Выстраиваем эффективное взаимодействие инженерной и продуктовой команд

@innubis
Реальность такова, что любой успешный продукт должен понимать, уметь предсказывать и чутко реагировать на новые потребности своей аудитории. И даже больше — задавать новые тренды. Это неизбежно накладывает обязательства на инженерную команду, которая участвует в развитии продукта: инженерам приходится постоянно погружаться в продуктовый процесс, проводить всяческие эксперименты и при этом сохранять эффективность на высоком уровне.
Мы в Badoo относительно небольшими силами (в моей команде 30 человек) ежемесячно деплоим порядка сотни новых востребованных фич, при этом не теряя в качестве кода, планирования и поддержки. Каким образом нам удаётся оставаться «на коне» и как у нас построено взаимодействие инженерной команды с продуктовой, я расскажу в этой статье.
Уверен, что наш опыт будет интересен и другим компаниям. И надеюсь, что подход, который мы выработали путём проб и постоянных улучшений, кому-то реально поможет (а в идеале — сэкономит время и силы при выстраивании процессов и даст нужный результат).
Меня зовут Дмитрий Семенихин, я тимлид команды Features компании Badoo. Работаю здесь почти шесть лет, и за это время на моих глазах произошла стремительная эволюция (в контексте продуктовой разработки) как команды, так и процессов в ней.
Под процессами в данной статье я подразумеваю систему взаимодействия инженерной и продуктовой команд, набор неких правил и рекомендаций, призванных улучшить и упростить это самое взаимодействие. Но прежде чем начать что-то улучшать, нужно определится с задачами, которые мы хотим решить. Назовём их ключевыми ценностями. Мы для себя выработали следующие:
- Прозрачность. Все участники процесса должны понимать, чем занимаются они и смежные команды, знать, ради чего всё делается и как.
- Скорость. Мы не можем себе позволить тратить много времени на множество согласований, пустых обсуждений, на «полировку» незначительных мелочей. Путь от идеи до прототипа на продакшене должен быть минимальным настолько, насколько позволяет требуемое качество.
- Гибкость. Мы должны максимально быстро адаптироваться к изменениям на рынке, уметь быстро трансформироваться, оперативно реагировать на любые вызовы.
Схема работы 1 (стартап)
Я пришёл в команду в 2012 году на инновационное по тем временам мобильное направление. Нас было пять бекенд-разработчиков и один продуктовый менеджер (он же заказчик). Также было три клиентских команды (iOS, Android и Mobile Web), но я в основном буду рассказывать о работе именно команды бекенда.
Постановка задач и планирование происходили просто. Продуктовый менеджер собирал с бизнеса требования, формулировал их в простеньких ТЗ, приоритизировал и формировал список задач для нашей команды. Далее задачи раздавались разработчикам, которые налаживали коммуникацию с девелоперами других команд и доводили свои задачи до продакшена. Почему это работало на тот момент:
- Единый список приоритетов (бери верхнюю задачу из списка, как только освобождается ресурс). При этом нужно иметь в виду, что любой девелопер мог работать над любой задачей. (Прозрачность и Гибкость)
- Простота коммуникации. Продуктовому менеджеру и бизнесу видно, чем занимается инженерная команда, легко отслеживать прогресс по каждой задаче, ведь их не так много. Если что-то непонятно, то один телефонный звонок или сообщение в чате решает проблему. (Прозрачность и Скорость)
- Тимлид всему голова. Лиду легко держать в голове все проекты, которые ведёт его команда, легко договориться с другими лидами об очерёдности, сроках и т. п. (Прозрачность и Скорость)
- Понятный и удобный процесс. Легко настроить фильтры и дашборды в Jira. Список один, задач немного. (Прозрачность, Скорость, Гибкость)
И мы довольно долго жили с такой схемой. Ведь она максимально близка к стартап-style! Все знают всё, все участвуют во всём. Процесс был максимально простым и понятным. «Как молоды мы были…» :)
Но что-то пошло не так
Со временем наша серверная команда выросла, и мы естественным образом разделились на группы, состоящие из нескольких человек. Каждая группа отвечала за определённые направления (например, мессенджер, поиск, нотификации и т. д.), или, в терминах Jira, компоненты. Продуктовая команда тем временем тоже выросла, и заказчиков у нас стало больше. В этот момент мы осознали некоторые недостатки нашей схемы, но по инерции продолжали жить с ней, точечно решая проблемы. А они были…
Первая проблема: мы больше не могли гарантировать очерёдность извлечения задач из приоритизированного списка, так как распределение в списке никак не соотносилось с направлениями, на которые была поделена команда. Таким образом, какие-то группы могли быть очень загружены, а другие — недозагружены продуктовой работой. Из-за этого у продуктового менеджера возникало ощущение, что мы работаем хаотично либо не на полную мощность.
Вторая проблема: несогласованность действий и непрозрачность. Появился рассинхрон в работе разных команд, так как участников процесса стало много, договариваться стало сложнее. В итоге мы тратили много времени на встречи, синхронизацию работы команд и обсуждения (кто, что и когда должен начать делать).
В общем, страдали сразу все наши ключевые ценности.
Схема работы 2 (планирование всему голова)
Обозначенные проблемы мы решали комплексно.
Во-первых, мы разработали интерфейс, в котором каждый проект делился на этапы (например, «Протокол — биллинг — серверный API — Android — iOS»), а дальше легко было видеть прогресс и зависимости. Это была некая надстройка над Jira, которая позволяла видеть общую картину проекта в более удобном для нас формате, нежели предлагали встроенные инструменты Jira. Прозрачность улучшилась.
Во-вторых, серверная команда начала самостоятельно тщательно отслеживать планы клиентских команд и брать в разработку только те проекты, которые значились у них в ближайших планах. Для этого для каждой клиентской команды был назначен ответственный со стороны серверной команды, который раз в неделю уточнял планы «своей» клиентской команды и оповещал о них остальных. Как мы убедились на собственном опыте, разрабатывать серверную часть сильно заранее — очень рискованно: и приоритеты могут поменяться, и требования к фиче. Прозрачность и скорость улучшились.
В-третьих, зная о планах клиентских команд, мы могли более грамотно организовать свою работу, видя, например, что одни группы перегружены, а другие — нет. В этом случае мы либо просили продуктовых менеджеров поменять приоритеты, либо перераспределяли работу меджу собой. Например, одна группа разработки могла взять часть задач другой, перегруженной, группы, чтобы обеспечить правильную очерёдность в списке приоритетов. Гибкость стала гибче. :)
Схема работы 3 (вертикали)
Шло время, наша команда продолжала расти. И если наше деление по направлениям (компонентам) в инженерке позволяло нам довольно легко масштабироваться, то продуктовая команда уже не могла существовать как монолит, поэтому она тоже разделилась на направления (вертикали). Были, например, такие: Comms, Revenue, Core, Next gen applications. То есть продуктовая команда разделилась в соответствии с бизнес-целями компании, что логично. В итоге мы получили вместо одного списка приоритетов сразу четыре условно независимых. Внутри каждого продуктового направления формировался приоритезированный список задач и «спускался» к нам.
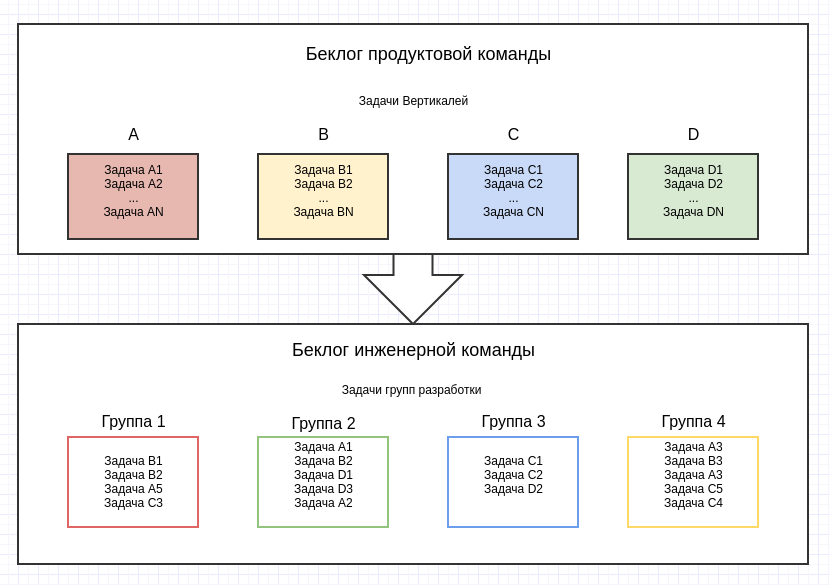
Рис. 1 Четыре независимых продуктовых вертикали (потока) формируют списки задач для всего инженерного отдела. Далее задачи попадают в соответствующие группы разработки в соответствии с их спецификой.
При этом для каждой вертикали у нас была утверждённая квота инженерных ресурсов. Условно говоря, вертикаль А получает в этом месяце 30% времени, B — 20%, C — 40%, D — 10%. Далее мы создали простейшую статистику, которая снимала срезы в Jira по продуктовым задачам в прогрессе, делила их по вертикалям и строила графики. Мы смотрели на эти графики и принимали решение, какой вертикали нам нужно уделить больше внимания.
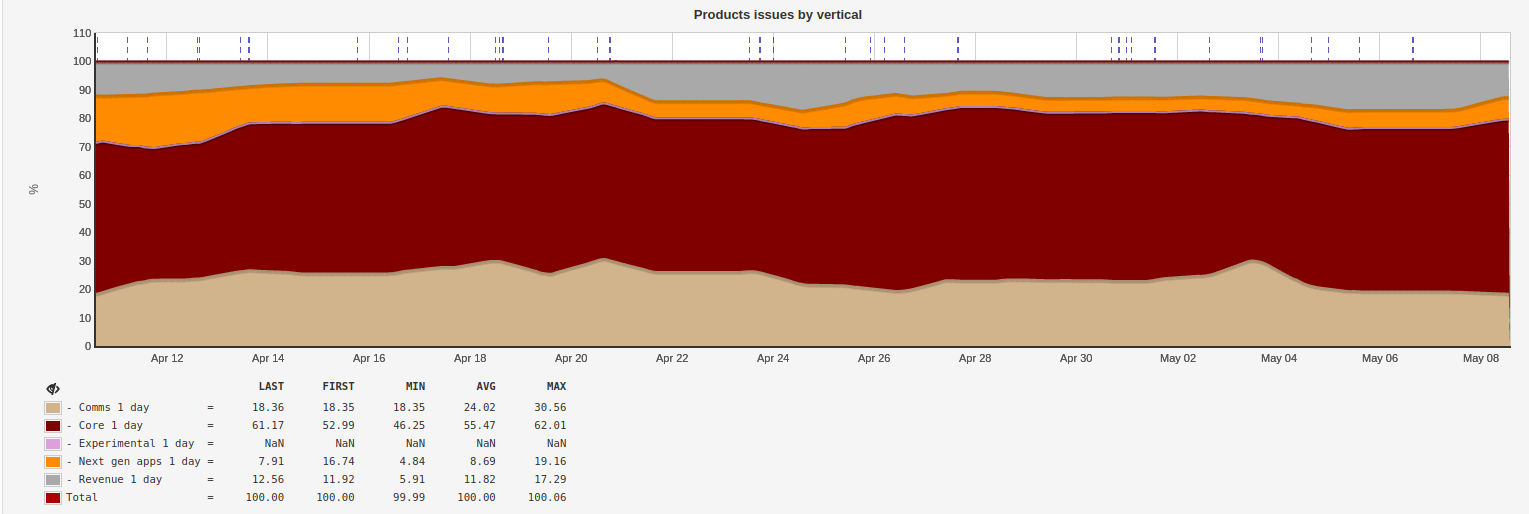
Рис. 2 Отслеживание реальных затрат ресурсов разработки на каждую из вертикалей для соблюдения правильных пропорций.
Схема вполне рабочая и в целом соответствовала всем нашим ценностям, если бы не тот факт, что мы почти всегда испытывали (и продолжаем испытывать) недостаток инженерных ресурсов (кстати, да, мы ищем таланты!). Это приводило к тому, что продуктовая команда не понимала, в какой момент тот или иной проект из определённой вертикали будет взят в разработку.
Учитывая выделенную квоту на вертикаль, а также наше внутреннее инженерное деление по компонентам, могло получится так, что задача, стоящая на третьем месте в вертикали, могла висеть там очень долго, а то и вообще не быть выполненной, так как ответственная за этот проект группа была перегружена.
Поясню. В данной схеме продуктовая команда воспринимала наш отдел как монолитный ресурс из более чем 30 человек, на который, например, одна из вертикалей «спускает» десять новых задач. Но на практике все эти десять задач могли попасть в одну группу разработки, поскольку все они принадлежали одному техническому направлению, за которое отвечает эта группа. Предположим, в этой группе всего пять человек. В этом случае очевидно, что команда не могла справиться с таким потоком задач в разумное время, но для продуктовой команды это было отнюдь не очевидно.
В создавшихся условиях стали происходить нехорошие вещи. Продуктовые менеджеры начали прессовать инженерных лидов по поводу своих «подвисших» проектов, хаотично сортировать свои списки, перемещая отдельные задачи на верхние строки списка и «задвигая» другие. Лиды находились в постоянном стрессе, пытаясь угодить всем и при этом пытаясь как-то оставлять ресурсы на саппорт и технические проекты. В итоге продуктовых проектов реализовывалось много, но удовлетворения это почему-то не приносило.
Дальше так жить было нельзя! Резюмируя, ещё раз обозначу проблемы, которые мы имели на тот момент:
- Сложность планирования. По большому количеству задач в пуле невозможно было сказать, когда они будут взяты в работу.
- Как следствие — непрозрачность процесса разработки. Другие команды просто не могли понять, когда можно будет начинать работу над своей частью проекта, поскольку было неясно, когда будет выполнена задача, от которой это зависит.
- Несколько нервозная обстановка в коллективе (и в инженерной команде, и в продуктовой). Все были недовольны всеми.
- Смещение фокуса на продуктовую разработку в ущерб поддержке и техническому долгу вследствие попыток удовлетворить запросы продуктовой команды.
И мы приняли меры.
Схема работы 4 (текущая)
Прежде всего мы решили улучшить прозрачность, открыв продуктовой команде наше внутреннее строение. Теперь они могут видеть, что за один функционал приложения отвечают пять человек, а за другой — всего три. Такая открытость процесса имеет приятный бонус: уважение к ресурсам коллег. Участники продуктовой команды видят, кто чем занят и как долго ещё будет занят, и учитывают это при планировании своих задач.
Далее мы ввели более чёткое недельное планирование, основанное на формировании раздельных беклогов для групп разработки. Продуктовая команда (все вертикали вместе) каждую неделю формирует и приоритизирует список задач в соответствии с их принадлежностью к опредёленной группе. Причём они договариваются между собой, какая из задач важнее, и инженерным лидам уже не надо искать баланс, чтобы угодить всем продуктовым вертикалям. Далее лид группы, учитывая возможности команды и сложность предложенных задач, берёт из топа своего списка столько задач, сколько его группа способна начать решать на этой неделе. После этого единый список взятых задач по всем группам показывается продуктовой команде, если необходимоо, в него вносятся коррективы (что-то добавляется, что-то заменяется). После этого план считается утверждённым.
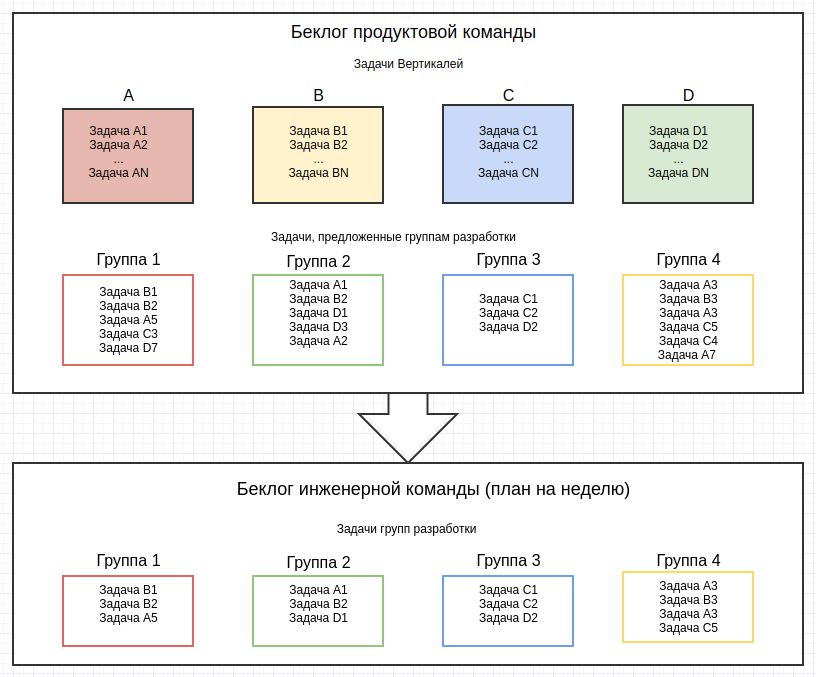
Рис. 3 Продуктовая команда самостоятельно формирует беклоги для каждой группы разработки. Инженерные лиды принимают в работу только те задачи, которые они в состоянии начать решать на неделе.
Нужно отметить, что в нашем случае план на неделю — это список задач, которые мы обязуемся начать решать на неделе. Срок завершения работы над задачей отображается в поле due date и выставляется в тот момент, когда разработчик приступает к работе над задачей (немного подробнее о due date я напишу ниже).
Что мы получили в итоге:
- Прозрачность. Все видят, какие задачи запланированы, могут оценить текущую ситуацию и сроки. Всё это представлено в удобном для всех виде.
- Гибкое и простое планирование. Период «неделя» был выбран неспроста. В наших условиях это оптимальный временной промежуток, который позволяет удерживать фокус на действительно важных вещах.
- Спокойная рабочая атмосфера. Есть утверждённый план, по нему и работаем. Не нужно ждать внезапных незапланированных задач (слукавил немного: их, конечно, нужно ждать, но не в таком количестве, как раньше).
- Свобода манёвра. Лиды, избавленные от прессинга, который был при использовании предыдущей схемы, могут планировать технические проекты, спокойно резервировать ресурсы для багфиксинга и технического долга.
Есть ли минусы? Безусловно. Например, теперь продуктовая команда должна делать несвойственные ей вещи: принимать участие в планировании ресурсов другой команды. Инженерка для неё отныне не просто «черный ящик», в который участники команды закидывают новые задачи и ждут их выполнения — теперь при формировании беклога задач нужно учитывать функциональное дробление инженерной команды, чтобы обеспечить равномерное распределение важных задач по группам. К счастью, встроенные инструменты Jira позволяют это делать относительно легко.
Также для продуктовой команды по-прежнему не всегда понятно, почему лид взял только три задачи на неделю из предложенных группе десяти. Сейчас мы просто устно объясняем, что лежит в основе такого решения, но хотелось бы упростить и визуализировать это. Например, можно предварительно оценивать размер всех новых задач. Это позволит более эффективно использовать ресурсы девелоперов. Вполне возможно, если бы продуктовый менеджер знал, что разработка некой задачи займёт так много времени, он бы её не предлагал, а сделал бы выбор в пользу нескольких более простых, но в сумме дающих больший эффект для бизнеса.
Несмотря на всё это, на мой взгляд, плюсов у этой схемы гораздо больше, чем минусов. Поэтому сейчас мы используем её, при этом не переставая анализировать проблемные места, чтобы в скором времени доработать наш механизм взаимодействия.
Важное дополнение
Чтобы не отвлекать от описания схем взаимодействия инженерной и продуктовой команд, я решил вынести в отдельную главу несколько моментов, о которых крайне важно упомянуть.
Due date
Мы выставляем due date для всех продуктовых задач и следим за соблюдением этого параметра. Разработчик, получив новую задачу, первым делом должен детально её проанализировать, оценить свою работу, работу смежных команд, риски и зависимости — и только после этого выставить дату, когда, по его мнению, тикет будет на продакшене. Да, это не ошибка. Не дату, когда он закончит писать код, и не дату, когда он отдаст задачу на QA, а именно дату появления задачи на продакшене.
Почему это важно и как мы к этому пришли, описал Илья Агеев в своей статье. В двух словах: у нас каждый разработчик — это немного менеджер проектов, который ведёт свою задачу от начала и до конца. И именно он отвечает за результат и сроки. В случае если due date не соблюдается, мы анализируем причины и пытаемся сделать так, чтобы это не повторилось в будущем, либо нащупываем узкие места в системе и фиксим их. Также разработчик кратко информирует всех заинтересованных о том, как продвигается проект, какие сложности возникают в процессе, чем и кем он заблокирован в специальном поле тикета Situation.
Проектные команды
Несмотря на планирование и наличие стандартного процесса разработки задач, основанного на функциональном разделении команд (каждый отдел отвечает за свою часть продукта), зачастую такой механизм недостаточно гибок и эффективен. Наиболее ярким примером являются экспериментальные задачи: когда требуется разработать некий функционал, вид и логика работы которого не до конца понятны; когда требуется быстро сделать изначальный прототип, а потом вносить множество правок, совершенствуя продукт (причём требуется одновременная работа сразу нескольких команд).
В таких случаях на период проекта мы создаём кроссфункциональную проектную команду, в которой есть ресурсы от всех необходимых подразделений. И она работает зачастую «в обход» стандартных процессов. Если требуется, для такой команды вводятся отдельные процессы планирования и разработки, а также схема взаимодействия с продуктовой командой.
Послесловие
Если у вас маленькая команда, в которой все умеют всё и все в курсе всего, никакие особые механизмы взаимодействия не требуются. Всё и так работает!
Но как только вы начинаете расти, появляется необходимость лучше координировать работу участников процесса, появляются накладные расходы на коммуникацию. В этот момент уже необходимо внедрять какие-то процессы вроде еженедельных митингов, стендапов, синков и т. п.
Когда же проект вырастает до того, что даже внутри одного отдела любой сотрудник не может заменить любого, нужны принципиальные изменения, процессы, которые будут учитывать вашу структуру и внутреннюю специфику.
Именно поэтому мы не взяли готовые методологии типа Scrum и Kanban, а используем некий промежуточный вариант со своими особенностями и надстройками. И мы по-прежнему продолжаем совершенствовать наши процессы и останавливаться не собираемся: как вы могли заметить, проблем всё ещё хватает.
А как вы решали и решаете обозначенные проблемы? Прошу делиться в комментариях.
Спасибо за внимание!
P.S. В эту субботу в московском офисе Badoo пройдёт Techleads Meetup. Свободных мест уже нет, но можно посмотреть трансляцию на нашем YouTube-канале. Присоединяйтесь, если вам интересна тема построения процессов в компании и управления в IT!
