Введение в DPDK: архитектура и принцип работы
За последние несколько лет тема производительности сетевого стека Linux обрела особую актуальность. Это вполне понятно: объёмы передаваемых по сети данных и соответствующие нагрузки растут не по дням, а по часам.
И даже широкое распространение сетевых карт 10GE не решает проблемы: в самом ядре Linux имеется множество «узких мест», которые препятствуют быстрой обработке пакетов.
Предпринимаются многочисленные попытки эти «узкие места» обойти. Техники, используемые для обхода, так и называются — kernel bypass (с кратким обзором можно ознакомиться, например, здесь). Они позволяют полностью исключить сетевой стек Linux из процесса обработки пакетов и сделать так, чтобы приложение, работающее в пользовательском пространстве, взаимодействовало с сетевым устройством напрямую. Об одном из таких решений — Intel DPDK (Data Plane Development Kit) — мы и хотели бы поговорить в сегодняшней статье.
О DPDK существует множество публикаций, в том числе и на русском языке (см., например: 1, 2 и 3). Среди этих публикаций есть и весьма неплохие, но они не отвечают на самый главный вопрос: как именно происходит обработка пакетов с использованием DPDK? Из каких этапов состоит путь пакета от сетевого устройства к пользователю?
Именно на эти вопросы мы и попытаемся ответить. Чтобы найти ответы, нам пришлось проделать огромную работу: так как в официальной документации мы всей нужной информации не нашли, то нам пришлось ознакомиться с массой дополнительных материалов и погрузиться в изучение исходников… Впрочем, обо всём по порядку. И прежде чем говорить о DPDK и о том, какие проблемы он помогает решить, нам нужно вспомнить, как осуществляется обработка пакетов в Linux. С этого мы и начнём.
Обработка пакетов в Linux: основные этапы
Итак, когда пакет поступает на сетевую карту, он сначала попадает в специальную кольцевую структуру, — приёмную очередь (receive queue или просто RX). Оттуда он копируется в основную память с помощью механизма DMA — Direct Memory Access.
После этого требуется сообщить системе о появлении нового пакета и передать данные дальше, в специально выделенный буфер (Linux выделяет такие буферы для каждого пакета). Для этой цели в Linux используется механизм прерываний: прерывание генерируется всякий раз, когда новый пакет поступает в систему. Затем пакет ещё нужно передать в пользовательское пространство.
Одно «узкое место» уже очевидно: чем больше пакетов приходится обрабатывать, тем больше на это уходит ресурсов, что отрицательно сказывается на работе системы в целом.
Данные пакета, как уже было сказано выше, хранятся в специально выделенном буфере, или, говоря точнее — в структуре sk_buff. Эта структура выделяется для каждого пакета и освобождается, когда пакет попадает в пользовательское пространство. На эту операцию расходуется очень много циклов шины (т.е. циклов, передающих данные из CPU в основную память).
Со структурой sk_buff есть ещё один проблемный момент: сетевой стек Linux изначально старались сделать так, чтобы он был совместим с как можно большим количеством протоколов. Метаданные всех этих протоколов включены и в структуру sk_buff, но для обработки конкретного пакета они могут быть просто не нужны. Из-за чрезмерной сложности структуры обработка замедляется.
Ещё одним фактором, отрицательно влияющим на производительность, является переключение контекста. Когда приложению, запущенному в пользовательском пространстве, требуется принять или отправить пакет, оно делает системный вызов, и происходит переключение контекста в режим ядра, а затем — обратно в пользовательский режим. Это сопряжено с ощутимыми затратами системных ресурсов.
Чтобы решить часть описанных выше проблем, в ядро Linux начиная с версии ядра 2.6 был добавлен так называемый NAPI (New API), в котором метод прерываний сочетается с методом опроса. Рассмотрим вкратце, как это работает.
Сначала сетевая карта работает в режиме прерываний, но как только пакет поступает на сетевой интерфейс, она регистрирует себя в poll-списке и отключает прерывания. Система периодически проверяет список на наличие новых устройств и забирает пакеты для дальнейшей обработки. Как только пакеты обработаны, карта будет удалена из списка, а прерывания включатся снова.
Мы описали процесс обработки пакетов очень бегло. С более детальным описанием можно ознакомиться, например, в цикле статей в блоге компании Private Internet Access. Однако даже краткого рассмотрения достаточно, чтобы увидеть проблемы, из-за которых скорость обработки пакетов замедляется. В следующем разделе мы опишем, как эти проблемы решаются с помощью DPDK.
DPDK: как это работает
В общих чертах
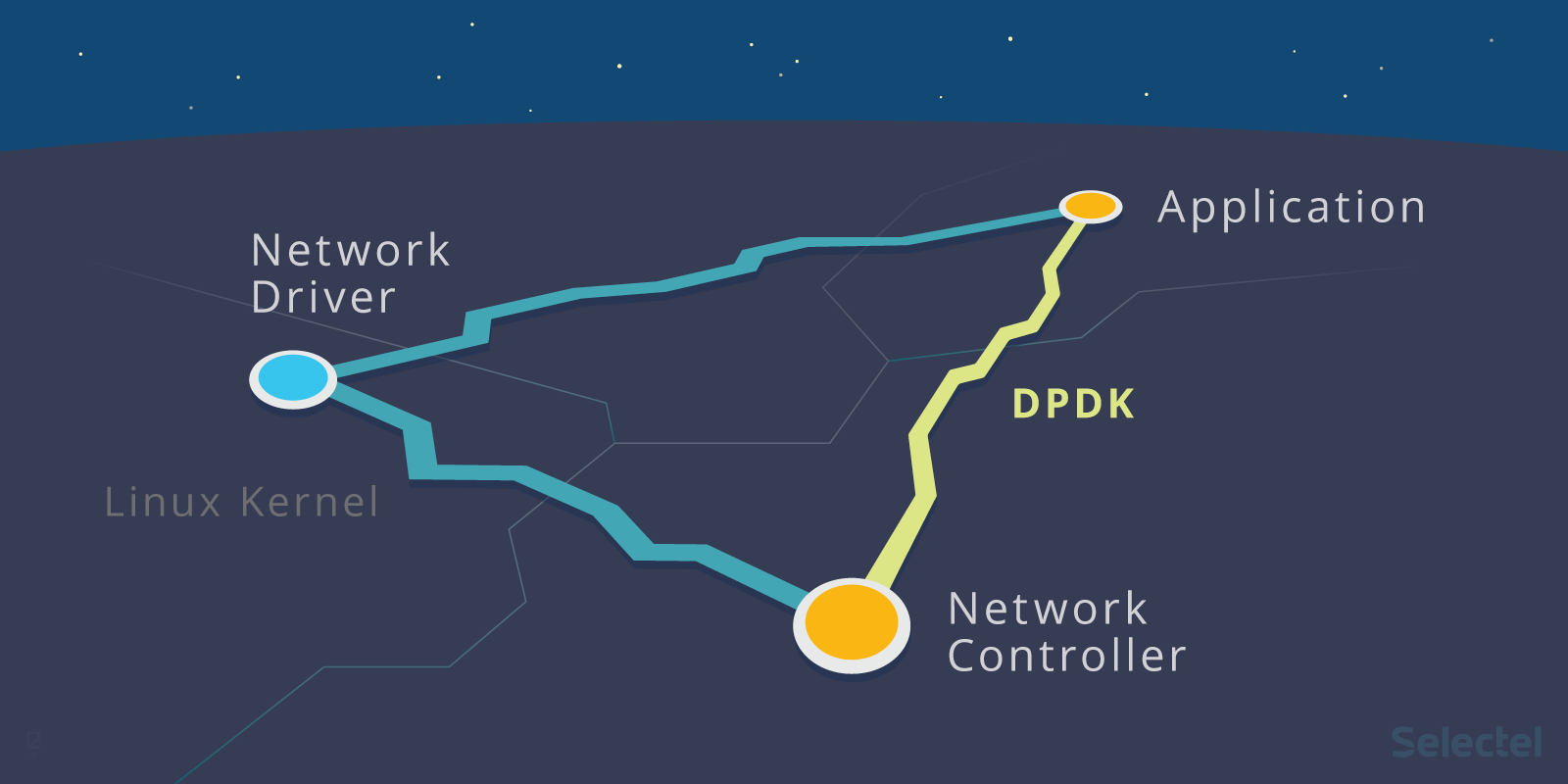
Рассмотрим следующую иллюстрацию:

Слева представлен процесс обработки пакетов «традиционным» способом, а справа — с использованием DPDK. Как видим, во втором случае ядро не задействовано вообще: взаимодействие с сетевой картой осуществляется через специализированные драйверы и библиотеки.
Если вы уже читали о DPDK или имеете хотя бы небольшой опыт работы с ним, то знаете, что порты сетевой карты, на которые будет поступать трафик, потребуется вообще вывести из-под управления Linux — это делается при помощи команды dpdk_nic_bind (или dpdk-devbind), а в более ранних версиях) — ./dpdk_nic_bind.py.
Как происходит передача портов под управление DPDK? У каждого драйвера в Linux есть так называемые bind- и unbind-файлы. Есть они и у драйвера сетевой карты:
ls /sys/bus/pci/drivers/ixgbe
bind module new_id remove_id uevent unbind
Чтобы открепить устройство от драйвера, нужно записать номер шины этого устройства в unbind-файл. Соответственно для передачи устройства под управление другого драйвера потребуется записать номер шины в его bind-файл. Более подробно об этом можно прочитать в этой статье.
В инструкциях по установке DPDK указывается, что порты нужно передать под управление драйвера vfio_pci, igb_uio или uio_pci_generic.
Все эти драйверы (подробно разбирать их особенности в рамках этой статьи мы не будем; заинтересованных читателей отсылаем к статьям на kernel.org: 1 и 2) делают возможным взаимодействие с устройствами в пользовательском пространстве. Конечно, в их состав входит и модуль ядра, но его функции сводятся к инициализации устройств и предоставлению PCI-интерфейса.
Всю дальнейшую работу по организации общения приложения с сетевой картой берёт на себя входящий в DPDK драйвер PMD (сокращение от poll mode driver).
Для работы с DPDK необходимо также настроить большие страницы памяти (hugepages). Это нужно, чтобы выделять большие регионы памяти и записывать в них данные. Можно сказать, что hugepages в DPDK выполняют ту же роль, что механизм DMA в традиционной обработке пакетов.
Все нюансы мы более подробно обсудим ниже, а пока кратко опишем основные стадии обработки пакетов с использованием DPDK:
- Поступившие пакеты попадают в кольцевой буфер (его устройство мы разберём в следующем разделе). Приложение периодически проверяет этот буфер на наличие новых пакетов.
- Если в буфере имеются новые дескрипторы пакетов, приложение обращается к буферам пакетов DPDK, находящимся в специально выделенном пуле памяти, через указатели в дескрипторах пакетов.
- Если в кольцевом буфере нет никаких пакетов, то приложение опрашивает находящиеся под управлением DPDK сетевые устройства, а затем снова обращается к кольцу.
Рассмотрим внутреннее устройство DPDK более детально.
EAL: абстракция окружения
EAL (Environment Abstraction Layer, уровень абстракции окружения) — это центральное понятие DPDK.
EAL — это набор программных инструментов, которые обеспечивают работу DPDK в конкретном аппаратном окружении и под управлением конкретной операционной системы. В официальном репозитории DPDK библиотеки и драйверы, входящие в состав EAL, хранятся в директории rte_eal.
В этой директории хранятся драйверы и библиотеки для Linux и BSD-систем. Имеются также наборы заголовочных файлов для различных процессорных архитектур: ARM, x86, TILE64, PPC64.
К программам, входящим в EAL, мы обращаемся при сборке DPDK из исходного кода:
make config T=x86_64-native-linuxapp-gcc
В этой команде, как не трудно догадаться, мы указываем, что DPDK нужно собрать для архитектуры x86_84, OC Linux.
Именно EAL обеспечивает «привязку» DPDK к приложениям. Все приложения, использующие DPDK (см. примеры здесь), обязательно включают входящие в состав EAL заголовочные файлы.
Перечислим наиболее употребительные из них:
- rte_lcore.h — функции управления процессорными ядрами и сокетами;
- rte_memory.h — функции управления памятью;
- rte_pci.h — функции, обеспечивающие интерфейс доступа к адресному пространству PCI;
- rte_debug.h — функции трассировки и отладки (логгирование, dump_stack и другие);
- rte_interrupts.h — функции по обработке прерываний.
Более подробно об устройстве и функциях EAL можно прочитать в документации.
Управление очередями: библиотека rte_ring
Как мы уже говорили выше, пакет, поступивший на сетевую карту, попадает в приёмную очередь, которая представляет собой кольцевой буфер. В DPDK вновь прибывшие пакеты тоже помещаются в очередь, реализованную на базе библиотеки rte_ring. Все приводимые ниже описания этой библиотеки основаны на руководстве разработчика, а также на комментариях к исходному коду.
При разработке rte_ring за основу была взята реализация кольцевого буфера для FreeBSD.Если вы заглянете в исходники, то обратите внимание на такой комментарий: Derived from FreeBSD«s bufring.c.
Очередь представляет собой кольцевой буфер без блокировок, организованный по принципу FIFO (First In, First Out). Кольцевой буфер — это таблица указателей на хранимые в памяти объекты. Все указатели делятся на четыре типа: prod_tail, prod_head, cons_tail, cons_head.
Prod и cons — это сокращения от producer (производитель) и consumer (потребитель). Производителем (producer) называется процесс, который записывает данные в буфер в текущий момент, а потребителем — процесс, который в текущий момент данные из буфера забирает.
Хвостом (tail) называется место, куда в текущий момент осуществляется запись в кольцевой буфер. Место, откуда, в текущий момент осуществляется считывание из буфера, называется головой (head).
Говоря образно, смысл операции постановки в очередь и выведения из очереди заключается в том, чтобы поменять голову и хвост местами. Например, при добавлении нового объекта в очередь в итоге всё должно получиться так, что указатель ring→prod_tail будет указывать на то место, куда ранее указывал ring→prod_head.
Здесь мы приводим лишь краткое описание; более подробно о сценариях работы кольцевого буфера можно прочитать в руководстве разработчика на сайте DPDK.
Из преимуществ такого подхода к управлению очередями следует выделить, во-первых, более высокую скорость записи в буфер. Во-вторых, при выполнении операций массовой постановки в очередь и массового выведения из очереди промахи кэша имеют место гораздо реже, потому что указатели хранятся в таблице.
Недостатком реализации кольцевого буфера в DPDK является фиксированный размер, который невозможно увеличить «на лету». Кроме того, на работу с кольцевой структурой расходуется гораздо больше памяти, чем на работу со связанным списком: в кольце всегда используется максимально возможное количество указателей.
Управление памятью: библиотека rte_mempool
Мы уже говорили выше, что для работы DPDK нужны большие страницы памяти (HugePages). В инструкциях по установке рекомендуется создавать HugePages размером по 2 мегабайта.
Эти страницы объединяются в сегменты, которые затем делятся на зоны. В зоны уже помещаются объекты, создаваемые приложениями или другими библиотеками — например, очереди и буферы пакетов.
К числу таких объектов принадлежат и пулы памяти, которые создаёт библиотека rte_mempool. Это пулы объектов фиксированного размера, которые используют rte_ring для хранения свободных объектов и могут быть идентифицированы по уникальному имени.
Для улучшения производительности могут использоваться техники выравнивания памяти.
Несмотря на то, что доступ к свободным объектам организован на базе кольцевого буфера без блокировок, затраты системных ресурсов могут быть очень большими. К кольцу имеют доступ несколько процессорных ядер и всякий раз, когда ядро обращается к кольцу, нужно осуществлять операцию сравнения с обменом (compare and set, CAS).
Чтобы кольцо не стало «узким местом», каждое ядро получает дополнительный локальный кэш в пуле памяти. Ядро имеет полный доступ к кэшу свободных объектов с помощью механизма блокировок. Когда кэш заполняется или освобождается полностью, пул памяти обменивается данными с кольцом. Таким образом обеспечивается доступ ядра к часто используемым объектам.
Управление буферами: библиотека rte_mbuf
В сетевом стеке Linux, как это уже было отмечено выше, для представления всех сетевых пакетов используется структура sk_buff. В DPDK для этой цели используется структура rte_mbuf, описанная в заголовочном файле rte_mbuf.h.
Подход к управлению буферами в DPDK во многом напоминает тот, что используется в FreeBSD: вместо одной большой структуры sk_buff — много буферов rte_mbuf небольшого размера. Буферы создаются до запуска приложения, использующего DPDK, и хранятся в пулах памяти (для выделения памяти используется библиотека rte_mempool).
Помимо собственно данных пакета каждый буфер содержит и метаданные (тип сообщения, длина, адрес начала сегмента данных). Буфер также содержит указатель на следующий буфер. Это нужно для работы с пакетами, содержащими большое количество данных — в этом случае пакеты можно объединять (так же, как это делается в FreeBSD — подробнее об этом можно прочитать, например, здесь).
Другие библиотеки: краткий обзор
В предыдущих разделах мы описали лишь самые основные библиотеки DPDK. Но есть ещё множество других библиотек, рассказать о которых в рамках одной статьи вряд ли возможно. Поэтому мы ограничимся лишь кратким обзором.
С помощью библиотеки LPM в DPDK реализуется алгоритм Longest Prefix Match (LPM), используемый для пересылки пакетов в зависимости от их IPv4-адреса. Основные функции этой библиотеки заключаются в добавлении и удалении IP-адресов, а также в поиске нового адреса с использованием LPM-алгоритма.
Для IPv6-адресов аналогичная функциональность реализована на базе библиотеки LPM6.
В других библиотеках похожая функциональность реализована с помощью хэш-функций. С помощью rte_hash можно осуществлять поиск по большому набору записей с использованием уникального ключа. Эту библиотеку можно использовать, например, для классификации и распределения пакетов.
Библиотека rte_timer обеспечивает асинхронное выполнение функций. Таймер может выполняться как один раз, так и периодически.
Заключение
В этой статье мы попытались рассказать о внутреннем устройстве и принципах работы DPDK. Попытались, но не рассказали до конца — тема эта настолько сложна и обширна, что одной статьи явно не хватит. Поэтому ждите продолжения: в следующей статье мы более подробно поговорим о практических аспектах использования DPDK.
В комментариях мы с удовольствием ответим на все ваши вопросы. А если у кого-то из вас есть опыт использования DPDK, то будем признательны за любые замечания и дополнения.
Для всех, кто хочет узнать больше, приводим полезные ссылки по теме:
- http://dpdk.org/doc/guides/prog_guide/ — детальное (хотя местами запутанное) описание всех библиотек DPDK;
- https://www.net.in.tum.de/fileadmin/TUM/NET/NET-2014–08–1/NET-2014–08–1_15.pdf — краткий обзор возможностей DPDK, сравнение с другими фреймворками аналогичного плана (netmap и PF_RING);
- http://www.slideshare.net/garyachy/dpdk-44585840 — презентация-введение в DPDK для начинающих;
- http://www.it-sobytie.ru/system/attachments/files/000/001/102/original/LinuxPiter-DPDK-2015.pdf — презентация с объяснениями устройства DPDK.
