проще и понятнее
Если вы на своём проекте выловили антипаттерн, который можно формализовать, не стесняйтесь сообщать о них разработчикам систем статического анализа, а не только вашим товарищам. Таким образом, вы поможете всем: разработчики добавят новую проверку и пропылесосят код самой «Идеи» (и вы получите более отказоустойчивую и быструю среду разработки), разработчики библиотек и фреймворков возьмут новую «Идею» и почистят свой код (и вы получите улучшенные библиотеки и фреймворки), и наконец вы сами можете применить статический анализ.
Исходники замеров с пояснениями: https://github.com/stsypanov/logeek-night-benchmark
Папка с замерами: https://github.com/stsypanov/logeek-night-benchmark/tree/master/results
