Всё, что вы хотели знать о стек-трейсах и хип-дампах. Часть 2
Перед вами вторая часть расшифровки доклада Андрея Паньгина aka apangin из Одноклассников с одного из JUG’ов (допиленная и расширенная версия его доклада с JPoint 2016). В этот раз мы закончим разговор о стек-трейсах, а также поговорим о дампах потоков и хип-дампах.
Итак, продолжаем…

Раз уж мы заговорили о рекурсии, что будет, если я запущу вот такой рекурсивный метод, который никогда никуда не возвращается:
static int depth;
static void recursion() {
depth++;
recursion();
}
public static void main(String[] args) {
recursion();
}Сколько пройдет вызовов, прежде чем появится StackOverflowError (на стандартных настройках — на стандартном размере стека)?
Давайте измерим:
package demo4;
public class Recursion {
static int depth;
static void recursion() {
depth++;
recursion();
}
public static void main(String[] args) {
try {
recursion();
} catch (StackOverflowError e) {
System.out.println(depth);
}
}
}Тот же самый код, только добавили catch StackOverflowError.
На 64-битной системе с размером стека 1 Мб результат варьируется от 22 до 35 тыс. вызовов. Почему такая большая разница? Дело в JIT: методы компилируются в фоновом потоке компилятора параллельно с исполнением java-кода. В какой-то момент (после того, как метод recursion несколько раз уже вызвался) запускается компиляция этого метода, а в это время продолжается исполнение в интерпретаторе. Как только компилятор закончит свою работу, следующий вызов перейдет не в интерпретированный фрейм, а в скомпилированный код.
Начиная с Java 8, у нас по умолчанию в одной VM есть 2 компилятора — «легкий» C1 и «тяжелый» C2, т.е. возможна ситуация, когда у нас на стеке окажутся фреймы трех типов: интерпретированный, скомпилированный C1 и скомпилированный C2. Это все будет один и тот же метод, просто с разным уровнем компиляции. Размер фрейма может сильно отличаться. У интерпретатора самые громоздкие фреймы, потому что все хранится в стеке (все аргументы, локальные переменные, дополнительные указатели на текущий метод, указатель текущего байткода и т.д.). В скомпилированном коде многое из этого не нужно и, чем оптимальнее будет компилятор, тем меньше надо хранить на стеке. C2, к примеру, вообще не будет заводить место на стеке под локальные переменные — все распихает по регистрам, а еще и заинлайнит на один уровень.
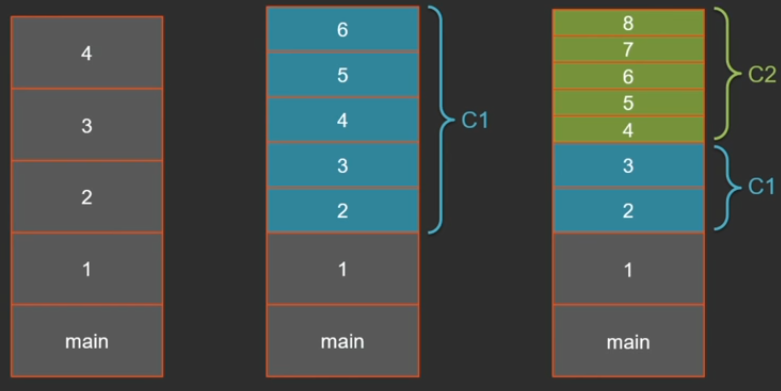
Если тот же самый код исполнить в чисто интерпретируемом режиме с ключиком
-Xint
Результат — практически всегда 12500 (± несколько фреймов).
Теперь то же самое, но после компилятора C1.
-Xcomp -XX:TieredStopAtLevel=1
В случае с компилятором C1 результаты тоже довольно стабильны — порядка 25 тыс.
Если все сразу компилировать в C2:
-Xcomp -XX:-TieredCompilation
все это будет работать дольше, но зато результат — 62 тыс. фреймов.
Если поделить стандартный размер стека (1 Мб) на 62 тыс., получится, что на 1 фрейм уходит примерно 16 байт. Я проверял по скомпилированному коду — так и есть. Размер фрейма на самом деле не 16 байт, а 32, но в 1 фрейме заинлайнено сразу 2 уровня вложенности.
По умолчанию на 64-битной архитектуре размер стека 1 Мб:

но его можно корректировать. Эти 2 ключика — синонимы.
-Xss, -XX:ThreadStackSize
Менее известный факт — что можно менять размер стека одного конкретного потока:
Thread(ThreadGroup, target, name, stackSize)
Но при создании больших стеков нельзя забывать о том, что они занимают место в памяти и может случиться такая ситуация, что много стеков, много потоков с большим размером стека приведут к out of memory:
java.lang.OutOfMemoryError: Unable to create new native thread
Интересный факт: если посмотреть с помощью ключика jvm -XX:+PrintFlagsFinal на Linux он действительно выдаст, что у него ThreadStackSize 1 Мб, а если посмотреть на Windows — дефолтное значение ключика ThreadStackSize будет 0. Откуда берется тогда 1 Мб?
Для меня самого было откровением, что дефолтный размер стека задается в exe-шнике (в атрибутах exe-формата прописан дефолтный размер для приложения).
Минимальный размер стека на 64-битной системе — примерно 228 Кб (он может меняться от версии к версии JDK). Как устроен стек и откуда складывается этот минимальный размер?

На стеке, помимо фреймов ваших Java-методов, есть еще некоторое зарезервированное пространство. Это как минимум всегда 1 красная зона (размером с 1 страницу — 4 Кб) в самой верхушке стека и несколько страниц желтой зоны.
Красная и желтая зоны нужны для проверки stack overflow. В начале обе зоны защищены от записи. Каждый Java-метод через попытку записи по адресу текущего стек-поинтера проверяет достижение красной или желтой зоны (при попытке записи операционная система генерирует исключение, которое виртуальная машина перехватывает и обрабатывает). При достижении желтой зоны она разблокируется, чтобы хватило места запустить обработчик stack overflow, и управление передается на специальный метод, который создает экземпляр stack overflow error и передает его дальше. При попадании в красную зону возникает unrecoverable error и виртуальная машина фатально завершается.
Есть еще так называемая shadow-зона. У нее довольно странный размер: на Windows — 6 страниц, на Linux, Solaris и прочих ОС — 20 страниц. Это пространство резервируется для нативных методов внутри JDK и нужд самой виртуальной машины.
Когда я готовил презентацию, запускал свой рекурсивный тестик и на Java 8, и на Java 9. На последней я получил такой чудесный краш виртуальной машины (фрагмент вывода):
#
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_STACK_OVERFLOW (0xc00000fd) at pc=0x0000019507acb5e0, pid=9048, tid=10544
#
# JRE version: Java(TM) SE Runtime Environment (9.0+119) (build 9-ea+119)
# Java VM: Java HotSpot(TM) 64-Bit Server VM (9-ea+119, mixed mode, tiered, compressed oops, g1 gc, windows-amd64)
# Problematic frame:
# J 155 C2 demo4.Recursion.recursion()V (12 bytes) @ 0x0000019507acb5e0 [0x0000019507acb5e0+0x0000000000000000]
#
# No core dump will be written. Minidumps are not enabled by default on client versions of Windows
#
# If you would like to submit a bug report, please visit:
# http://bugreport.java.com/bugreport/crash.jsp
#
--------------- S U M M A R Y ------------
…
Я, естественно, скачал самый последний из доступных билдов (на момент доклада это был 9.0+119), на нем эта проблема также воспроизводится.
Это очень хороший случай для анализа краш-дампа (Андрей Паньгин — Анализ аварийных дампов JVM). Тут пригодились все навыки, в частности, дизассемблирование.
Вот инструкция, которая записывает значение относительно текущего стек-поинтера. Краш произошел как раз на этой инструкции:
Instructions:
00000000: 89 84 24 00 a0 ff ff mov DWORD PTR [rsp-0x6000],eax
00000007: 55 push rbp
00000008: 48 83 ec 10 sub rsp,0x10
0000000c: 49 ba 78 71 88 8d 00 00 00 00 movabs r10,0x8d887178
00000016: 41 83 42 70 02 add DWORD PTR [r10+0x70],0x2
0000001b: e8 e0 ff ff ff call 0x00000000
Registers:
RSP=0×0000007632e00ff8
Java Threads:
=>0×0000019571d71800 JavaThread «main» [_thread_in_Java, id=10544,
stack (0×0000007632e00000,0×0000007632f00000)]
0×0000007632e00ff8
Используя значение регистра RSP, можно вычислить адрес, в который мы записываем. Нужно отнять 6000 в HEX от этого адреса, получится какое-то такое значение:

Мы записываем по этому значению. Там же в краш-дампе указан диапазоны стека текущего потока:

Мы видим, что это значение попадает в конец самой первой (самой верхней) страницы этого стека, т.е. как раз в красную зону.
Действительно, есть такой баг. Я проанализировал его и нашел причину: некоторым функциям JVM не хватает на Windows доступных 6 shadow-страниц (они занимают больше при исполнении). Разработчики виртуальной машины обсчитались.
Кстати, размер этих зон можно менять ключиками JVM.
Зачем нам вообще большие стеки? Для Java EE, не иначе.
Вот одна из моих любимых картинок на эту тему.

На 2 строчки бизнес-логики порождаются сотни фреймов от различных фреймворков и application-серверов.
Стек-трейсы для измерения перформанса
Профилирование — неотъемлемая часть измерения производительности вашей системы. Все профиляторы можно разделить на 2 большие группы: семплирующие и инструментирующие.
Инструментирующий профайлер просто помечает методы: добавляет в начало какую-то сигнализацию о входе в метод, в конец — сигнализацию о выходе из него. Понятно, если мы каждый метод так проинструментируем, все это будет создавать большой overhead, хотя измерение будет довольно точным.
public void someMethod(String… args) {
Profiler.onMethodEnter («myClass.someMethod»);
// method body
Profiler.onMethodExit («myClass.someMethod»);
}
В продакшене чаще всего применяется иной подход — семплирующий профайлер. Он с какой-то периодичностью (10–100 раз в секунду) снимает дамп потоков и смотрит, какие треды с какими трейсами в данный момент выполняются. Методы, которые чаще всего попадают в эти стек-трейсы, и являются горячими.
Давайте посмотрим сразу на примере, как это работает. Я написал небольшую программку. Несмотря на то, что она маленькая, сходу и не скажешь, что в ней может тормозить.
Во-первых, она генерирует 2 случайные географические координаты. Потом в цикле вычисляет расстояние от случайно сгенерированной координаты до другой заданной точки (Москвы) — т.е. есть функция distanceTo, в которой много математики.
Результаты складываются в хэш-мап.
Все это в цикле много-много раз бежит:
package demo5;
import java.util.IdentityHashMap;
import java.util.Map;
import java.util.concurrent.ThreadLocalRandom;
public class Location {
static final double R = 6371009;
double lat;
double lng;
public Location(double lat, double lng) {
this.lat = lat;
this.lng = lng;
}
public static Location random() {
double lat = ThreadLocalRandom.current().nextDouble() * 30 + 40;
double lng = ThreadLocalRandom.current().nextDouble() * 100 + 35;
return new Location(lat, lng);
}
private static double toRadians(double x) {
return x * Math.PI / 180;
}
public double distanceTo(Location other) {
double dlat = toRadians(other.lat - this.lat);
double dlng = toRadians(other.lng - this.lng);
double mlat = toRadians((this.lat + other.lat) / 2);
return R * Math.sqrt(Math.pow(dlat, 2) + Math.pow(Math.cos(mlat) * dlng, 2));
}
private static Map calcDistances(Location target) {
Map distances = new IdentityHashMap<>();
for (int i = 0; i < 100; i++) {
Location location = Location.random();
distances.put(location, location.distanceTo(target));
}
return distances;
}
public static void main(String[] args) throws Exception {
Location moscow = new Location(55.755773, 37.617761);
for (int i = 0; i < 10000000; i++) {
calcDistances(moscow);
}
}
} Тут все может тормозить: и генерация случайной координаты, и измерение расстояния (тут много математики), и раскладывание по мапе. Давайте запустим профайлер и посмотрим, на что именно тут тратится время.
Возьму Java VisualVM (входит в стандартную поставку JDK — ничего проще нет), нахожу наш процесс на закладке Sampler, щелкаем CPU — начинаем измерения (дадим поработать пол минуты). Дефолтный интервал измерений — раз в 100 мс.
Что получилось:
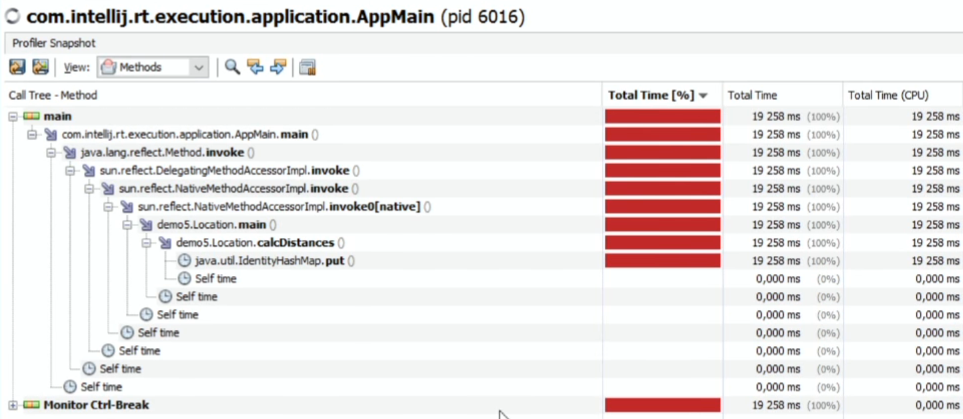
Чуть менее чем полностью (согласно профилятору Java VisualVM) время у нас тратится на IdentiryHashMap.put.
Если посмотреть плоскую табличку по методам, отсортировав по SelfTime:
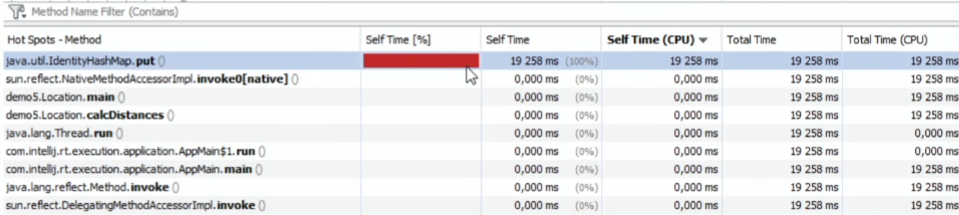
Как будто ничего другого и не выполняется.
То же самое можно померить другими профайлерами (JProfiler, YourKit и т.п.), уверяю вас, результат будет такой же.
Неужели HashMap настолько тормозные? Нет. Просто профайлеры врут.
Устроены они при этом одинаково: с заданной периодичностью они вызывают метод через JMX или JVMTI (смотря как они подключаются), который получает дамп всех потоков. Например, в JVMTI есть метод GetAllStackTraces (http://docs.oracle.com/javase/8/docs/platform/jvmti/jvmti.html#GetAllStackTraces). То, что виртуальная машина говорит, они здесь суммируют и печатают.
Положа руку на сердце, это не профайлеры врут, а JVM — она дает неправильные стек-трейсы. У всех профайлеров есть одна большая проблема: стек-трейсы потоков могут быть сняты только в моменты safepoint, а это определенные точки в коде, про которые виртуальная машина знает, что поток можно безопасно остановить. И таких точек на самом деле немного: они есть внутри циклов и в точках выхода из методов. Если у вас есть большое полотно кода — той же математики; без циклов — в нем может вообще не быть safepoint, значит, это полотно никогда в стек-трейсы не попадет.
Другая проблема в том, что потоки, которые спят, и потоки, которые работают, сэмплятся одинаково, т.к. у нас снимается дамп со всех потоков. Это не очень хорошо, т.к. спящие потоки нам не интересно видеть в стек-трейсах.
Также большинство профайлеров не могут отличить нативные методы, которые спят на каком-то блокирующем системном вызове. Например, при ожидании данных из сокета поток будет в состоянии runnable и профайлер будет показывать, что поток ест 100% CPU. А он не ест CPU, просто виртуальная машина не может отличить работающий нативный метод от блокирующего системного вызова.
Что делать?
В ОС предусмотрены возможности для профилирования нативного кода. Если говорить о Linux, там есть системный вызов setittimer (http://man7.org/linux/man-pages/man2/setitimer.2.html), который задает таймер и с заданной периодичностью генерирует специальный сигнал ОС (SIGPROF) для профилирования. Он будет получать тот тред, который в данный момент исполняется. Нам бы хорошо уметь использовать возможности ОС и в обработчике сигнала SIGPROF собирать стек-трейсы текущего потока, даже если он не в safepoint. И в виртуальной машине HotSpot такая возможность предусмотрена. Есть недокументированный приватный API: AsyncGetCallTrace, который можно вызывать для получения текущего стека потоков не в safepoint.
Эта дырка была пропилена специально для Oracle Solaris Studio. Это чуть ли не единственный профилятор, который получает честный стек-трейс.
Пока готовил этот доклад, я смотрел, а есть ли кто-то еще, кто использует эти методы. Нашел буквально 2 проекта: один — старый и уже заброшенный, а другой появился сравнительно недавно (в 2015 году) и называется honest-profiler.
API здесь довольно простой: подготавливаем место, куда будем складывать стек, и вызываем метод:
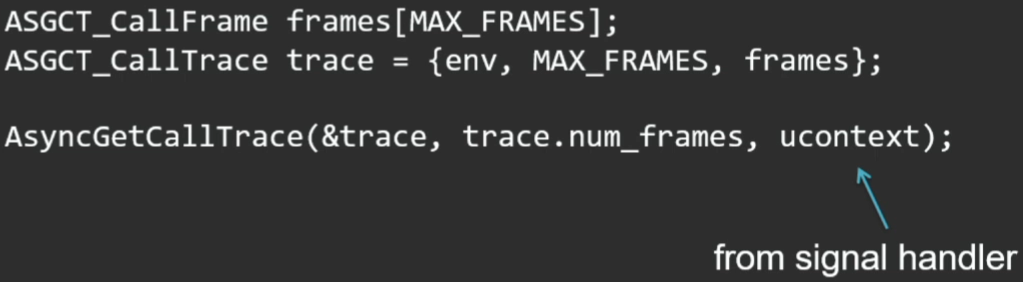
Третьим параметром этого метода является текущий контекст, который приходит к нам в signal handler.
Ссылка на мой собственный open source профайлер: https://github.com/apangin/async-profiler. Берите — пользуйтесь. Сейчас он уже в том состоянии, когда его не стыдно показать людям. Правда, сейчас он реализован только для Linux (Примечание: со времени доклада добавилась поддержка macOS).
Проверим на том же примере.
Говорим, какой процесс профилируем.
Наш Pid — 3202.
Особенность моего профайлера (которую я еще ни у кого не видел) в том, что он может подключаться на лету (упомянутый honest-profiler надо обязательно запускать в качестве Java-агента при старте приложения).
Дадим несколько секунд на профилирование. Вот что получаем в результате:
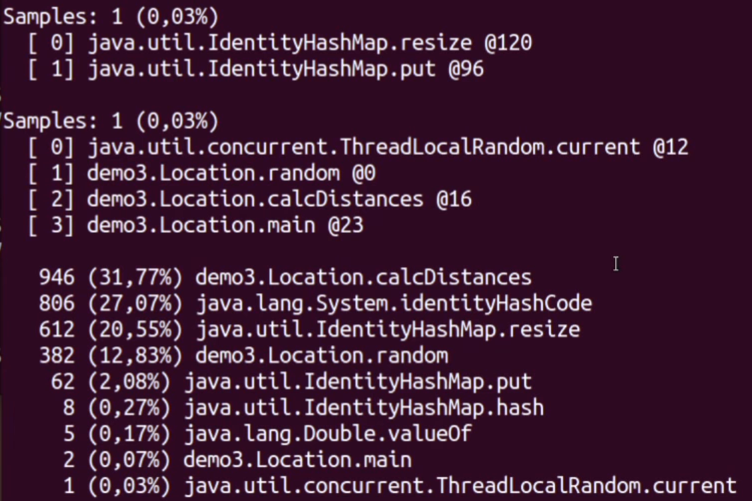
В конце — плоский список методов; чуть выше — отдельно подробности (все стеки потоков). Картина кардинально отличается. Чуть ли не треть всего времени уходит на математику — вычисление расстояния. IdentityHashMap.put — вообще внизу с результатом 2% (согласно первому профайлеру он занимал 100%). А реально занимает время вычисление identityHashCode объекта. И немало времени уходит на сам put и resize. К слову, генерация случайной локации тоже не бесплатна (как минимум 12%).
Почувствуйте разницу.
Накладные расходы этого профайлера гораздо меньше. Его можно запускать хоть 1000 раз в секунду, и это будет нормально, поскольку он снимает стек-трейс только активного потока. И складывает результаты он в очень компактную структуру — он не генерирует все эти названия методов, классов. Это все вычисляется только при распечатке. А во время профилирования складываются только jmethodID (фактически, указатели на методы).
Дампы потоков
Есть много способов делать дампы потоков: java-вские, нативные, изнутри самого процесса, снаружи процесса.
Если говорить об анализе процесса изнутри, то есть Java API getAllStackTraces, который выдает нам массив StackTraceElement со всеми вытекающими.

Когда мы на продакшене пытались им пользоваться, для случая с 2 тысячами потоков, у каждого из которых глубина стека 50–60 фреймов, один только этот массив занимал порядка 50 Мб.
Есть похожий метод у JMX (он полезен тем, что его можно дергать удаленно). Он выдает тот же самый массив StackTraceElement, а вдобавок еще информацию о захваченных мониторах.
Если говорить о генерации стек-трейсов из самого приложения, гораздо лучше способ — JVMTI (Tool Interface) — нативный интерфейс для разработки инструментов, профилировщиков, анализаторов и т.д.

Есть метод GetAllStackTraces, который обычно используют как раз профайлеры. По сравнению с Java API у него очень компактное представление.
При снятии дампов снаружи, то самый простой способ — это послать процессу SIGQUIT (или kill -3 или в консоли соответствующую комбинацию):

Преимущество метода в том, что стек-трейсы распечатает сама Java машина. Это делается с максимальной скоростью. Это все равно происходит во время safepoint, но нам не нужно создавать никаких промежуточных структур.
Альтернативный путь — утилита jstack. Она работает через механизм dynamic attach (на ней я остановлюсь подробнее).
Важно понимать, что у утилит jstack и jmap есть 2 режима работы. Они отличаются всего одним ключиком -F, но по сути это 2 разные утилиты, которые служат для одного и того же, но работают двумя совершенно разными способами.
Поясню, в чем между ними разница.
Dynamic attach — это механизм общения утилиты с JVM через специальный интерфейс. Как это происходит (на примере Linux)?
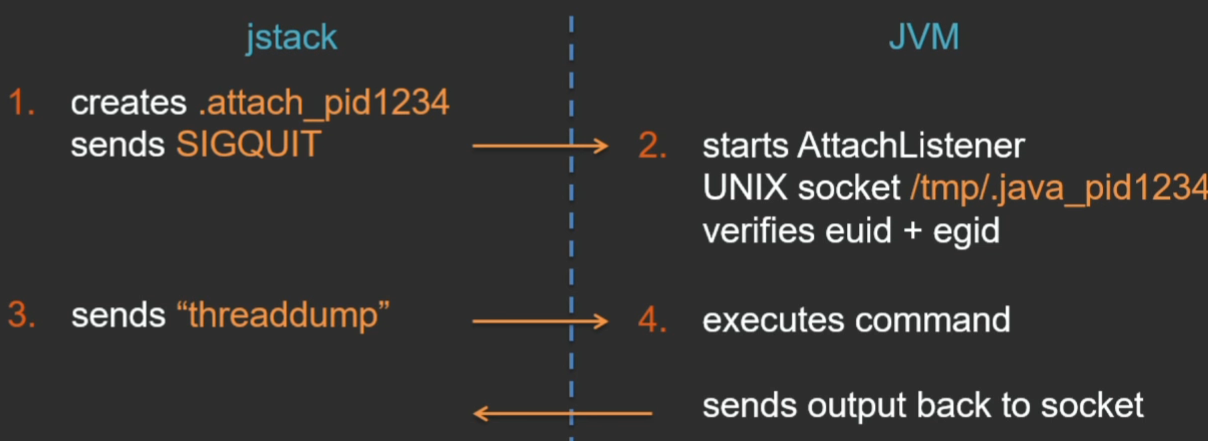
Утилита jstack создает некий файлик в текущем каталоге — сигнал того, что утилита хочет подключиться к JVM, и посылает виртуальной машине сигнал SIGQUIT. Виртуальная машина обрабатывает этот сигнал, видит в текущем каталоге сигнальный файлик .attach_pid и в ответ на это запускает специальный поток — AttachListener (если он уже запущен, то ничего не делает). И в этом потоке открывается UNIX domain socket для коммуникации между утилитой jstack и JVM. Когда утилита подконнектится к этому сокету, JVM проверяет права пользователя на той стороне, чтобы нельзя было чужим пользователям подключиться к виртуальной машине и получить какую-то приватную информацию. Но проверка там очень простая — проверяются только точное соответствие эффективных UID и GID (в итоге есть такая популярная проблема, что при запуске jstack из под другого пользователя, даже root, вы не сможете получить дамп ровно из-за этой проверки).
После того как соединение по UNIX socket установлено, утилита посылает команду, и эту команду исполняет сама виртуальная машина, а ответ пересылает назад утилите по этому же сокету.
В Window все устроено несколько по-другому (не знаю, почему нельзя было сделать так же; в Windows нет разве что UNIX-сокетов, зато есть named pipes) — есть другой красивый API, который мне нравится, поэтому я не мог не упомянуть его здесь.
Начало примерно такое же — создается named pipe. Далее в Windows API есть функция WriteProcessMemory, которая может записывать некоторые данные напрямую в память чужого процесса, если у нее есть на это права. Через эту функцию создается временная вспомогательная страница памяти в адресном пространстве java-процесса, туда записывается команда, которую нужно выполнить, аргументы и название pipe, куда пойдет ответ. Еще одна не менее чудесная функция, которая позволяет внедрить в чужой процесс тред — CreateRemoteThread. Утилита jstack запускает удаленный поток — он исполняется уже в контексте процесса виртуальной машины. И в качестве аргумента этому треду передается указатель на созданную ранее область памяти, где есть вся информация о команде.
Далее все то же самое: JVM сама исполняет команду и посылает результат назад.

Плюсы такого подхода:
- все операции исполняются напрямую виртуальной машиной наиболее эффективным способом;
- поскольку интерфейс не зависит от версии VM, одной утилитой jstack можно снимать дампы с разных процессов, вне зависимости от того, под какой версией Java эти VM запущены.
К недостаткам можно отнести:
- уже упомянутое ограничение на несоответствие пользователя;
- это можно исполнять только на «живой» виртуальной машине, поскольку команды выполняются самой виртуальной машиной;
- этот механизм можно отключить (например, в целях безопасности) специальной JVM-опцией
-XX:+DisableAttachMechanism.
В качестве «proof of concept» я решил написать простую утилитку на С, которая таким способом подключается к удаленному Java-процессу и исполняет там команду, переданную в командной строке (https://github.com/apangin/jattach).
Виртуальная машина поддерживает следующие команды:

Это дамп тредов, дамп хипа, получение гистограммы хипа, распечатка и установка флагов виртуальной машины, исполнение команд, которые умеет исполнять утилита jcmd, и load — наверное, самая интересная команда, которая позволяет загрузить библиотеку JVMTI-агента в удаленную виртуальную машину. С помощью команды load и работает мой async профайлер (загружает свою библиотеку в удаленную JVM).
Кратко продемонстрирую, как это работает. Запущу какой-нибудь процесс, допустим, tomcat:
pid процесса — 8856.

по команде выдается тот самый дамп потока. Поскольку это не java-утилита, а С, нам не нужно тратить время на запуск Java. Утилитка очень короткая — буквально 100 строчек для Windows и для Linux. Доступно на GitHub.
Через этот механизм работает не только утилита jstack, но и утилиты jmap, jinfo и jcmd (по сути один мой jattach исполняет роль всех этих утилит).
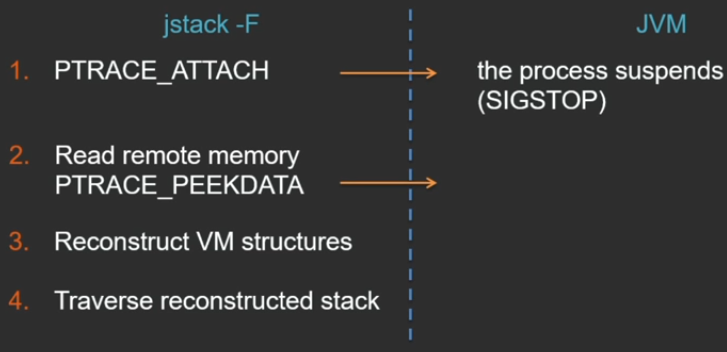
Второй способ — режим jstack -F. Отличается он тем, что здесь никакой кооперации от JVM уже не требуется — утилита все делает сама.
На Linux через системный вызов PTRACE_ATTACH (на Windows есть аналогичный) полностью останавливает процесс, к которому подключаемся, замораживая его состояние. Дальше через дебажный API, который позволяет читать память с чужого процесса, утилита jstack вытаскивает все, что нужно, из удаленного JVM процесса. Далее у себя реконструирует структуры JVM и пробегает по ним, сама восстанавливает стек.
Поскольку операция PTRACE_PEEKDATA за 1 раз из чужого процесса может прочитать только 1 машинное слово, если нам нужен большой хип, придется сделать много системных вызовов (что, конечно же, очень медленно).
Но плюс в том, что:
- никакой кооперации от виртуальной машины не требуется — можно утилиту jstack -F запускать даже на зависшей или зацикленной VM;
- пользователь root может подключиться к виртуальной машине, созданной любым пользователем.
Минусы тоже понятны:
- выполняется все медленнее, чем если бы это делала сама виртуальная машина;
- поскольку утилитой jstack воссоздаются структуры виртуальной машины, утилита должна знать, что где располагается, поэтому версия утилиты jstack должна в точности совпадать с версией JVM, против которой она запускается.

Для чего это нужно? Например, в ситуации, когда у нас удаленный сервер принимает запросы от клиентов. В какой-то момент он начинает по некой причине тормозить и перестает справляться с потоком входящих запросов. Когда приложение детектит эту ситуацию (например, исчерпался thread pool), запускается дамп потоков, чтобы разработчик в логах мог увидеть, что же система делала в этот момент, что же именно затупило.
Как я говорил ранее, мы у себя в проекте ранее использовали Java API для получения стека потоков, это было очень медленно и занимало кучу памяти. Вместо этого мы теперь собираем информацию через Dynamic Attach — есть к нему Java API, через который как раз и работает утилита jstack. Мы узнаем pid своего же процесса, подключаемся сами к себе через Dynamic Attach и заставляем виртуальную машину саму сгенерировать нам дамп.
public static void dump() throws AttachNonSupportedException, IOException {
String vmName = ManagementFactory.getRuntimeMXBean().getName();
Sring pid = vmName.substring(0, vmName.indexOf(‘@’));
HotSpotVirtualMachine vm = (HotSpotvirtualMachine) VirtualMachine.attach(pid);
try {
vm.localDataDump();
} finally {
vm.detach();
}
}Ссылка на GitHub примера: https://github.com/odnoklassniki/one-nio/blob/master/src/one/nio/mgt/
Хип-дампы
Утилита jmap в принципе устроена так же.
jmap -dump:live,format=b,file=heap.bin PID
Утилита умеет дампить содержимое хипа целиком или, если вам не нужен весь хип, просто строить гистограммы классов:

Виртуальная машина пробегает по хипу и считает, сколько экземпляры каждого класса занимают в памяти. Далее выводит гистограмму, сортированную по размеру классов. Из этой гистограммы можно понять, какие объекты больше всего мусорят в хипе.
У этой утилиты также существует 2 режима работы: через Dynamic Attach и через Serviceability Agent (с теми же плюсами и минусами).

jmap без -F работает быстро, может снять дампы с приложений других версий, но запускается только на живой JVM. В свою очередь jmap -F может снимать дампы даже с зависших приложений, но это очень медленно.
В каком случае может не сработать jmap? Часто вы хотите получить дамп хипа, когда произошла какая-то проблема. Предположим, у вас произошла какая-то утечка в хипе, VM вошла в бесконечный цикл сборки мусора — именно в этот момент вы хотите сдампить хип, чтобы посмотреть, чем он замусорен. Но как раз в этот момент виртуальная машина этого не может сделать, потому что через механизм Dynamic Attach просто не подключиться. Придется либо повторять запуск утилиты, надеясь попасть на тот интервал, когда все-таки исполняется код приложения, либо воспользоваться опцией -F. Но и тут могут подкарауливать неприятности. Если сейчас работает сборка мусора, то состояние хипа может оказаться неконсистентным. Восстановить утилита jmap ничего не сможет, просто потому что в хипе были перезаписаны какие-то указатели.
К счастью, есть хитрый способ, как снимать дампы с мертвых или зависших потоков в forced-режиме.
$ sudo gcore 1234
$ jmap -dump:format=b,file=heap.bin /path/to/java core.1234
Вам не нужно пробегать весь хип, анализировать объекты — можно сгенерировать не дамп хипа, а дамп всего процесса — core dump. Это делается гораздо быстрее. Ничего не сканируется, просто память пишется подряд на диск с максимальной скоростью диска. И дальше приложение может продолжить работу.
Далее jmap можно «натравить» на полученный в forced-режиме core-дамп.
Давайте покажу на примере.
У меня запущен tomcat с pid 2362. Попробуем снять jmap в forced-режиме:

Это происходит долго. Ждем пару минут и прерываем. В то же время, если я вызову gcore, результат (core-дамп) получаем за секунду. Занимает он 227 Мб.
Приложение дальше работает: ваши пользователи даже не заметили, что tomcat на секунду перестал принимать подключения.
Дальше jmap можно натравить на этот core-файл.

Он тоже будет работать долго, т.к. здесь тот же самый механизм, но вас это уже не волнует, поскольку приложение работает, а обработка идет в офлайне (это даже чуть быстрее, чем jmap -F, поскольку здесь данные получаем с диска порциями, а не по 1 слову вытягиваете из удаленного процесса через системные вызовы). Правда, если дамп неконсистентный, jmap -F и в этом случае ничего обработать не сможет.
В тех случаях, когда что-то пошло плохо, хочется генерировать хип-дамп автоматически. Для этого есть опция виртуальной машины:
-XX:+HeapDumpOnOutOfMemoryError
Она полезна для самого распространенного случая — когда у вас произошло out of memory. Сборки GC можно не дождаться, лучше сразу сдампить хип для последующего анализа и рестартануть приложение.
Также можно дампить хип до и после полной сборки мусора:

Опционально можно задать путь или конкретное имя файла, куда это все будет сложено.
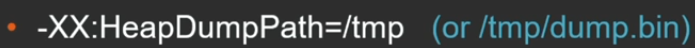
Интересно, что все перечисленные опции являются manageable, т.е. включать и выключать их можно прямо в рантайме, либо снаружи через команду jinfo, либо из приложения через JMX-интерфейс.
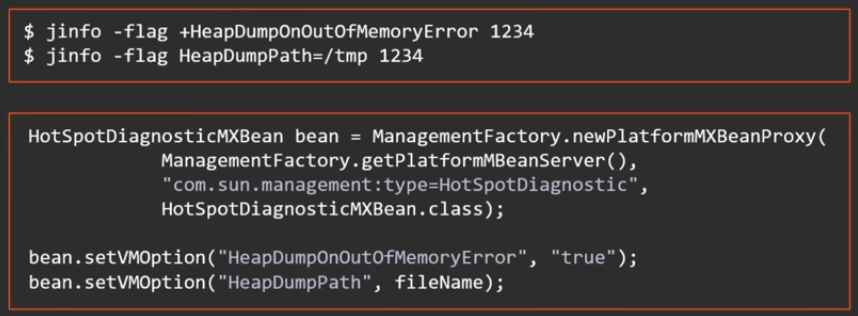
В Java 8 update 92 появились еще 2 новых опции для автоматизации хип-дампов (как раз чтобы downtime был как можно меньше):

Честно говоря, опции, конечно, полезные, но можно и без них было обходиться. Ничто не мешало задать одновременно такие 2 опции (сдампить хип на out of memory и потом прибить это же приложение):

Какие есть способы сгенерировать дамп хипа?
Это можно сделать из java, из native, изнутри процесса, снаружи процесса.
Изнутри процесса проще всего через соответствующий MXBean:
HotSpotDiagnosticMXBean bean = ManagementFactory.newPlatformMXBeanProxy(
ManagementFactory.getPlatformMBeanServer(),
"com.sun.management:type=HotSpotDiagnostic",
HotSpotDiagnosticMXBean.class);
bean.dumpHeap("/tmp/heap.bin", true);Аналогично если у вас снаружи торчит JMX remote interface, можете через него подключиться и на удаленной виртуальной машине сфорсировать дамп хипа.
Важный момент: jmap работает всегда только на локальной машине, поэтому если у вас нет возможности по ssh к продакшн-серверу подключиться, но необходимо дампить хип, единственный способ его получить — через JMX remote interface.
Быстрее и более гибко из приложения позволяет это сделать все тот же JVMTI. Есть такая замечательная функция IterateOverInstancesOfClass.
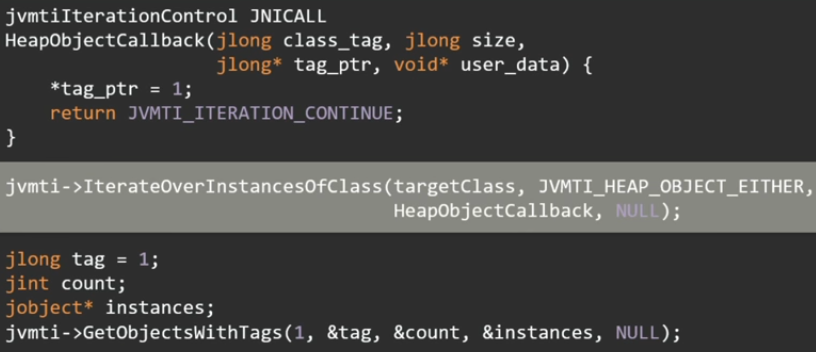
Этой функции можно сразу сказать, что нужно обойти только экземпляры какого-то конкретного класса или интерфейса. Например, вы хотите найти объекты только нужного вам типа, а хип у вас на 16 Гб.
Интересный момент, что пользоваться этой функцией нужно в два этапа. Сначала сама эта функция ничего не возвращает, но она дает возможность пометить объекты, которые вы хотите потом получить. А уже затем вызовом GetObjectsWithTags можно получить отмеченные объекты в массив jobject.
Моя любимая тема — это serviceability agent — API, который есть в HotSpot. Он изначально создавался для разработчиков JDK и JVM, но нашел применение и у простых Java-программистов.
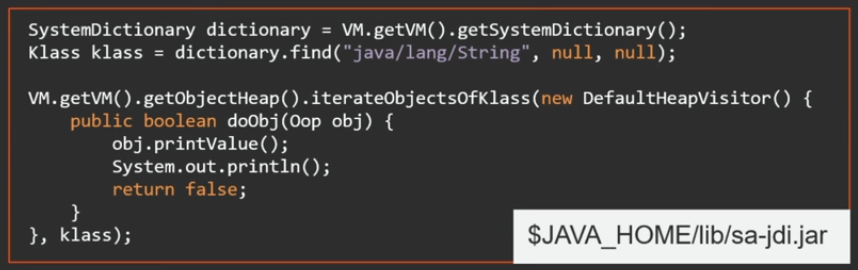
В библиотеках Java есть файлик sa-jdi.jar — это как раз API serviceability agent. Он знает все о внутренностях виртуальной машины: какие есть внутренние структуры JVM, по каким оффсетам что лежит, и есть Java API, чтобы этим всем пользоваться. В частности, можно подключиться к другому процессу VM и обойти хип другого процесса.
Давайте рассмотрим на примере.
Представьте, что вы — хакер, получили на короткое время доступ к серверу. Вы хотите получить оттуда какую-то информацию, например, приватные ключи. Но если вы будете дампить хип целиком, это очень быстро заметят, т.к. тут же сработает монитор простоя приложения. А с помощью serviceability agent можно обойти в хипе только объекты нужных классов и распечатать их.
API очень простой.
package demo6;
import sun.jvm.hotspot.oops.DefaultHeapVisitor;
import sun.jvm.hotspot.oops.Klass;
import sun.jvm.hotspot.oops.Oop;
import sun.jvm.hotspot.runtime.VM;
import sun.jvm.hotspot.tools.Tool;
public class KeyScanner extends Tool {
@Override
public void run() {
Klass klass = VM.getVM().getSystemDictionary().find("java/security/PrivateKey", null, null);
VM.getVM().getObjectHeap().iterateObjectsOfKlass(new DefaultHeapVisitor() {
@Override
public boolean doObj(Oop oop) {
oop.iterate(new FieldPrinter("key"), false);
return false;
}
}, klass);
}
public static void main(String[] args) {
new KeyScanner().execute(args);
}
}Уже заготовлен весь фреймворк (в виде класса Tool), и утилита должна просто заэкстендить этот класс и вызвать его метод execute с аргументами (даже обработка аргументов уже происходит за вас). Остается только в методе run реализовать логику.
Это все работает через механизм serviceability agent, когда отлаживаемый процесс полностью останавливается и методом чтения удаленной памяти происхо
