Зачем С++ в Такси? Доклад Яндекса
Бэкенд первой версии Яндекс.Такси, которая вышла в 2011 году, был написан на Python. Мы довольно долго не меняли основной язык, но постепенно пришли к идее о необходимости С++ в стеке технологий. Перед вами доклад о том, что мы переписали в первую очередь и почему, а также о трюках С++, которые помогают нам справляться с ростом.— Добрый день. Меня зовут Александр Голубев, и сегодня я вам объясню, зачем C++ появился в Такси. Обсудим, как он развивался и какие проблемы мы встречали.
Сначала, чтобы быть не совсем noname-персоной, я немного расскажу о себе. Я руковожу сектором разработки инфраструктуры в технологической платформе, которая входит в бизнес-группу электронной коммерции и перемещения Яндекса. В эту бизнес-группу входит Такси, Еда, Лавка, Драйв, Доставка, Маркет и ряд других направлений. В этой технологической платформе я отвечаю за сервисы коммуникаций, поиск водителей на заказ и инфраструктуру партнерского продукта.
Общий стаж моей работы в IT-сфере — 18 лет. За это время я успел поработать с корпоративными мессенджерами, с VoIP-телефонией, с DPI на магистральных каналах, в облачном хранилище размером в десятки петабайт. Делал антивирусные SDK и, собственно, работал в агрегаторе Такси.
В сегодняшнем докладе я дам ответ на следующие вопросы: когда и зачем появился C++ в Яндекс.Такси, как эволюционировало его использование и какие «велосипеды» помогают нам в решении задач. Особого хардкора не будет, но, надеюсь, будет интересно.

Прежде чем приступить к основной части доклада, давайте взглянем, что есть у агрегаторов такси, какие языки они используют. Данные взяты из открытых источников, здесь можно наблюдают эволюцию разработки. Большинство агрегаторов начинали с простых технологий, которые позволяли двигаться быстро. Это мог быть Python, Ruby, PHP. Затем, когда они дорастали до этапа развития, на котором привычные технологии перестали отвечать потребностям, возникали более производительные языки, например Go, C++ или Java.
Яндекс.Такси не был исключением, он начался в 2011 году с языка Python.
Начало. 2011 год
Почему? Потому что у команды, которая этим занималась, была экспертиза в Python. На этом языке писали достаточно много людей, их легко было нанять. Python позволяет быстро прототипировать и достаточно быстро разрабатывать. Производительность на этом этапе не критична, на нее обычно не обращают внимания при выборе языка, на котором стартует какой-либо новый сервис.
Немаловажное свойство — широкий выбор библиотек. Такси в своем развитии использует и внешние библиотеки — например, для построения деревьев для задач поиска, и внутрияндексовые — например, коннекторы к базам, которые есть только внутри Яндекса. Это немаловажный пункт при выборе.
Был Python, был Twisted как фреймворк, активно использовалась многопоточность и асинхронность. В то время водителей на линии работало до 10 тысяч одновременно. Было подключено более 200 партнеров-таксопарков, это позволяло выполнять более 200 тысяч заказов в неделю.
Если вам интересно, вы можете посмотреть доклад 2014 года Дмитрия Курилова, рассказывающий о том, как это работало, какие проблемы решались и как работали с асинхронностью и многопоточностью в Python:
Следующие слайды взяты как раз из того самого доклада. Здесь представлена архитектура Такси. Есть пользователи, есть монолит Такси, есть роутер, которым занимаются маршрутизаторы, есть партнеры, которые предоставляют информацию о доступных водителях, и есть трекер. Трекер решает конкретную задачу: осуществляет геопоиск подходящих водителей на заказ. В нашем дальнейшем рассказе он наиболее интересен.
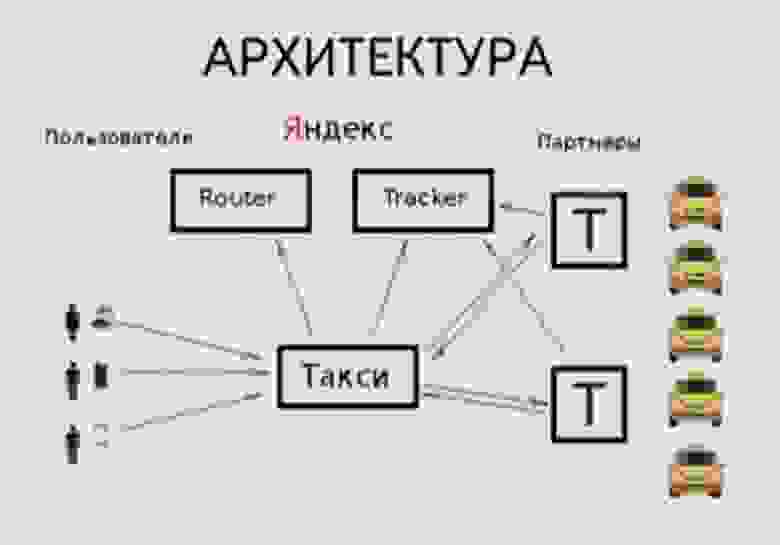

Примерно как он работал? Он брал позиции водителей от всех партнеров, строил по ним дерево для геопоиска, упаковывал его и раздавал другим потокам, чтобы они могли осуществлять по нему поиск.
Здесь начали всплывать типичные проблемы второго Python. В первую очередь — GIL, который не позволял из одного процесса работать с данными эффективно. Упаковка и построение дерева — достаточно CPU-емкая операция. Соответственно, input и output там нет и асинхронность в рамках Python не очень эффективна. К тому же Python — не очень производительный язык, он не предназначен для того, чтобы молотить цифры, а построение деревьев и поиск по ним — это как раз по большей части обход деревьев и математика.
Когда мы строим дерево геопоиска, нам важны не только позиции водителей, но и их статус, какой у водителя профиль, какие классы он может перевозить, согласен ли он на перевозку животных. Возможно, он заблокирован какими-либо системами. Эти данные должны быть достаточно горячими, должны быть близки. Здесь возникает потребность в кэшировании. Но Python не очень подходит и для кэширования данных в памяти, потому что из-за GIL и других ограничений он работает в несколько процессов, которые не имеют общей памяти. Эти проблемы становятся узким местом языка.
Отдельно отмечу, что в сфере такси задержки очень важны. Почему? Потому что Такси работает с реальным миром. Автомобили двигаются, и при средней скорости в городе 60 км/ч за минуту автомобиль проезжает километр, а за секунду — 17 метров. И каждая секунда задержки принятия данных в обработку, в дерево поиска, приводит к ошибкам позиционирования, а они — к тому, что водитель может проехать нужный поворот, то есть к снижению эффективности, к скачкам времени ожидания, к снижению качества Такси как серсвиса.
Чтобы решить эти проблемы, требовалось выбрать другой стек технологий для решения задач, позволяющих работать эффективно и с кэшированием, быстрее обрабатывать потоки данных.
И выбрали C++. Почему? Причины те же самые. Экспертиза. C++ — один из основных языков разработки в Яндексе, а на рынке много кадров и их легко нанимать. Скоростью разработки и прототипирования пришлось пожертвовать, зато у нас появилась нужная нам производительность и также широкий выбор библиотек. Какие были альтернативы? В то время — напомню, это 2015 год — разработчиков на Go было достаточно мало на рынке, да и внутри Яндекса было недостаточно опыта, чтобы эффективно решать задачи при помощи Go. У Java есть Garbage Collector, который может вносить свои коррективы. А Rust? О нем и сейчас больше говорят, чем реально используют.
Первый сервис на C++ в Такси. 2015 год
Первый сервис на C++ появился в Такси в 2015 году. Это был Tracker. Он наследовал не только зону ответственности, но и имя своего прародителя. Разрабатывали его на 14-м стандарте, очень активно использовали clang-format. Он стал нашим стандартом. Я его выписал отдельно, потому что эта технология позволяет нам решить две проблемы.
Во-первых, код становится единообразным, легко читается. Во-вторых, убираются все холивары и споры о пробелах на ревью. Форматирование стандартизировано, рекомендую тем, кто не использует. У нас есть ряд хаков, которые не позволяют неотформатированный код запушить в репозиторий, блокируют. Это приводит к тому, что код у нас везде выглядит единообразно.
В качестве фреймворка выбрали Fastcgi-deamon, это тоже опенсорс-разработка Яндекса. Вы можете ознакомиться с ней на GitHub, она имеет пул потоков и синхронно обрабатывает запросы. В том числе благодаря тому, что мы выбрали эту технологию, у нас в дальнейшем появился Userver, так как мы в поисках решения поняли, что лучше делать фреймворк самостоятельно. Для сборки использовали CMakeLists, у нас было дерево для построения геоиндексов, множество кэшей, и на всем этом у нас крутились данные о более чем 200 тысячах водителей на линии единовременно.
Но сервис не стоял на месте, развивался. Изначально в нем был только индекс свободных водителей. Но для аналитики, для лучшего понимания того, что происходит вокруг, и чтобы качественнее сделать мониторинги, добавился отдельный индекс занятых водителей. Для удобства работы с ним и для расчета более разнообразного числа метрик — в том числе и для определения повышенного спроса — в индекс занятых попадают свободные водители. А в индекс свободных въезжают «цепочки» с занятыми водителями — теми, которые сейчас выполняют заказ, но он у них близится к концу, и можно выдать следующий. Дополнительно появился индекс с очередями в аэропорту. Это аналитический режим, который позволял видеть вообще всех участников системы, вне зависимости от того, насколько они активны, заблокированы они или нет.
И появился дорожный граф. Он позволяет сильно поднять эффективность поиска за счет того, что мы при поиске учитываем дорожную обстановку. Обычный геопоиск ищет какое-то количество ближайших водителей, которые дальше отдельно маршрутизируются. В отдельных сценариях он находит не совсем идеальных для этого заказа водителей.
Поиск на графе учитывает дорожную обстановку и находит тех водителей, которые действительно находятся вблизи. Здесь выбор языка сыграл нам в плюс, так как у Яндекса есть свои карты. Мы просто взяли библиотеку дорожного графа Яндекса, построили на нем свою систему и встроили ее в сервис. Это позволило нам более эффективно искать водителей.
И все это развитие делалось разными командами, в рамках разных целей и задач. В, соответственно, у сервисе не было какого-то одного человека, который видит, как сервис должен развиваться, знает, куда он должен двигаться. Код потихонечку начинал превращаться в спагетти. Большие функции на несколько экранов, где последовательно шли разные проверки. Это все легко было сломать, потому что не всегда можно было понять, куда можно безопасно встроиться и на что это повлияет.

Кроме того, трудно исследовать проблемы, понимать, что и где надо улучшить. Все это приводило к высокому порогу вхождения. Если человек приходил с новой функциональностью, то он достаточно много времени тратил на исследования и на понимание, как все работает. Было трудно поменять что-либо. Например, добавление графа привело к «шрапнельным» правкам, так как данные пришлось пробрасывать от самого начала запроса до самых его глубин. Это привело нас к мысли, что мы в развитии этого сервиса зашли в тупик и надо его переосмыслить.
Второй подход к задаче. 2019 год
В 2019 году у нас было движение к микросервисности. У нас уже появилась ранняя версия Userver, который должен был прийти на замену Fastcgi. К слову, с самим Fastcgi у нас не было проблем. Дело в том, что у него пул потоков практически не болел в этом сервисе за счет того, что мы в основном упирались в CPU. У нас почти отсутствовал ввод-вывод в обработке запросов.
У Fastcgi-deamon кончался пул потоков в сервисах, где большую часть операций составляет ввод-вывод, обращение к другим сервисам, хождение в базу, при любых увеличениях задержки сети, или если смежный сервис начинал подтупливать. Fastcgi просто начинал отбрасывать новые соединения. У нас такой проблемы не было, но мы двигались со всеми вместе и решили перейти на Userver.

Мы выписали все, что хотим получить от новой платформы. Это было отображением проблем, которые у нас были. Мы хотели переиспользовать этот сервис в других сценариях. К нам уже присоединилась Еда, где были схожие задачи — поиск курьера на доставку заказа. Нужно было гибко расширять, конфигурировать.
Сервис должен быть отказоустойчивым. Нужно предусмотреть ручную и автоматическую деградацию функциональности, чтобы в случае резких всплесков заказов или проблем смежников мы могли бы ухудшить качество поиска, но продолжать работать и выполнять заказы. Функциональность должна добавляться легко и просто. Должны быть прочерчены четкие зоны ответственности, мы должны пережить активный рост, уметь масштабироваться.
К слову, большинство из этих требований решаются при помощи такой замечательной вещи, как объектно-ориентированное программирование. Здесь C++ тоже сыграл нам на пользу.
Что у нас было? 17-й стандарт. Мы по-прежнему с любовью использовали clang-format и продолжаем его использовать. В качестве фреймворка стал использоваться Userver. Появилась кодогенерация, причем много. Мы кодогенерируем и методы, и конфиги, и эксперименты, и нашу внутреннюю логику. Эта кодогенерация в основном строится на формате YAML. У нас сразу было KD-дерево для геопоиска, дорожный граф как основной инструмент, достаточно много кэшей. И сотни тысяч водителей на линии.
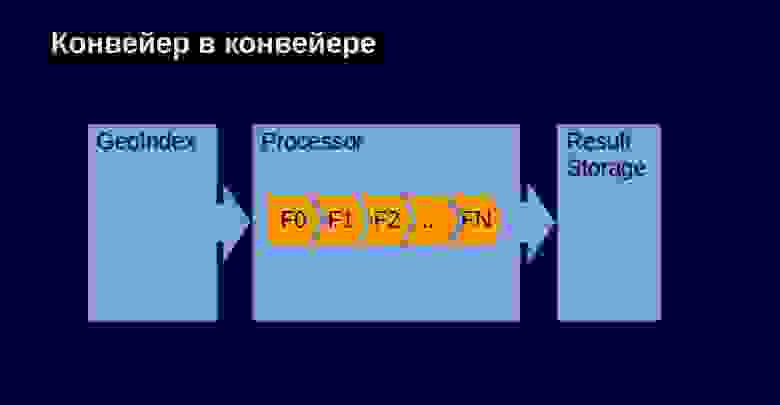
Чтобы построить эту схему, мы решили сделать такой конвейер. У нас есть индекс — отдельная сущность. Есть процессор, который пропускает тех водителей, которых нам предлагает геоиндекс, через цепочку фильтрующих логик. Информацию о водителях, которые прошли успешно всю цепочку, мы складируем в хранилище.
Я покажу интерфейсы, которые у нас получились. Они очень тривиальны, их очень легко реализовать. За счет этого расширение логик выполняется очень просто. У нас есть фильтр, который реализовывает фильтрующую логику. У него один виртуальный метод, который принимает водителя, его контекст и просто отвечает, подходит ли он под представленные требования.
class Filter {
public:
Filter(const FilterInfo& info) : info_(info) {}
virtual ~Filter() = default;
const FilterInfo& info() const { return info_; }
virtual Result Process(const GeoMember& member, Context& context) const = 0;
protected:
const FilterInfo& info_;
};
Есть геоиндекс, принимающий параметры поиска и ссылку на процессор, который будет обрабатывать найденных водителей.
class GeoIndex {
public:
virtual ~GeoIndex() = default;
virtual std::string name() const = 0;
virtual SearchInfo Search(const formats::json::Value& params,
const Environment& environment,
Processor& processor) const = 0;
};
Есть интерфейс хранилища, который принимает водителей, прошедших все проверки, и может ответить, хватит ли искать или нужно еще.
class ResultStorage {
public:
virtual ~ResultStorage() = default;
virtual void Add(const GeoMember& member, filters::Context&& context) = 0;
virtual size_t size() const = 0;
virtual bool full() const = 0;
virtual std::vector Extract() = 0;
virtual void Finish() {}
};
И сам процессор, который получает в конструкторе некоторую цепочку фильтров, прогоняет через нее водителей и отправляет результаты в хранилище.
class Processor {
public:
virtual ~Processor() = default;
virtual std::string name() const = 0;
virtual size_t size() const = 0;
virtual bool full() const = 0;
virtual void SearchCallback(const GeoMember& member,
filters::Context&& context) = 0;
virtual void Finish() = 0;
};
Сейчас это работает в трех дата-центрах на 74 хоста. У нас почти две тысячи ядер. Сотни тысяч водителей онлайн. Обрабатываем мы 20 тысяч запросов в секунду. Цифра кажется не очень большой. Один сервис, делающий простые операции, может обрабатывать столько же на одном хосте, даже на одном ядре.
У нас же в основном все операции сложные — геопоиск, обход графа, проверки водителей с сотнями фильтров на разные условия. Это получение класса водителя, проверки блокировок, не устал ли он, есть ли у него лицензия, удовлетворяет ли он требованиям в запросе, что у него с балансом, может ли он принимать данный способ оплаты. Таких проверяющих логик у нас более ста.
Этими ста логиками мы каждую секунду для этих двадцати тысяч запросов пропускаем 30 млн водителей. У нас шесть разных индексов, деревья, граф, несколько очередей для разных задач. Теперь у нас есть и отдельные индексы поиска для пеших курьеров, которые не привязаны к автомобильным дорогам.
Более 60 кэшей хранят полную информацию об водителях так, чтобы мы могли быстро и оперативно отвечать, не ходя за данными в какие-либо сервисы. Потому что если мы 30 млн раз в секунду будем ходить и спрашивать какую-либо базу:, а дай мне метаданные по данному водителю, то, кажется, ни одна база не выдержит.
В этом проекте участвовали 40 с лишним разработчиков, при этом он сохранил свою простоту и надежность. Каждая фильтрующая логика — это просто отдельная папочка, в которой хранятся ее модели, сама реализация и необходимые для данной логики кэши, если они требуются.
Дальше я хотел бы немножко показать «велосипеды», которые мы используем, чтобы иметь возможность достичь этих цифр.
Конкурентный словарь индексов
В системе миллионы водителей. Не все из них активны, но большинство из этих водителей имеют пересекающиеся данные, не уникальные. Это может быть класс или модель автомобиля. Соответственно, хранить эти миллионы записей в виде строк не рационально.
Возникла задача: хорошо бы уметь быстро и эффективно преобразовывать строки из ограниченного списка. Например, ясно, что классов будет меньше 200 или что моделей, которые активно участвуют, несколько тысяч, не больше. Можно просто преобразовать эти строковые описания в некое число, положить его в профиль. Это упростит сравнение, уменьшит потребление памяти и в целом повысит эффективность.
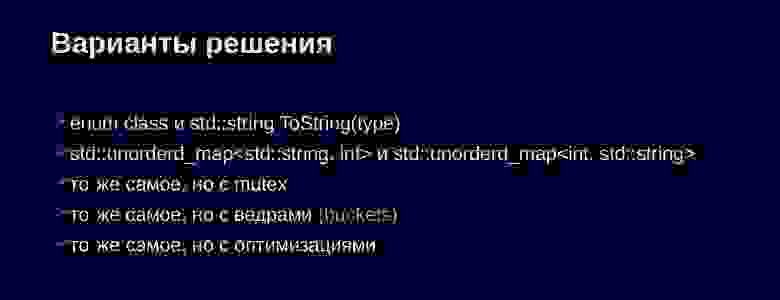
Можно для этого использовать class enum, с него большинство таких ситуаций и начиналось. Из enum можно получить строку, из строки — распарсить enum. Но здесь возникает проблема: с развитием этот enum начинает разрастаться. При добавлении туда данных все исходники, которые его используют, должны пересобраться, а проект у нас и так собирается не моментально.
Получается единое место, куда все пишут. Это приводит и к конфликтам на пул-реквестах, оттуда забывают удалять какую-либо информацию. Там бывают ошибки, опечатки, сделали копипаст и забыли поправить. В итоге из enum получается не та строка, или из строки получается не тот enum. Можно было бы взять два unordered_map, использовать их для прямого/обратного индекса. Но нам нужно уметь с этим работать конкурентно, и это требует mutex, а mutex приводит к блокировкам, все это снижает эффективность. Можно, конечно, побить эти индексы на некие ведра, разделить их на множества так, чтобы минимизировать количество блокировок в системе. Но можно сделать все то же самое, но более эффективным способом.
Итак, у нас появился конкурентный словарь индексов. Он параметризуется максимальным количеством ключей, которые могут быть количеством ведер. Здесь мы отдельно принимаем тип mutex, потому что этот класс не всегда работает в контексте корутины, и иногда мы хотим использовать не mutex Userver, а mutex-стандарт библиотеки. Есть типы ключа, хэша. Чтобы не хранить дважды один и тот же ключ в прямом/обратном индексе, мы в прямом индексе из строки храним не саму строку, а ссылку на нее.
template
class ConcurrentIdxDict {
using Key = std::string;
using Hash = std::hash;
using KeyCRef = std::reference_wrapper;
struct KeyCRefEq {
bool operator()(KeyCRef l, KeyCRef r) const {
const auto& ro = r.get();
const auto& lo = l.get();
return &ro == &lo || ro == lo;
}
};
using Map = std::unordered_map;
struct Bucket {
constexpr static const size_t kSubBucketHint =
kMaxKeysCount / kBucketsCount + 1; // prealloc hint
Map storage = Map(kSubBucketHint);
mutable Mutex lock;
};
};
Определяем структуру ведра, которое содержит индекс для данного подмножества и mutex. Причем здесь мы знаем, каким будет максимальное число элементов и на сколько частей мы побили. Поэтому можем рассчитать, примерно сколько в данном индексе будет элементов, и заранее предалоцировать место для них, чтобы не делать это в процессе работы.
Есть всего лишь четыре поля. Мы знаем, сколько будет частей, и можем сразу объявить их в виде массива, зная, сколько будет ключей. И два счетчика: счетчик следующего элемента для получения его идентификатора и счетчик для учета, сколько ключей мы уже сохранили. Почему их два, будет видно дальше.
template
class ConcurrentIdxDict {
private:
std::array buckets_;
std::array keys_;
std::atomic next_key_idx_;
std::atomic stored_keys_cnt_;
};
Есть примитивы, которые позволяют получить нужное нам подмножество. Мы легко высчитываем индекс. Если мы решили не делить на подмножества, то всегда можем просто возвращать готовый индекс, нулевой.
static size_t GetBucketIdx(const Key& key) {
if constexpr (kBucketsCount == 1) return 0;
static const Hash hasher;
return hasher(key) % kBucketsCount;
}
Bucket& GetBucket(const Key& key) {
return buckets_[GetBucketIdx(key)];
}
const Bucket& GetBucket(const Key& key) const {
return buckets_[GetBucketIdx(key)];
}
Если же у нас несколько частей, то считаем хэш от ключа, остатком от деления получаем нужный индекс и две реализации получения bucket: константный и не константный.
Как выглядит добавление, получение индекса для нового ключа? Здесь все делится на три части. Сначала мы проверяем, есть ли такой ключ. Если да, возвращаем готовый индекс. Потом мы блокируем данные в bucket уже на запись, перепроверяем, не успели ли мы в него записать значение. Если записали — возвращаем готовый индекс. Если нет — получаем новый индекс через счетчик. По этой позиции кладем сам ключ в хранилище ключей.
uint16_t GetOrCreateIdx(const Key& key) {
auto& bucket = GetBucket(key);
{
std::shared_lock up_lk(bucket.lock);
const auto it = bucket.storage.find(key);
if (it != bucket.storage.cend()) return it->second;
}
uint16_t idx = kMaxKeysCount;
{
std::unique_lock u_lk(bucket.lock);
const auto it = bucket.storage.find(key);
if (it != bucket.storage.cend()) return it->second;
idx = next_key_idx_.fetch_add(1);
const auto& r = (keys_[idx] = key);
bucket.storage.emplace(r, idx);
}
while (!stored_keys_cnt_.compare_exchange_strong(idx, idx + 1)) {
engine::Yield();
}
return idx;
}
Делаем это абсолютно безопасно, потому что массив уже предалоцирован. Никто по этому индексу не может писать одновременно. И так как мы этот ключ еще не зарегистрировали как сохраненный, то и читать из него никто не будет. Ссылку на строку в этом хранилище мы используем как ключ в прямом индексе, который позволяет нам получить из строки идентификатор.
Снимаем данную блокировку и последним фрагментом гарантируем, что мы последовательно будем увеличивать счетчик сохраненных ключей. Почему? Потому что у нас может быть несколько bucket. Мы можем писать в них параллельно. И может так случиться, что первая запись получила ключ один, вторая получила ключ два и освободилась раньше. Мы не можем сказать, что мы сохранили второй ключ, потому что тогда может произойти обращение к первому индексу, а ключ просто может быть еще не сохранен физически.
И мы просто гарантируем в цикле, что будем увеличивать по порядку счетчик сохраненных ключей. Сначала запишем один и только после этого два. Чтобы облегчить эту операцию в рамках асинхронного фреймворка, мы вызываем Yield, который позволяет не крутить этот цикл вхлостую, а заняться чем-нибудь более полезным.
Получение индекса и ключа по индексу тривиальны — ряд проверок и обращение в хранилище. Все элементарно.
std::optional FindIdx(const Key& key)
const { const auto& bucket = GetBucket(key);
std::shared_lock sh_lk(bucket.lock);
const auto it = bucket.storage.find(key);
if (it != bucket.storage.cend()) return it->second;
return std::nullopt;
}
const Key& GetKey(size_t idx) const {
const size_t max_sz = GetKeysSize();
if (!max_sz || idx >= max_sz)
throw std::out_of_range("unexpected idx");
while (stored_keys_cnt_.load() <= idx) {
engine::Yield();
}
return keys_[idx];
} Динамическое перечисление с эффективным списком
Но иногда нам недостаточно получить некий индекс из строки. Мы хотим работать со списком строк. Например, это могут быть классы автомобиля — Эконом, Комфорт, Комфорт+, Бизнес. Могут быть экзамены — водители сдают экзамены на работу в Детском тарифе или в VIP-классе. Хотелось бы уметь работать и с этими списками быстро и эффективно. Можно было бы преобразовать строки в индексы, положить их в вектор. Но в нем неудобно искать. Надо писать код, который будет бежать по нему и проверять значение.

Причем если вдруг окажется, что вектор достаточно большой, этот поиск будет иметь линейную сложность. unordered_set помогает эту задачу решить, но здесь возникают другие вопросы:, а если мы хотим слить два set или проверить вхождение одного в другого? Подобное также приводит к линейной сложности этих алгоритмов.
Но в стандартной библиотеке есть bitset. У нас уже есть ограничение по количеству элементов. Мы гарантируем в нашем конкурентном словаре индекса, что все элементы будут идти по порядку, что не будет пропусков. Здесь можно посмотреть в сторону bitset. Естественно, сырой bitset использовать не очень удобно. Давайте попробуем его улучшить. Для начала сделаем простой класс, который преобразует строку в наш идентификатор и назад. Он параметризуется типом нашего индекса. Это сделано для того, чтобы использовать strong definition. То есть мы делаем class enum и потом с ними работаем.
template
class Mapper {
public:
using Type = T;
static constexpr size_t kMaxCount = MaxCount;
static constexpr Type kUnknown = static_cast(kMaxCount);
protected:
using Map = utils::ConcurrentIdxDict;
Mapper() = default;
static Map map_;
};
Указываем количество элементов, этими данными параметризуем конкурентный словарь индексов и позволяем из него преобразовывать строку в индекс, а индекс в строку. Все это делается тривиально, с минимальными проверками. Останавливаться здесь не будем.
static Type Parse(const std::string& name) {
if (name.empty()) return kUnknown;
try {
return static_cast(map_.GetOrCreateIdx(name));
} catch (const std::exception&) {
}
return kUnknown;
}
static const std::string& GetName(const Type value) {
static const std::string kUnknownName;
if (value == kUnknown) return kUnknownName;
return map_.GetKey(static_cast(value));
}
Далее мы можем на основании этого класса построить наш список. Он принимает Mapper, берет из него количество элементов, типы и определяет сам bitset подходящей размерности.
template
class Mask {
public:
using Type = typename Mapper::Type;
static constexpr Type kUnknown = Mapper::kUnknown;
using BitSet = std::bitset;
Mask() = default;
private:
explicit Mask(const BitSet& value) : value_(value) {}
static constexpr uint16_t Convert(Type value) {
return static_cast(value);
}
static constexpr Type Convert(uint16_t value) {
return static_cast(value);
}
BitSet value_{0};
};
Работать с bitset очень легко. Мы говорим — по такому-то ключу выстави true или false. Если нужно преобразование строки, оно также добавляется элементарно.
void Add(const Type value) {
if (value == kUnknown) return;
value_.set(Convert(value), true);
}
void Remove(const Type value) {
if (value == kUnknown) return;
value_.set(Convert(value), false);
}
void Add(const std::string& name) {
Add(Mapper::Parse(name));
}
void Remove(const std::string& name) {
Remove(Mapper::Parse(name));
}
Все проверки упрощаются, в bitset есть готовые методы, мы можем их использовать. Можем проверить, что в одном списке есть хотя бы одно вхождение, тривиально через логический оператор И.
bool Provides(const Mask& mask) const {
return (value_ & mask.value_).any();
}
bool Provides(const Type value) const {
if (value == kUnknown) return false;
return value_[Convert(value)];
}
bool Provides(const std::string& name) const {
return Provides(Mapper::Parse(name));
}
И мы не только можем использовать готовые, то есть сравнивать, есть ли пересечение, но и делать свои кастомные операции, которые ведут себя, возможно, неожиданно и странно.
Mask operator&(const Mask& rhs) const noexcept {
Mask result;
result.value_ = value_ & rhs.value_;
return result;
}
Mask operator|(const Mask& rhs) const noexcept {
Mask result;
result.value_ = value_ | rhs.value_;
return result;
}
Mask operator-(const Mask& rhs) const noexcept {
Mask result;
result.value_ = value_ & ~rhs.value_;
return result;
}
Например, у нас есть оператор «минус», он просто убирает из одного списка все элементы, которые есть в другом. То есть в какой-то степени накладывает реверсивную маску.
Сюда же можно добавить итераторы, чтобы иметь возможность итерироваться и перебирать все заведенные типы. Все это сильно упрощает нам работу.
class ConstIterator {
public:
using iterator_category = std::input_iterator_tag;
using difference_type = std::ptrdiff_t;
using value_type = Type;
using pointer = Type*;
using reference = Type&;
ConstIterator& operator++() {
for (++cur_; cur_ < ref_.size(); ++cur_)
if (ref_[cur_]) break;
return *this;
}
bool operator==(const ConstIterator& rhs) const { return !(*this != rhs); }
bool operator!=(const ConstIterator& rhs) const { return cur_ != rhs.cur_; }
Type operator*() const { return static_cast(cur_); }
static ConstIterator begin(const BitSet& ref) {
if (ref.none()) return ConstIterator::end(ref);
for (size_t i = 0; i < ref.size(); ++i)
if (ref[i]) return ConstIterator(ref, i);
return ConstIterator::end(ref);
}
static ConstIterator end(const BitSet& ref) {
return ConstIterator(ref, ref.size());
}
private:
ConstIterator(const BitSet& ref, const size_t cur) : ref_(ref), cur_(cur) {}
const BitSet& ref_;
size_t cur_;
};
При этом мы еще и эффективно начинаем, с точки зрения потребления ресурсов, работать с такими задачами. Можно определить тип strong definition, объявить Mapper, список на нем и успешно решать нужные нам задачи.
namespace models {
enum class Exam : uint16_t {}; // strong definition using ExamMapper = dynamic_enum::Mapper; using Exams = dynamic_enum::Mask;
} // namespace models
UTEST(DynamicEnum, Sample) {
models::Exams exams{{"comfortplus", "vip"}};
EXPECT_FALSE(exams.empty());
EXPECT_TRUE(exams.Provides("comfortplus"));
EXPECT_TRUE(exams.Provides(models::ExamMapper::Parse("vip")));
} Контекст фильтров
Как уже я говорил, у нас есть фильтрующие логики, у них — некий контекст. Фильтры могут добавить туда информацию, а потом другие фильтры могут ее использовать. Например, какой-то из фильтров может получить профиль водителя, запомнить его. Другие профили уже не будут ходить в кэши, доставать оттуда данные. Они просто возьмут эти данные из контекста. Для упрощения этой операции нам нужно было что-то придумать, сделать хранилище для обмена информацией между фильтрами.
Самый простой вариант — сделать структуру, в которой объявить все нужные поля нужного нам типа, но здесь возникает все та же проблема. Фильтров у нас более 100. Постоянно добавляются новые, отмирают старые. В эту структуру будут писать все. При любой модификации будет пересобираться бо́льшая часть проекта. Туда будут что-то добавлять, но, может быть, забывать удалять. Получится такая структура-помойка на несколько экранов. У нас такое уже было в нескольких местах, это ужасно. С этим очень неприятно работать, особенно пытаться понять, а вот это поле — оно вообще где-то используется или его просто забыли удалить?
Можно было сделать unordered_map, который по некому ключу хранит std: any. Можно по этому ключу достать данные, преобразовать их в нужные типы и работать с ними. И мы так, на самом деле, в начале и сделали. Но так как у нас 100 фильтров, 30 млн водителей в секунду, которых мы рассматриваем, то нам хорошо бы обращаться к этой map эффективно. Почему бы не использовать enum class, который позволит по некому числовому представлению получать нужные нам данные? А если в enum ключи лежат по порядку, то, может быть, нам нужен не unordered_map, а хватит и вектора? Мы просто по позиции достанем оттуда нужные нам данные. Но здесь возникает та же проблема: нужен этот большой enum class, где все будут добавлять записи, забывать удалять, и изменения в котором будут приводить к тому, что все будет пересобираться.
Но у нас уже есть конкурентный словарь индексов, почему бы не использовать его? Мы это сделали. С unordered_map от string простые фильтрующие логики, которые берут информацию из контекста, проверяют, например, наличие экзамена и решают, пропускать данные водителя или нет, работали за единицы микросекунд — одну, две, иногда три. Забегая вперед: когда мы переделали это на решение с конкурентным словарем индексов, они же стали работать менее чем за одну микросекунду. То есть ускорение было буквально в разы. Бо́льшая часть их работы состояла в том, что они считали хэш по ключу, искали нужную нам ячейку, проверяли, совпадает ли там строка, получали данные и решали коллизии. Когда мы эту работу у них забрали, они стали легковесными.
Здесь опять надо начать с класса, который нам позволит эффективно преобразовывать строку в индекс. Простая обертка.
class IndexStorage {
public:
size_t GetIndex(const std::string& name) { return map_.GetOrCreateIdx(name); }
std::string GetName(size_t idx) const { return map_.GetKey(idx); }
size_t GetSize() const { return map_.GetKeysSize(); }
static IndexStorage& GetInstance() {
static IndexStorage instance;
return instance;
}
private:
IndexStorage() = default;
// can not use engine::SharedMutex for static; read only using
using Map = ConcurrentIdxDict<256, 1, std::shared_mutex>;
Map map_;
};
И сам контекст, который предоставляет тривиальные функции для получения данных и для записи в них. Сам вектор с std: any. Но здесь есть неудобство: нам нужно помнить индекс, знать тип данных, которые мы достаем. Типов много, они разные, могут меняться. Это все надо синхронизировать.
class Context {
public:
template
const T* TryGetData(size_t idx) const;
template
const T& GetData(size_t idx) const;
template
T GetData(size_t idx, T def) const;
template
void SetData(size_t idx, T value);
static size_t GetDataIndex(const std::string& name);
private:
const std::any* TryGetRawData(size_t idx) const;
void SetRawData(size_t idx, std::any&& value);
std::vector data_;
};
Вот немного кода. Наверное, на нем не стоит останавливаться, он достаточно тривиален. Мы пробуем получить данные из вектора, сохранить с проверками.
const std::any* Context::TryGetRawData(size_t idx) const {
if (data_.size() <= idx) return nullptr;
const auto& value = data_[idx];
if (!value.has_value()) return nullptr;
return &value;
}
void Context::SetRawData(size_t idx, std::any&& value) {
if (data_.size() <= idx) data_.resize(idx + 1);
data_[idx] = std::move(value);
}
size_t Context::GetDataIndex(const std::string& name) {
return IndexStorage::GetInstance().GetIndex(name);
}
Чтобы упростить работу, мы сделали отдельный класс, который хранит контекст, позволяет работать с данными в контексте. Он параметризуется типом хранимых данных, хранит индекс, по которому эти данные находятся, предоставляет простой интерфейс получения данных нужного нам типа из контекста. Здесь тип уже зашит в API и не требует вспоминать о нем и вручную преобразовывать.
template
class ContextData {
public:
static auto Create(const std::string& name) {
return ContextData(Context::GetDataIndex(name));
}
void Set(Context& context, T value) const {
context.SetData(idx_, std::move(value));
}
auto& Get(const Context& context) const {
return context.GetData(idx_);
}
protected:
ContextData(size_t idx) : idx_(idx) {}
const size_t idx_;
};
Применение становится тривиальным. Мы делаем статическое константное поле, инициируем его, и у нас есть два готовых метода для получения и сохранения данных. Такие примитивы позволяют нам быстро и эффективно искать водителей, чтобы предоставлять вам сервис Такси.
class FetcherProfile {
public:
static void Set(Context& context, models::Profile value) {
data_.Set(context, std::move(value));
}
static const models::Profile& Get(const Context& context) {
return data_.Get(context);
}
private:
static const ContextData data_;
};
const ContextData FetcherProfile::data_ =
ContextData::Create("FetcherProfile/data");
На этом мой доклад окончен. Я рассказал вам краткую историю технологий в Такси, о том, как они развивались, какие проблемы мы встречали. Поделился «велосипедами», которые позволяют нам решать их быстро и эффективно. Спасибо.
