Временное хранилище данных на Apache Druid: почему это эффективно сработало для загрузки табличных файлов
Всем привет! Меня зовут Амир, я Data Engineer в компании «ДЮК Технологии». Расскажу, как мы спроектировали и реализовали на Apache Druid хранилище разрозненных табличных данных.
Тысячи сотрудников заказчика каждый день создают сотни таблиц: отчеты, списки, прогнозы, статистика. К нам заказчик пришел с запросом: создать временное хранилище данных для создания аналитических витрин.
В статье опишу, почему для реализации проекта мы выбрали именно Druid, с какими особенностями реализации столкнулись, как сравнивали методы реализации датасорсов.
Задача
Задача — создать временное хранилище данных (ВХД), чтобы хранить в базах данных загруженные туда JSON/CSV/XLS/XLSX. Затем на основе данных создавать аналитические витрины.
Требуемые характеристики системы:
Оперативное хранение данные с возможностью загрузки JSON/CSV/XLS/XLSX.
Поддержка большого числа одновременных сессий.
Поддержка горизонтального масштабирования.
Возможность формирования витрин данных
Возможность доступа к витринам из BI-инструментов и Dremio
Отказоустойчивость.
Почему Apache Druid?
Инструментом для хранения данных из файлов был выбран Apache Druid — это колоночная база данных реального времени, хорошо подходящая для быстрой обработки больших, редко изменяющихся массивов данных и немедленного предоставления доступа к ним.
Apache Druid имеет уникальную распределенную и эластичную архитектуру, которая предварительно собирает данные из общего слоя данных в практически бесконечный кластер серверов данных. Эта архитектура обеспечивает более высокую производительность и большую масштабируемость по сравнению с такими базами данных, как PostgreSQL и MySQL.
Apache Druid хорошо подходит для создания графических пользовательских интерфейсов (GUI) аналитических приложений. Он также хорошо вписывается в бэк-энд высокопоточных API, которым требуется быстрое агрегирование данных.
Apache Druid поддерживает множество методов и источников для получения и хранения данных и предоставляет большой выбор встроенных API для выполнения тех или иных действий с данными и самой БД, что сильно облегчает взаимодействие с базой данных при помощи внешних инструментов и создания собственного UI с бэк-эндом.
Инструмент Apache Druid используют Airbnb, British Telecom, Paypal, Salesforce, Netflix, Cisco.
Каждая компания использует Apache Druid уникальным образом:
Например, Netflix использует инструмент для агрегирования множества потоков данных, поглощая до 2 терабайт информации каждый час.
Cisco использует Druid в работе аналитической платформы реального времени для сбора данных о сетевых потоках.
Twitch использует Druid, чтобы помогать своим сотрудникам углубляться в высокоуровневые показатели, а не читать сгенерированные отчеты.
Теперь немного об устройстве хранения данных в Druid. Это пригодится для того, чтобы в дальнейшем понимать трудности, с которыми придется столкнуться.
На макро-уровне все данные, хранимые БД Druid, располагаются в Базах данных, которые в свою очередь разбиваются на датасорсы (datasource), которые по смыслу и строению ближе всего к «таблице» из реляционных баз данных, однако способ их записи на диск отличается из-за ориентированности на большие данные и хранение записей поколоночно. Каждый датасорс может иметь свою собственную схему, правила загрузки, ротации и прочее.
Каждая запись в датасорсе обязана иметь метку времени. С помощью неё данные разделяются на временные периоды, называемые временным отрезком (time chunk). Так в дизайн системы закладывается принцип партиционирования. Также, помимо времени, данные можно дополнительно разделять с помощью иных атрибутов, но это не обязательно.
Временные отрезки делятся на сегменты (segment), которые и записываются в постоянное хранилище.
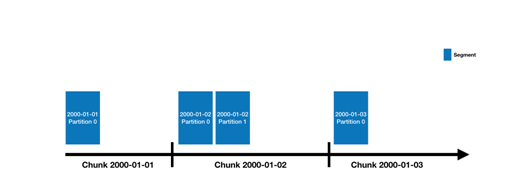
Схема 1
Сегмент — это архив, содержащий несколько специальных файлов, в которых сохранена какая-то часть датасорса (datasource). Данные в нём записываются поколоночно.
При этом каждый сегмент имеет свою схему данных. Она может отличаться от сегмента к сегменту, но любая из них всегда будет являться подмножеством общей схемы датасорса.
Реализация решения
Работали с Apache Druid версии 24.0.1.
Для реализации наших целей мы создали веб-интерфейс, который подключался и отправлял в Apache Druid команды, используя его API.
Для загрузки пользовательских данных в Apache Druid мы использовали встроенный пакетный ввод (Native batch ingestion) — метод, при котором нужно загрузить в Druid так называемую спецификацию задания на загрузку (ingestion task spec, далее its), в которой указываются метаданные о загружаемом файле (местонахождение файла, формат файла, выгружаемые колонки, градация и прочее).
Спецификация позволяет быстро и эффективно загружать данные в Druid, используя заданные параметры и настройки. Большое количество параметров, которые можно настроить, помогает тонко настраивать индексацию данных и получать оптимальную производительность при запросах в Druid.
Бывают простые варианты, когда данные всегда грузятся из одного источника, и при этом оформление данных, количество и названия колонок всегда одинаковое. Но в нашем случае данные в файлах могли быть совершенно разные, и это создавало некоторые неудобства, поскольку нужно было под каждый файл сгенерировать индивидуальный its.
Ниже представлены основные параметры, которые могут использоваться в Ingestion spec:
— `type`: тип источника данных (например, файл, Kafka, JDBC).
— `dimensions`: список всех измерений (полей), которые будут индексироваться.
— `metrics`: список всех метрик, которые будут вычисляться и храниться в индексе.
— `timestamp`: поле временной метки в данных.
— `granularity`: определяет размер временного окна и частоту, с которой данные будут индексироваться.
— `inputFormat`: формат данных, используемый в источнике данных.
— `parser`: параметры, используемые для преобразования данных в формат, который понимает Druid.
— `tuningConfig`: настройки индексации, такие как размер блока сегмента, параметры сбора мусора и другие.
— `ioConfig`: определение фактических настроек чтения и записи данных.
— `firehose`: определяет способ получения потока данных.
Взаимодействие инструментов
В качестве технологий для бэкэнда мы выбрали Python и PostgreSQL. Далее расскажу, почему и для каких целей.
Общая схема взаимодействия инструментов:
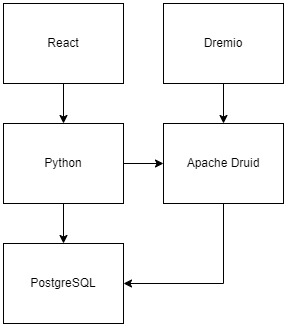
Метаданные Apache Druid в PostgreSQL
Apache Druid хранит метаданные необходимые для работы кластера во внешних хранилищах, а внутри себя хранит только фактические данные, загружаемые пользователем. Для хранения метаданных поддерживаются Derby, MySQL и PostgreSQL. Мы выбрали PostgreSQL, так как это стабильное и гибкое open source решение, широко применяемое во многих крупных проектах.
И, так как у нас по задумке осуществлялся собственный веб-интерфейс с отдельной аутентификацией, отображением истории загрузок и прочих действий пользователей, PostgreSQL также стал хранилищем данных нашего веб-интерфейса и обработки данных пользователей.
Python — мост между Apache Druid и нашим веб интерфейсом
Мы использовали Python в качестве инструмента для написания бэк-энд части нашего веб-интерфейса, в частности использовали библиотеку FastAPI для написания микросервисов вызываемых нашим фронт-эндом.
Python хорошо подошел для решения наших задач, так как имеет все готовые библиотеки для взаимодействия с PostgreSQL и для вызова и обработки сторонних API.
Нами были написаны несколько микросервисов, с помощью которых веб-интерфейс мог взаимодействовать с PostgreSQL и Druid, создан функционал загрузки файлов на сервер и последующей их обработкой перед загрузкой в Apache Druid.
Dremio как альтернатива встроенной web консоли Apache Druid
Dremio обладает механизмом виртуализации данных, который подключается к различным источникам данных, включая базы данных, озера данных и облачные платформы хранения. Затем движок создает унифицированное представление данных, к которым можно получить доступ и запросить их с помощью SQL и других стандартных инструментов.
Проблемы реализации и их решения
Первой большой трудностью, которую нам нужно было решить, стала реализация индивидуального its для каждого файла: в разных файлах могло попадаться разное количество столбцов и с разными именами и градациями.
Необходимо было создать гибкий шаблон its, который можно было подстраивать на уровне бэк-энда в момент загрузки файлов на сервер.
Для этого мы создали таблицу в PostgreSQL, куда сохранили шаблоны its с переменными вместо значений для параметров и написали функцию, которая получала от Python нужные значения для параметров, вычитывая данные из файла и подставляла в шаблон необходимые метаданные.
Следующим сложным шагом было решение проблемы хранения данных в Druid, а именно создание для каждого нового файла отдельный датасорс либо же создание для каждого пользователя отдельный датасорс, в который будут загружаться все его файлы. И мы провели исследование плюсов и минусов обоих этих вариантов, один файл — один датасорс (ОФОД), и один пользователь — один датасорс (ОПОД).
У каждого из двух вариантов были свои недостатки и положительные стороны.
У метода ОПОД были следующие плюсы и минусы:

О плюсах и минусах ОФОД:

По совокупности плюсов и минусов приняли решение для первоначальной реализации использовать метод ОФОД.
Для четкого разделения датасорсов между пользователями решили, что у каждого пользователя название датасорса будет начинаться с префиксом «логин+.+название загруженного файла», и каждый пользователь будет иметь доступ только к своим датасорсам.
Также нам нужно было решить вопрос хранения файлов, загруженных через веб-интерфейс, и дальнейшего их удаления после того, как данные этих файлов будут загружены в Apache Druid.
Было принято решение создать на сервере директорию, в которой эти файлы будут храниться и удаляться ежедневно по расписанию.
Стандартная схема работы Apache Druid:
Витрины без поддержки джойнов
В использованной нами версии Apache Druid не поддерживались DDL команды по типу create table/view, вместо этого можно было создавать модифицированные копии существующих датасетов с помощью конструкций INSERT-SELECT или REPLACE- SELECT.
Но это можно было делать только при помощи встроенной web-консоли либо с помощью API, по JDBC же такая конструкция не срабатывала. В будущих версиях обещали решить это ограничение, но мы не могли ждать и продумали собственное решение.
Результаты внедрения
В результате внедрения мы получили рабочий продукт:
Все таблицы хранятся в едином хранилище.
Веб-интерфейс c JWT аутентификацией.
Аутентификация через Госуслуги.
Разработанный нами коннектор для Dremio ARP, который транслирует запросы от дремио через JDBC. Позволяет в обход встроенной web консоли Apache Druid работать с датасетами.
История загруженных файлов, которая позволяет загружать данные файлов пользователей в Apache Druid для дальнейшей работы с ними сторонними BI приложениями.
Какие есть планы развития продукта:
У Apache Druid есть собственный веб-интерфейс. План — разработать минималистичную кастомизированную консоль для работы BI-аналитиков.
Интерфейсы управления пользователями и логирования.
Реализация CI/CD для повышения скорости разработки.
Мониторинг на базе Grafana.
