Зачем рассказывать про контейнеризацию в 2023 году

Техножрец DevOps бережно описывает документацию по проекту
Опытные специалисты с характерным оттенком глаз могут справедливо возмутиться, что это всё уже давным-давно разжёвано и вообще RTFM. И будут отчасти правы. Тем не менее приходят новые специалисты, которые не застали бесплатную рассылку дисков с Ubuntu и вдумчивую компиляцию ОС с нуля.
Каждая новая технология поначалу держится на энтузиастах, которые её полностью понимают. Например, первые пользователи радио знали почти всё про радиосвязь, могли на коленке собрать детекторный приёмник и ловить радио «Маяк» на металлическую вешалку и моток проводов. Первые пользователи GNU/Linux знали всё про ядро и ключевые принципы работы. По крайней мере, вариант «поправил и скомпилировал драйвера для модема, чтобы настроить сеть» был не самым редким. Текущие пользователи обычно не сталкивались с основами, так как начали щупать технологию уже после снижения порога входа.
Те же процессы идут не только в среде потребителей технологий, но и среди инженеров. С одной стороны, узкая специализация совершенно нормальна, с другой — мы рискуем получить аналог культа Галактического Духа на Анакреоне из цикла романов «Основание» Азимова. Техножрецы выполняют сложные ритуалы, ядерные реакторы пайплайны работают. Ровно до тех пор, пока всё не сломается к чертям на низком уровне, а чинить будет некому.
Так происходит и с контейнеризацией. Я всё чаще встречаю на собеседованиях devops-инженеров, которые знают, как пользоваться Docker и Podman, пишут Dockerfile, но теряются, когда спрашиваешь про namespaces, и начинают плавать при вопросе: «А зачем, чем RPM хуже?» Все собирают контейнеры, и я собираю. Таков Путь. Не всегда, кстати, оптимальный.
Меня зовут Кушневский Иван, я работаю главным техническим руководителем разработки в Газпромбанке. Сегодня попробую раскрыть эту тему немного под другим углом. Поэтому пройдёмся по базису с другого ракурса:
- Базис, на котором строится современная контейнеризация.
- Отличия от виртуализации.
- Linux namespaces и что общего у firefox с docker.
- Nsenter — давайте закинем приложение внутрь исполняемого контейнера на низком уровне.
- Unshare и изоляция без docker.
Наливайте себе чашку кофе и поехали.
Уровни абстракции
Уровень железа
Базис, на котором строится вся современная инфраструктура, — это железо. Как часто говорят, нет никаких облаков, есть интерфейс к такому же железу в чужом дата-центре. При этом оборудование может быть совершенно любым — китайское оборудование со своими особенностями, брендовые серверы от HP или даже самосборный кластер из Raspberry Pi с кастомными контроллерами. Научить программы взаимодействовать с этим зоопарком напрямую в теории возможно, но в 99% случаев совершенно нецелесообразно. Большинство разработчиков хотят написать код один раз и запускать его где угодно с минимальными изменениями, чтобы не задумываться, что там под капотом — SSD, HDD, лента стримера или вообще восстановленный just for fun floppy-disk. Также в идеале не хочется задумываться о доступах к файлам, областям оперативной памяти и прочих нюансах.
Системные вызовы — уровень ядра
Для этого вводится уровень абстракции, который работает посредником между hardware и software, — ядро ОС. Оно обеспечивает необходимые API-вызовы, которые позволяют взаимодействовать с теми или иными ресурсами. Их называют системными вызовами. Чаще всего они относительно низкоуровневые, надёжные и довольно примитивные. Например, «считай 10 байт, открой файл, считай 10 байт».
В целом можно упороться и писать приложения, которые используют почти исключительно системные вызовы. Представим, что нам нужно написать оконное приложение на голом ядре. Мы можем напрямую отправить в буфер видеокарты отрисованное окно приложения и вывести его на экран, отреагировать на нажатия клавиш. Потом через системные вызовы перехватывать координаты мыши и вычислять, в какой точке экрана произошёл клик, чтобы правильно отработать событие «пользователь нажал на кнопку button_1». Сурово, иногда необходимо, но обычно всё-таки не для графических приложений. Переиспользование готового кода в этом случае минимально, а нагрузка на разработчиков и требования к их квалификации очень высоки. Можно и в машинных кодах напрямую в процессор тогда тыкать, что уж там.
Уровень библиотек
Более типовой вариант состоит в использовании готовых библиотек, которые заворачивают системные вызовы в более удобные для работы абстракции и берут на себя все низкоуровневые проблемы шевеления мышью, доступа к сетевым ресурсам и звуковым устройствам, как тот же Pshsh-pshh-audio PulseAudio.
Уровень пользовательского пространства
Следующий уровень — это user-space. Сама программа ничего не знает про наше оборудование, про ОС и прочее. Обычно это просто набор высокоуровневых инструкций, которые полагаются на зависимости в виде библиотек из предыдущего слоя.
Операционная система создаёт для нашей программы отдельный изолированный процесс, который позволяет приложению не задумываться о доступных ресурсах и прочих деталях. Она работает сама по себе, искренне полагая, что исполняется в гордом одиночестве и все ресурсы принадлежат ей. На самом деле ОС в это время выдаёт этому процессу нужный объём оперативной памяти, гарантируя, что никто посторонний туда ничего внезапно не запишет, следит за выделением процессорного времени, «ставя на паузу» какое-то приложение, пока на этом ядре выполняются расчёты для чего-то другого. Всё это происходит в соответствии с квотами и приоритетами. Удобно.
Как вообще может программа, которая ничего не знает про ОС, работать со всеми этими фреймворками и обвязкой? Делается это с помощью динамически подключаемых библиотек. По сути, это набор некоторых типовых инструкций, который вынесен в отдельную абстракцию, чтобы было проще.
Давайте залезем в консоль и посмотрим, как это работает.
$ file /usr/bin/ls
/usr/bin/ls: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=897f49cafa98c11d63e619e7e40352f855249c13, for GNU/Linux 3.2.0, stripped
$ ldd /usr/bin/ls
linux-vdso.so.1 (0x00007ffd9bfee000)
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1 (0x00007f029db9d000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f029d800000)
libpcre2-8.so.0 => /lib/x86_64-linux-gnu/libpcre2-8.so.0 (0x00007f029db06000)
/lib64/ld-linux-x86-64.so.2 (0x00007f029dc0c000)
Для начала мы натравили команду file на бинарник ls и убедились в том, что он динамически слинкован с библиотеками. Без них работать не будет, так как полагается на их наличие в ОС. Далее с помощью ldd мы определили, какие именно библиотеки используются приложением при работе.
При этом, что важно, подключаются не просто какие попало библиотеки, а вполне конкретные их версии. Дело в том, что в каких-то минорных релизах могут править баги, что-то оптимизировать и фиксить уязвимости. Но при крупных изменениях могут добавляться новые фичи, а старые ломаться. Да, традиционно для популярных библиотек стараются максимально долго поддерживать все старые API-вызовы, но и их приходится убирать, если это мешает внедрению новых архитектурных решений. Обычно о таком предупреждают заранее, долгими и упорными сообщениями о том, что вот конкретно этот вызов deprecated и скоро всё сломается — перепишите. Как обычно, часто никто ничего не делает до последнего момента, если бизнес не хочет за это платить прямо сейчас.
Никто не любит поддержку

Разработчики очень трепетно относятся к своему творчеству. Цените их
Поддерживать ПО тяжело. Для начала — оно уже написано и работает. Бизнес крайне не любит расставаться с деньгами, чтобы решать проблемы, которые ещё не наступили. Кроме этого, есть сложности во взаимодействии между разработчиком и конечным пользователем, который будет запускать приложение.
Например, сидит разработчик на древней Ubuntu и всё никак не обновится. Или в стародавние времена втащил куда-то в основание приложения библиотеку, которая была похоронена ещё под несколькими слоями кода и абстракций. И вот он берёт артефакт своего приложения или исходный код и отдаёт девопсу. Инженер выкатывает это приложение в среду, и всё благополучно падает. Ругается, что ног не чувствует, рук не чувствует, вон ту библиотеку не завезли, а вот эта непонятной версии, вызовы не те.
Девопс возвращается к разработчику и говорит, что ни черта не работает, нужно понять, как запустить. Но может получить ответ в духе «ничего не знаю, у меня такая же нога, и она не болит; всё работает, я проверял».
И вот тут возникает дилемма — как лучше воспроизвести окружение, которое необходимо приложению для полноценной работы? Допустим, я сейчас накидаю ворох из библиотек и как-то запущу это в тестовой среде. А как заказчику бинарник передавать? Писать огромную инструкцию о том, как настроить среду с нужными библиотеками, тащить всё огромным архивом и инсталлировать набором скриптов или найти более простое решение?
Поддерживаем дистрибутивы
Вот на этом моменте есть разные варианты решений. Если есть много ресурсов для разработки, пишется что-то монументальное и низкоуровневое, то можно поддерживать несколько наиболее популярных дистрибутивов ОС с их наборами библиотек. То есть разработчики должны учитывать наборы библиотек, которые поставляются с определёнными версиями ОС, и тщательно тестировать в различных средах. Воткнуть новые модные фичи при заявленной поддержке CentOS 6, естественно, не получится. Плюс, кроме сопровождения этого зоопарка, добавится головной боли с закрытием уязвимостей и бэкпортированием новых фич с учётом старых версий библиотек на более ранних дистрибутивах. Ну и скорее всего, придётся тесно взаимодействовать с мейнтейнерами дистрибутивов, чтобы всё устанавливалось и собиралось, как задумано.
Дорого. Сложно. Очень удобно и прозрачно для конечного пользователя, которому будет достаточно выполнить yum install super_application. Одни и те же библиотеки используются множеством приложений и потребляют меньше памяти.
Контейнеризируем или виртуализируем
Чаще всего ресурсов на поддержку множества дистрибутивов нет. Можно ограничиться небольшим их количеством, но проблемы начнутся, когда дистрибутив станет oldstable, а небольшой команде придётся обновлять все зависимости при переходе на новую версию ОС.
В этом случае традиционным уже решением станет упаковка всего в docker image и передача заказчику. На чём именно он его запустит, уже не так важно. Благодаря слою абстракции наш образ будет содержать всё необходимое в переносимом виде. Если девопсы хорошие, то образ получится минималистичным и будет содержать только самое необходимое.
Тут внезапно выясняется, что приложению требуется работать с аппаратными токенами, контроллерами жёстких дисков и кассовыми аппаратами. Нам нужны полноценные драйверы, а засунуть своё ядро в контейнер не получится. Да и не даст нам ОС этого сделать. В этом случае поможет только полная виртуализация, где гипервизор host-OS позволит нам запустить любое ядро с драйверами, которые нам нужны. Часто это более оптимальное решение, но сейчас мы рассмотрим ситуацию, когда нам не нужен оверхед в виде множества запущенных ядер полноценных ОС для запуска небольших приложений.
В случае контейнера системные вызовы мы отправляем в ядро, на котором запущены все контейнеры, а уже библиотеки перетаскиваем вместе с бинарником внутри docker image. По сути, это позволяет нам говорить процессу: «Ты за библиотеками не туда ходи, а вот сюда. Они в контейнере лежат». При этом процесс ничего не знает о файловой системе и компьютере в целом. Всё, что он знает, он получает от ядра. Когда мы говорим: «Дай нам список файлов в директории», мы отправляем запрос в ядро. Ядро в ответ на этот системный вызов отвечает нам списком файлов директории. Мы отправляем запрос в ядро: «Сообщи, пожалуйста, список сетевых интерфейсов». Ядро отвечает списком сетевых интерфейсов. «Ядро, открой, пожалуйста, нам tcp соединение». Ядро нам возвращает указатель на это соединение. То есть процесс в принципе без ядра беспомощен, хоть и притащил с собой все нужные для приложения библиотеки.
Namespace
Ядро Linux нативно поддерживает так называемые namespace. Этот механизм не требует установки каких-то дополнительных пакетов, он поставляется сразу на уровне ядра. Он позволяет нам отвечать на системные вызовы каждого приложения по-разному.
По мере развития этого механизма добавлялись новые возможности по виртуализации тех или иных функций.
С появлением этой технологии появилась возможность, например, отдавать разные наборы доступных сетей при запросе к ядру из приложений, которые выполняются в разных namespace. В таблице выше представлены все доступные на текущий момент пространства имён. Из них относительно недавно добавился time namespace, который позволяет разным процессам видеть разное системное время или часовой пояс.
С появлением этой технологии появилась возможность, например, отдавать разные наборы доступных сетей при запросе к ядру из приложений, которые выполняются в разных namespace. В таблице выше представлены все доступные на текущий момент пространства имён. Из них относительно недавно добавился time namespace, который позволяет разным процессам видеть разное системное время или часовой пояс.
Проверить присвоенные пространства можно так:
ls -l /proc/$$/ns
итого 0
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 net -> 'net:[4026531840]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 time -> 'time:[4026531834]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 user -> 'user:[4026531837]'
lrwxrwxrwx 1 ivan ivan 0 мая 11 17:08 uts -> 'uts:[4026531838]'
Давайте посмотрим на некоторые из них немного поближе.
Network namespace позволяет нам изолировать ресурсы, связанные с сетью. При этом процессы из разных пространств видят свои собственные сетевые устройства, таблицы маршрутизации, правила firewall и так далее. Если приложение выполняется в процессе с отдельным net namespace, то мы можем гарантировать полную сетевую изоляцию от всей остальной системы и взаимодействие только через специально выделенные для этого интерфейсы.
Mount namespace — это та область файловой системы, которая предоставляется приложению как корневая. То есть мы создаём какую-то структуру в контейнере и говорим процессу: «Вот эта директория — это/. Пользуйся». Проверить можно так:
$ cat /proc/$$/mounts
*******************
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
udev /dev devtmpfs rw,nosuid,relatime,size=16331004k,nr_inodes=4082751,mode=755,inode64 0 0
*******************
Также есть namespace, который представляет новые PID, создаёт namespace PIDов, пользователей. User namespace позволяет иметь свою собственную копию пользовательских и групповых идентификаторов, IPC позволяет нам организовать межпроцессное взаимодействие, а UTS — это собственный hostname.
Где это используется?
Итак, наше ядро умеет обеспечивать нативную изоляцию процессов друг от друга при необходимости. Да, именно этот механизм лежит в основе docker-контейнеризации, но это далеко не исчерпывающий список технологий, которые используют namespaces.
Воспользуемся командой lsns и посмотрим, кто и как у нас использует этот метод изоляции:
$ lsns
NS TYPE NPROCS PID USER COMMAND
4026532829 user 1 3064 ivan /usr/lib/firefox/firefox -contentproc -parentBuildID 20230227191043 -prefsLen 75473 -prefMapSize 266990 -appDir /usr/lib/firefox/browser {56177664-74fd
4026532830 ipc 1 3064 ivan /usr/lib/firefox/firefox -contentproc -parentBuildID 20230227191043 -prefsLen 75473 -prefMapSize 266990 -appDir /usr/lib/firefox/browser {56177664-74fd
4026532832 ipc 1 3166 ivan /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 75614 -prefMapSize 266990 -jsInitLen 246560 -parentBuildID 20230227191043 -app
4026532833 net 1 3166 ivan /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 75614 -prefMapSize 266990 -jsInitLen 246560 -parentBuildID 20230227191043 -app
4026533061 mnt 7 14015 ivan /snap/spotify/64/usr/share/spotify/spotify
Совершенно внезапно без всяких docker-контейнеров наш firefox использует пространства имён для более качественной изоляции от основной ОС и повышения безопасности. А ещё snap, распространённый в ubuntu-based дистрибутивах, предоставляет собственные изолированные интерфейсы своим приложениям.
Если запустить то же самое от имени root, станет видно и системные компоненты, которые используют namespace для задач изоляции:
# lsns
NS TYPE NPROCS PID USER COMMAND
4026531834 time 486 1 root /sbin/init splash
4026531835 cgroup 485 1 root /sbin/init splash
4026531836 pid 474 1 root /sbin/init splash
4026531837 user 430 1 root /sbin/init splash
4026531838 uts 482 1 root /sbin/init splash
4026531839 ipc 442 1 root /sbin/init splash
4026531840 net 429 1 root /sbin/init splash
4026531841 mnt 450 1 root /sbin/init splash
4026532491 mnt 1 667 root /lib/systemd/systemd-udevd
4026532492 uts 1 667 root /lib/systemd/systemd-udevd
4026532689 mnt 1 1161 systemd-resolve /lib/systemd/systemd-resolved
4026532693 net 1 1199 root /usr/libexec/accounts-daemon
4026532748 mnt 1 1199 root /usr/libexec/accounts-daemon
4026532749 mnt 3 1210 root /usr/sbin/NetworkManager --no-daemon
4026532771 mnt 6 1307 root /bin/sh /snap/cups/872/scripts/run-cups-browsedСмотрим на Docker
Попробуем сделать то же самое, но уже с запущенным привычным docker.
docker run -it ubuntu:22.04 /bin/bash
root@9133f3149aaf:/# lsns
NS TYPE NPROCS PID USER COMMAND
4026531834 time 2 1 root /bin/bash
4026531837 user 2 1 root /bin/bash
4026534955 mnt 2 1 root /bin/bash
4026534956 uts 2 1 root /bin/bash
4026534957 ipc 2 1 root /bin/bash
4026534958 pid 2 1 root /bin/bash
4026534959 net 2 1 root /bin/bash
4026535358 cgroup 2 1 root /bin/bash
И изнутри контейнера, и снаружи мы видим, что системные вызовы полностью изолированы в отдельном namespace. Все приложения внутри контейнера не заметят разницы между запуском в среде контейнера и на хост-системе за счёт этого механизма.
Давайте проверим hostname:
root@9133f3149aaf:/# hostname
9133f3149aaf
Несмотря на то что мы обратились с системным вызовом к общему ядру, bash-сессия внутри контейнера получила ответ, отличный от мастер-системы от uts namespace. Аналогично уникальные ответы мы получим при запросах доступных сетевых интерфейсов или текущего времени от time namespace:
# date
Чт 8 мая 2023 18:22:45 MSK
root@9133f3149aaf:/# date
Thu May 8 15:22:35 UTC 2023nsenter и unshare
Есть прекрасная утилита nsenter, которая позволяет нам запускать процессы в произвольных namespace, просто зная их PID. Давайте попробуем ещё раз.
Запустим в одной консоли интерактивную сессию с docker, а в другой попробуем подкинуть приложение в то же пространство напрямую, не используя стандартной обёртки.
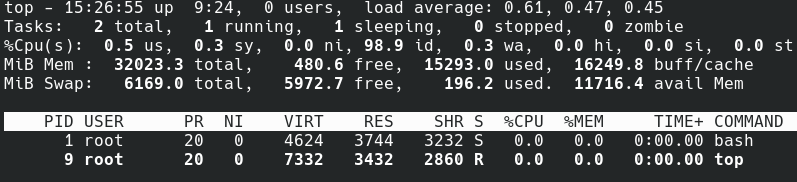
Пустой контейнер, где выполняются только два процесса
Находим pid нашего контейнера:
# lsns | grep /bin/bash
NS TYPE NPROCS PID USER COMMAND
4026535356 mnt 2 50199 root /bin/bash
4026535357 uts 2 50199 root /bin/bash
4026535358 ipc 2 50199 root /bin/bash
4026535411 pid 2 50199 root /bin/bash
4026535412 net 2 50199 root /bin/bash
4026535467 cgroup 2 50199 root /bin/bash
Теперь давайте запустим sleep внутри нашего контейнера на одну минуту:
nsenter -t 50199 -m -u -i -n -p sleep 1m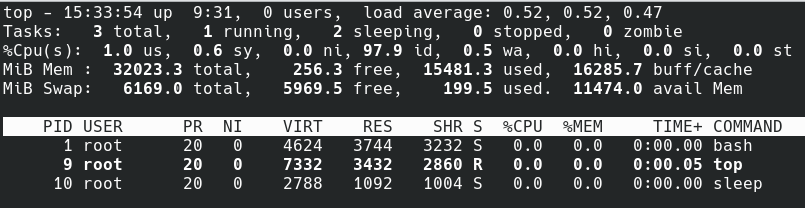
Внутри нашего контейнера мы видим команду sleep, которая была запущена в этом изолированном namespace. Причём без классических docker-инструментов.
А можно ли запустить какой-нибудь процесс без докера, но при этом чтобы этот процесс оказался в отдельных namespace? Да, можно, конечно. Для этого есть прекрасная утилита unshare. Она как раз позволяет запускать приложения в изолированных namespace, чтобы не влиять на основную систему:
root@ivan-desktop:/# hostname
ivan-desktop
root@ivan-desktop:/# unshare -u bash
root@ivan-desktop:/# hostname test-desktop
root@ivan-desktop:/# hostname
test-desktop
root@ivan-desktop:/# exit
exit
root@ivan-desktop:/# hostname
ivan-desktop
В примере выше мы создали новую bash-сессию, но в изолированном namespace, успешно поменяли hostname, а после выхода из сессии увидели, что эти изменения были применены только в рамках изолированного пространства имён.
Краткие выводы
Основной тренд сейчас заключается в максимальной модульности. Этот подход позволяет нам дёшево собрать любой велосипед со своим набором библиотек и гарантировать его запуск почти где угодно. Это позволяет резко снизить time-to-market, обеспечить переносимость, отказоустойчивость, лёгкость балансировки и прочие приятные вещи, которые даёт переход от парадигмы Pets (уникальные, вручную настроенные сервисы и серверы) к парадигме Cattle (одинаковые номерные сущности, которые поднимаются сотнями и так же без жалости убиваются).
При этом не нужно забывать, что docker — это всего лишь крайне удобная обёртка поверх стандартных механизмов ядра. И они используются не только в связке с docker, но и со многими другими технологиями.
