Зачем коту хвост: realtime статистика в условиях средней видимости
Меня зовут Игорь, полтора года назад я начал работать в проекте Рейтинг Mail.ru, и спустя год мне разрешили заняться риалтайм-статистикой в рамках этого проекта. Сегодня я немного более подробно расскажу о том, как у нас устроена статистика. Если вы вдруг не в курсе, cчетчик Рейтинг Mail.ru установлен на примерно 20% всех сайтов рунета. Мы обрабатываем и показываем статистику по динамике посещений, статистику по пользователям (демография: пол, возраст), и много-много других отчетов, включая время загрузки страницы. Риалтайм статистика — это более динамичная статистика, которая показывает количество пользователей прямо сейчас на сайте, какие страницы сайта популярны прямо сейчас, с приблизительно 1-секундной задержкой.Дашборд, сводящий все риалтайм-отчеты вместе, выглядит вот так:
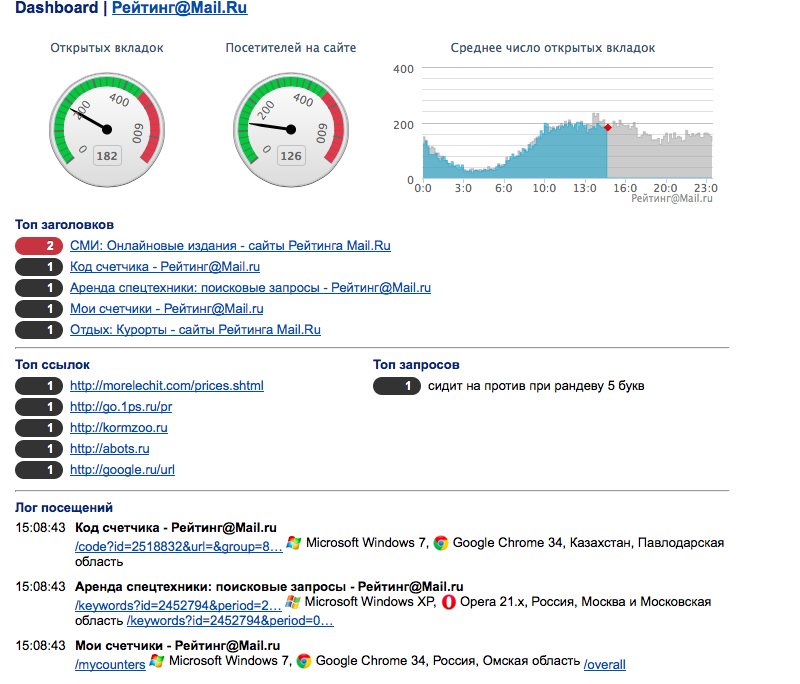 Он показывает:
Он показывает:
количество посетителей на сайте; сколько вкладок браузера открыто; топ страниц; топ ссылок, с которых осуществляются переходы; топ запросов, с которых приходят с поисковиков; и, конечно же, лог посещений. Разумеется, отдельные отчеты также доступны. Не хочу заниматься тавтологией, более подробно можно прочитать про каждый отчет в нашем корпоративном блоге.Недавно я закончил работать над этим проектом, и хочу поделиться некоторыми паттернами, которые я нашел интересными.
Мне кажется, самый важный паттерн который я использовал — это паттерн обратный к «Not Invented Here». Десять лет назад я учился в Бауманском (КФ), и в качестве одной из курсовых я сделал небольшое приложение с пятью формами которое считало частоты слов (ну и, разумеется, я пытался его продавать как shareware). Оно все еще доступно на archive.org. Я был апологетом антипаттерна «Not Inveted Here» и не верил в использование чужих библиотек. Программка была написана на «C с классами» и имела свою ОО библиотеку обертывающую Win32 API.
Десять тысяч строк кода, четыре месяца работы и пшик на выходе. Богатством функциональности ненамного сложнее CD Ejector’а. Религиозно-фанатичное «Not invented here» ведет к огромному времени разработки и неподдерживаемому коду.
Сейчас я занимаюсь тем, что утаскиваю в свою копилку тщательно проработанные библиотеки с элегантным API, написанные профессионалами. Это, например, BOOST, Intel Threading Building Blocks, Google Protobuf. Я не совсем уверен, как называется антипод антипаттерна «Not Inveted Here», но лично я склоняюсь к «No man is an island». В текущем проекте на порядок больше функциональности, чем в моей вариации на тему «CD Ejector’а». Вся эта функциональность влезает в две тысячи строк кода, и была разработана за те же самые 4 месяца. Из компонентов я использую следующее:
C++11 — удобно и быстро и половина BOOST’а уже там. Google TMalloc — сделаем все немножко быстрее. Google Protobuf — сериализация/десериализация даром, и пусть никто не уйдёт обиженным. Intel® TBB — во всём демоне риалтайм статистике используется один mutex, все остальное сделано с помощью TBB: concurrent_hash_table, concurrent_bounded_queue. BOOST — для всего что не покрывается С++11, MongoDB — для хранения состояния и месседжинга. Capped collections+tailable cursors работают просто замечательно в этой роли, хотя я бы предпочел TibcoRV’s certified messaging, но это совершенно точно overkill. Макросы для работы с BSON очень удобны. Не расписываю архитектуру полностью — это большое удовольствие разрабатывать ее, и я не хочу спойлить удовольствие для тех из нас, кто будет решать похожую задачу. Но я хочу поделиться некоторыми техническими решениями, которые я нашел полезными. Если где-то что-то добавилось, где-то что-то должно убавиться. Все пользователи и сессии должны где-то храниться (и хранятся они по счетчикам). Через некоторое время сессия истекает, и запись должна быть удалена.Одно из прямолинейных решений — это итерация и удаление истекших записей. Есть более элегантное решение, когда запись добавляется или обновляется, в concurrent_bounded_queue добавляется запись о необходимости удаления. И в отдельном потоке используется блокирующий pop, который возвращает запись, если есть что читать. Так как таймаут константный, каждая следующая запись будет актуальна позже, чем та, которую вернули. И, если время удаления еще не настало, достаточно сделать sleep () до момента, когда она будет актуальной. После чего достаточно сравнить время истечения и последнее время обновления записи, и если она действительно истекла (не обновлялась со времени добавления текущей записи об удалении) — удалить её. Дешево и сердито.
Некоторые библиотеки логирования плохо работают с асинхронностью и пишут в несколько потоков в один файл. Ну, и не надо забывать о том, что логфайл для ротации логов должен переоткрываться по SIGHUP. Я разрешил себе потратить полчаса для того, чтобы сделать логирование более элегантным.Логирование в коде выглядит так: LOG («All msgs:» << sum);
Вот так это сообщение выглядит в логе:2014–05–15 18:57:17 INFO void QueueCounter: run (): All msgs: 38288
Реализуется он с помощью макроса который помещает std: string в привычный tbb: concurrent_bounded_queue откуда в один поток сообщения читаются и пишутся логфайл.
Если подумать, concurrent_bounded_queue — это не что иное, как очередь сообщений. И логично иметь брокер сообщений, который знает обо всех message queues. Он бы так и назывался MessageBroker’ом. Но тогда я бы не смог добавить в него другие сервисы необходимые многим компонентам (например, логгинг и конфигурации) и назвать его Context.Поэтому единственный параметр конструктора, который принимают LiveObject — это ссылка на объект класса Context. LiveObject — это просто объект класса, в котором есть метод run; этот метод выполняется в отдельном треде. Обычно один такой объект отвечает за один поток исполнения.
«Лог посещений» (аналог tail) пишется в concurrent_hash_table. Он пишется по 1-секундным бакетам. Ключом выступает id счетчика. Небольшая проблема: tbb: concurrent_hash_table нельзя обходить, если в нем используются не-POD структуры.Решение довольно просто — использовать атомарный указатель на эту таблицу и подменять его раз в секунду. Проблема в следующем: после сериализации (которая происходит довольно быстро, 0.5–50 мс) старая структура данных удаляется. И если поток, который «обогащает» записи в tail (геолокация по ip, мапирование OS, браузеров), запишет в удаленную структуру данных, будет бобо. Также известное как SEGFAULT.
Время обработки записи считается в микросекундах. На несильно загруженном сервере ожидать магических подвисаний потоков a la Java «stop the world» не стоит. И если добавить sleep перед сериализацией проблема решится. Альтернативой может быть один из классических примитивов синхронизации, но это не элегантно и не нужно.
Для подсчета топов (топ ключевых слов, топ страниц и так далее) используется несколько модифицированный lossy counting.Оригинальный lossy counting работает следующим образом: есть поток элементов. Его разбивают на бакеты (в некоторых описаниях бакет называется окном). Если в таблице с элементами уже есть элемент, его счетчик увеличивается на 1. Если элемента нет, и в таблице есть место, элемент добавляется и его счетчик выставляется в 1. В конце бакета изо всех счетчиков вычитается единица. Элементы со счетчиками, достигшими нуля, удаляются. В модифицированном элементе для каждого элемента ведется подсчет количества сессий. Когда количество сессий на элементе опускается до нуля, он удаляется. Когда наступает «конец окна», из счетчиков (которые имеет тип float) вычитается не единица, а (1 — (количество удаленных элементов по нулю сессий) / размер окна).
Топы становятся более динамичными, особенно для сайтов с низкой посещаемостью.
Зачем хоту хвост, я не знаю, но догадываюсь. Что же до риалтайм-статистики, то с ней все проще — она оказалась достаточно популярной. И мы решили сделать из одного из самых популярных отчетов информер, который можно установить на сайте. Для посещаемых сайтов выглядит он очень интересно, отображая самые популярные страницы на сайте и количество людей которые на них смотрят прямо сейчас.Регистрируйтесь и радуйтесь жизни. Обратите внимание, что на сайтах с малым количеством посещений статистика не столь интересна.
