Выкатываем сервис в production: 6 шагов к успешному релизу

Существует много руководств и инструкций по созданию базовых бекенд-приложений. Также в сети можно найти пошаговые tutorial по сборке приложения и развёртыванию на сервер, либо подробные инструкции для популярных CI/CD-инструментов. Описанных в них шагов достаточно для запуска pet-проектов, но для полноценных приложений, которые должны будут выдержать пиковые нагрузки от большого количества пользователей и при этом бесперебойно работать, нужна более детальная и качественная подготовка. Ниже я опишу шаги, которые обязательны для инженеров из моих команд при первом развёртывании веб-приложения в production и при дальнейшей выкатке крупных фич.
Шаг 0. Логирование и добавление метрик

Перед выкаткой приложения в прод очень важно корректно настроить уровни логирования технических сообщений и ошибок, их запись в хранилище логов, а также «обмазать» все важные показатели метриками. Для сбора и просмотра логов я рекомендую хорошо зарекомендовавший себя ELK-стек (Elasticsearch, Logstash, Kibana).

После корректной настройки все stdout-логи сервиса попадут в хранилище и будут доступны для просмотра в Kubana. Уровни логирования выставлять следующим образом:
info — для типовых сообщений.
warning — если заход в этот блок кода не планировался. Время от времени логи уровня warning нужно просматривать и анализировать.
error — для ошибок.
debug — этот уровень логирования лучше применять как можно реже, потому что debug-сообщения занимают очень много места и ухудшают поиск. Если же для устранения проблем или при запуске сервиса всё-таки нужен debug-уровень, то обязательно согласуйте дату, когда этот вид логов будет отключен.
В асинхронных приложениях в лог надо обязательно добавить request UUID, по которому можно будет легко отследить всю цепочку логов для конкретного вызова.
Если логи пишутся в понятном виде и по ним можно легко установить, в чём именно ошибка, значит работа проделана хорошо. Опытные разработчики знают, что лучше не экономить на логах уровня info, так как при их нехватке потребуется дописывать код, снова его развёртывать в прод и пытаться воспроизвести проблему, что займёт довольно много драгоценного времени.
Для логов уровня error рекомендую использовать дополнительный инструмент — Sentry. В нём удобно просматривать новые и самые массовые ошибки. Для ошибок вида Exception можно сохранять traceback, что сильно ускоряет их исправление. Также будет удобно настроить оповещения обо всех новых ошибках в Telegram-канал.
Для сбора метрик приложения хорошим выбором будет Prometheus с последующим выводом их в Grafana.
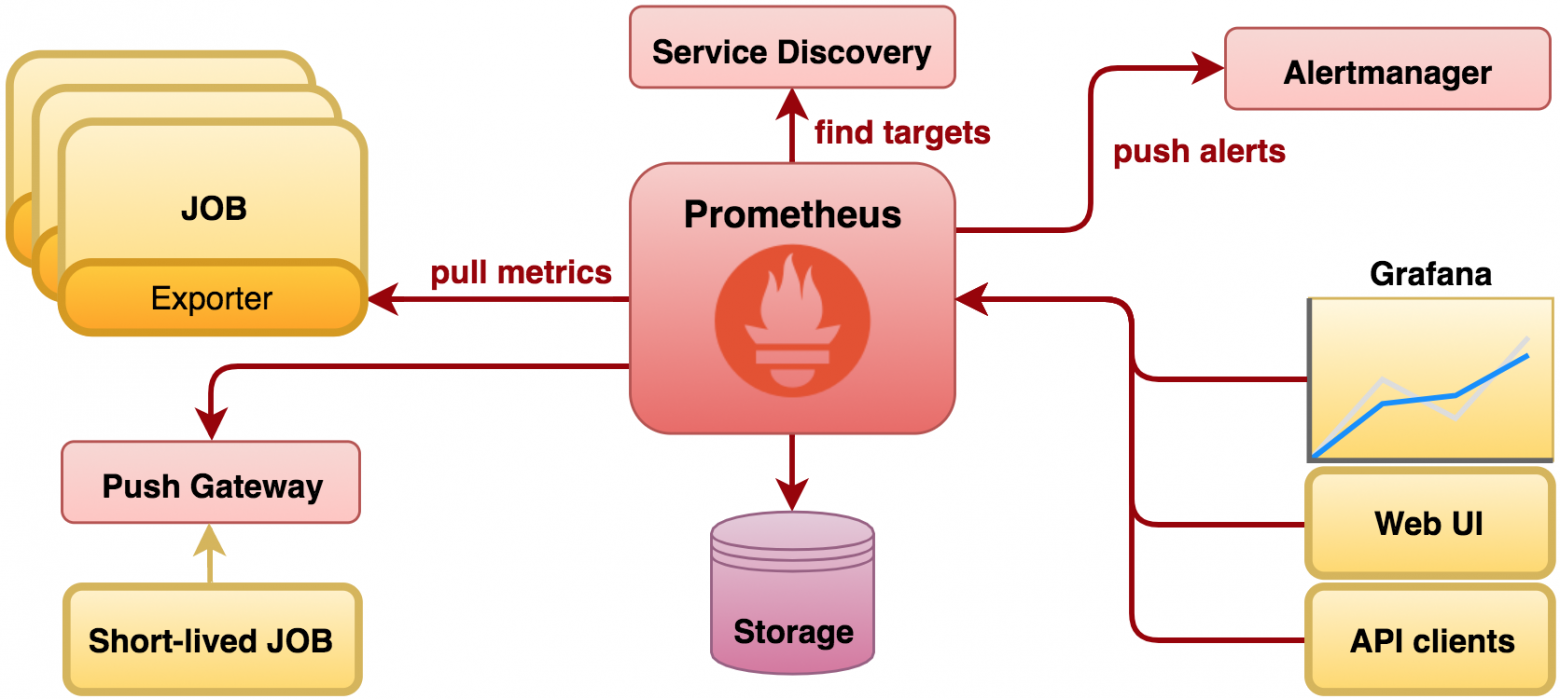
Помните, что обо всех нештатных ситуациях команда разработки и сопровождения должна узнавать раньше жалоб пользователей. Поэтому если при самой первой выкатке приложения может быть достаточно сбора метрик по 4xx и 5xx ошибкам приложения, задержкам по API-методам и паре важных бизнес-показателей, то по мере роста кодовой базы и важности сервиса необходимо постоянно добавлять всё больше специфичных и узконаправленных метрик.
Шаг 1. Code review

Если внимательно отнестись к этому шагу, то есть шанс отловить огромное количество ошибок и не краснеть перед пользователями. На code review не обязательно работать интерпретатором и придирчиво проверять каждую строчку; важно, чтобы проверяющий понимал общую идею каждой написанной функции, а в случае непонимания каких-то моментов не стеснялся обращаться к автору кода. Также убедитесь, что для каждого критически важного куска кода написан unit-тест, и проверьте корректность проверяемых тестом параметров. Общее покрытие кода тестами должно достигать 80% (code coverage можно проверять сторонними инструментами, например SonarQube).
Также при code review важно проверить миграции в базу данных: убедиться что добавление колонок или же создание индекса не «повесит» базу. А если такой шанс есть — вынести эти шаги в подготовительную к релизу часть и выполнить при минимальной нагрузке на сервер.
Особое внимание стоит уделить SQL-запросам: операции поиска, обновления и удаления всегда должны содержать WHERE-часть (если же в функцию все параметры переданы как null, тогда нужно падать с ошибкой и не допускать запроса к БД без параметров).
Также для всех подозрительных запросов стоит сделать explain (в идеальном случае — с продовой реплики БД) и убедиться, что «стоимость» запросов низкая и индексы используются. В противном случае нужно добавить в миграции недостающие индексы.
Шаг 2. Пентест
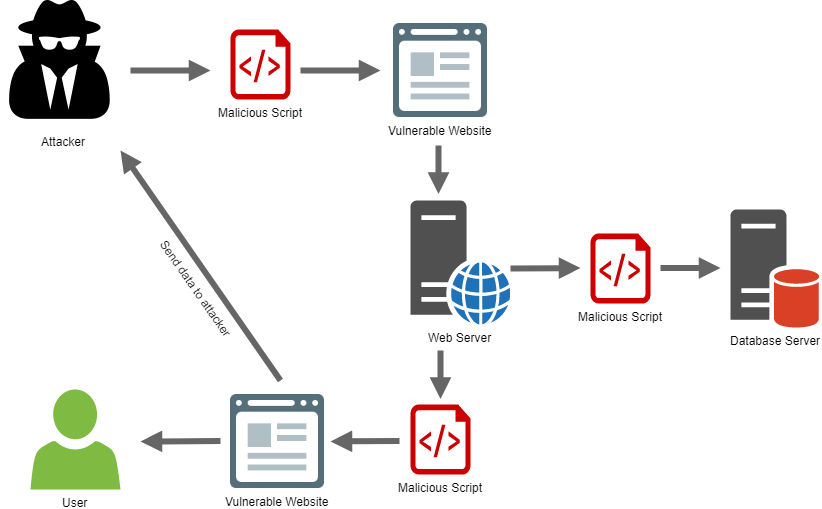
Для того, чтобы данные, хранение которых доверили вам ваши пользователи, не стали доступны третьим лицам, нужно провести pentest приложения (тестирование на проникновение). Это метод оценки безопасности компьютерных систем или сетей средствами моделирования атаки злоумышленника. В Домклик pentest проводят специалисты из Кибербезопасности. Если же в вашей компании нет специально обученных инженеров для сканированияуязвимостей, то рекомендую пройти хотя бы базовый курс по кибербезопасности (для разработчиков), чтобы не допускать самых детских ошибок.
По моему опыту следующий набор действий сильно снизит риск получения злоумышленником незащищённых данных:
Использовать актуальные версии библиотек (в старых версиях могут быть уязвимости). Выбирать наиболее популярные в сообществе библиотеки.
При работе с БД не использовать (или минимально использовать) raw SQL с конкатенацией. Убедиться, что используемый драйвер для подключения к БД автоматически избавляется от опасных спецсимволов в запросе (большинство SQL-инъекций строится именно на добавлении спецсимволов в запрос с последующим выполнением нужной злоумышленнику команды).
При сохранении текста, который впоследствии будет отображаться пользователям (например, комментарии), превращать текст в безопасный HTML, чтобы на странице не отобразился исполняемый JS-код.
Для каждого API-метода использовать контроль доступа по ролевой модели. Логировать, под каким пользователем произошли операции добавления, изменения, удаления данных.
Также отмечу, что после исправлений уязвимостей, выявленных на пентесте, необходимо повторное прохождение code review.
Шаг 3. Нагрузочное тестирование

Чтобы понять, сможет ли сервис выдержать «наплыв» пользователей, необходимо провести нагрузочное тестирование. Также этот шаг поможет понять, сколько запросов может выдержать один экземпляр или под сервиса, и правильно рассчитать запас на случай пиковых нагрузок.
Инструментов для нагрузочного тестирования великое множество, и в качестве базовых можно выбрать Apache JMeter либо утилиту wrk (для локальных тестов). Для создания симуляции сложного профиля нагрузки можно самостоятельно написать скрипт с нужными API-вызовами и запустить его в нужное количество потоков.
Шаг 4. Канареечный релиз
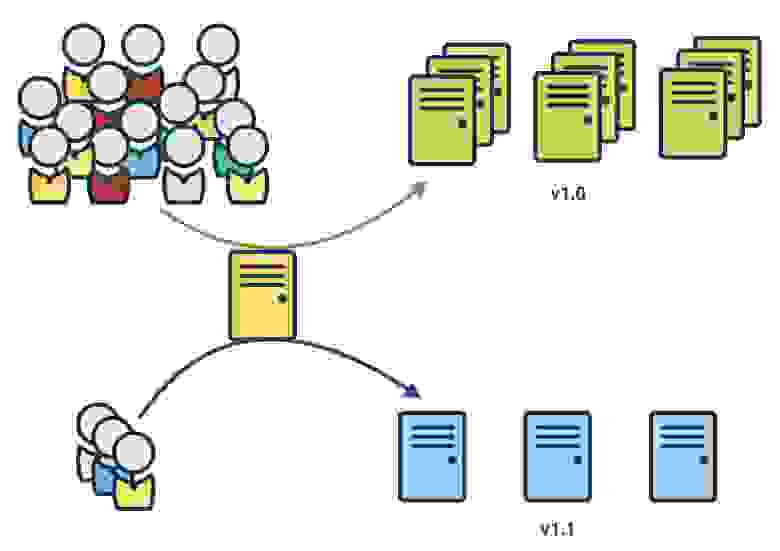
К сожалению, все возможные ошибки при релизе новой функциональности предусмотреть невозможно, но их влияние можно минимизировать при проведении канареечного релиза (canary release) — это метод снижения риска при внедрении новой версии в промышленную эксплуатацию путëм предоставления изменения небольшому подмножеству пользователей с нарастанием до состояния, когда это изменение становится доступным для всех. На каждом шаге повышения трафика на релизную версию необходимо мониторить ошибки и быть готовым в любой момент откатиться на старую версию (особенно важно проработать план отката миграций в БД в случае нештатных ситуаций).
Шаг 5. Поддержка сервиса в проде, мониторинг и исправление ошибок

После релиза важно мониторить ошибки и нетипичное поведение метрик хотя бы в течение суток. У команды разработки должен быть ресурс для оперативного исправления ошибок после релиза, задачи в спринт рекомендую планировать с учётом этого фактора. Если после релиза были найдены крупные ошибки, то команде стоит продумать шаги по недопущению похожих ситуаций, например усилить code review или тестирование. Также любые ошибки должны хорошо читаться в логах и метриках. Если же о серьёзной ошибке вы узнали от пользователей, то стоит внедрить новые метрики, которые бы явно сигнализировали о внештатной ситуации в будущем.
Заключение
У каждой компании своя специфика разработки, но надеюсь, что описанные выше шаги будут справедливы для большого количества веб-сервисов. В комментариях поделитесь своим видением правильной выкатки сервиса в production и опишите шаги, которые применяются в ваших компаниях или проектах.
