Задачник по теории информации + ML. Часть 1
Давно хотел сделать учебные материалы по теме Теория Информации + Machine Learning. Нашёл старые черновики и решил довести их до ума здесь, на хабре.
Теория Информации и Machine Learning мне видятся как интересная пара областей, глубокая связь которых часто неизвестна ML инженерам, и синергия которых раскрыта ещё не в полной мере.
Когда я говорю коллегам, что LogLoss на тесте и Mutual Information между прогнозом и прогнозируемой величиной связаны напрямую, и по несложной формуле можно из одного получить второе, они часто искренне удивляются. В википедии со страницы LogLoss есть ссылка на Mutual Information, но не более того.
Теория Информация может стать (а, точнее, стала) источником понимания как и почему работают разные методы ML, в частности нейронные сети, а также может дать идеи улучшения градиентных методов оптимизации.
Начнём с базовых понятий Энтропии, Информации в сообщении, Взаимной Информации (Mutual Information), пропускной способности канала. Далее будут материалы про схожесть задач максимизации Mutual Information и минимизации Loss-а в регрессионных задачах. Затем будет часть про Information Geometry: метрику Фишера, геодезические, градиентные методы, и их связь с гауссовскими процессами (движение по градиенту методом SGD — это движение по геодезической с шумом).
Также нужно затронуть AIC, Information Bottleneck, поговорить про то, как устроен поток информации в нейронных сетях — Mutual Information между слоями (Information Theory of Deep Learning, Naftali Tishby) и многое другое. Не факт, что получится всё перечисленное охватить, но попробую начать.
1. Базовые определения
Есть три более менее разных способа прийти к формуле энтропии распределения

Давайте их опишем. Начнём с базовых определений.
Опр. 1.1: Неопределенность — это логарифм по основанию 2 от числа равновероятных вариантов:  . Измеряется в битах. Например, неопределенность неизвестного битового слова длины k равна k. Для краткости везде далее
. Измеряется в битах. Например, неопределенность неизвестного битового слова длины k равна k. Для краткости везде далее  обозначается просто как
обозначается просто как  .
.
Опр. 1.2: Информация в сообщении — это разница неопределенностей до получения сообщения и после

Тоже измеряется в битах.
Например, Ваня загадал число от 1 до 100. Нам сообщили, что оно меньше либо равно 50. Неопределённость до сообщения равна  , а после —
, а после —  . То есть в этом сообщении 1 бит информации. Умело задавая бинарные вопросы (вопросы, на которые ответ ДА или НЕТ), можно извлекать ровно 1 бит информации.
. То есть в этом сообщении 1 бит информации. Умело задавая бинарные вопросы (вопросы, на которые ответ ДА или НЕТ), можно извлекать ровно 1 бит информации.
Некоторые вопросы неэффективны, например, вопрос «верно ли, что число меньше либо равно 25?» уменьшит неопределенность на  бита с вероятностью 0.25, а с вероятностью 0.75 только на
бита с вероятностью 0.25, а с вероятностью 0.75 только на  бит, то есть в среднем на
бит, то есть в среднем на  бит. Если вы своим вопросом разбиваете множество вариантов в пропорции
бит. Если вы своим вопросом разбиваете множество вариантов в пропорции  , то среднее количество бит информации в ответе равно
, то среднее количество бит информации в ответе равно  .
.
Это выражение будем обозначать через  или
или  . Здесь мы как программисты перегрузим функцию H так, чтобы она работала для двух случаев — когда на вход поступает пара чисел, сумма которых равна 1, и когда одно число из отрезка [0, 1].
. Здесь мы как программисты перегрузим функцию H так, чтобы она работала для двух случаев — когда на вход поступает пара чисел, сумма которых равна 1, и когда одно число из отрезка [0, 1].
Опр. 1.3: 
График H (x)
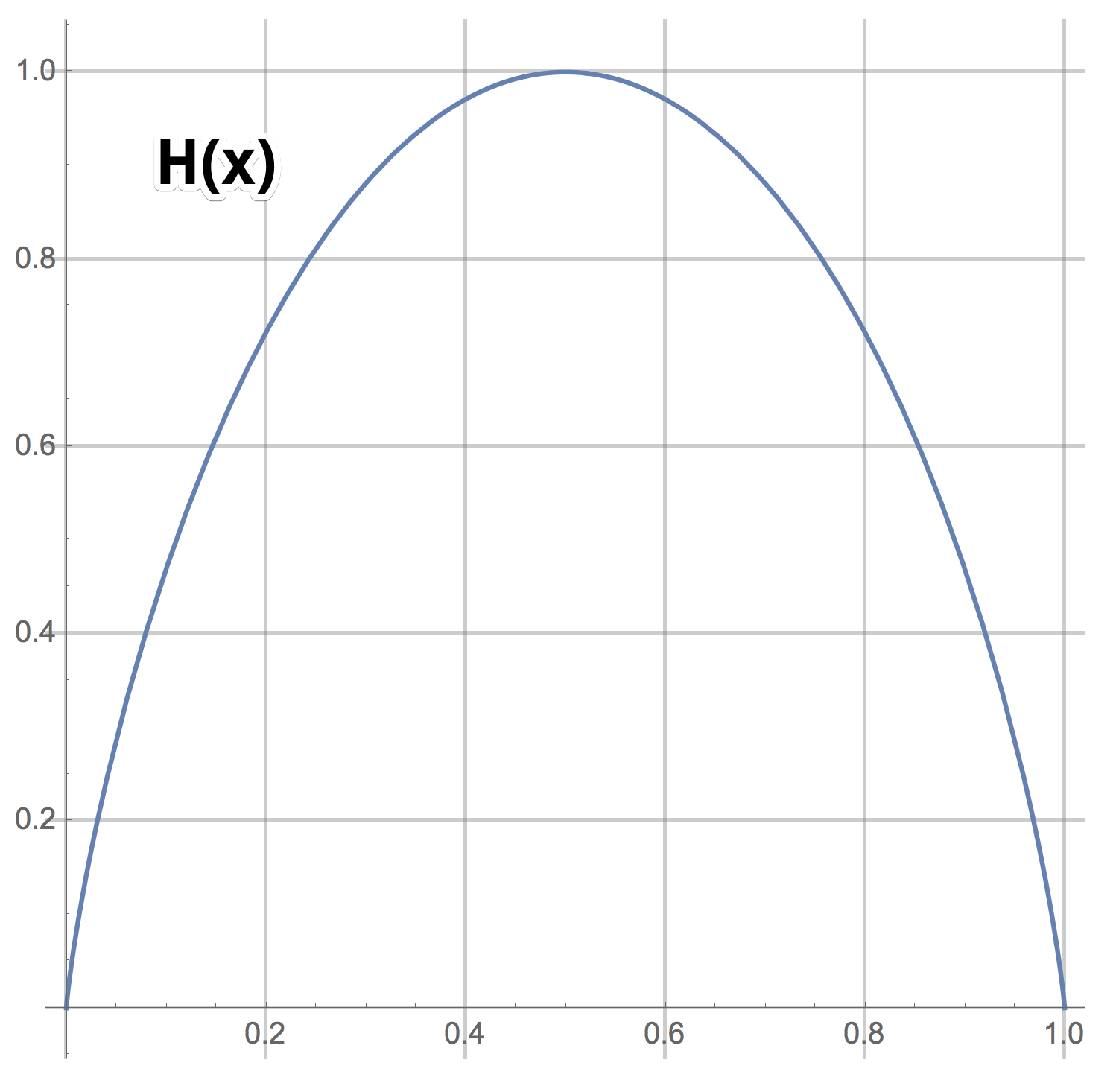
Видно, что задавая бинарные вопросы, в среднем можно в извлекать максимум 1 бит информации. Ещё раз: да, можно сразу задавать вопросы типа «Число равно 57?» и если повезёт, получать log (100) бит информации. Но если не повезёт, вы получите лишь log (100/99) бит информации. Среднее число бит информации для такого сорта вопросов равно  что заметно меньше 1.
что заметно меньше 1.
В этом примере 100 вариантов, а значит начальная неопределенность равна  — это то, сколько всего в среднем бинарных вопросов нужно задать Ване, чтобы выведать ответ. Правда число получается нецелое и нужно округлять вверх.
— это то, сколько всего в среднем бинарных вопросов нужно задать Ване, чтобы выведать ответ. Правда число получается нецелое и нужно округлять вверх.
Если мы будем задавать не бинарные вопросы, а вопросы, которые подразумевают в качестве ответа натуральное число от 1 до M, то мы сможем в одном ответе получать более, чем один бит информации. Если мы задаём такой вопрос, для которого все M ответов равновероятны, то в среднем мы будем получать  бит. Если же вероятность ответа i равна p(i), то среднее число бит в ответе будет равно:
бит. Если же вероятность ответа i равна p(i), то среднее число бит в ответе будет равно:

Опр. 1.4: Энтропия дискретного распределения  задаётся формулой (1) выше.
задаётся формулой (1) выше.
Здесь мы перегрузили функцию H для случая, когда на вход поступает дискретное распределение.
ИТАК: Первый простой способ прийти к формуле энтропии  — это посчитать среднее число бит информации в ответе на вопрос с разновероятными ответами.
— это посчитать среднее число бит информации в ответе на вопрос с разновероятными ответами.
Давайте пойдём дальше. Пусть Ваня не загадывает число, а сэмплирует его из распределения  . Сколько бинарных вопросов нужно задать Ване, чтобы узнать выпавшее число? Интуитивно понятно, что нужно разбить множество вариантов на два подмножества уже равных не по количеству элементов, а по суммарному значению вероятности, и спросить Ваню, в каком из двух находится выпавшее число. Получить ответ и продолжить в том же духе с новым уменьшенным множеством вариантов — снова разбить его на два с примерно равным весом, спросить в каком из двух находится выпавшее число и так далее. Идея хорошая, но не совсем рабочая. Оказывается, правильнее поступать с конца и начать строить дерево разбиений снизу, а именно, найти два самых мало вероятных варианта и объединить их в один новый вариант, тем самым уменьшив число вариантов на 1. Потом снова найти два самых маловероятных и снова объединить их в один новый, и так далее, построив конечном итоге бинарное дерево. В листьях этого дерева находятся числа. Внутренние вершины помечены множеством чисел из поддерева, корнем которого они являются. Корень дерева помечен множеством всех чисел. Это дерево и даёт алгоритм того, как нужно задавать вопросы Ване. Нужно двигаться с корня дерева и спрашивать Ваню, куда по этому дереву идти — влево или вправо (в каком из двух множеств вершин детей находится выпавшее число). Это дерево даёт рецепт самого быстрого в среднем метода угадывания числа, а ещё и алгоритм Хаффмана сжатия данных.
. Сколько бинарных вопросов нужно задать Ване, чтобы узнать выпавшее число? Интуитивно понятно, что нужно разбить множество вариантов на два подмножества уже равных не по количеству элементов, а по суммарному значению вероятности, и спросить Ваню, в каком из двух находится выпавшее число. Получить ответ и продолжить в том же духе с новым уменьшенным множеством вариантов — снова разбить его на два с примерно равным весом, спросить в каком из двух находится выпавшее число и так далее. Идея хорошая, но не совсем рабочая. Оказывается, правильнее поступать с конца и начать строить дерево разбиений снизу, а именно, найти два самых мало вероятных варианта и объединить их в один новый вариант, тем самым уменьшив число вариантов на 1. Потом снова найти два самых маловероятных и снова объединить их в один новый, и так далее, построив конечном итоге бинарное дерево. В листьях этого дерева находятся числа. Внутренние вершины помечены множеством чисел из поддерева, корнем которого они являются. Корень дерева помечен множеством всех чисел. Это дерево и даёт алгоритм того, как нужно задавать вопросы Ване. Нужно двигаться с корня дерева и спрашивать Ваню, куда по этому дереву идти — влево или вправо (в каком из двух множеств вершин детей находится выпавшее число). Это дерево даёт рецепт самого быстрого в среднем метода угадывания числа, а ещё и алгоритм Хаффмана сжатия данных.
Задача 1.1: Изучите код Хаффмана. Докажите, что текст с исходной длиной символов N имеет в сжатом виде длину, ограниченную снизу величиной  бит и при удачных обстоятельствах его достигает.
бит и при удачных обстоятельствах его достигает.
ИТАК: Формула  возникает при решении задачи о минимальном среднем числе бинарных вопросов, которые нужно задать, чтобы выведать выпавшее значение случайной величины с распределением.
возникает при решении задачи о минимальном среднем числе бинарных вопросов, которые нужно задать, чтобы выведать выпавшее значение случайной величины с распределением.
Это второй способ прийти к формуле (1).
Для случайной величины  будем использовать такие обозначения для энтропии его распределения
будем использовать такие обозначения для энтропии его распределения  (ещё раз «перегрузим» функцию H):
(ещё раз «перегрузим» функцию H):  или
или  или
или  или
или 
Есть ещё один, третий, простой способ прийти к формуле энтропии, но нужно знать формулу Стирлинга.
Задача 1.2: Есть неизвестное битовое слово длины k (последовательность единиц и ноликов, всего k символов). Нам сообщили, что в нём 35% единичек. Чему равно  при больших k?
при больших k?
Ответ
Примерно  , где
, где 
Задача 1.3: У Вани есть неизвестное слово длины  в алфавите длины M. Он сообщил доли всех букв в слове —
в алфавите длины M. Он сообщил доли всех букв в слове —  .
.
Чему равно  при больших
при больших  ?
?
Ответ

ИТАК: Задача 1.3 и есть третий способ прийти к формуле (1).
Опр. 1.5: Информация в сообщении по некоторую случайную величину — это разница энтропий: 
Значения случайной дискретной величины можно рассматривать как буквы, каждая следующая буква слова — это просто очередное измерение случайной величины. Вот и получается, что информация в сообщении про некоторую случайную величину — это количество бит информации про измерения этой случайной величины нормированное на число измерений.
Задача 1.4: Чему равна энтропия дискретного распределения  ? Сколько информации содержится в сообщении
? Сколько информации содержится в сообщении  где
где  имеет распределение
имеет распределение  ?
?
Ответ:


Этот результат требует принятия. Как же так? — Нам сообщили ненулевую на первый взгляд информацию, отсекли самый вероятный вариант из возможных. Но неопределённость на множестве оставшихся вариантах осталась прежней, поэтому формула  даёт ответ 0.
даёт ответ 0.
Задача 1.5: Приведите пример конечного распределения и сообщения, которое не уменьшает, а увеличивает неопределённость.
Ответ:
 , а сообщение message = «это не первый элемент». Тогда
, а сообщение message = «это не первый элемент». Тогда 
Древняя мудрость «во многих знаниях многие печали» в этом контексте получает ещё одну интересную интерпретацию: современный мир, наука и человеческая жизнь таковы, что новые «сообщения» о истории и об устройстве мира только увеличивают неопределённость.
Дискретные распределения на счётном множестве значений, которые затухают по экспоненциальному закону (геометрические прогрессии), обладают свойством неизменности неопределённости при получении информации, что среди первых элементов нет правильного ответа. Менее, чем экспоненциальные затухания (например,  ), только растят неопределённость при откидывании первых элементов.
), только растят неопределённость при откидывании первых элементов.
Задача 1.6: Напишите формулу для энтропии распределения Пуассона
 ,
,  .
.
Найдите простое приближение для больших  .
.
Ответ

Задача 1.7: Дано распределение  вещественной случайной величины. Пусть
вещественной случайной величины. Пусть  — это сколько бинарных вопросов в среднем нужно задать, чтобы узнать какое-то выпавшее значение случайной величины с точностью до
— это сколько бинарных вопросов в среднем нужно задать, чтобы узнать какое-то выпавшее значение случайной величины с точностью до  . Найдите приближённое выражение
. Найдите приближённое выражение  для малых значений
для малых значений  .
.
Ответ:
Опр. 1.6: Энтропия непрерывного распределения равна

Здесь мы ещё раз перегрузили значение символа H для случая, когда аргумент есть функция плотности вероятности (PDF).
Задача 1.8: Даны два распределения  и
и  двух вещественных случайных величин. К чему стремится разница
двух вещественных случайных величин. К чему стремится разница  при
при  ?
?
Ответ:

Задача 1.9: Чему равна энтропия нормального распределения  ?
?
Ответ:

Задача 1.10: Напишите формулу для энтропии экспоненциального распределения  .
.
Задача 1.11: Случайная величина  является смесью двух случайных величин, то есть её распределение
является смесью двух случайных величин, то есть её распределение  есть взвешенная сумма распределений:
есть взвешенная сумма распределений:

Пусть множество значений, которые принимает  , не пересекается с множеством значений
, не пересекается с множеством значений  , другими словами, пусть носители этих двух случайных величин не пересекаются. Найдите выражение для энтропии
, другими словами, пусть носители этих двух случайных величин не пересекаются. Найдите выражение для энтропии  через энтропии
через энтропии  и
и  .
.
Ответ

Последнее равенство тут возможно только благодаря тому, что носители  и
и  двух распределений по условию задачи не пересекаются. Дальше мы это выражение преобразуем в
двух распределений по условию задачи не пересекаются. Дальше мы это выражение преобразуем в

В этой задаче хотелось показать, что даже в простом случае непересекающихся носителей энтропии не просто складываются с соответствующими весами, а появляется добавка  . Если веса равны ½, то эта добавка равна 1.
. Если веса равны ½, то эта добавка равна 1.
Интерпретация формулы такая: результат измерения с вероятностью  находится в
находится в  и с вероятностью
и с вероятностью  — в
— в  и соответственно нам достанется неопределённость
и соответственно нам достанется неопределённость  значений на множестве
значений на множестве  или неопределённость
или неопределённость  на множестве
на множестве  . Но чтобы выяснить, в каком из них находится измерение мы потратим в среднемвопросов.
. Но чтобы выяснить, в каком из них находится измерение мы потратим в среднемвопросов.
Из этого в частности следует, что смесь с коэффициентами ½ двух нормальных величин с одинаковой дисперсией, но сильно разными средними, имеет энтропию на 1 больше, чем энтропия одного нормального распределения. Носители нормальных случайных величин равны всей прямой, а значит пересекаются, но в случае сильно разных средних можно этим пренебречь.
Задача 1.12: Случайная величина  равновероятно равна 0 или 1. Случайная величина
равновероятно равна 0 или 1. Случайная величина  зависит от : если
зависит от : если  , то
, то  сэмплируется из
сэмплируется из  , а если
, а если  , то сэмплируется из . Сколько бит информацию про случайную величину содержится в сообщении
, то сэмплируется из . Сколько бит информацию про случайную величину содержится в сообщении  (как функция от
(как функция от  )?
)?
Ответ
Есть такой численный ответ:
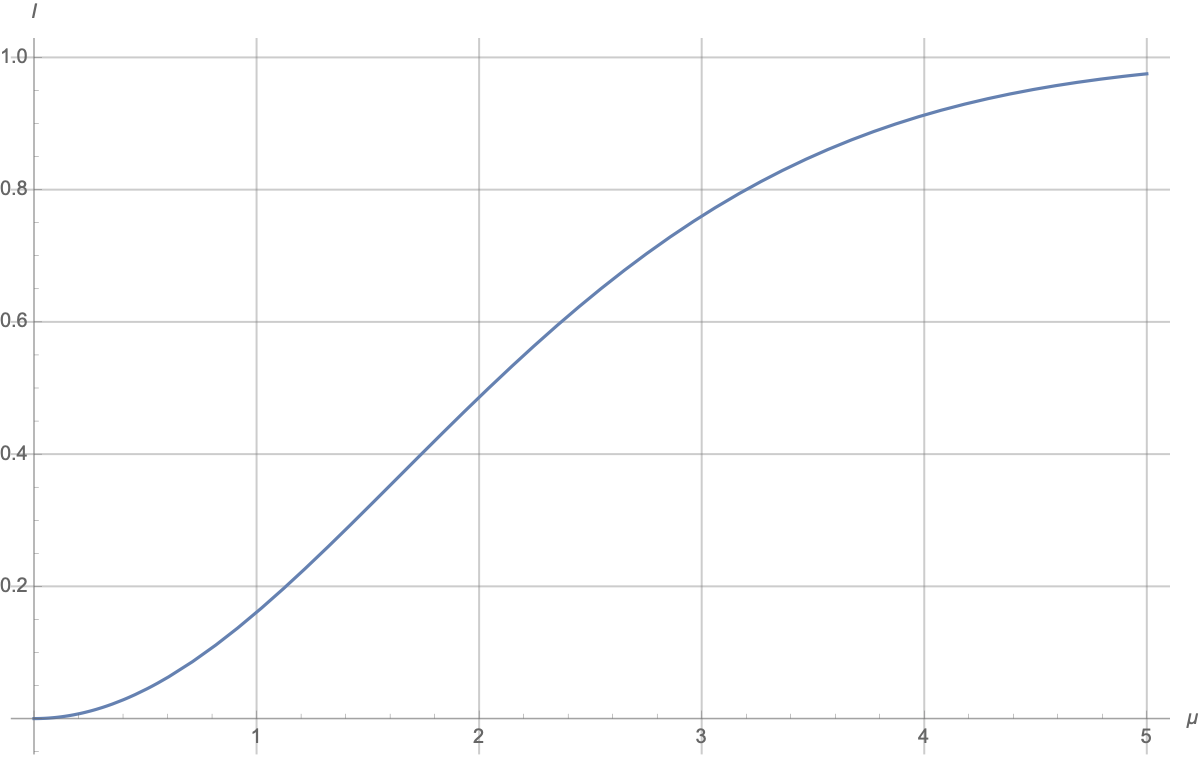
Понятно, что график начинается с 0 и стремится к 1:
Задача 1.13: Случайная величина устроена так: сначала сэплируется число  из экспоненциального распределения со средним
из экспоненциального распределения со средним  , а потом сэплируется случайное число
, а потом сэплируется случайное число  из распределения Пуассона, с параметром
из распределения Пуассона, с параметром  . Мы получили сообщение, что одно измерение дало
. Мы получили сообщение, что одно измерение дало  . Сколько бит информации мы получили про случайную величину
. Сколько бит информации мы получили про случайную величину  ? Дайте численный ответ. Сколько бит информации даст последовательность измерений 10, 9, 11, 8, 10?
? Дайте численный ответ. Сколько бит информации даст последовательность измерений 10, 9, 11, 8, 10?
Ответ
 .
.
 .
.
Задача 1.14: Случайная величина устроена так: сначала один раз сэплируется число из бета-распределения с параметрами  , а потом сэплируется случайное число из биномиального распределения с параметрами
, а потом сэплируется случайное число из биномиального распределения с параметрами  . Мы получили сообщение, что одно измерение
. Мы получили сообщение, что одно измерение  дало 10 (то есть 10 из 100 бросаний монетки выпали орлом). Сколько бит информации мы получили про скрытую случайную величину
дало 10 (то есть 10 из 100 бросаний монетки выпали орлом). Сколько бит информации мы получили про скрытую случайную величину  ? Дайте численный ответ. Сколько бит информации даст последовательность измерений 10, 9, 11, 8, 10?
? Дайте численный ответ. Сколько бит информации даст последовательность измерений 10, 9, 11, 8, 10?
Задача 1.15: Случайные величины  сэмплированы из бета-распределения с параметрами . Сами нам неизвестны, но нам дали 10 измерений
сэмплированы из бета-распределения с параметрами . Сами нам неизвестны, но нам дали 10 измерений  из 10 биномиальных распределений с параметрами
из 10 биномиальных распределений с параметрами  и это наше знание про
и это наше знание про  . Сколько бит информации мы получим в среднем про случайную биномиальную величину с параметрами и когда нам назовут значение
. Сколько бит информации мы получим в среднем про случайную биномиальную величину с параметрами и когда нам назовут значение  ? А если известны абсолютно точно (случай
? А если известны абсолютно точно (случай  )? А если 10 заменить на
)? А если 10 заменить на  ?
?
Эту задачу можно сформулировать на языке ML так: у нас есть категориальная фича для прогноза булевой величины ('кликнет пользователь на баннер или нет', aka binary classification problem). Насколько хорош будет наш прогноз, если в обучающих данных нам известны лишь исторические данные по кликам по этим 10 категориям?
для прогноза булевой величины ('кликнет пользователь на баннер или нет', aka binary classification problem). Насколько хорош будет наш прогноз, если в обучающих данных нам известны лишь исторические данные по кликам по этим 10 категориям?
