Жадный гном: Как я писал аналитику рынка в Lineage 2
Вот и наступила осенне-зимняя пора. За окном дожди и желания проводить время на открытом воздухе все меньше и меньше. И вот приходит мне сообщение от товарища »А давай поиграем в Lineage 2?». И опять я, поддавшись ностальгии, согласился. Выбрали мы свеженький сервер на ру-офе и создали персонажей.
В отличии от World of Warcraft в Lineage 2 совершенно другая система добычи игровой валюты. Нужно круглыми сутками охотиться на монстров с целью получения наживы. Для меня было даже открытием, что для некоторых людей RMT (Real money trading) является чем то вроде работы. Также, в игре присутствует экономика, которую формируют игроки. Иными словами, можно заработать на купи-продай или же покупать дешевые ресурсы, из них делать вещи и продавать с наценкой. Так как для нас игра остается чем то вроде отдыха именно такой способ получения игровой валюты был выбран нами.
Чтобы покупать и продавать предметы игрок должен находиться online (Скриншот сверху). Соответсвенно, кто-то хочет побыстрее продать (дешевле), а кто-то побыстрее купить (дороже). А что если разница продать — купить положительная? Как раз этот пример и будет рассмотрен в статье как итог.
Однако, цены на рынке достаточно нестабильны и часто меняются. По этому существует вероятность купить что то «дешево» и потом еще дешевле продать и отрицательной прибылью. Этого мы и стараемся избежать. В общем было решено написать систему аналитики рынка и разобраться с парочкой интересных мне технологий.
Spoiler:
В статье будут использованы следующие технологии
Docker, DigitalOcean, NodeJs, Ktor, Prometheus, Grafana, Telegram bot notification
Чтобы «что-то» анализировать, нужно сначала нам это «что-то» получить. Было рассмотрено 2 варианта получения информации.
Sniffing — написать приложение, которое будет слушать трафик и его анализировать. Минусы данного подхода очень просты. Нужно быть постоянно онлайн и смотреть рынок да и по политике сервера могут забанить. Однако, хотелось бы минимальных действий от пользователя и желательно максимально все автоматизировать.
Parsing — есть сайт, который как раз специализируется на сниффинге для этой игры — l2on.net. Как раз то, что нам нужно! Мы отдаем роль собирателя сырых данных этому сервису. Осталось только как то получить данных и начать с ними экспериментировать.
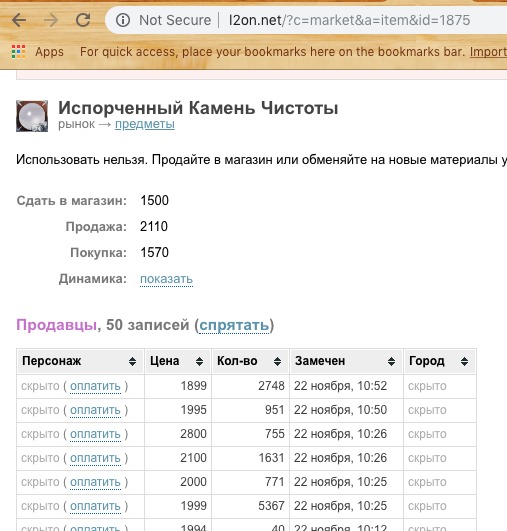
Исходя из строки запроса мы понимаем что нам необходимо передать id ресурса для получения информации по нему. Однако, если мы это будем автоматизировать, то необходимо передавать еще и id игрового сервера. Покопавшись минуту в исходном коде страницы было найдено следующее:

Пробуем… Отлично! Получаем список цен покупки и продажи.
Теперь нужно думать с помощью чего будем парсить сайт.
Выбор пал на Puppeteer для NodeJs.
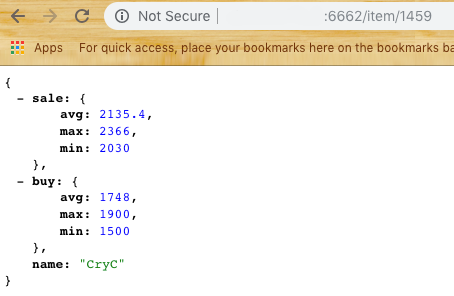
На его основе был создан первый модуль подсистемы — Scrapper. Его основная задача — пойти на сайт, открыть, распарсить и вернуть данные в виде JSON. Берем выборку из последних N элементов, считаем среднюю, минимальную и максимальную цену. (Забегая вперед скажу что нужно доработать percentile для редактирования шума если какой то игрок ставит слишком высокую цену на продажу или низкую на покупку) Получаем ответ по данным вида:
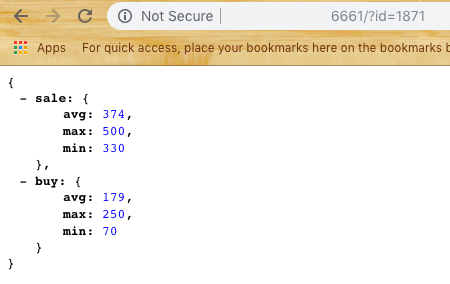
Теперь мы можем двигаться к следующей части — хранение данных.
Предположим, у нас будет 2–3 потребителя наших данных и мы хотим отдавать их массивом. Также мы хотим избежать частых запросов на l2on чтобы не быть добавленным в черный список. Значит нам нужно создать второй модуль, который будет выполнять роль посредника между l2on и нашими агентами.
Методика опроса была выбрана простая. Раз в 5 минут модуль должен запрашивать все предметы из установленного списка и предоставлять на выход данные как по одному ресурсу так и выход для аналитики.
Для этой системы захотелось попробовать Ktor — сервер решение на Kotlin.
Базу данных использовать не стал, а последние данные решил хранить в Singleton. Да, решение не самое изящное, но на скорую руку подойдет, а оптимизировать всегда успеем.
Так появился второй модуль системы — Harvester.
Harvester предоставляет для пользователя два endpoint’a /item/{id} и /metrics
Если с первым все понятно, то последний возвращает данные в формате для следующей системы — Prometheus
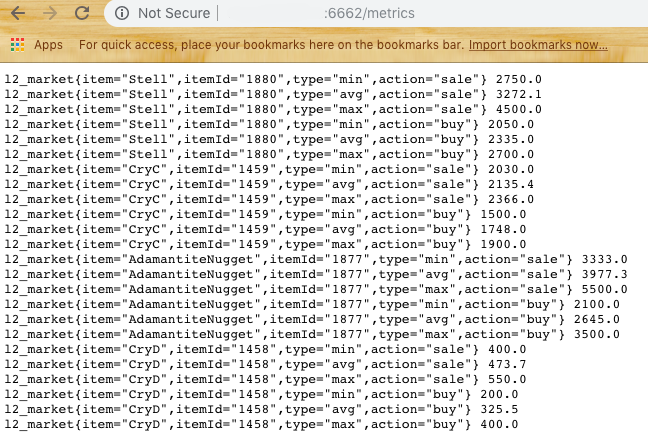
Промежуточным звеном был выбран Prometheus — Open Source база данных для аналитики которая работает через Pull подход. Другими словами при конфигурировании вам необходимо указать в yaml файле набор поставщиков данных и частоту опроса. В нашем случае — это как раз тот самый /metrics endpoint.
Пробуем запустить Prometheus (по умолчанию это 9090 порт) и если видим в Target что то похожее на:
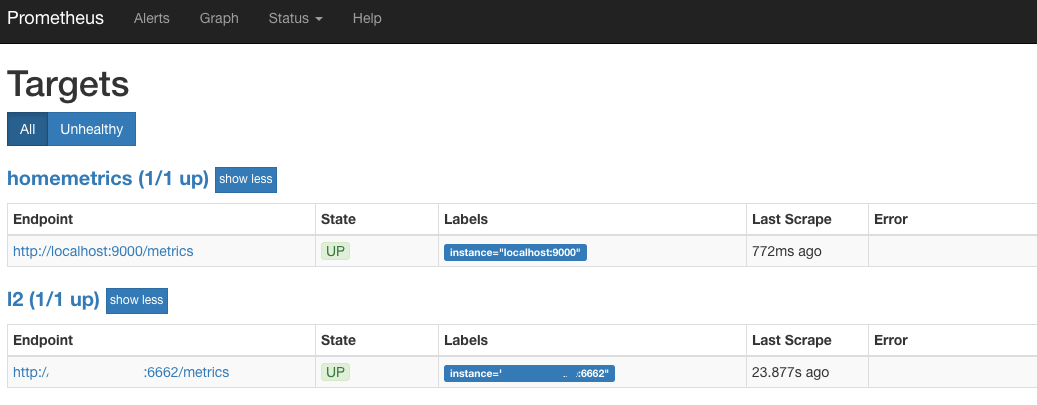
Значит мы идем по правильному пути. Это значит что каждый 30 секунд Prometheus идет в Harvester и забирает последнее состояние по всем интересующим нас товарам.
Следующий этап — это красивое отображение графиков
Для отрисовки была выбрана Grafana которая тоже Open Source.
Плюсы Grafana и Prometheus — они доступны в виде Docker контейнеров, которые требуют от пользователя минимум действий.
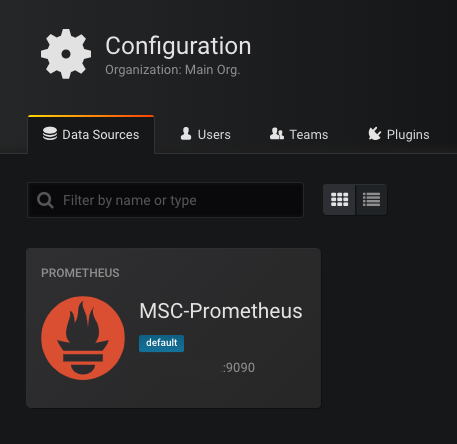
При первом запуске Grafana (стандартный порт 3000) она попросит указать доступную базу данных. Выбираем Prometheus как базу и прописываем адрес. Если все пройдет успешно — то увидим:
Следующий шаг — отрисовать графики.
Пример запроса на отрисовку графика по продаже:
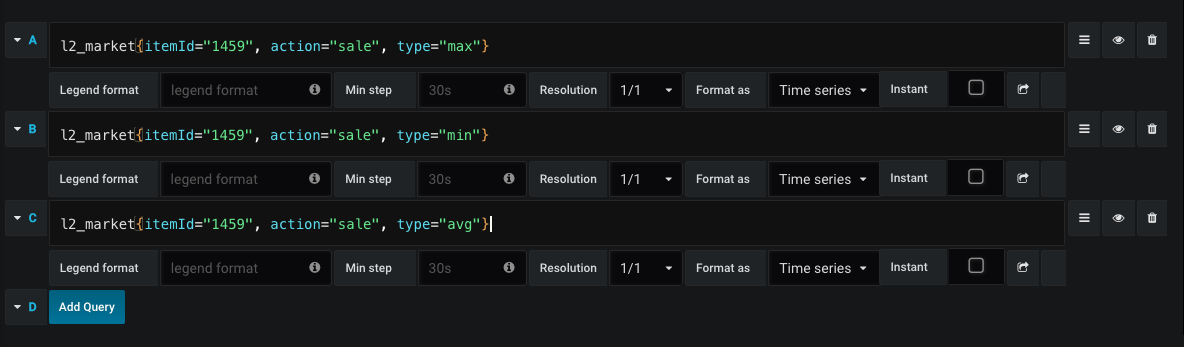
Таким образом мы в любой момент времени видим среднюю цену для закупки и продажи, а также динамику цен.

Однако, бывают моменты, когда минимальная цена продажи выше максимальной цены покупки. Это означает, что мы можем получить легкую наживу в виде «купи продай». Для канала отправки нотификация был выбран Telegram. Создаем бота и добавляет его токен в Grafana (да да, она поддерживать нотификации)
Достаточно просто установить условие, при котором нам будет приходит данное уведомление.

Как мы видим сходя из графика, такие ситуации случаются на рынке.

Каждую подсистему мы пакуем в Docker container и загружаем в DigitalOcean или другие сервисы по вашему вкусу. Но это не мешает нам и запускать всю эту систему без выделенного IP. Сейчас минимальный контейнер на DO стоит 5$ в месяц.
Запускаем сначала Scrapper
docker run -d -p 6661:6661 --name scrapper l2/scrapper: latest
За ним Harvester
docker run -d -p 6662:6662 -v /root/harvester:/res --link scrapper: scrapper l2harvester: latest
В папке /harvester должен находиться файл ids.txt с форматом
id1 name1
id2 name2
В конечном итоге система выглядит следующим образом:
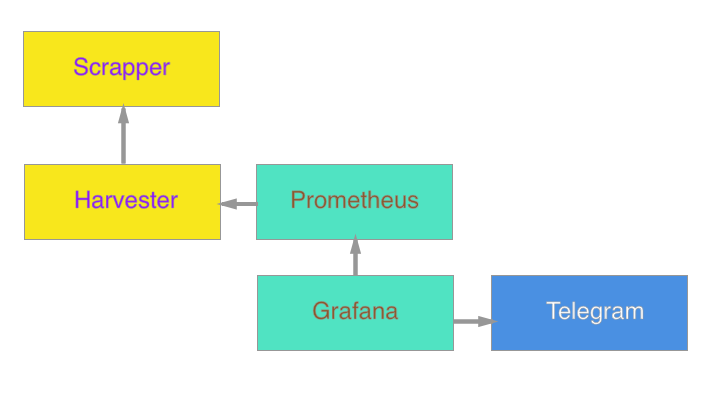
Планируется в будущем добавить агента чтобы обновлять google docs, и считать стоимость крафта на лету.
Не знаю, принесет ли данная наработка какую то выгоду, но лично для меня это был хороший опыт освежить свой знания в прикладной области. Основная моя специфика — мобильные приложения. Разработка серверной части это дополнительный скилл и любознательность.
В качестве дополнения прикладываю ссылки для ознакомления с кодом:
Scrapper
Harvester
(Собрать контейнеры можно командами
docker build -t scrapper.
docker build -t harvester .)
Я очень надеюсь, что данная статья навеяла кому то ностальгические чувства, или же дала вдохновение для какой то новой идеи. Спасибо за то, что дочитали статью до конца!
