Введение в RapidMiner
 На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner. RapidMiner (далее просто «майнер») — инструмент созданный для дата майнинга, с основной идеей, что майнер (аналитик) не должен программировать при выполнении своей работы. При этом как известно, для майнинга нужны данные, по этому его снабдили достаточно хорошим набором операторов решающих большой спектр задач получения и обработки информации из разнообразных источников (базы данных, файлы и т.п.), и можно с уверенностью говорить, что это ещё и полноценный инструмент для ETL.
На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner. RapidMiner (далее просто «майнер») — инструмент созданный для дата майнинга, с основной идеей, что майнер (аналитик) не должен программировать при выполнении своей работы. При этом как известно, для майнинга нужны данные, по этому его снабдили достаточно хорошим набором операторов решающих большой спектр задач получения и обработки информации из разнообразных источников (базы данных, файлы и т.п.), и можно с уверенностью говорить, что это ещё и полноценный инструмент для ETL.
Помимо самого майнера есть ещё и сервер RapidMiner Server (ранее назывался RapidAnalytics, до версии 6) который может использоваться как репозиторий для хранения и выполнения процессов майнера (в том числе по расписанию), «шарить» соединения к источникам данных между пользователями, отдавать данные из процессов майнера как веб-сервис.
К нашему с вами сожалению, с 6 версии создатели майнера решили начать зарабатывать денежку на продажах этого ПО и сменили лицензию с AGPL на Business Source. Тем не менее 5 версия AGPL и мы можем её использовать свободно и без ограничений. По этому в статье будет рассмотрена именно она. Также отметим, что в шестой версии не так много новых операторов и функций (пожалуй самое интересно это поддержка облака), и для большинства задач хватит RapidMiner 5 Community.
Не так давно c официального сайта ссылки на скачивание RapidMiner 5 были удалены, по этому соберем RM из исходного кода который возьмем в официальном проекте на гитхабе.
Для сборки RapidMiner'a из репозитория нам понадобится
 Зайдем в консоль, перейдем в каталог куда хотели бы поставить майнер, клонируем репозиторий
Зайдем в консоль, перейдем в каталог куда хотели бы поставить майнер, клонируем репозиторий
git clone https://github.com/rapidminer/rapidminer-5.git
следующий шаг соберем проект
ant build
ant release.makePlatformIndependent
теперь запустим майнер
.\scripts\RapidMinerGUI.bat
для линукса соответственно
./scripts/RapidMinerGUI.sh
Перед вам откроется окно как на картинке справа. Нажимаем на New Process и идем дальше.
Перед тем как на примере посмотреть основные принципы работы с RapidMiner сделаем небольшое введение в его основные понятия.
Процесс
Совокупность операторов соединенных между собой в заданном порядке для выполнения требуемой задачи анализа/обработки данных.
Оператор
 Логическая единица процесса. Оператор производит какие то действия над данными, у него есть вход-выход (так называемые «порты»), на вход приходят данные, на выход идут обработанные оператором данные. Таким образом мы можем делать цепочки обработки данных, к примеру — считать транзакции клиентов из БД, найти самые большие, сконвертировать в доллары и выдать результат. При этом можно цепочки параллелить — к примеру в одной мы читаем транзакции из разных БД, а в другой ищем данные клиентов, потом объединяем и получаем результат (при этом также возможно их параллельное исполнение во времени!).
Логическая единица процесса. Оператор производит какие то действия над данными, у него есть вход-выход (так называемые «порты»), на вход приходят данные, на выход идут обработанные оператором данные. Таким образом мы можем делать цепочки обработки данных, к примеру — считать транзакции клиентов из БД, найти самые большие, сконвертировать в доллары и выдать результат. При этом можно цепочки параллелить — к примеру в одной мы читаем транзакции из разных БД, а в другой ищем данные клиентов, потом объединяем и получаем результат (при этом также возможно их параллельное исполнение во времени!).
В интерфейсе программы операторам соответствует вкладка Operators — где в иерархии они сгруппированы по функциональному признаку. Чтобы воспользоваться оператором необходимо нажать на него и перенести в рабочую область процесса.
Репозиторий
 Место для хранения процессов RM. Может быть локальным, а также удаленным (RapidMiner Server), для которого возможно исполнять процессы на стороне сервера, многопользовательский доступ к процессам/соединениям БД, запуск процессов по расписанию или отдача данных как веб-сервис.
Место для хранения процессов RM. Может быть локальным, а также удаленным (RapidMiner Server), для которого возможно исполнять процессы на стороне сервера, многопользовательский доступ к процессам/соединениям БД, запуск процессов по расписанию или отдача данных как веб-сервис.
Во вкладе Repositories в RM тут можно увидеть только Samples, DB и Local Repository. Первое как уже понятно из название набор процессов — примеров, DB — текущие соединения к базам данных доступных в майнере (определяются через Tools -> Manage Database Connections) и Local Repository, место для хранения собственных процессов на компьютере.
Контекст процесса
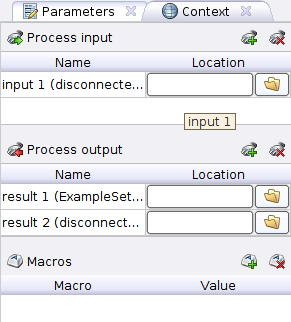 Контексту соответствует вкладка Context где мы можем увидеть три секции:
Контексту соответствует вкладка Context где мы можем увидеть три секции:
- Process input — данные передающиеся на вход процесса. Тут можно указать путь к данными внутри репозитория.
- Process output — тут указывается путь в репозитории, куда будет сохранен результат работы процесса.
- Macros — это глобальная переменная доступная в процессе из любого места. Может принимать в качестве значения только строки или числа.
Отметим, что Process input и Process output обозначены в процессе кружками по границе процесса с надписями inp и res. Чтобы воспользоваться данными из входа или сохранить их нужно соединить соответствующий кружок с входом/выходом операторов.
Самое лучшее обучение — практика. Сделаем небольшой процесс на основе которого увидим основные принципы работы с майнером.
Небольшая задачка
Вы директор небольшой компании, которая занимается созданием сайтов, промышленным дизайном и т.д. Достаточно часто, ввиду большого количества заказов и недостатка сотрудников вы нанимаете фрилансеров из разных стран (т.к. клиенты со всего мира) и исправно вносите информацию о выполненных работах в эксель табличку указывая имя исполнителя, род работы, дату оплаты, сумму и валюту оплаты. В какой то момент вам захотелось получить сумму затрат, в рублях (на курс ЦБ), которую вы понесли в разбивке по видам работ на конкретную дату (более интересные случаи — разбивка по месяцам, сотрудникам остаются на собственные эксперименты).
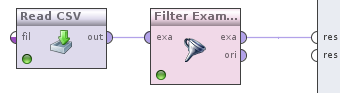
 Первое, что мы сделаем, это сохраним наш эксель файлик в формате CSV и откроем его на чтение в RapidMiner'e. Для этого, возьмем оператор Read CSV (Import -> Data -> Read CSV) и перетянем его в рабочую область процесса. Далее нажимаем на него и видим справа настройки оператора. Нажмём на значок открытой папочки
Первое, что мы сделаем, это сохраним наш эксель файлик в формате CSV и откроем его на чтение в RapidMiner'e. Для этого, возьмем оператор Read CSV (Import -> Data -> Read CSV) и перетянем его в рабочую область процесса. Далее нажимаем на него и видим справа настройки оператора. Нажмём на значок открытой папочки  , в диалоговом окне выбираем требуемый нам файл (используемый CSV в примере можно скачать по ссылке)
, в диалоговом окне выбираем требуемый нам файл (используемый CSV в примере можно скачать по ссылке)
Обратим внимание на нажатую кнопку  — режим эксперта. В нём доступны дополнительные параметры для операторов, как правило нужные почти всегда и помечаемые курсивом.
— режим эксперта. В нём доступны дополнительные параметры для операторов, как правило нужные почти всегда и помечаемые курсивом.
Выставляем параметры как на картинке справа и жмем на Edit list справа от data set meta data information снизу. Выставляем все как на картинке ниже
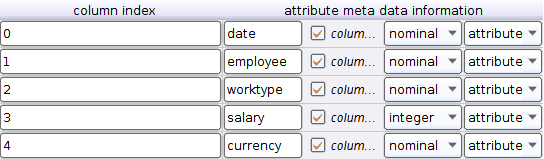
Как можно догадаться тут мы выставляем названия колонок, галочка ставится, чтобы исключить или включить колонку из результата парсинга, тип и роль. Роли отличные от attribute могут понадобиться в майнинге, в обычном же случае они как правило не требуются.
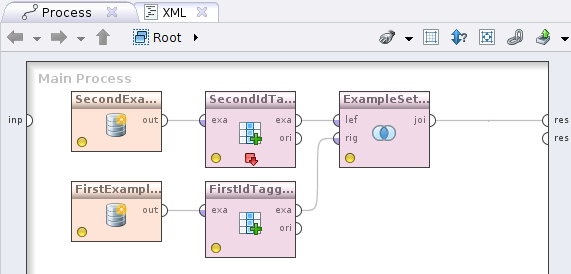
Нажимаем Apply и переходим к следующему шагу. Добавим оператор Filter examples (Data Transformation -> Filtering), его вход соединим с выходом Read CSV, а выход с выходом процесса обозначенным кружочком и надписью res. У вас получится такая картина
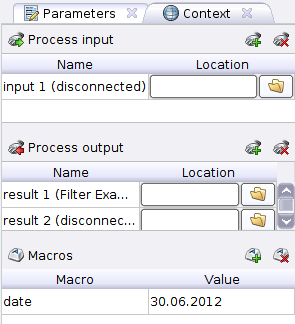 С помощью добавленного оператора мы выберем записи только на указанную дату которую объявим как макрос процесса. Идем на вкладку Context процесса, там находим секцию Macros и нажимаем на
С помощью добавленного оператора мы выберем записи только на указанную дату которую объявим как макрос процесса. Идем на вкладку Context процесса, там находим секцию Macros и нажимаем на  . В колонке Macro пишем date, а в Value желаемую дату, пусть это будет 30.06.2012.
. В колонке Macro пишем date, а в Value желаемую дату, пусть это будет 30.06.2012.
Так вкладка Context на данном шаге у вас будет выглядеть как на картинке справа. Макрос (напомню, т.е. глобальную переменную) мы определили и теперь воспользуемся им для фильтра записей по дате из нашего CSVшничка. Жмем на оператор Filter Examples выбираем в condition class attribute_value_filter и в parameter string пишем: date = %{date}. Слева мы указали название колонки по которой происходит фильтрация, по центру операция проверки на равенство и справа взятие значения из макроса.
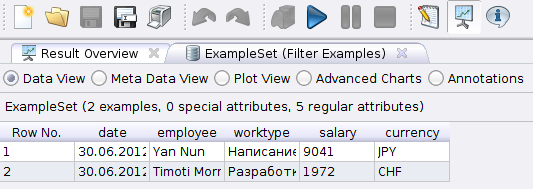
Посмотрим, что получилось. Жмём на кнопочку запуска процесса  и майнер переключившись на Result perspective (если этого не произошло нажмите на
и майнер переключившись на Result perspective (если этого не произошло нажмите на  ) отобразит отфильтрованные данные на 30 июля 2012 года.
) отобразит отфильтрованные данные на 30 июля 2012 года.
Первый результат получен, но нам хотелось бы видеть затраты в рублях по курсу ЦБ РФ. Переключаемся на Design Perspective нажатием на  и добавляем оператор Open file (Utility -> Files -> Open file). Нажимаем на него и выставляем следующие настройки
и добавляем оператор Open file (Utility -> Files -> Open file). Нажимаем на него и выставляем следующие настройки
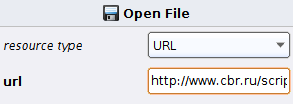
Где url: http://www.cbr.ru/scripts/XML_daily.asp?date_req=%{date}
Обратим внимание, что мы подставили макрос в параметр оператора.
Получить данные мы получим, но что-то должно их преобразовать в ExampleSet — т.е. таблицу с данными. В первом случае эту роль выполнял Read CSV, а сейчас как не трудно догадаться мы воспользуемся Read XML (Import -> Data -> Read XML). Тянем оператор, соединяем его вход с выходом оператора Open file и делаем следующие настройки (если вы испытываете трудности с xpath воспользуйтесь мастером импорта нажав наImport configuration wizard).
 Обратите внимание, что выставлена галочка parse numbers и разделителем целой и дробной части выставлена запятая.
Обратите внимание, что выставлена галочка parse numbers и разделителем целой и дробной части выставлена запятая.
Необходимо определить какие атрибуты RapidMiner возьмет для ExampleSet. Нажимаем на Edit enumeration справа отxpath for attributes, добавляем две записи
Value[1]/text() — стоимость в рублях единицы валюты
CharCode[1]/text() — буквенный код валюты
Теперь необходимо выставить типы значений для атрибутов. Для этого нажимаем на Edit list справа от data set meta datainformation и выставляем как на картинке ниже

На данном этапе мы имеем процесс который у вас должен выглядеть так
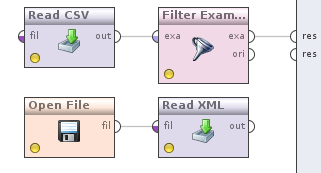
Пришло время сделать конвертацию валют в отфильтрованных по дате данным. Для этого, как можно догадаться, нам потребуется каким то образом объединить котировки и данные. В этом нам поможет оператор Join (Data Transformation -> Set Operations -> Join). Теперь делаем следующее. Берем выход оператора Filter examples, который на данный момент у нас соединен с выходом процесса и соединяем с оператором Join, делаем аналогичное с оператором Read XML.
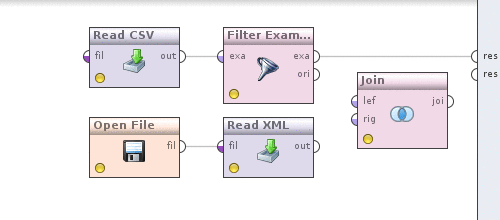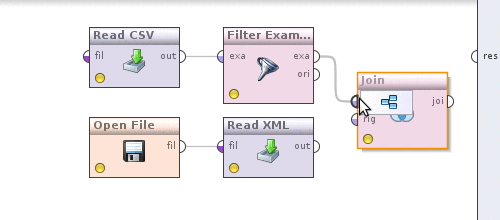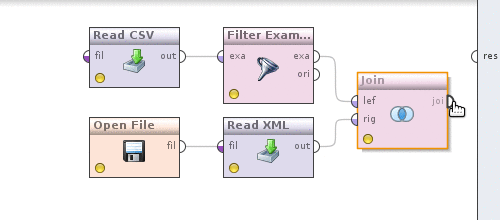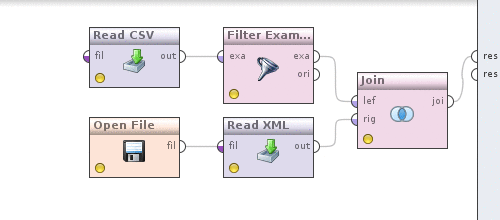
Теперь нажмем на оператор Join и определим как именно будут объединятся данные. Убираем галочку use id attribute as key, так как объединение у нас происходит по полю currency, появится новый параметр key attributes нажмем слева от него наEdit list, в диалоге Add entry и в обоих полях пропишем — currency. Сохраняем изменения. Можем посмотреть, что получилось, аналогично тому как это делалось выше нажав на кнопочку. Результат будет таким

Мы все ближе к заветной цели — узнать сколько же мы потратили в рублях на наши задачи. Остался последний штрих, собственно сама конвертация. Добавим в процесс оператор Generate Attributes (Data Transformation -> Attribute Set Reduction and Transformation -> Generation) и соединим его вход с выходом оператора Join, а первый выход около которого написано exp (сокращенно ExampleSet)к выходу процесса. Как понятно из названия оператора его задача добавить новый атрибут, для этого нажмем на оператор и справа в его настройках на Edit list, кнопка напротив function descriptions. Дадим название атрибуту и как его считать

Сохраняем изменения и выполняем процесс, наш результат

Ура! Вот она заветная цифра затрат в рублях которую мы понесли по курсу ЦБ на дату оплаты. Развить данную задачу можно очень далеко, к примеру сделать вывод информации за месяц, в группировке по типу работ, исполнителю или датам. В общем, простор фантазии.
Полезные материалы
