Who is stealing virtual CPU time?

Hi! In this article, I want to explain, in layman«s terms, how steal appears in VMs and tell you about some of the less-than-obvious artifacts that we found during research on the topic that I was involved in as CTO of the Mail.ru Cloud Solutions platform. The platform runs KVM.
CPU steal time is the time during which a VM doesn«t receive the necessary resources to operate. This time can only be calculated in a guest OS in virtualization environments. It is extremely unclear where the allocated resources are lost, just like in real life situations. However, we decided to figure it out, and we even performed a series of tests to do so. That is not to say that we know everything about steal, but there are some fascinating things that we would like to share with you.
1. What is steal?
Steal is a metric that indicates a lack of CPU time for VM processes. As described in the KVM kernel patch, steal is the time that a hypervisor spends running other processes in a host OS, while VM process is in a run queue. In other words, steal is calculated as the difference between the moment when a process is ready to run and the moment when CPU time is allocated to the process.
The VM kernel gets the steal metric from the hypervisor. The hypervisor doesn«t specify which processes it is running. It just says: «I«m busy, and can«t allocate any time to you.» In a KVM, steal calculation is supported in patches. There are two main points regarding this:
- A VM learns about steal from the hypervisor. This means that in terms of losses, steal is an indirect measurement that can be distorted in several ways.
- The hypervisor doesn«t share with the VM information regarding what it is occupied with. The most crucial point is that it doesn«t allocate time to it. The VM itself, therefore, cannot detect distortions in the steal metric, which could be estimated by the nature of the competing processes.
2. What affects steal?
2.1. Calculating steal
Essentially, steal is calculated in more or less the same way as CPU utilization time. There isn«t a great deal of information regarding how utilization is calculated. That«s probably because most professionals think it«s obvious. However, there are some pitfalls. The process is described in an article by Brendann Gregg. He discusses a whole host of nuances regarding how to calculate utilization and scenarios in which the calculation will be wrong:
- CPU overheating and throttling.
- Turning Turbo Boost on/off, resulting in a change in CPU clock rate.
- The time slice change that occurs when CPU power-saving technologies, e.g. SpeedStep, are used.
- Problems related to calculating averages: measuring utilization for one minute at 80% power could hide a short-term 100% boost.
- A spinlock that results in a scenario whereby the processor is utilized, but the user process doesn«t progress. As a result, the calculated CPU utilization will be 100%, but the process will not actually consume CPU time.
I haven«t come across any articles describing such calculations of steal (if you know of any, please share them in the comments section). As you can see from the source code, the calculation mechanism is the same as for utilization. The only difference is that another counter is added specifically for the KVM process (VM process), which calculates how long the KVM process has been waiting for CPU time. The counter takes data on the CPU from its specification and checks if all its ticks are being utilized by the VM process. If all the ticks are being used, then the CPU was only busy with the VM process. Otherwise, we know that the CPU was doing something else and steal appears.
The process by which steal is calculated is subject to the same issues as the regular calculation of utilization. These issues are not that common, but they can appear rather confusing.
2.2. Types of KVM virtualization
In general, there are three types of virtualization, and they are all supported by a KVM. The mechanism by which steal occurs may depend on the type of virtualization.
Translation. In this case, the VM OS will work with physical hypervisor devices in the following way:
- The guest OS sends a command to its guest device.
- The guest device driver accepts the command, creates a BIOS device request, and sends the command to the hypervisor.
- The hypervisor process translates the command into a physical device command, making it more secure, among other things.
- The physical device driver accepts the modified command and forwards it to the physical device itself.
- The execution results of the command return following the same path.
The advantage of translation is that it allows us to emulate any device and requires no special preparation of the OS kernel. But this comes at the expense of performance.
Hardware virtualization. In this case, a device receives commands from the OS on the hardware level. This is the fastest and overall best method. Unfortunately, not all physical devices, hypervisors, and guest OSs support it. For now, the main devices that support hardware virtualization are CPUs.
Paravirtualization. The most common option for device virtualization on a KVM and the most widespread type of virtualization for guest OSs. Its main feature is that it works with some hypervisor subsystems (e.g. network or drive stack) and allocates memory pages using a hypervisor API without translating low-level commands. The disadvantage of this virtualization method is the need to modify the guest OS«s kernel to allow for interaction with the hypervisor using the same API. The most common solution to this issue is to install special drivers into the guest OS. In a KVM this API is called a virtio API.
When paravirtualization is used, the path to the physical device is much shorter than in cases when translation is used, because commands are sent directly from the VM to the hypervisor process in the host. This accelerates the execution of all instructions within the VM. In a KVM, a virtio API is responsible for this. It only works for some devices like network and drive adapters. This is why virtio drivers are installed to VMs.
The flip side of such acceleration is that not all processes executed in a VM stay within the VM. This result in a number of effects, which might cause steal. If you would like to learn more, start with An API for virtual I/O: virtio.
2.3. Fair scheduling
A VM on a hypervisor is, in fact, a regular process, which is subject to scheduling laws (resource distribution between processes) in a Linux kernel. Let«s take a closer look at this.
Linux uses so-called CFS, Completely Fair Scheduler, which became the default with kernel 2.6.23. To get a handle on this algorithm, read Linux Kernel Architecture or the source code. The essence of CFS lies in the distribution of CPU time between processes, depending on their run time. The more CPU time a process requires, the less CPU time it gets. This guarantees the «fair» execution of all processes and helps to avoid one process taking up all of the processors, all of the time and allows other processes to run too.
Sometimes this paradigm results in interesting artifacts. Long-standing Linux users will no doubt remember how a regular text editor on the desktop would freeze when running resource-intensive applications like a compiler. This happened because resource-light tasks, such as desktop applications, were competing with tasks that used many resources, like a compiler. CFS considers this to be unfair, and so it stops the text editor from time to time and lets the CPU process the compiler tasks. This was fixed using the sched_autogroup mechanism; there are, however, many other peculiarities of CPU time distribution. This article is not really about how bad CFS is. It is rather an attempt to draw attention to the fact that «fair» distribution of CPU time is not the most trivial task.
Another important aspect of a scheduler is preemption. This is necessary to rid the CPU of any over-indulged processes and allow others to work too. This is called context switching. The entire task context is retained: stack status, registers, and so on, after which the process is left to wait and is replaced by another process. This is an expensive operation for an OS. It«s rarely used, but it«s actually not bad at all. Frequent context switching might be an indicator of an OS issue but it usually occurs continuously and is not a sign of any issue in particular.
This long discourse was necessary to explain one fact: in a fair Linux scheduler, the more CPU resources the process consumes, the faster it will be stopped to allow other processes to work. Whether this is right or not is a complex question, and the solution is different depending on the load. Until recently, Windows scheduler prioritized desktop applications, which resulted in slower background processes. In Sun Solaris there were five different scheduler classes. When virtualization was introduced, they added another one, Fair share scheduler, because the others were not running properly with Solaris Zones virtualization. To dig deeper into this, I recommend starting with Solaris Internals: Solaris 10 and OpenSolaris Kernel Architecture or Understanding the Linux Kernel.
2.4. How can we monitor steal?
Just like any other CPU metric, it«s easy to monitor steal inside a VM. You can use any CPU metric measurement tool. The main thing is that the VM must be on Linux. For some reason, Windows doesn«t provide such information to the user. :(
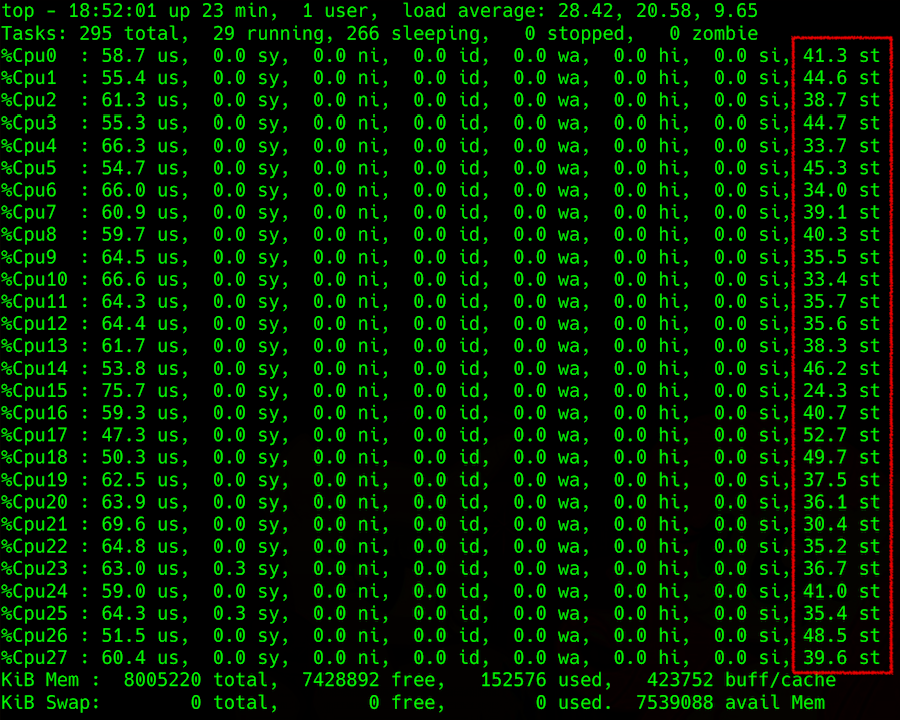
top output: specification of CPU load with steal in the right column
Things become complicated when trying to get this information from a hypervisor. You can try to forecast steal on a host machine, using Load Average (LA), for example. This is the average value of the number of processes in the run queue. The calculation method for this parameter is not a simple one, but in general, if an LA that has been standardized according to the number of CPU threads is greater than 1, it means that the Linux server is overloaded.
So, what are all these processes waiting for? Obviously, the CPU. This answer is not quite accurate, however, because sometimes the CPU is free and the LA is way too high. Remember that NFS falls and LA rises at the same time. A similar situation might occur with the drive and other input/output devices. In fact, the processes might be waiting for the end of a lock: physical (related to input/output devices) or logical (a mutex object, for example). The same is true for hardware-level locks (for example, disk response) or logic-level locks (so-called «locking primitives», which include a number of entities, mutex adaptive and spin, semaphores, condition variables, rw locks, ipc locks…).
Another feature of LA is that it is calculated as an average value within the OS. For example, if 100 processes compete for one file, the LA is 50. This large number might make it seem like this is bad for the OS. However, for poorly written code this can be normal. Only that specific code would be bad, and the rest of OS might be fine.
Because of this averaging (for less than a minute), determining anything using an LA is not the best idea, as it can yield extremely ambiguous results in some instances. If you try to find out more about this, you«ll find that Wikipedia and other available resources only describe the simplest of cases, and the process is not described in detail. If you are interested in this, again, visit Brendann Gregg and follow the links.
3. Special effects
Now let«s get to the main cases of steal that we encountered. Allow me to explain how they result from the above and how they correlate with hypervisor metrics.
Overutilization. The simplest and most common case: the hypervisor is being overutilized. Indeed, with a lot of VMs running and consuming a lot of CPU resources, competition is high, and utilization according to the LA is greater than 1 (standardized according to CPU threads). Everything lags within all VMs. Steal sent from the hypervisor grows as well. You have to redistribute the load or turn something off. On the whole, this is all logical and straightforward.
Paravirtualization vs single instances. There«s only one VM on a hypervisor. The VM consumes a small part of it, but provides high input/output load, for example, for a drive. Unexpectedly, a small steal of less than 10% appears (as some of the tests we conducted show).
This is a curious case. Here, steal appears because of locks on the level of the paravirtualized devices. Inside the VM, a breakpoint is created. This is processed by the driver and goes to the hypervisor. Due to the breakpoint processing on the hypervisor, the VM sees this as a sent request. It is ready to run and waits for the CPU, but receives no CPU time. The VM thinks that the time has been stolen.
This happens when the buffer is sent. It goes to the hypervisor«s kernel space and we wait for it. From the point of view of the VM, it should return immediately. Therefore, according to our steal calculation algorithm, this time is considered stolen. It is likely that other mechanisms may be involved in this (e.g. the processing of other sys calls), but they should not differ to any significant degree.
Scheduler vs highly loaded VMs. When one VM suffers from steal more than the others, this is connected directly with the scheduler. The greater the load that a process puts on a CPU, the faster a scheduler will throw it out, so as to allow other processes to work. If the VM is consuming little, it will experience almost no steal. Its process has just been sitting and waiting, and it needs to be given more time. If the VM puts a maximum load on all cores, the process is thrown away more often and the VM is afforded less time.
It«s even worse when processes within the VM try to get more CPU, because they can«t process the data. Then the OS on the hypervisor will provide less CPU time because of the fair optimization. This process snowballs, and steal surges sky-high, while other VMs may not even notice it. The more cores there are, the worse is it for the unfortunate VM. In short, highly loaded VMs with many cores suffer the most.
Low LA but steal is present. If the LA is about 0.7 (meaning that the hypervisor seems underloaded), but there«s steal in some VMs:
- The aforementioned paravirtualization example applies. The VM might be receiving metrics that indicate steal, while the hypervisor has no issues. According to the results of our tests, such steal does not tend to exceed 10% and doesn«t have a significant impact on application performance within the VM.
- The LA parameter has been calculated incorrectly. More precisely, it has been calculated correctly at a specific moment, but when averaging, it is lower than it should be for one minute. For example, if one VM (one-third of the hypervisor) consumes all CPUs for 30 seconds, then the LA for a minute will be 0.15. Four such VMs, working at the same time, will result in a value of 0.6. Based on the LA, you wouldn«t be able to deduce that for 30 seconds for each of them, the steal was almost 25%.
- Again, this happened because of the scheduler, which decided that someone was «eating» too much and made them wait. Meanwhile, it will switch context, process breakpoints, and attend to other important system matters. As a result, some VMs experience no issues, and others suffer from significant performance losses.
4. Other distortions
There are a million possible reasons for distortion of fair CPU time allocation on a VM. For example, hyperthreading and NUMA add complexity to the calculations. They complicate the choice of the core used to run a process because a scheduler uses coefficients; that is to say weights, which complicate the calculations even more than this when switching contexts.
There are distortions that arise from technologies like Turbo Boost or its opposite, power saving mode, which might artificially increase or decrease CPU core speed and even time slice. Turning Turbo Boost on decreases the productivity of one CPU thread due to a performance increase in another one. At that moment, information regarding the current CPU clock speed is not sent to the VM, which thinks that someone is stealing its time (e.g. it requested 2 GHz and got half as much).
In fact, there can be many reasons for distortion. You may find something else entirely in any given system. I recommend starting with the books linked above and obtaining statistics from the hypervisor using tools such as perf, sysdig, systemtap, and dozens of others.
5. Conclusions
- Some steal may appear due to paravirtualization and this can be considered normal. Online sources say that this value can be 5–10%. It depends on the application within a VM, and the load the VM puts on its physical devices. It is important to pay attention to how applications feel inside a VM.
- The correlation between the load on the hypervisor and steal within a VM is not always certain. Both steal calculations can be wrong in some cases and with different loads.
- Scheduler does not favor processes that request a lot of resources. It tries to give less to those that ask for more. Big instances are mean.
- A little steal can be normal without paravirtualization as well (taking into consideration the load within the VM, the particularities of neighbors» loads, the distribution of the load between threads, and other factors).
- If you would like to calculate steal in a particular system, research the various possibilities, gather metrics, analyze them thoroughly, and think about how to distribute the load fairly. Regardless, there can be deviations, which must be verified using tests or view these in a kernel debugger.
