Выбираем хранилище данных для Prometheus: Thanos vs VictoriaMetrics
Всем привет. Ниже представлена расшифровка доклада с Big Monitoring Meetup 4.
Prometheus — система мониторинга различных систем и сервисов, с помощью которой системные администраторы могут собирать информацию о текущих параметрах систем и настраивать оповещения для получения уведомлений об отклонениях в работе систем.
В докладе будет сравнение Thanos и VictoriaMetrics — проектов для долгосрочного хранения метрик Prometheus.


Сначала расскажу про Prometheus. Это система мониторинга, которая собирает метрики с заданных target’ов и сохраняет их в локальное хранилище. Prometheus умеет записывать метрики в удаленное хранилище, умеет генерировать alert’ы и recording rules.

Ограничения Prometheus:
- У него нет global query view. Это когда у вас есть несколько независимых экземпляров prometheus. Они собирают метрики. И вы хотите сделать запрос поверх всех этих метрик, собранных с разных экземпляров prometheus. Prometheus это не позволяет.
- У prometheus производительность ограничена только одним сервером. Prometheus автоматически не может масштабироваться на несколько серверов. Вы только можете вручную разделить ваши target’ы между несколькими Prometheus’ами.
- Объем метрик в Prometheus ограничен только одним сервером по той же причине, по которой он автоматически не может автоматически масштабироваться на несколько серверов.
- В Prometheus не так-то просто организовать сохранность данных.

Решения этих проблем/задач?
Решения такие:
Все эти решения для удаленного хранения данных, собранных Prometheus. Они решают проблему remote storage с предыдущего слайда по разному. В данной презентации я расскажу только про первые два решения: Thanos и VictoriaMetrics.
Впервые информация про Thanos появилась по этой ссылке. Там описана архитектура Thanos и как он работает.

Thanos берет данные, которая сохранил Prometheus на локальный диск, и копируют их в S3, в GCS либо в другой object storage.

Таким образом Thanos обеспечивает global query view. Вы можете запрашивать данные, сохраненные в object storage c нескольких экземпляров Prometheus.

Thanos поддерживает PromQL и Prometheus querying API.

Thanos использует код Prometheus для хранения данных.

Thanos разрабатывает те же разработчики, что и Prometheus.
Про VictoriaMetrics. Вот ссылка, где мы впервые рассказали про VictoriaMetrics.

VictoriaMetrics получает данные с нескольких prometheus по remote write API протоколу, поддерживаемым Prometheus.
VictoriaMetrics обеспечивает global query view, так как несколько экземпляров Prometheus могут записывать данные в одну VictoriaMetrics. Соответственно, вы можете сделать запросы по этим всем данным.

VictoriaMetrics также поддерживает, как и Thanos — PromQL и Prometheus querying API.

В отличие от Thanos, исходный код VictoriaMetrics написан с нуля и оптимизирован по скорости и потребляемым ресурсам.

VictoriaMetrics в отличие от Thanos, масштабируется как вертикально так и горизонтально. Есть Single-node версия, которая масштабируется вертикально. Вы можете начать с одного процессора и 1 ГБ памяти и постепенно расти до сотни процессоров и 1ТБ памяти. VictoriaMetrics умеет использовать все эти ресурсы. Ее производительность вырастет примерно в 100 раз по сравнению с 1-ядерной системой.

История Thanos началась в ноябре 2017 года, когда появился первый публичный коммит. До этого Thanos разрабатывался внутри компании improbable.io.

В июне 2019 года был знаковый релиз 0.5.0, в котором убрали gossip протокол. Eго убрали из Thanos, потому что он себя показал не с лучшей стороны. Часто кластер Thanos неправильно работал, неправильно подключались к нему ноды из-за gossip протокола. Поэтому решили его оттуда убрать. Я считаю, что это правильное решение.

В том же июне 2019 года они отправили заявку номер 256 в Cloud Native Computing Foundation.

И через пару месяцев Thanos приняли в Cloud Native Computing Foundation, в которую входит Prometheus, Kubernetes и другие популярное проекты.

В январе 2018 года началась разработка VictoriaMetrics.

В сентябре 2018 я впервые публично упомянул про VictoriaMetrics.

В декабре 2018 года опубликовали Single-node версию.

В мае 2019 были опубликованы исходники как Single-node, так и кластерной версии.

В июне 2019, также как Thanos, мы подали заявку в CNCF foundation под номером 255. Мы подали заявку на один день раньше, чем подал заявку Thanos.

Но, к сожалению, нас до сих пор не приняли туда. Нужна помощь комьюнити.

Рассмотрим самые главные слайды, показывающие архитектуру Thanos и VictoriaMetrics.

Начнем с Thanos. Желтые компоненты — это компоненты Prometheus. Все остальное — это компоненты Thanos. Начнем с самого главного компонента. Thanos sidecar — это компонент, который устанавливается рядом с каждым Prometheus. Он занимается тем, что загружает данные Prometheus из локального storage в S3 либо другой Object Storage.
Есть еще такой компонент, как Thanos Store Gateway, который умеет считывать эти данные c Object Storage при входящих запросах от Thanos query. Thanos query — компонент реализует PromQL и Prometheus API. То есть снаружи он выглядит как Prometheus. Принимает запросы PromQL, отправляет их в Thanos Store Gateway, Thanos Store Gateway достает нужные данные из Object Storage, отправляет их назад.
Но у нас в Object Storage хранятся данные без последний двух часов из-за особенности реализации Thanos sidecar, который не может закачать последние два часа в Object Storage S3, так как для этих двух часов Prometheus еще не создал файлы в локальном хранилище.
Как же это решили обойти? Thanos query кроме запросов в Thanos Store Gateway, отправляет параллельно запросы еще в каждый Thanos sidecar, который находятся рядом с Prometheus.
А Thanos sidecar, в свою очередь, проксирует запросы дальше в Prometheus, и достает данные за последние два часа.
Кроме этих компонент, есть еще опциональный компонент, без которого Thanos будет плохо себя чувствовать. Это Thanos Compact, который занимается слиянием мелких файлов на Object Storage в более крупные файлы, которые были загружены сюда Thanos sidecar’ами. Thanos sidecar загружает туда файлы с данными за два часа.
Эти файлы, если их не сливать в более крупные файлы, то их количество может вырастить очень существенно. Чем больше таких файлов, тем больше нужно памяти для Thanos Store Gateway, тем больше нужно ресурсов для передачи данных по сети, метаданных. Работа Thanos Store Gateway становится неэффективной. Поэтому нужно обязательно запускать Thanos Compact, который сливает мелкие файлы в более крупные, чтобы таких файлов было меньше и чтобы уменьшить overhead на Thanos Store Gateway.
Есть еще такой компонент как Thanos Ruler. Он выполняет Prometheus alerting rules и может вычислять Prometheus recording rules, для того чтобы записывать данные снова в Object Storage.
Вот такая схема простая у Thanos.
Теперь сравним со схемой VictoriaMetrics.
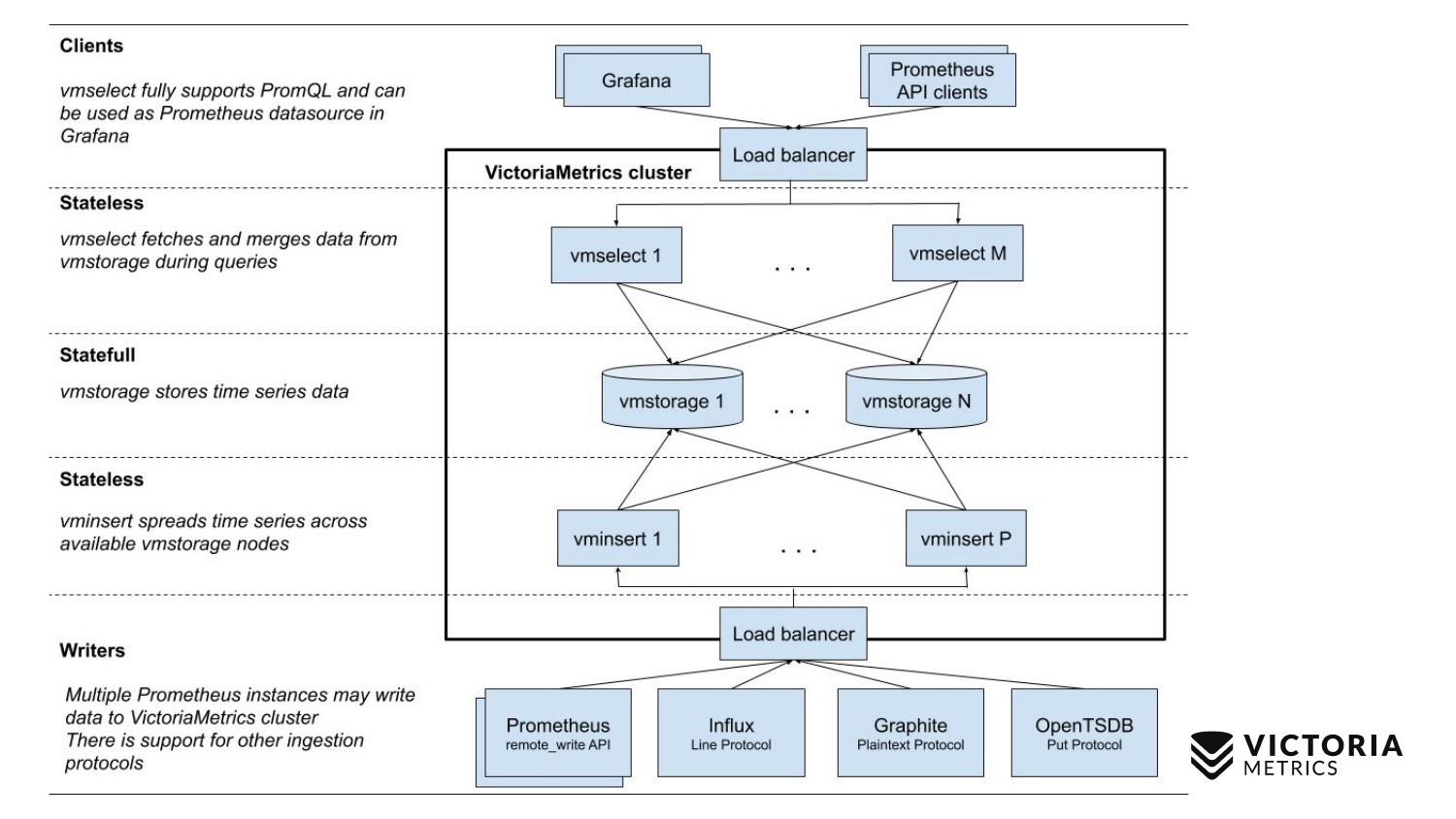
У VictoriaMetrics есть 2 версии: Single-node и кластерная версия. Single-node работает на одном компьютере. В Single-node нет этих компонентов, просто один бинарник. Этот бинарник на слайде выглядит вот этим квадратом. Все, что находится внутри квадрата — это содержимое бинарного файла для Single-node версии. Вам необязательно про него знать. Просто запускаете бинарник — и все у нас работает.
Кластерная версия сложнее. Внутри нее находится три разных компонента: vmselect, vminsert и vmstorage. Из их названия должно быть понятно, чем каждый из них занимается. Insert компонент принимает данные в разных форматах: из Prometheus remote write API, Inlux line протокола, Graphite протокола и из OpenTSDB протокола. Insert компонент принимает их, парсит и распределяет между имеющимися storage компонентами, где данные уже сохраняется. Select компонент, в свою очередь, принимает PromQL запросы. Он реализует PromQL, а также Prometheus querying API, и он может быть использован, как замена Prometheus в Grafana или других Prometheus API клиентах. Select принимает promql запрос, парсит его, считывает необходимые данные для выполнение этого запроса из storage нод, процессит эти данные и возвращает ответ.

Сравним сложность установки Thanos и VictoriaMetrics.

Начнем с Thanos. Перед тем, как начать работать с Thanos, нужно создать storage bucket в Object Storage, такой как S3 или GCS, чтобы Thanos sidecar мог туда записывать данные.

Потом для каждого Prometheus нужно установить Thanos Sidecar. Перед этим нужно не забыть отключить data compaction в Prometheus. Data compaction периодически сжимает данные в локальном хранилище Prometheus для того, чтобы уменьшить потребление ресурсов.
Когда вы устанавливаете Thanos Sidecar к вашим Prometheus’ам, вы должны отключить этот data compaction, потому что Thanos Sidecar не умеет нормально работать при включенном data compaction. Это означает, что ваш Prometheus начинает сохранять данные блоками по два часа и перестает сливать в более крупные блоки. Соответственно, если вы делаете запросы, которые превышают длительность последние два часа, то они будут не настолько эффективно работать, по сравнению с тем как могли бы работать, если был бы включен data compaction.

Поэтому Thanos рекомендует уменьшать время хранения данныех (data retention) в локальном storage до 6–8 часов, чтобы снизить этот overhead большого количества мелких блоков.
После того как вы установили Thanos Sidecar, вы должны для каждого Object Storage Bucket установить два компонента. Это Thanos Compactor и Thanos Store Gateway.

После этого нужно установить Thanos query и настроить его, чтобы он умел подключаться ко всем Thanos Store Gateway, которые у вас есть, а также умел подключатся ко всем Thanos Sidecar.
Тут может быть небольшая проблемка.

Вам нужно настроить надежное и защищенное подключение от Thanos query к этим компонентам. И если у вас Prometheus’ы находятся в разных дата-центрах, либо в разных VPC, то к ним запрещены подключения извне. Но для работы Thanos query вам нужно как-то настроить подключение туда, и вы должны придумать способ.
Если у вас таких дата-центров много, то, соответственно, снижается надежность всей системы. Так как Thanos query должен постоянно держать подключения ко всем Thanos Sidecar, расположеных в разных дата-центрах. При каждом входящем запросе он будет направлять запросы на все Thanos Sidecar. Если соединение прервется, то вы получите либо не полный набор данных, либо получите ответ «кластер не работает».

В VictoriaMetrics все немного проще. Для Single-node версии достаточно просто запустить один бинарник и все работает.

В кластерной на версии достаточно запустить все вышеупомянутые три типа компонентов в любом необходимом вам количестве, либо использовать helm chart для автоматизации запуска компонентов в Kubernetes. Мы еще планируем сделать Kubernetes оператор. Helm chart не покрывает некоторые кейсы, и позволяет вам выстрелить ногу. Например, он позволяет уменьшить количество storage node, что приведет к потере данных.

После того, как вы запустили один бинарник либо кластерную версию, вам достаточно добавить в конфиг Prometheus настройку для remote write url, чтобы он начал записывать даннык параллельно в локальный storage и в remote storage. Как вы заметили, такая конфигурация должна работать намного надежнее по сравнению с конфигурацией Thanos. Нам не нужно держать подключение от VictoriaMetrics ко всем Prometheus’ам, потому что Prometheus’ы сами подключаются к VictoriaMetrics и передают данные.

Рассмотрим сопровождение Thanos и VictoriaMetrics.

У Thanos нужно следить за Sidecar, чтобы они не прекращали загрузку данных в Object Storage. Они могут прекратить эту загрузку данных вследствие ошибок загрузки, например у вас временно прервалась сетевое соединение с Object Storage, либо Object Storage временно стал недоступен. Thanos Sidecar в этот момент заметит это, сообщит об ошибке, может свалиться и после этого перестать работать. Если вы не будете его мониторить, то у вас перестанут передаваться данные в Object Storage. Если пройдет время retention (6–8 часов рекомендованное), то вы будете терять данные, которые не попали в Object Storage.

Thanos сompactor-ы могут перестать работать из-за race’ов (1890) с Sidecar. Сompactor-ы берут данные с Object Storage и сливают их в более крупные куски данных. Так как сompactor-ы не синхронизированы с Sidecar’ами, то может произойти вот что: Sidecar не успел еще дописать блок, Compactor решает, что этот блок полностью записан. Compactor начинает его считывать. Он считывает блок не в полном виде и перестает работать.

Store Gateway может отдавать неконсистентные данные из-за race’ов между Compactor’ом и Sidecar’ами. Тут такая же штука, потому что Store Gateway никак не синхронизирован с Compactor’ами и Sidecar’ами. Соответственно, могут возникать состояние гонок, когда Store Gateway не видит часть данных, либо видит лишние данные.

Query компонент в Thanos по умолчанию отдает частичный результат, если некоторые Sidecar-ы либо Store Gateway не доступны в данный момент. Вы получите часть данных, и даже не будет знать, что получили не все данные. Это он работает так по умолчанию. В похожей ситуации VictoriaMetrics возвращает помеченные данные как частичные.

В отличие от Thanos, VictoriaMetrics редко теряет данные. Даже если прервалось подключение от Prometheus к VictoriaMetrics, то не проблема, так как Prometheus продолжается записывать поступающие новые данные в Write Ahead Log, размер которого равен 2 часам. Если вы в течении двух часов восстановите подключение к VictoriaMetrics, то данные не потеряются. Prometheus умеет дописывать данные после восстановления подключения к VictoriaMetrics.

В отличие от Thanos, который записывает данные в object storage только спустя два часа, Prometheus автоматически реплицирует данные по remote write протоколу в remote storage, такой как VictoriaMetrics. Вам не страшна потеря local storage в Prometheus. Если он вдруг потерял local storage, то вы худшем случае потеряете последние секунды данных, которые не успели записаться в remote storage.

Kubernetes автоматически управляет кластером в отличие от Thanos. Все компоненты Thanos сложно поместить в один Kubernetes кластер, в отличие от кластерных компонент VictoriaMetrics.

У VictoriaMetrics очень простое обновление на новую версию. Просто останавливаете VictoriaMetrics, обновляете бинарники и запускаете. При остановке через SIGINT сигнал все бинарники VictoriaMetrics делают gracefull shutdown. Они правильно сохраняют нужные данные, правильно закрывают входящие соединения, чтобы ничего не потерять. Поэтому вы ничего не потеряете при обновлении.

У VictoriaMetrics очень просто расширять кластер. Просто добавляете необходимые компоненты и продолжаете работать.

Про подводные камни в Thanos и VictoriaMetrics.

У Thanos следующие подводные камни. Prometheus должен хранить данные за последние два часа. Если они потеряются, вы их полностью потеряете, так как они еще не успели записаться в Object Storage, такой как S3.

Store Gateway компонент и сompactor компонент может требовать много памяти для работы с большим Object Storage, если там хранится много мелких файлов. Чем больше количество и объем файлов, тем больше требуется оперативной памяти Store Gateway и сompactor для хранения метаинформации. У Thanos много issues по поводу того, что Store Gateway и сompactor падают при средних объемов записанных данных.

Thanos рекламируется, что он может скейлиться бесконечно на количество ваших Prometheus. На самом деле это неправда. Так как все запросы идут через Query компонент, который должен параллельно опросить все Store Gateway компоненты и все Sidecar компоненты, вытянуть оттуда данные и потом их препроцессить. Очевидно что скорость запросов ограничена самым медленным слабым звеном, самым медленным Store Gateway либо самым медленным Sidecar.
Эти компоненты могут быть неравномерно нагружены. Например, у вас есть Prometheus, который собирает миллионы метрик в секунду. И есть Prometheus, в котором собирается тысячи метрик в секунду. Prometheus, в котором собираются миллионы метрик в секунду, намного сильнее загружает сервер, на котором он работает. Соответственно Sidecar там работает медленнее. И вообще все там медленно работает. И Query компонент будет очень медленно оттуда данные вытягивать. Соответственно производительность вашего всего кластера будет ограничена этим медленным Sidecar.

По умолчанию Thanos отдает частичное данные, если некоторые Sidecar’ы и либо Store Gateway недоступны. Например, если у вас Sidecar’ы раскиданы по всему миру в разных дата-центрах, то вероятность разрыва соединения и недоступности компонентов сильно возрастает. Соответственно, в большинстве случаев вы будете получать частичные данные, даже не зная об этом.

У VictoriaMetrics тоже есть подводные камни. Первый подводный камень — это опция, которая ограничивает объём оперативной памяти, используемой под кеш VictoriaMetrics. По умолчанию она равна 60% оперативной памяти на машине, где VictoriaMetrics запущена либо 60% ОЗУ пода VictoriaMetrics в Kubernetes.
Если неправильно поменять это значение, то можно угробить производительность VictoriaMetrics. Например, если установить слишком низкое значение, то данные могут перестать помещаться в кеш VictoriaMetrics. Из-за это ей придется делать лишнюю работу и нагружать процессор с диском. Если вы сделаете эту опцию слишком большой, то это повышает, во-первых, вероятность того, что VictoriaMetrics будет вылетать с ошибкой out of memory, и, во-вторых, это будет приводить к тому, что в операционной системе будет оставаться очень мало оперативной памяти для файлового кэша. А VictoriaMetrics очень сильно полагается на файлового кэша для производительности. Если его недостаточно, то может сильно увеличиться нагрузка на диск. Поэтому совет: не менять параметр без крайней необходимости.
Вторая опция. Это retentionPeriod — период, который по умолчанию выставлен в 1 месяц. Это время, в течение которого VictoriaMetrics хранит данные. По истечении этого срока VictoriaMetrics данные удаляет.
Многие запускают VictoriaMetrics без этого параметра, записывают данные в течение месяца. А потом спрашивают: почему данные пропали за предыдущий месяц? Потому что retentionPeriod по умолчанию равен 1 месяц. Поэтому нужно знать и устанавливать правильный retentionPeriod.

Пройдемся по уникальных возможностям.

У Thanos есть такая фича, как downsampling: 5-минутные и часовые интервалы, которые зачастую неправильно работают. Если погуглить и посмотреть их issue на github, там очень много issues, связанных с этим downsampling, что он иногда неправильно работает, либо работает не так, как ожидают пользователи.

У Thanos есть дедупликация данных для Prometheus HA pairs. Когда два Prometheus’а собирают одни и те же метрики с одних и тех же target’в и Thanos их складывает в Object Storage. Thanos умеет правильно дедуплицировать эти данные, в отличие от VictoriaMetrics.

У Thanos есть alert компонент, который был на схеме Thanos. Но его не рекомендуется использовать в production.

У Thanos преимущество, что код у Thanos и у Prometheus — общий. Thanos и Prometheus разработан одними и теми же разработчиками. При улучшениях в Thanos либо Prometheus выигрывает другая сторона.

У VictoriaMetrics главная фича это — MetricsQL. Это расширенния VictoriaMetrics для PromQL, про которые я рассказывал на предыдущем big monitoring metup.

VictoriaMetrics поддерживает заливку данных по множеству разных протоколов. VictoriaMetrics не только может принимать данные от Prometheus, но и по протоколам Influx, OpenTSDB и Graphite.

Данные VictoriaMetrics занимают обычные намного меньше места по сравнению с Thanos и Prometheus.
Если записывать реальные данные, то пользователи говорят о 2–5 кратном уменьшение размера данных на диске по сравнению с Prometheus и Thanos.

Еще одно преимущество VictoriaMetrics — она оптимизирована под скорость.

Пройдемся по стоимости инфраструктуры.

Одно из преимуществ Thanos в том, что он сохраняет данные в object storage, который сравнительно дешевый.
При сохранении данных в object storage, вы должны оплачивать операции запись и чтения данных ($10 за миллион операций). Когда вы записываете данные в object storage, вы оплачиваете расходы вашего хостинга на загрузку данных в интернет, если ваш кластер находится не в AWS — там бесплатно. Когда вы считываете данные, вы оплачиваете от $10 до $230 за 1ТБ. Это может быть существенно, если вы часто запрашиваете исторические данные из Thanos кластера.

Для Thanos кластера нужно оплачивать сервера для Compact, Store Gateway, Query компонентов, которые требует много памяти, ЦПУ для больших объемов данных.

У VictoriaMetrics расходы такие. Если хранить данные на GCE HDD дисках, то выходит $40 за 1ТБ. Для VictoriaMetrics достаточно обычных HDD дисков, не нужны никакие SSD, которые стоят раз в пять дороже. VictoriaMetrics оптимизирована под HDD.

Для VictoriaMetrics нужны сервера для компонентов: либо Single-nod либо для кластерных компонентов, которые в отличие от Thanos компонентов, требует намного меньше ЦПУ, ОЗУ — соответственно будет дешевле.

Примеры внедрения.

У Thanos пример внедрения — это Gitlab. Gitlab полностью работает на Thanos. Но там не все так гладко. Если посмотреть по их issues, то можно увидеть что у них постоянно возникают какие-то операционные проблемы с Thanos: не хватает памяти для Store Gateway либо Query компонентов. Им постоянно приходится увеличивать объем памяти.
Из-за этого увеличиваются расходы на решение этих проблем.
Второе внедрение, которое может быть более успешное — это компания Improbable, которые начали разработку Thanos. Они опубликовали исходники Thanos. Improbable — компания, которая занимается разработкой игровых движков.

У VictoriaMetrics публичные примеры внедрения это:
- wix.com конструктор сайтов
- Adidas внедряет VictoriaMetrics и даже сделал доклад на последнем PromCon 2019
- TrafficStars — ad network
- Seznam.cz — популярный чешский поисковик.
А дальше пошли ноунейм компании, которые я не могу назвать сейчас. Они не дали согласие.
- Один крупный разработчик игр. Крупнее, чем им Improbable.
- Крупный разработчик графического ПО.
- Крупный российский банк.
- Европейский производитель ветряных турбин, который успешно протестировал VictoriaMetrics. Этот производитель внедряет VictoriaMetrics для мониторинга данных, полученных с ветряных турбин со скоростью 50 сэмплов в секунду на каждый датчик. В каждой ветряной турбине по несколько сотен датчиков. У них несколько сотен ветряных турбин.
- Российские авиалинии, которые хотят внедрить VictoriaMetrics, но все никак не могут. Мы с ними на стадии договора.
 Выводы.
Выводы.
VictoriaMetrics и Thanos решают похожие задачи, но разными способами:
- Global query view
- горизонтальное масштабирование
- произвольный retention

Спасибо.

