Выбор и настройка Garbage Collector для Highload системы в Hotspot JVM

При работе в сфере RTB (Real Time Bidding) одной из ключевых характеристик является время, затраченное на показ рекламы пользователю, зашедшему на сайт. Оно складывается из нескольких этапов, один из которых — аукцион за рекламное место, проводимый SSP (Supply Side Platform) между несколькими DSP (Demand Side Platform) системами. В этом случае критической величиной является время, за которое DSP успеет ответить своим инвентарем и денежной ставкой за данный показ. Как правило, верхняя граница этого времени составляет примерно 100 миллисекунд. С учетом того, что для оптимальной производительности рекламных кампаний требуется десятки тысяч запросов в секунду, выполнение данного требования может стать весьма нетривиальной задачей.
Наш Ad Server, отвечающий за основную работу GetIntent DSP разработан на языке Java и работает на стандартной Hotspot JVM, имеющей общеизвестные механизмы сборки мусора (GC). Поэтому наиболее оптимальный вариант лежит в анализе того, как именно происходит работа с памятью, и как следствие выбор наиболее подходящего алгоритма сборки мусора и его оптимальная настройка. Об этом и пойдет речь в данной статье.
В совокупности, наш ожидаемый результат — максимальный баланс между количеством серверов (чем меньше, тем лучше) и суммарной продолжительностью и частотой GC пауз, во время которых мы можем терять потенциальные показы.
Для тестирования использовалось 2 рабочих станции. На первой JVM запускалась с:
-Xmx4500m
На второй:
-Xmx12g
Сравнивались сборщики мусора CMS (Concurrent Mark Sweep) и G1 (Garbage First)
Тестирование производилось в течение 16 часов на нагрузке полностью соответствующей боевой.
CMS (Concurrent Mark Sweep)
CMS позволяет значительно сокращать задержки, связанные со сборкой мусора. Однако при его использовании приходится неизбежно сталкиваться с двумя основными проблемами, которые и создают необходимость в дополнительной настройке:
- Фрагментация памяти
- Высокий allocation rate
Положительно повлиять на первый параметр можно путем контролирования promotion rate показателя. Для этого необходимо определить, какой объем объектов попадает в Tenured, а какой «умирает молодым» в Eden области.
Тестирование производилось со следующими параметрами:
-XX:+UseConcMarkSweepGC
-XX:NewRatio=1, 3, 5
для логирования использовались:
-XX:+PrintGCDetails -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+PrintGCDateStamps -XX:+PrintCMSInitiationStatistics -XX:PrintCMSStatistics=1
G1 (Garbage First)
G1 GC выглядит заманчивым выбором для RTB bidder-а, так как его основая цель — выдерживать стабильные и предсказуемые Stop The World (STW) паузы. Это также обуславливает простоту и наглядность его настройки. Фактически надо оперировать только одним параметром — максимально допустимой длительностью STW паузы: -XX: MaxGCPauseMillis
В нашем случае ради исключения случайных долгих пауз можно пожертвовать небольшой долей throughput.
Относительно G1 GC, с момента его появления в качестве доступного для экспериментов сборщика мусора, сформировались некоторые предубеждения, главное из которых то, что MaxGCPauseMillis не выдерживается. Также есть озвученная Oracle рекомендация использовать его на достаточно больших размерах heap (>= 6 Gb).
Насколько все это актуально мы узнаем после нашего тестирования. Также уделим немного времени такой эксклюзивной для G1 GC функции как String Deduplication.
Тестирование производилось со следующими параметрами:
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100, 60, 40
Дополнительно были проведены тесты с параметром:
-XX:MaxTenuringThreshold=8
для логирования использовались:
-XX:+PrintGCDetails -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+PrintGCDateStamps -XX:+PrintAdaptiveSizePolicy -XX:+PrintReferenceGC
Сводная таблица распределения Stop The World пауз:

Однозначным победителем в данной конфигурации выходит CMS с флагом
-XX:NewRatio=5
Как можно заметить, несмотря на то, что показатель ms/sec паузы у данной конфигурации чуть хуже чем у остальных, она все равно показывает себя как самая стабильная — ~12 ms средняя пауза и практически 98% укладывается в норму — отличный для нас результат. При таких показателях на один Full GC в течение 16 часов можно закрыть глаза.
График распределения latency для лучших показателей G1 и CMS:

Анализ результатов CMS
Мы проэкспериментировали с наборами параметров, в которых размер Eden (-XX: NewRatio) был ½, ¼, и 1/6 от общего размера памяти. Средний promotion rate для этих конфигураций распределился соответствующим образом: 1.7, 2.75 и 2.79 mb/sec, что вполне логично — чем меньше размер Eden, тем больше мусора успевает просочиться непосредственно в Old Gen. Как можно заметить, с определенного момента, размер Eden области начинает слабо влиять на этот показатель. В нашем случае мы можем пожертвовать более высоким promotion rate (как следствие более частые OldGen сборки и большая вероятность фрагментации) ради минимально возможной средней задержкой в течении работы приложения.
Анализ результатов G1
Видно, что G1 тесно в столь маленьком heap. Mixed паузы очень часты,
-XX: MaxGCPauseMillis оказывает маленькое влияние на конечный результат, а конфигурация с желаемой паузой 40ms не смогла обойтись без Full GC.
Однако есть еще один момент, который нас смутил. По умолчанию G1 выбирает 15 ages для Survivor области. Мы решили посмотреть, действительно ли нам необходимо столько:
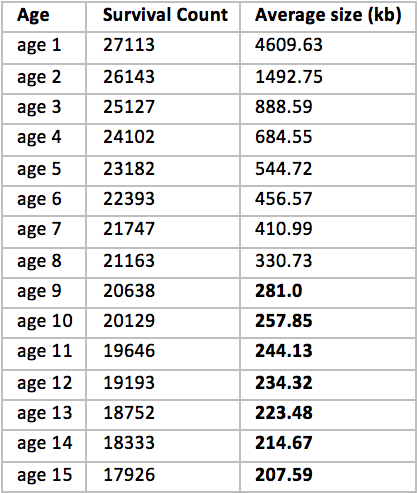
Очевидно странный знак. Начиная примерно с age 8 размер остается всегда примерно на одном уровне; это говорит о том, что это долгоживущие объекты, которые скорее всего в любом случае попадут в Tenured область, а до этого при каждой минорной сборке мы просто переливаем из пустого в порожнее, тогда как могли бы сразу поместить все это в OldGen. Хорошее решение — поставить в значение MaxTenuringThreshold=8.
Однако, в случае с heap 4.5Gb мы не заметили большой разницы в результатах, поэтому для краткости опустим их. Посмотрим изменится ли что-то на большом heap.
Сводная таблица распределения Stop-the-World пауз:

Состав представителей G1 немного изменился, т.к. параметр MaxTenuringThreshold=8 (в таблице mtt=8) в данной конфигурации начал приносить заметный результат.
На большом heap G1 расправил крылья и вышел вперед как по общему распределению пауз, так и по очень короткой максимальной паузе. При этом среднее время затрачиваемое на GC составило меньше 7ms каждую секунду, т.е. меньше 0.7%
График распределения latency для лучших показателей G1 и CMS:

Анализ результатов CMS
Считается, что основная проблема CMS это вопрос масштабируемости. Наше тестирование это подтверждают. Практически все показатели хуже, чем при использовании маленького размера heap. Из плюсов можно отметить, что благодаря большему объему памяти, влияния фрагментации здесь заметно ниже — ни одного Full GC за все время эксперимента.
Анализ результатов G1
Результат явно показывает, что G1 действительно гораздо стабильнее на больших объемах памяти; достаточно четко выполняются условия, заданные в настройках. Здесь бесспорный победитель с 40 ms latency. Средняя пауза выросла всего на 3 ms, когда как размер памяти вырос почти в 2.4 раза! Что уж говорить про показатель ms/sec — в два раза лучше.
Поскольку наш биддер работает с текстовым OpenRTB протоколом, пишет множество строковых логов, хранит строковые кеши, и т.д., то вполне логично ожидать большой эффект от этой новой функции. В теории количество сборок мусора должно сократиться при том, что время средней сборки увеличится. Мы добавили этот флаг для конфигурации с MaxGCPauseMillis = 100ms и Xmx=4500m:

Хоть средняя пауза и находится в указанных пределах, кол-во пауз превышающих 1000ms превысило допустимые пределы. Это видно на графике:

Попытки установить меньшую длительность паузы приводили к очень сильному росту потребления CPU. От использования данного параметра было решено отказаться.
Мы провели детальный анализ CMS и G1 сборщиков мусора, основной целью которого было понимание того, как сильно мы можем снизить влияние GC на latency — наиболее критичный показатель для нашей системы.
Вполне ожидаемый результат — однозначных выводов здесь нет. Для VM с размером памяти 5Gb, вышел победителем CMS с конфигурацией -XX: NewRatio=5; несмотря на большую максимальную паузу, в течении жизни приложения он показывал более стабильный результат, лучший percentile и среднюю задержку. Однако на VM с размером heap 12Gb G1 с большим перевесом опередил CMS, что оправдывает рекомендации Oracle; ms/sec задержка лучше в 1.94 раза, max пауза в 13.3 раза!
Благодаря этому исследованию мы могли больше не работать вслепую, руководствуясь лишь отдельными рекомендациями и разнородными мнениями; напротив, мы смогли найти идеальный баланс для нашей неоднородной в плане конфигурации системы, получая максимальную стабильность и как следствие прибыль из того, что мы имеем сегодня.
Авторы статьи — absorbb и dmart28
