Выявление незаконных построек по спутниковым снимкам с помощью CV
Привет, Хабр! Я Вова, Lead Data Scientist. Заметил, что вам очень нравится вместе с нами разбирать решения задач с хакатонов. Сегодня расскажу, как я занял 4 место в соревновании по выявлению незаконных построек по спутниковым снимкам и что мне не хватило, чтобы попасть в топ-3 на Цифровом прорыве.
Информация о задаче, проблема
С каждым годом спрос на снимки со спутников для Дистанционного Зондирования Земли (ДЗЗ) увеличивается. В результате количество получаемых снимков с поверхности Земли растет. Последующая обработка полученной спутниковой информации усложняется из-за многократного увеличения получаемых данных. Сейчас подобная работа занимает несколько десятков или сотен часов труда специалистов по дешифровке. Чтобы повысить качество и скорость обработки космических данных, требуется создание специально обученных сверхточных нейросетей, способных осуществлять разметку данных и в автоматическом режиме проводить поиск и отметку значимой для пользователя информации. Подобная система, например, способна в автоматическом режиме провести обработку спутниковых данных с территории заповедника и идентифицировать незаконную постройку. Создание подобного сервиса на основе сверхточных нейросетей должна помочь в работе с космическими данными, увеличив качество аналитики и сократив время работы специалистов.
Цель задачи — разработать модель машинного обучения для подсчета зданий на изображении. Обязательное условие: на снимке присутствует хотя бы одна постройка.
Исходные данные и метрика качества
Размер каждого изображения составляет 300×300 пикселя.
Данные представляют из себя две папки и два csv-файла, а именно:
● train/ — папка, содержащая 2100 фотографий тренировочного набора;
● test/ — папка, содержащая 900 фотографий для тестирования;
● train.csv — содержит в себе 2 столбца:
Решения оценивались по коэффициенту детерминации, который принимает значения от 0 до 1. Чем выше значение метрики, тем больше статистическая взаимосвязь между предсказанными и фактическими значениями.
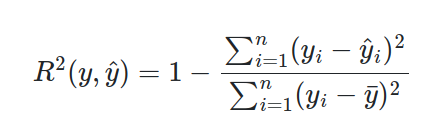
Посмотрев на данные, я разделил все снимки на 3 группы
Небольшие дома частного сектора

Парковки с небольшими служебными помещениями

Промышленная или коммерческая недвижимость

По итогу изучения данных я отметил пальмы, большое количество бассейнов в частном секторе и характерные тупики, и пришел к выводу, что снимки были сделаны не в России.
 Где-то я уже видел это место…
Где-то я уже видел это место… Это же Сан-Андреас!
Это же Сан-Андреас!
Первоначальный план
Организаторы соревнования подготовили базовое решение с обучением сверточной нейронной сети на решение задачи регрессии, но я сразу решил не использовать такой подход. На похожих задачах по подсчету моржей и тюленей со спутниковых снимках побеждали решения, которые находят каждого животного по отдельности и затем делают их подсчет. Я решил пойти таким же путем. Мой первоначальный план был такой — разметить около 100 фотографий в LabelStudio, затем обучить модель на object detection или instance segmentation и затем проверить жизнеспособность моего плана
Я запустил LabelStudio через docker простой командой и разметил несколько фото.
docker pull heartexlabs/label-studio:latest
docker run -it -p 8080:8080 -v $(pwd)/mydata:/label-studio/data heartexlabs/label-studio:latest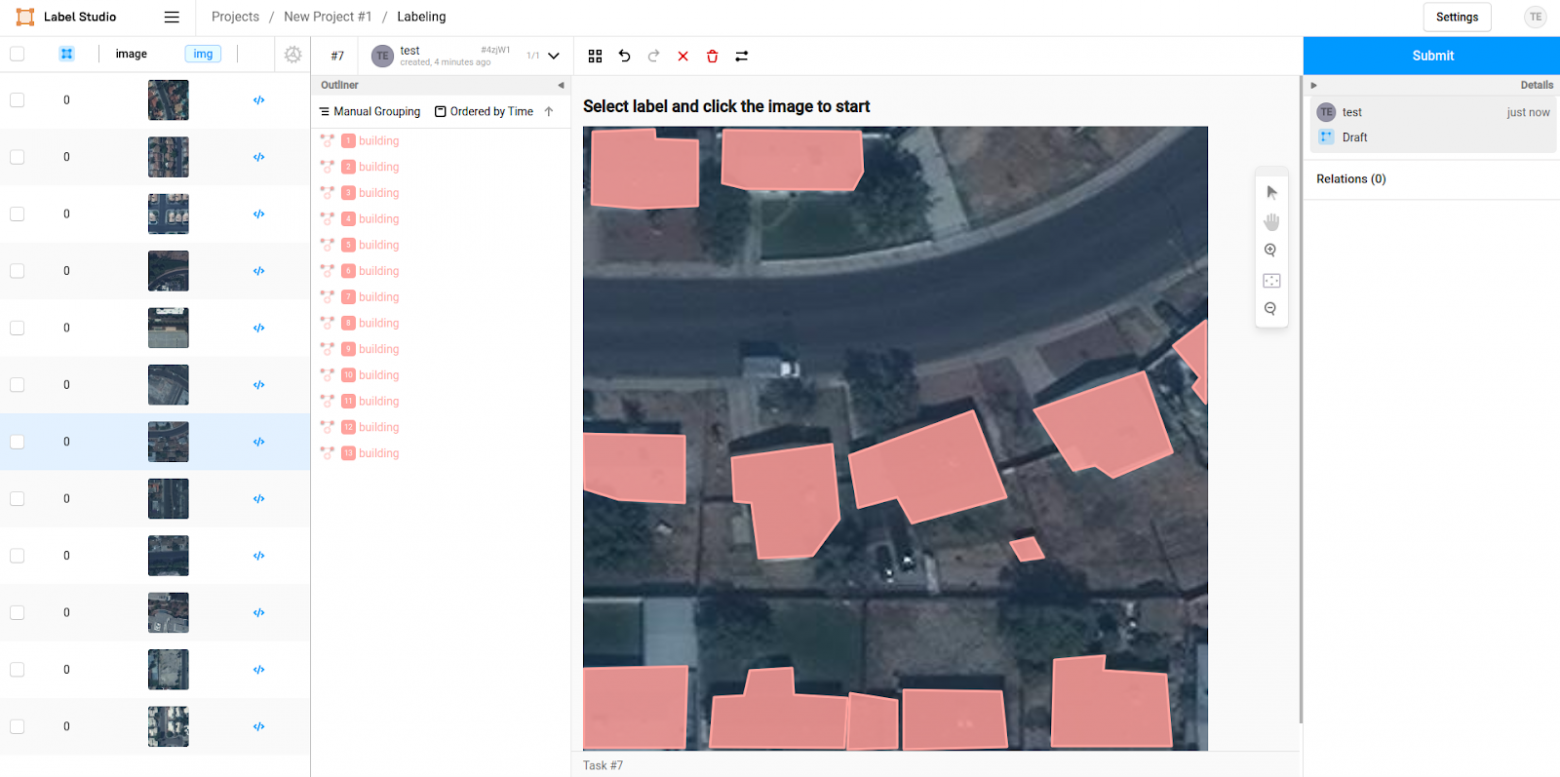
Но столкнулся с одной проблемой — количество домой, который разметил я, не сходилось с тем, что указано в представленных данных. Например, на фотографии выше я разметил 13 зданий, а в метаданных отмечено 17. Стало понятно, что на глаз не могу отделить небольшие строения вроде сторожевых будок или сараев от просто случайных однотонных пятен на фото, и поэтому моя разметка расходилась от данных организаторов на плюс-минус 3–5 домов.
И тут в чате соревнования всплыли данные с разметкой на instance segmentation, из которых организаторы собрали свой датасет. И я перестал размечать данные и взял новые данные для обучения.
Используемые данные
Как оказалось, данные от организатор являются частью данных из соревнования Mapping Challenge на AICrowd. Эти данные размечены под задачу Instance Segmentation в формате COCO, т.е. семантическая маска каждого дома выделена как отдельный объект. Датасет содержит 280 тысяч таких снимков, из которых я убрал снимки из тестовой части соревнования.

Используемый подход
Я взял модель архитектуры DetectoRS, у которой есть вариации для Object Detection и Instance Segmentation, потому что решил использовать информацию не только о координатах, но и конкретных масках домов. Также из своего опыта знаю, что для дообучения такой сети нужно не очень большое количество эпох. И еще одним плюсом было то, что фреймворк MMDetection, на котором я обучал модель, из коробки работает с форматом COCO.
Эта архитектура является продолжением идей двухстадийных детекторов таких, как FasterRCNN и MaskRCNN и у неё есть две особенности.
Recursive Feature Pyramid — осуществляется несколько проходов по пирамиде признаков и на каждом проходе учитываются извлеченные признаки из прошлой итерации.
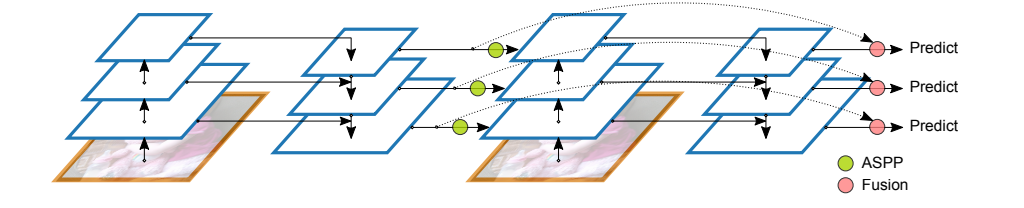
Switchable Atrous Convolution — один и тот же сверточный модуль запускают с разным расстоянием между пикселями, тем самым позволяя учитывать взаимосвязь пикселей на разном расстоянии относительно изображения.
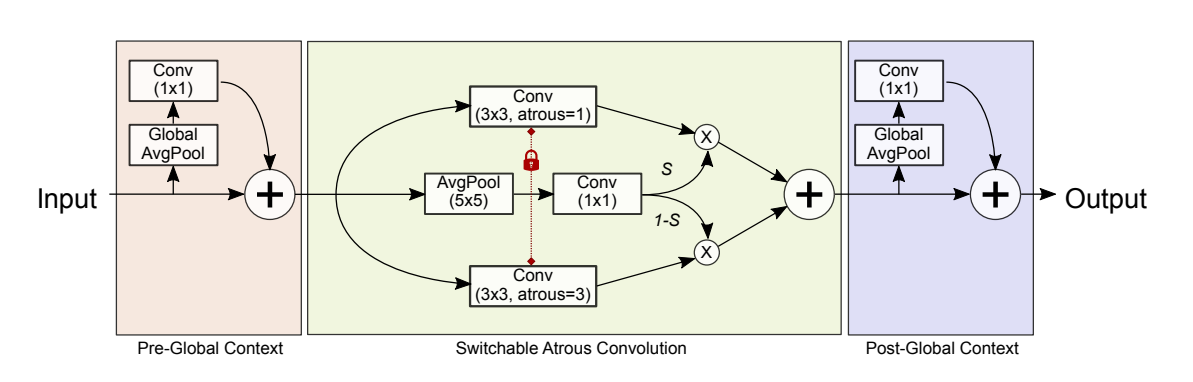
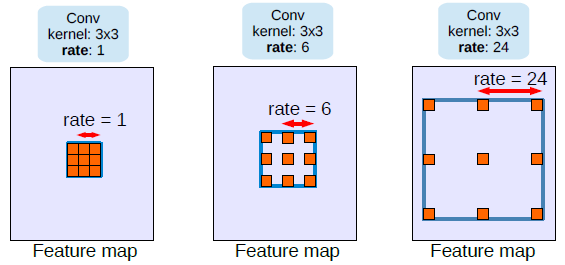
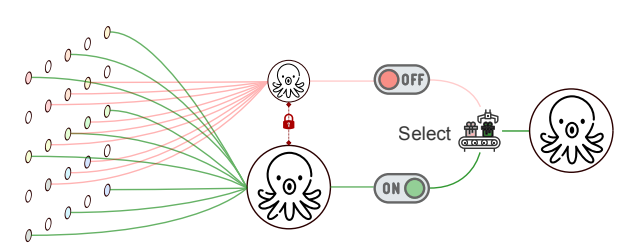
Для начала я ограничил датасет 10 тысячами изображений и использовал версию модели для Object Detection. Так, столкнулся с первой проблемой — модель на локальной валидации выдавала низкие метрики. Я начал изучать разметку и понял, что формат координат детекционной рамки отличается от общепринятого. Потратив несколько дней, пытаясь понять как правильно использовать эти метаданные, пришел к выводу — разметка детекционной рамки сама по себе кривая и её не стоит использовать. Я пересобрал эту разметку из координат точек сегментационных масок.
def change_anno(i):
i['category_id'] = 1
i['bbox'] = [min(i['segmentation'][0][0::2]),
min(i['segmentation'][0][1::2]),
max(i['segmentation'][0][0::2]) - min(i['segmentation'][0][0::2]),
max(i['segmentation'][0][1::2]) - min(i['segmentation'][0][1::2])]
return iМодель теперь стала обучаться. Так я получил значение метрики 0.75.
Затем решил перейти к обучении модели на задаче Instance Segmetation. Для такой модели требуется дополнительная информация в виде semantic segmentation масок, т. е. изображения со значением 1 там, где находятся здания и 0 где зданий нет. Эти маски я также сформировал с помощью координат точек сегментационных масок каждого здания, используя следующие функции.
def make_mask(img):
mask = np.zeros((300, 300), np.uint8)
for an in train['annotations']:
if an['image_id'] != img['id']:
continue
seg = an['segmentation']
rr, cc = polygon(seg[0][1::2], seg[0][::2])
mask[np.clip(rr, 0, 299), np.clip(cc, 0, 299)] = 1
cv2.imwrite(f'/data/train/masks/{img["file_name"].replace("jpg", "png")}', mask)
На этой версии модели я получил значение метрики 0.8.
Дальше я уже обучал на всех данных и использовал Test Time Augmentation для улучшения значения метрики.
Test Time Augmentation — подход применения аугментации на этапе предсказания модели. Я использовал три аугментации, не ухудшающие исходное изображение и их комбинации. Таким образом, у меня получалось 8 вариаций исходного изображения, для которых я делал предсказания и затем усреднял их. Для получения аугментированных изображений использовал следующую функцию.
def tta(image, vertical_flip=False, horizontal_flip=False, rotate=False):
if vertical_flip:
image = cv2.flip(image, 0)
if horizontal_flip:
image = cv2.flip(image, 1)
if rotate:
image = np.rot90(image)
return image
Обучение на всех данных занимало больше суток и соревнование уже подходило к концу, поэтому я успел обучить модель только одну эпоху. Финальное значение метрики получилось 0.92.
Итог
Если бы я выстроил тайм менеджмент более грамотно и изначально потратил бы больше времени на изучение разметки данных, не смешивая её с обучением, я бы успел обучить итоговую модель большее число эпох и получил бы метрики выше. Не забывайте заранее проверять, что ваши данные соответствуют тому, что ожидаете вы и ваша модель.
По ссылкам можно ознакомиться с кодом и презентацией моего решения:
https://github.com/Vlako/satellite-building-counting
Выявление незаконных построек по спутниковым снимкам. Владимир Фоменко
Решение оформлено через docker compose, где каждый шаг вынесен в отдельный сервис. Для его запуска нужно выполнить всего лишь несколько шагов:
Скачать данные соревнования в папку data и разархивировать их.
Скачать train.tar.gz из этого соревнования https://www.aicrowd.com/challenges/mapping-challenge.
Запустить скрипт подготовки данных
docker compose up --build data_creation.Запустить обучение
docker compose up --build trainили загрузить модель в папку model по ссылке.Для предсказания на тестовых данных запустить
docker compose up --build inference.Для визуализации детекции на тестовых данных можно запустить
docker compose up --build draw_detections.
