Вышла библиотека PyWhat для автоматического парсинга трафика
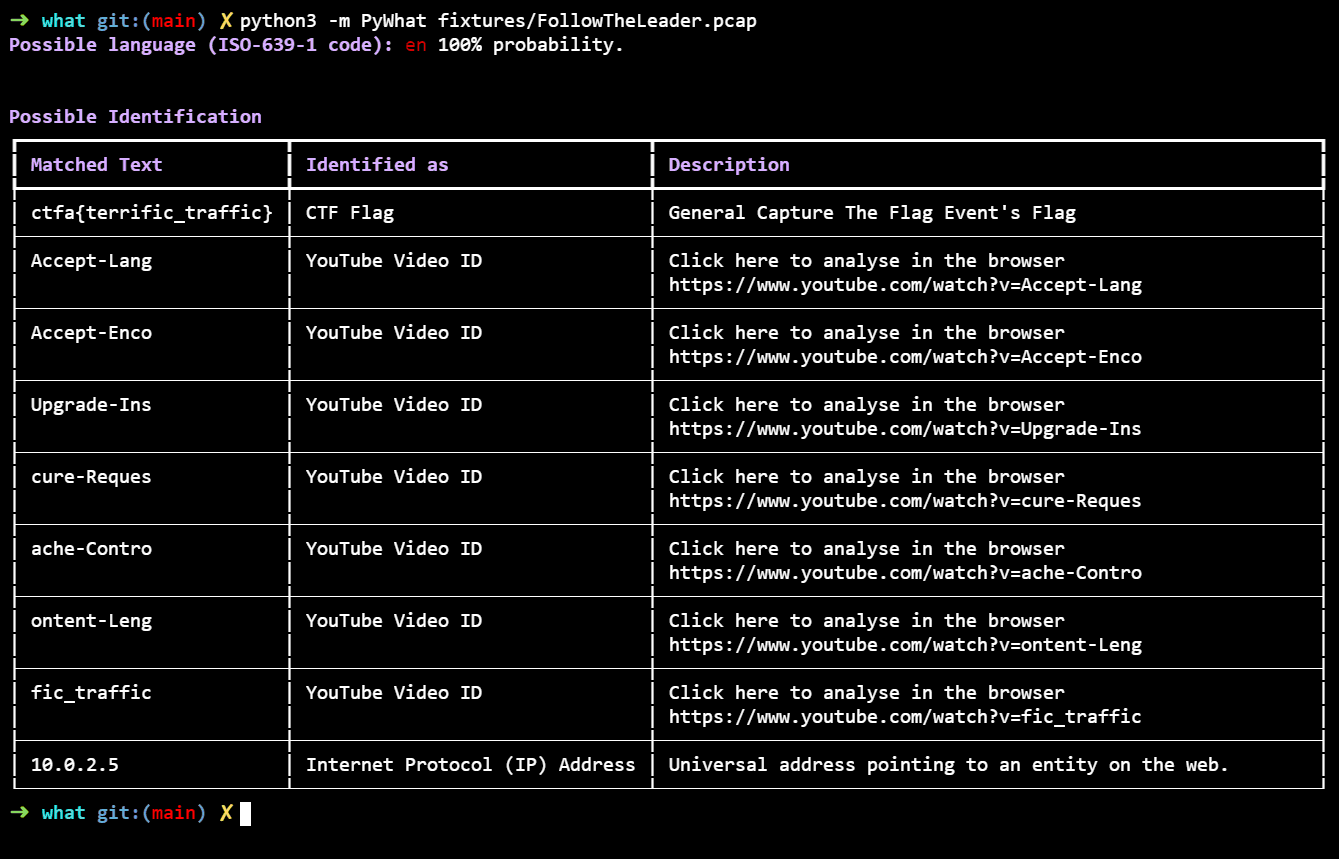
Разработана удобная библиотека PyWhat, которая помогает классифировать данные в неструктурированном массиве. Например, у вас несколько мегабайт трафика, записанного в стандартном формате .pcap. Что с ним делать? PyWhat спарсит все строки, выделит:
- кошельки криптовалют,
- номера социального страхования,
- кредитные карточки,
- заголовки видеороликов Youtube ID,
- любые хэши,
- другие известные типы данных.
Так в трафике гораздо проще ориентироваться. Увидев нужный пакет, затем в Wireshark можно выбрать остальные пакеты конкретно из этого потока в реальном времени.
В принципе, всё то же самое можно сделать фильтрами в Wireshark, если искать в трафике что-то конкретное, но эта библиотека автоматизирует процесс и экономит время.
Иди другой пример. Посреди кода или в каком-то файле встречается таинственная строка 5f4dcc3b5aa765d61d8327deb882cf99. Нет проблем. Запускаем PyWhat — и смотрим, что это такое, с помощью команды what "5f4dcc3b5aa765d61d8327deb882cf99".

Задача команды what — выяснить происхождение строки символов, фрагмента, текста внутри файла или какого-то hex-значения.
Автор библиотеки приводит такой пример. Вы столкнулись с новым вариантом вредоносного ПО под названием WantToCry. Вспоминаете, что оригинальный Wannacry удалось остановить, потому что никому не известный паренёк обнаружил в коде «выключатель» с триггером на появление сайта по указанному адресу. Парень зарегистрировал этот домен — и остановил распространение Wannacry во всём мире.
«Итак, запускаем what — находим все домены во вредоносной программе — и через API регистратора доменов все их регистрируем. Если Wannacry появится снова, вы сможете остановить его за считанные минуты», — пишет автор.
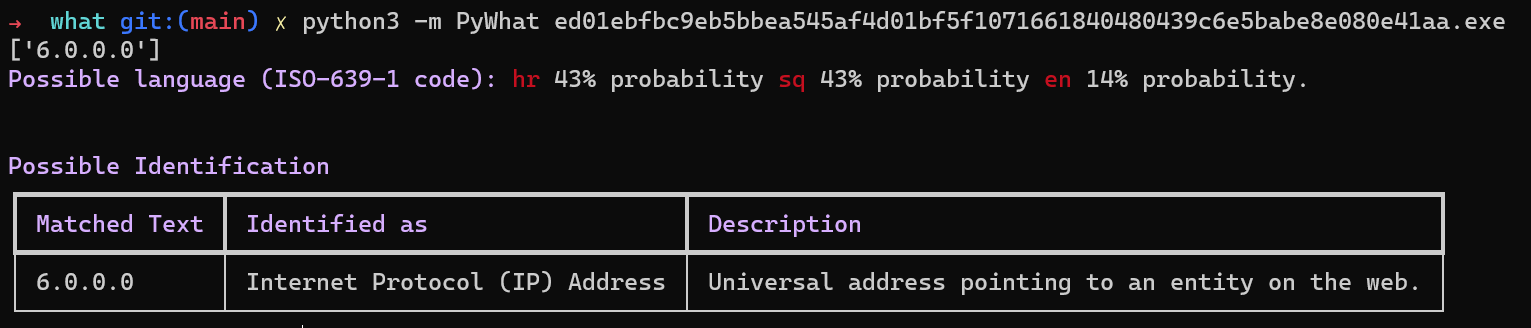
В общем, библиотека помогает найти структурированные данные в любом файле, поддерживает рекурсивный поиск файлов в директориях, работает с API.
PyWhat относится к классу «вероятностных библиотек» на Python (probabilistic library), созданных в процессе машинного обучения моделей. В каком-то смысле, такие модели после обучения распознают форматы строк примерно как системы машинного обучения распознают лица конкретных людей, сверяясь с базой паттернов.
Из других полезных вероятностных библиотек/пакетов на Python можно назвать следующие:
- probablepeople: парсер неструктурированных западных имён с разбиением их по полям (имя, фамилия и другие компоненты)
- usaddress: парсер американских адресов с разбиением из одной строки на шесть полей
- chardet: автоматическое определение кодировки символов
- Gen.jl: система вероятностного программирования общего назначения с программируемым выводом. Например, позволяет наводить порядок в таблицах с плохо структурированными данными
- DataProfiler: инструмент, похожий по функциональности на PyWhat. Принимает на входе файлы и данные любых форматов, а на выходе выдаёт структурированную информацию по следующим полям:
- UNKNOWN
- ADDRESS
- BAN (bank account number, 10–18 digits)
- CREDIT_CARD
- EMAIL_ADDRESS
- UUID
- HASH_OR_KEY (md5, sha1, sha256, random hash, etc.)
- IPV4
- IPV6
- MAC_ADDRESS
- PERSON
- PHONE_NUMBER
- SSN
- URL
- US_STATE
- DRIVERS_LICENSE
- DATE
- TIME
- DATETIME
- INTEGER
- FLOAT
- QUANTITY
- ORDINAL
Возможно переобучение модели DataProfiler на новые типы данных.

