Xeon Phi: Почему сопроцессоры используют для создания торговых приложений

В нашем блоге на Хабре мы много пишем о разработке торговых роботов и построении инфраструктуры для онлайн-трейдинга. В прошлых материалах мы рассмотрели тему использования FPGA и GPU, а сегодня, речь пойдет о создании торговых приложений с помощью сопроцессоров Xeon Phi.
Современные фондовые биржи транслируют информацию о ситуации на рынке с помощью специальных обработчиков потоков (feed handlers), которые содержат информацию о котировках акций и приказах на покупку и продажу. С ростом числа заявок и количества торгуемых финансовых инструментов, производительность торговых систем также должна драматическим образом увеличиваться — иначе неизбежны задержки в торговле, что часто неприемлемо.
Кроме того многие биржи транслируют данные в различных форматах, включая мультикаст-трансляцию и point-to-point передачу по TCP/IP. Сложность работы с проприетарными финансовыми протоколами приводит к тому, что в некоторых случаях финансовые компании и частные HFT-трейдеры предпочитают не разрабатывать собственные программные обработчики потоков финансовых данных, а использовать коммерческие «железные» решения для повышения производительности своих приложений.
Существует два подхода к построению торговых приложений. Первый можно описать, как «общий» — в этом случае решение состоит из программного приложения, работающего на каких-то широко используемых процессорах вроде Intel Xeon и стандартных ОС вроде Linux. Второй подход подразумевает создание «кастомизированного» решения, использующего FPGA или ASIC, которые позволяют осуществлять обработку финансовых данных на значительно более высоких скоростях. Второй путь также характеризуется увеличивающимися издержками на разработку и поддержку решения.
Важным аспектом любого высокопроизводительного решения для работы на финансовом рынке является также и величина задержки, вносимой обрабатывающим софтом. В мире HFT даже микросекундные задержки могут сделать торговлю убыточной. Задержка обработчиков зависит от количества ядер, которые можно для них выделить — обычно их число не особенно велико, потому что аппаратные ресурсы нужны и самому софту, выполняющему торговые операции. Решить задачу снижения вносимой задержки помогает использование сопроцессоров Xeon Phi, которые позволяют осуществлять обработку данных на скоростях, сравнимых со скоростью их получения.
Архитектура обработки пакетов
Сопроцессоры Intex Xeon Phi позволяют создавать приложения с крайне высоким уровнем параллелизма. Вычислительная платформа состоит из следующих компонентов:
- Большое количество ядер последовательного кэша и потоков для обработки множества независимых потоков данных для оптимальной работы системы.
- Поддержка SIMD с помощью 512-битных векторов, вместо использования более «узких» MMX, SSE или AVX2.
- Поддержка высокопроизводительных инструкций для выполнения операций вычисления квадратного корня, экспоненты и обратных величин.
- Большой объём доступной полосы пропускания для памяти.
- Высокопроизводительные инструменты коммуникации — к приеру, PCI-шина между хостом и подключенными сопроцессорами.
В итоге один или больше потоков на хост-машине получают пакеты — это могут быть рыночные данные — через сокетное соединение из внешнего источника с помощью стандартного сетевого инструмента (NIC). Хост формирует из пакетов очередь FIFO для дальнейшей обработки. Связанный поток на стороне сопроцессора, работающий на ядре, обрабатывает каждый пакет, полученный через FIFO и пропускает каждый пакет через алгоритм обработки потоков. Результат его работы затем снова копируется в FIFO для дальнейшей обработки.
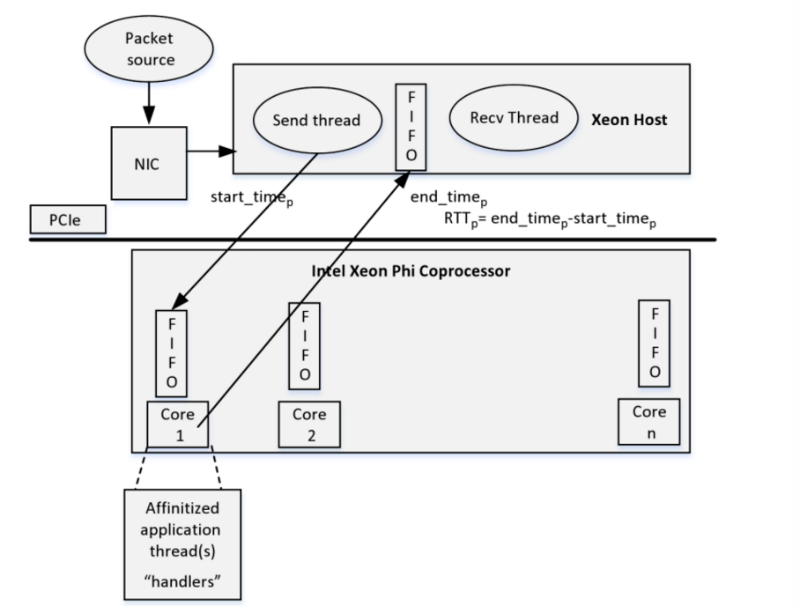
Архитектура приложения для обработки пакетов, использующего сопроцессоры
Эффективная «межузловая» связь между двумя соседними процессами обеспечивается с помощью симметричного коммуникационного интерфейса SCIF (Symmetric Communication Interface). В итоге приложения передают данные с помощью SCIF API, который работает аналогично Berkeley Sockets API. Драйверы и библиотеки SCIF симметрично располагаются на обеих сторонах PCI-шины — процесс установки соединения похож на sockets API, где одна сторона слушает и принимает входящие соединения, а вторая подключается к удаленному процессу.
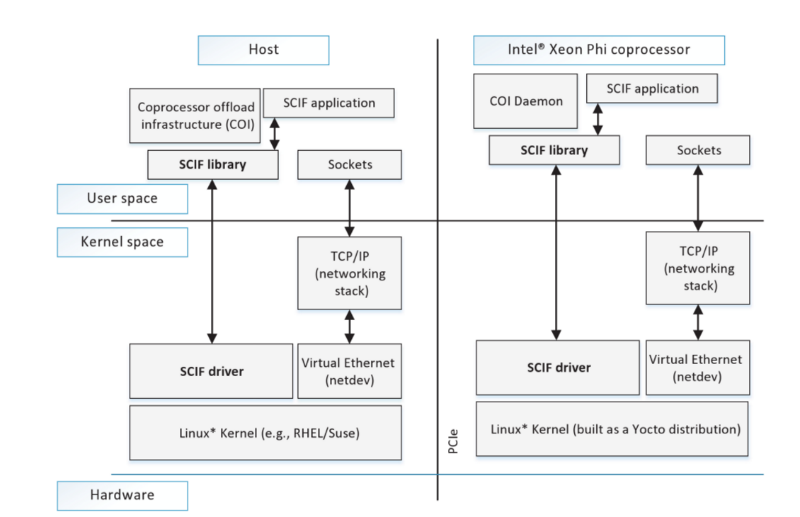
Стек Intel Many-Core Platform Software (MPSS), включающий SCIF-драйвер и библиотеку для работу в режиме пользователя
Более подробная информация о работе с памятью и оптимизации торговых приложений с помощью Xeon Phi представлена в книге High Performance Parallelism Pearls Volume Two: Multicore and Many-core.
Далее мы рассмотрим тестовую реализацию приложения на Xeon Phi.
Расчет процентных свопов LIBOR по методу Монте-Карло
Компания-разработчик решений для высокочастотной торговли Xcelerit в своем блоге опубликовала описание реализации приложения для обработки процентных свопов LIBOR по методу Монте-Карло. Мы воспользуемся основными моментами этого материала.
Для определения стоимости портфолио LIBOR-свопционов используется симуляция Монте-Карло. С ее помощью симулируются тысячи возможных будущих вариантов развития показателей интереса LIBOR — для этого применяется нормально-распределенные случайные числа. Для вычисления ставок и доходности LIBOR используется механизм, описанный профессором Майком Жилем (Mike Giles).
Чувствительность портфолио вычисляется с помощью алгоритмической дифференциации (Adjoint Algorithmic Differentiation, AD). Итоговые значения свопционов в портфолио и греки — греческими буквами обозначают чувствительность премии опциона к изменению различных величин.
В реализации используется SDK от Xcelerit. Для получения нормально распределенных случайных образцов необходим генератор случайных чисел, затем модуль вычисления ставок LIBOR, определения портфолио и греков. Затем идет финальное выисление портфолио и значений греков.

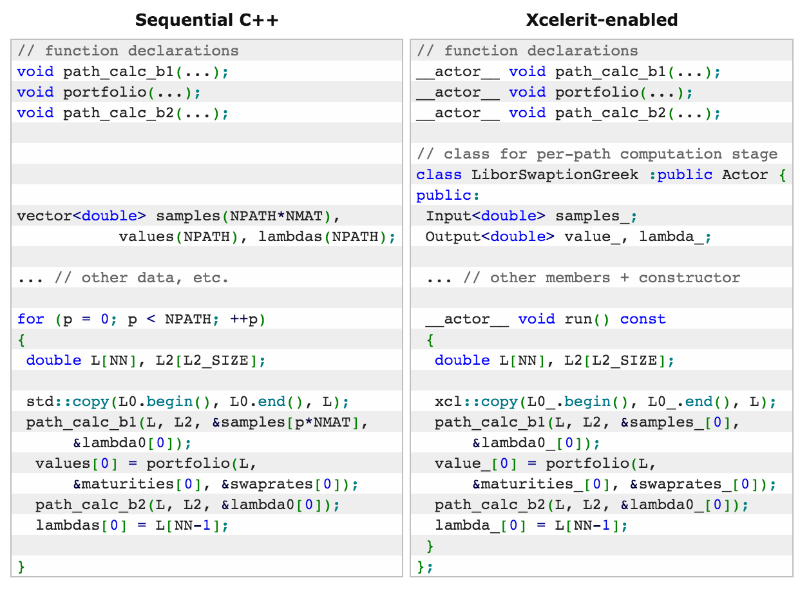
В таблице ниже приведено сравнение двух возможных реализаций подобного приложения — одна с помощью последовательного C++, а вторая — при использовании SDK для работы с Xeon Phi.
Приложение использует нативный режим Xeon Phi, не задействуя основной процессор. Тестовая среда имела следующую конфигурацию:
- CPU: Haswell Xeon E5–2697 v31 (14 ядер, 2x HT) и Xeon Phi 7120P1 (61 ядро, 4x HT)
- HT: включенный Hyper-threading
- OS: RedHat Enterprise Linux 6 (64bit)
- RAM: 64GB
- Средства разработки: Xcelerit SDK 3.0.0b / ICC 15.0
В ходе эксперимента сравнивалось время вычислений тестового приложения на двух процессорах и последовательная реализация на одном ядре Haswell CPU. Под временем вычислений подразумевается выполнение всех стадий описанного выше алгоритма.

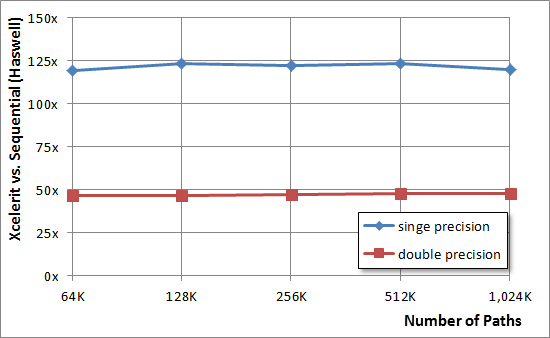
На графике ниже приведено сравнение скорости работу реализации, запущенной на Haswell для чисел с двойной и одинарной точностью:
При использовании Xeon Phi результаты следующие:

Если в предыдущем случае удалось добиться ускорения обработки 50x и 125x для одинарной и двойной точности, то с помощью сопроцессоров эти величины были увеличены до 75x и 150x соответственно.
Другие материалы о железе и онлайн-трейдинге:
