Выбираем html-парсер для Apache.JMeter
Среднее качество работы парсеров (для семи сайтов)
Предлагаю:
- посчитать среднее качество полноты извлечения ссылок на встроенные ресурсы html-парсерами Apache.JMeter;
- проверить правда ли извлечение ссылок в Apache.JMeter 3.0 стало более полным;
- испытать в деле плагин CsvLogWriter.
Как гласит народная мудрость: Верить верь, но…
Описание проекта
Объект тестирования
Тестируются htmlParser-ы для Apache.JMeter 2.13 и Apache.JMeter 3.0.
Парсеры Apache.JMeter 2.13:
- LagartoBasedHtmlParser;
- HtmlParserHTMLParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser.
Парсесы Apache.JMeter 3.0:
- LagartoBasedHtmlParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser.
Парсеры разбирают стартовые страницы различных веб-сайтов:
- stackoverflow.com;
- habrahabr.ru;
- yandex.ru;
- mos.ru;
- jmeter.apache.org;
- google.ru;
- linkedin.com;
- github.com.
Основа тестирования
Основой послужили изменения в Apache.JMeter 3.0, см. http://jmeter.apache.org/changes.html.
Core improvements
Dependencies refresh
Deprecated Libraries dropped or replaced by up to date ones:
- htmllexer, htmlparser removed
- jdom removed
Удалён парсер htmlparser и более неиспользуемая библиотека jdom.Protocols and Load Testing improvements
Parallel Downloads is now realistic and scales much better:
- Parsing of CSS imported files (through import) or embedded resources (background, images, …)
Добавлен новый парсер для CSS-файлов, будут извлекаться ссылки на другие CSS-файлы (через import) и ссылки на ресурсы, указанные в CSS-файлах: фоновые изображения, картинки, …Incompatible changes
- Since version 3.0, the parser for embedded resources (replaced since 2.10 by Lagarto based implementation) which relied on the htmlparser library (HtmlParserHTMLParser) has been dropped along with its dependencies.
- The following jars have been removed:
- htmllexer-2.1.jar (see Bug 59037)
- htmlparser-2.1.jar (see Bug 59037)
- jdom-1.1.3.jar (see Bug 59156)
Удалён парсер htmlparser и более неиспользуемые библиотеки htmllexer и jdom.Improvements
HTTP Samplers and Test Script Recorder
- Bug 59036 — FormCharSetFinder: Use JSoup instead of deprecated HTMLParser
- Bug 59033 — Parallel Download: Rework Parser classes hierarchy to allow plug-in parsers for different mime types
- Bug 59140 — Parallel Download: Add CSS Parsing to extract links from CSS files
Для поиска аттрибутаaccept-charsetв тегахformтеперь используется JSoup вместо удалённого HTMLParser [Bug 59036]. Реализован парсер CSS-файлов [Bug 59140] и этот парсер используется по умолчанию [Bug 59033].
Цели тестирования
Сравнить работу всех доступных парсеров. В частности сравнить между собой парсеры версий 2.13 и 3.0, убедиться, что загрузка встроенных ресурсов стала реалистичнее и лучше.
Стратегия
Этап 1:
- Выполнить загрузку стартовых страниц списка сайтов используя все 5 парсеров Apache.JMeter 2.13 и записать логи.
- Выполнить загрузку стартовых страниц списка сайтов используя все 4 парсера Apache.JMeter 3.0 и записать логи.
- Проанализировать логи работы Apache.JMeter и сравнить их между собой. Оценить, стала ли загрузка встроенных ресурсов лучше, расширился ли перечень загружаемых встроенных ресурсов.
Этап 2:
- Выполнить загрузку стартовых страниц списка популярных сайтов, используя Google Chrome и сервис webpagetest.org.
- Проанализировать отчёты из webpagetest.org и сравнить их с результатами анализа логов Apache.JMeter. Оценить, реалистичность загрузки встроенных ресурсов.
Подход к тестированию
Чтобы точно определить сколько запросов посылается во время открытия страницы сайта из Apache.JMeter все запросы логируются:
- View Results Tree — стандратный логгер, логирование в XML-формат с логированием подзапросов, XML-лог будет использоваться для выяснения деталей запросов/ответов/ошибок;
- CsvLogWriter — кастомный логгер https://github.com/pflb/Jmeter.Plugin.CsvLogWriter, логирование в CSV-формат с логированием подзапросов, CSV-лог будет использоваться для программного подсчёта статистики по работе различных парсеров;
- Выполняется только количественная оценка, адреса подзапросов посписочно не сравниваются.
Чтобы иметь возможность сгруппировать запросы по версиям Apache.JMeter, парсерам и сайтам, в лог будут записываться дополнительные переменные для каждого запроса:
- siteKey — тестируемый сайт;
- jmeterVersion — версия Apache.JMeter;
- htmlParser — название html-парсера, используемого в данный момент.
Оценка улучшения работы парсеров для версии 3.0 по сравнению с версией 2.13
Кардинальных улучшений полноты разбора html-страниц нет, есть ухудшения.
Существенное отличие — в парсерах для Apache.JMeter 3.0 есть рекурсивная загрузка страницы промо-материалов браузера Яндекс Браузер. Это проявляется при загрузке https://yandex.ru/.
Сайты с малым количеством контента — хороший результат
На простых сайтах, таких как jmeter.apache.org, все парсеры работают одинаково. Создавая то же количество подзапросов, которое создаётся браузером. Качество работы парсеров для jmeter.apache.org — идеально, 100%.
Сайты с большим количеством контента — плохой результат
Но на таком сайте как mos.ru, парсеры найдут в среднем 22 ссылки на встроенные ресурсы, тогда как полная загрузка страницы с загрузкой всех встроенных ресурсов браузером — 144 запроса. Качество низкое.
Аналогично на сайте habrahabr.ru, парсер Lagardo из Apache.JMeter 3.0 найдёт 55 ссылок, тогда как браузер сделает 117 подзапросов. Качество — 47,01%. Удовлетворительное качество полноты извлечения ссылок на встроенные ресурсы.
Количество подзапросов при использовании различных парсеров
Таблица на Google Docs: JMeter.HtmlParser.Compare (верхняя таблица).
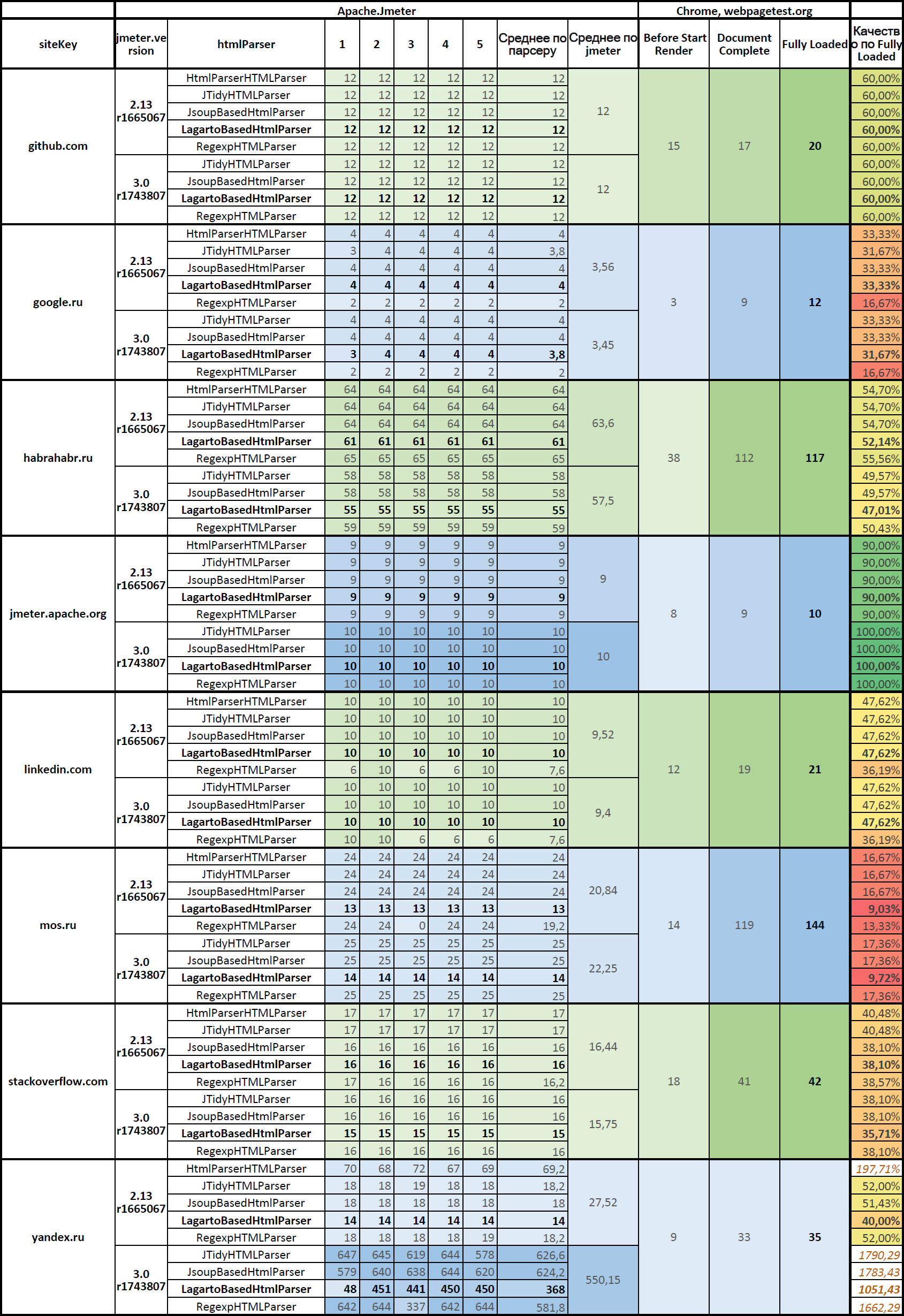
Статистика работы Apache.JMeter в разрезе версий и html-парсеров и её сравнение с работой Google Chrome
Описание столбцов:
- Before Start Render — количество подзапросов, сделанных браузером, до момента начала отображения содержимого страницы. Это html-разметка, основные js и css-файлы, основные изображения.
- Document Complete — количество подзапросов, сделанных браузером, на момент полной загрузки документа. Тут уже загрузились все ресурсы страницы.
- Fully Loaded — количество подзапросов, сделанных браузером, на момент когда отработал javascript, когда загрузилось всё.
Хорошим результатом работы парсеров будет, если подзапросов будет столько же, сколько браузер Google Chrome делает на момент Document Complete, а отличным — на момент Fully Loaded. Мерилом реалистичности работы Apache.JMeter при использовании конкретного парсера будем считать близость количества подзапросов к количеству подзапросов, выполняемых браузером на момент Fully Loaded.
Если исключить результаты тестирования сайта yandex.ru, где:
- парсинг уходит в рекурсию делая снова и снова запросы к yandex.ru пока глубина рекурсии не достигает максимального уровня и завершается ошибкой:
>java.lang.Exception: Maximum frame/iframe nesting depth exceeded.
и за мерило качества работы парсеров принять количество подзапросов на момент Fully Loaded, то получим такую таблицу среднего качества работы парсеров.
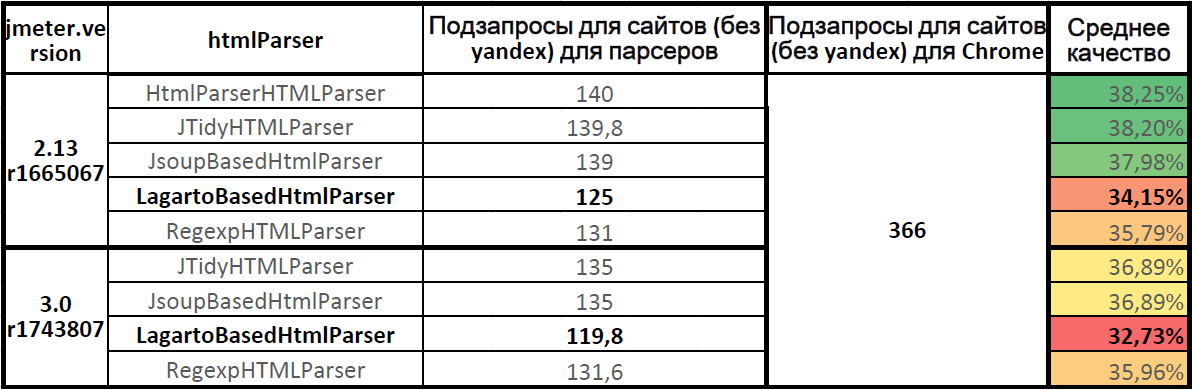
Среднее качество работы парсеров
Таблица на Google Docs: JMeter.HtmlParser.Compare (нижняя таблица).
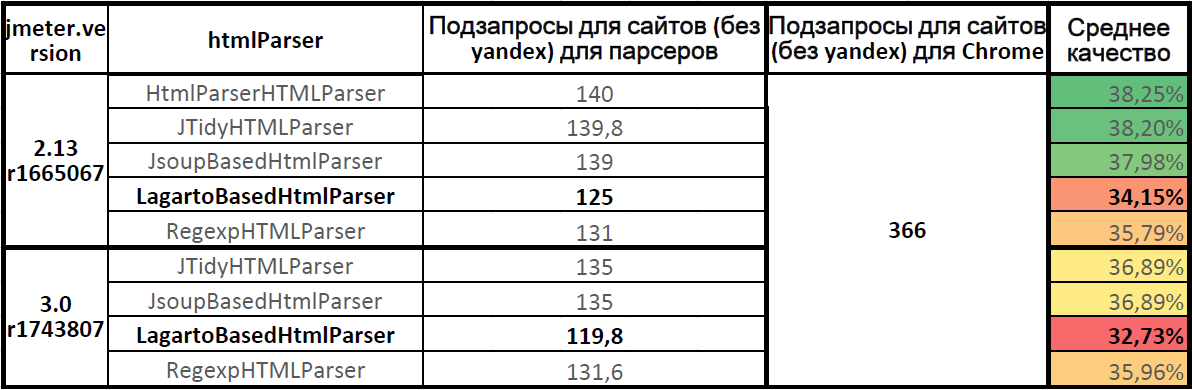
Среднее качество работы парсеров (для семи сайтов, без yandex.ru)
Самый точный парсер HTMLParser в Apache.JMeter 2.13. В Apache.JMeter 3.0 парсеры Jsoup и JTidy показали одинаковое качество. Парсер Lagarto отстаёт от лидеров. Полнота парсинга для парсера Lagarto в Apache.JMeter 3.0 снизилась по сравнению с Apache.JMeter 2.13.
Качество работы парсера Lagarto на актуальной версии Apache.JMeter 3.0 составило 32,73%, лишь треть всех подзапросов была послана, две трети нагрузки на статику не было подано.
Логи и их обработкаИсходные данные
Все логи доступны по ссылке: https://drive.google.com/drive/folders/0B5nKzHDZ1RIiVkN4dDlFWDR1ZGM.
Отчёты WebPageTest.org
| sytekey | webpagetest.org | Raw page data (.csv) | Raw object data (.csv) | HTTP Archive (.har) |
|---|---|---|---|---|
| github.com | 160819_VF_FM8 | github.com.summary.csv | github.com.details.csv | github.com.har |
| google.ru | 160819_C9_FQD | google.ru.summary.csv | google.ru.details.csv | google.ru.har |
| habrahabr.ru | 160819_8N_FRB | habrahabr.ru.summary.csv | habrahabr.ru.details.csv | habrahabr.ru.har |
| jmeter.apache.org | 160819_CG_FSM | jmeter.apache.org.summary.csv | jmeter.apache.org.details.csv | jmeter.apache.org.har |
| linkedin.com | 160819_K2_FY1 | linkedin.com.summary.csv | linkedin.com.details.csv | linkedin.com.har |
| mos.ru | 160819_91_G0F | mos.ru.summary.csv | mos.ru.details.csv | mos.ru.har |
| stackoverflow.com | 160819_S0_G18 | stackoverflow.com.summary.csv | stackoverflow.com.details.csv | stackoverflow.com.har |
| yandex.ru | 160819_MR_G1R | yandex.ru.summary.csv | yandex.ru.details.csv | yandex.ru.har |
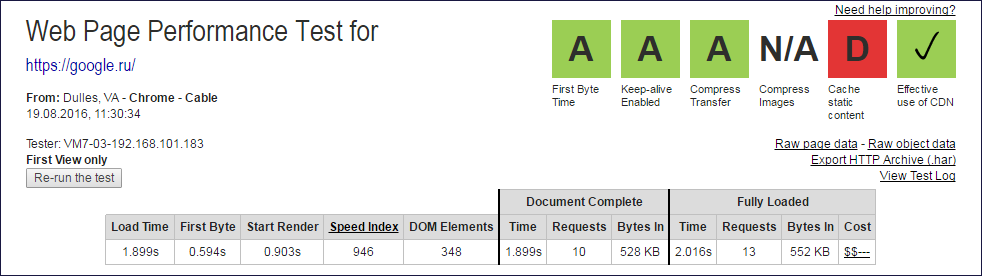
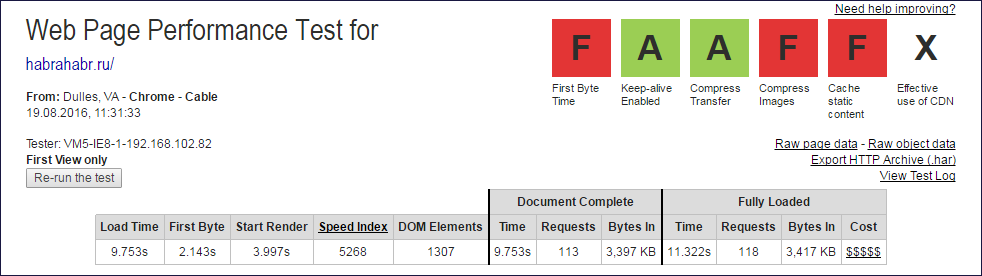
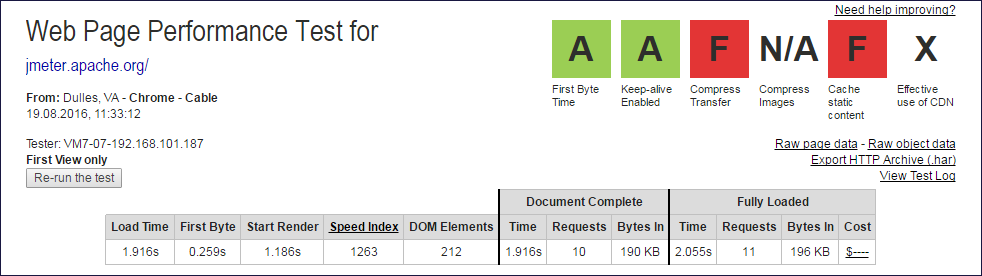

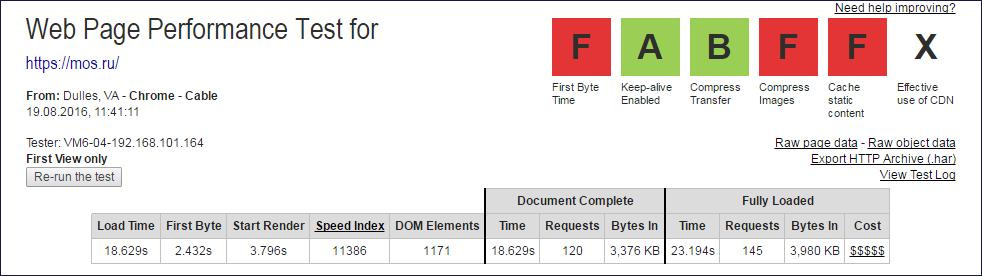

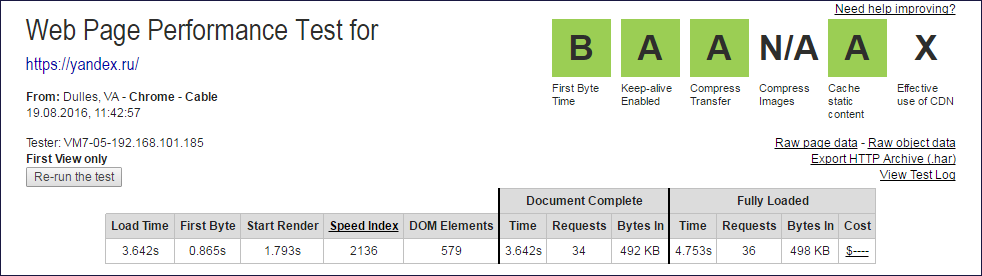
Шапки отчётов webpagetest.org из которых извлекались данные Document Complete и Fully Loaded
Из значений колонок Document Complete и Fully Loaded нужно исклюить один запрос (корневой), чтобы получить количество подзапросов.
Логи Apache.JMeter
Для обработки используются csv-логи, сформированные плагином CsvLogWriter:
- проект: https://github.com/pflb/Jmeter.Plugin.CsvLogWriter;
- описание на habrahabr.ru: Плагин CsvLogWriter для JMeter.
Сторонний плагин используется, чтобы в csv-лог попали запросы на embedded-ресурсы.
В результате работы CsvLogWriter формируется лог, в список колонок которого входят:
- timeStamp — момент времени;
- URL — адрес запроса;
- elapsed — длительность получения ответа на запрос;
- bytes — размер ответа;
- siteKey — используемый сайт;
- htmlParser — название используемого ;
- jmeterVersion — используемая версия Apache.JMeter;
- i — номер итерации тестирования.
Автоматизация обработки логов
Аггрегация csv-логов Apache.JMeter выполняется при помощи pandas вот таким кодом на python:
import pandas as pd
import codecs
from os import listdir
import numpy as np
# Настройки - каталог с логами и настройки считывания логов.
dirPath = "D:/project/jmeter.htmlParser.3.0.vs.2.13/logs"
read_csv_param = dict( index_col=['timeStamp'],
low_memory=False,
sep = ";",
na_values=[' ','','null'])
# Получение списка csv-файлов в каталоге с логами.
files = filter(lambda a: '.csv' in a, listdir(dirPath))
# Чтение содержимого всех csv-файлов в DataFrame dfs.
csvfile = dirPath + "/" + files[0]
print(files[0])
dfs = pd.read_csv(csvfile,**read_csv_param)
for csvfile in files[1:]:
print(csvfile)
tempDfs = pd.read_csv(dirPath + "/" + csvfile, **read_csv_param)
dfs = dfs.append(tempDfs)
#dfs.to_excel(dirPath + "/total.xlsx")
# Убрать из выборки все JSR223, по ним статистику строить не надо, оставить только HTTP Request Sampler.
# У JSR223 URL пустой, у HTTP-запросов URL указан.
dfs = dfs[(pd.isnull(dfs.URL) == False)]
# Сводная таблица по количеству подзапросов, сохраняется в report.subrequests.html - основной результат работы.
# Из количества запросов удаляется один запрос, чтобы исключить корневой запрос.
# Цель данного исследования - подсчёт количества подзапросов, поэтому корневой исключается.
pd.pivot_table(dfs,
index=['siteKey', "jmeterVersion", "htmlParser"],
values="URL",
columns=["i"],
aggfunc=lambda url: url.count()-1).to_html(dirPath + "/report.subrequest.count.html")

Рекурсивная загрузка встроенных ресурсов для актуальной версии Apache.JMeter 3.0 с настройками по умолчанию (html-парсер Lagarto) на сайте yandex.ru
Как видно:
- Apache.JMeter находит и переходит по ссылке
https://yandex.ru/clck/redir/dtype=stred....7004fcb3793e79bb1ac9e&keyno=12 - Затем находит новую уникальную ссылку
https://yandex.ru/clck/redir/dtype=stred....cd1c46cad58fbfe2f61&keyno=12 - И так далее, уходит в рекурсию.
В данном случае это картинка внутри ссылки на загрузку Яндекс Браузера: 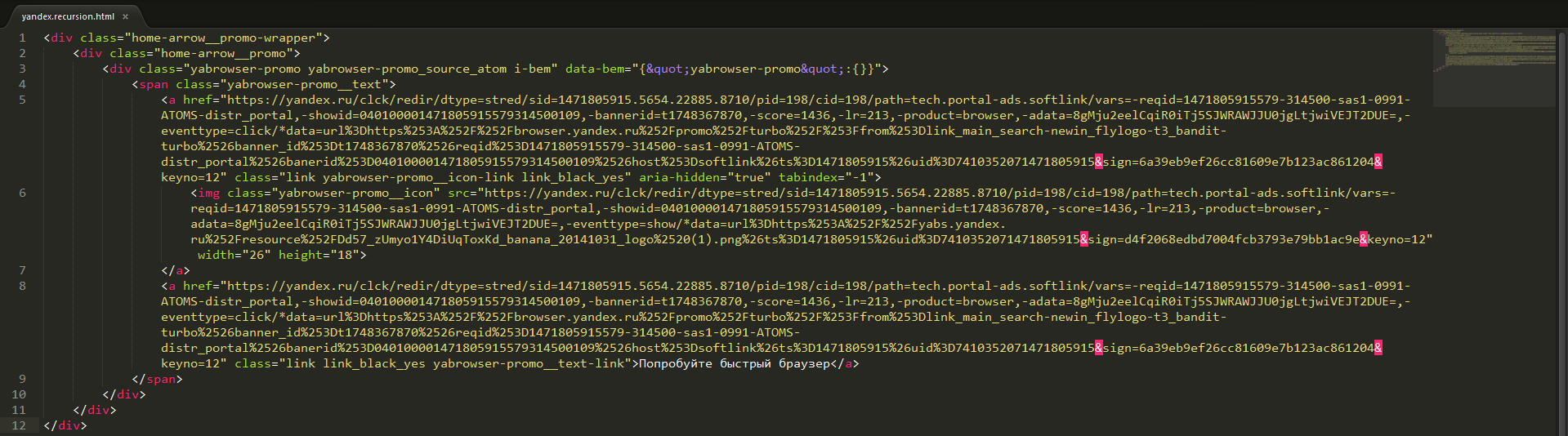
Фрагмент html-кода сайта yandex.ru обработка которого добавляет новый шаг рекурсии, ссылки и картинка для скачивания Яндекс Браузера
Картинку парсер находит. JMeter пробует её скачать, в ответ получает html-страницу, там снова ссылка на картинку и другие ссылки. И всё повторяется. Поведение Apache.JMeter корректное.
А в Apache.JMeter 2.13 рекурсия просходит только на парсере HtmlParser, догадки почему не происходит на других:
- есть ограничение на длину ссылок, и за счёт отсекания уникального окончания ссылки рекурсии не происходит;
- или в Apache.JMeter 2.13, что-то неправильно работает в парсерах;
- или в Apache.JMeter 2.13, что-то работает наоборот правильно — куки, ещё что-то и сам сервер Яндекса отвечает ему так, чтобы тот не уходил в рекурсию, например, отвечает картинкой на запрос картинки, а не новой html-страницей.
Гадать не буду. Кажется безвыходная ситуация. Но таких ситуаций не бывает. Всегда есть решение.
Например, можно попробовать в качестве User-Agent указать Яндекс Браузер. Тогда сервер, наверно, не покажет картинку для скачивания браузера, или на запрос картинки будет отвечать картинкой, и рекурсии не будет. Это догадка, не проверял её.
Сейчас в скрипте был указан User-Agent для Google Chrome для синхронности с работой webpagetest.org, и сервер видя не свой браузер, видимо, предлагает ссылку на свой.
Состав проекта- jmeter.testfile.jmx — тестовый скрипт для Apache.JMeter 2.13 и Apache.JMeter 3.0 принимающий на вход параметры:
URL— адрес тестируемого сайта, например, https://yandex.ru/;siteKey— строка по которой будет осуществляться группировка записей в логах, например, yandex.ru;loopCount— количество итераций теста, используется несколько итераций из-за того, что работа веб-сайтов может быть нестабильной;htmlParser.className— парсер для извлечения ссылок на встроенные ресурсы;- для работы скрипта необходимо скачать и установить дополнительный плагин CsvLogWriter.
- jmeter.3.0.bat — командный файл запуска теста для Apache.JMeter 3.0, тут задаётся путь к папке
/bin/Apache.JMeter 3.0, путь к тестовому скрипту jmeter.testfile.jmx, опции запуска теста, а также список htmlParser-ов проверка работы которых выполняется; - jmeter.2.13.bat — командный файл запуска теста для Apache.JMeter 2.13, тут задаётся путь к папке
/bin/Apache.JMeter 2.13, путь к тестовому скрипту jmeter.testfile.jmx, опции запуска теста, а также список htmlParser-ов проверка работы которых выполняется; - test.bat — командный файл запуска теста на двух версиях Apache.JMeter, 2.13 и 3.0, файл содержит количество итераций тестирования и адреса тестируемых сайтов. Файл вызывает файлы jmeter.2.13.bat и jmeter.3.0.bat;
- jmeter.3.0.vs.jmeter.2.13.ipynb — блокнот для jupyter для анализа логов работы Apache.JMeter;
- statistics.xlsx — таблица со статистикой по работе парсеров, результат исследования.
Тест легко изменить под себя, указать свои сайты и нужное количество итераций. Все настройки задаются в файле test.bat.
CALL jmeter.2.13.bat http://stackoverflow.com/ 5 stackoverflow.com
CALL jmeter.2.13.bat https://habrahabr.ru/ 5 habrahabr.ru
CALL jmeter.2.13.bat https://yandex.ru/ 5 yandex.ru
CALL jmeter.2.13.bat https://www.mos.ru/ 5 mos.ru
CALL jmeter.2.13.bat http://jmeter.apache.org/ 5 jmeter.apache.org
CALL jmeter.2.13.bat https://www.google.ru/ 5 google.ru
CALL jmeter.2.13.bat https://www.linkedin.com/ 5 linkedin.com
CALL jmeter.2.13.bat https://github.com/ 5 github.com
CALL jmeter.3.0.bat http://stackoverflow.com/ 5 stackoverflow.com
CALL jmeter.3.0.bat https://habrahabr.ru/ 5 habrahabr.ru
CALL jmeter.3.0.bat https://yandex.ru/ 5 yandex.ru
CALL jmeter.3.0.bat https://www.mos.ru/ 5 mos.ru
CALL jmeter.3.0.bat http://jmeter.apache.org/ 5 jmeter.apache.org
CALL jmeter.3.0.bat https://www.google.ru/ 5 google.ru
CALL jmeter.3.0.bat https://www.linkedin.com/ 5 linkedin.com
CALL jmeter.3.0.bat https://github.com/ 5 github.com
Далее результаты можно вставлять с Excel-файл с настроенными формулами и получать наглядную таблицу результатов.
Можно попробовать доработать парсеры, и по похожей методике отслеживать улучшение качества разбора embedded-ресурсов.Выводы
Особой практической ценности в статье нет. Но некоторые полезные выводы сделать можно:
- парсер в среднем извлекает ссылки только на треть ресурсов;
- парсеры работают почти одинаково, а значит можно применять любой;
- парсеры заточены под работу с простыми сайтами, такими как jmeter.apache.org;
- на сайтах с большим количеством содержимого парсеры работают значительно хуже реального браузера;
- полнота загрузки встроенных ресурсов в новой версии JMeter незначительно снизилась, а не возросла;
- продемонстрировано прикладное использование плагина CsvLogWriter, логирующего запросы к embedded-ресурсам в csv-лог, который сделала моя коллега Александра Sanchez92;
- с помощью bat-файлов, передачи парамеров JMeter через командную строку, логирования переменных и обработки csv-логов с помощью pandas можно тестировать сам инструмент тестирования, см. проект на github https://github.com/pflb/jmeter.htmlParser.3.0.vs.2.13, методика отработана.
