Вперёд в п(р)ошлое. Geforce FX. The Dawn of War
Со дня своего основания в Microsoft умели две самые важные вещи в жизни: вовремя проанализировать что-то чужое и сделать на этом какие-то свои деньги. Во многом именно благодаря Microsoft как главному генератору самых максималистских идей вся IT-индустрия шла (и до сих пор идёт) выгодными прежде всего самому Microsoft путями развития. Результатом реализации множества таких идей стало не только банкротство многих гигантов IT-индустрии, но и стремительная всеобщая унификация. Все компоненты в PC от железа до софта становились всё более универсальными и похожими, теряя возможности выгодно отличаться. И вот, в 2002 году, когда Microsoft в очередной раз приложила свои шаловливые монополистические ручонки к 3D-индустрии, по производителям 3D-чипов громовой волной раскатилась спецификация DirectX9…
И как все мы хорошо помним :) уже следующий 2003 год ознаменовал приход киношной графики на PC. Ну да, ведь так всё и было: WinXP, игры на DVD, требующие установить DirectX9, и… одинаковые видеокарты с какими-то там шейдерами. Условно можно сказать, что спецификация DX9 должна была положить конец различиям результатов рендеринга одного и того же изображения на картах разных производителей. Тем не менее, даже эта спецификация не смогла тогда окончательно обуздать NVIDIA. И правильно, иначе зачем NVIDIA было вкладывать во что-то перспективное деньги?
И вот тут мы подходим к тому, что побудило меня в очередной раз ткнуть труп палкой и таки написать этот обзор.
Возможно, вы тоже не знали:
…
David Kirk adds a bit of back-story as to how this technology was brought into GeForce FX:When we did the acquisition of 3dfx, NV30 was underway, and there was a project [code-named Fusion] at 3dfx underway. The teams merged, and the projects were merged. We had each team switch to understand and present the other«s architecture and then advocate it. We then picked and chose the best parts from both.
…
www.extremetech.com/computing/52560-inside-the-geforcefx-architecture/6
К моменту этого высказывания GeForce FX уже был знатным долгостроем и сильно опаздывал на рынок. Можно сказать, NVIDIA однажды удалось избежать того самого дня,

Краем глаза

Действительно… Первое, что бросалось в край нашего глаза при виде легендарного дастбастера (GeForce FX 5800) — это габариты.

Вот это двухслотовое чудовище рядом с Radeon 9800:

Чтобы понять причину столь неординарного решения нам придётся посмотреть поближе…
Ближе к сердцу

GeForce FX хоть и не был первым суперскалярным GPU в мире, но, без сомнения, был самым сложным суперскалярным GPU своего времени и (оставался таковым ещё долгое время). Настолько сложным, что точная информация о, казалось бы, простейших составляющих его внутренней архитектуры до сих пор отсутствует. Как следствие, его выход на рынок переносился… переносился… И вот, наконец, он явился, долгожданный.
NV30: The Dawn of CineFX

Если быть точным, эта самая сложная архитектурная часть NV30 называлась CineFX (1.0) Engine. Маркетологи NVIDIA тогда решили, что это будет звучать привлекательнее nfiniteFX III Engine. Спорно, но факт.
CineFX (кто не понел: Cinematic Effects) — во многом заслуга инженеров 3dfx (вспомним нашумевший T-Buffer). Несёт в себе всё необходимое для рендеринга кинематографических спец-эффектов у вас дома.
Вы спросите: что же нужно начинающему кинематографу? Всё просто. Начинающему кинематографу потребуется только самое необходимое: 128-битная точность представления данных для работы с плавающей точкой и полностью программируемый графический конвеер с поддержкой Shader Model 2.0, позволяющий наложить до 16 текстур. Заинтригованы? Да, этого есть здесь:
- 64/128 bit depth rendering — the Dawn of Cinematic Computing
В мире труколора такое маркетинговое заявление звучало бы несколько странно. Всем несведующим сообщу лишь, что с этого момента тусклый мир труколора остался в прошлом. И, если вы до сих пор думаете, что все новые игры рендерят изображение в 32-битном цвете… Вы, конечно, правы… Лишь отчасти. Потому что, на самом деле, многие (если не все) «части» в играх теперь просчитываются на пути к вашему монитору с сильно большей точностью, получившей название Floating Point Color Accuracy.Разумеется, я не поверил. И, как оказалось, не поверил не я один, потому что в сети нашлась даже такая нужная программулина ShaderMark 2.1, которая, как следует из названия, была создана именно для этого самого: тестирования производительности шейдерных блоков gpu. И вот, представьте себе, действительно есть разница не только в скорости, но и в цвете с разными пресетами точности! Качество при конвертации шотов в gif, конечно, упало, но менее не тем «исправленному верить»:
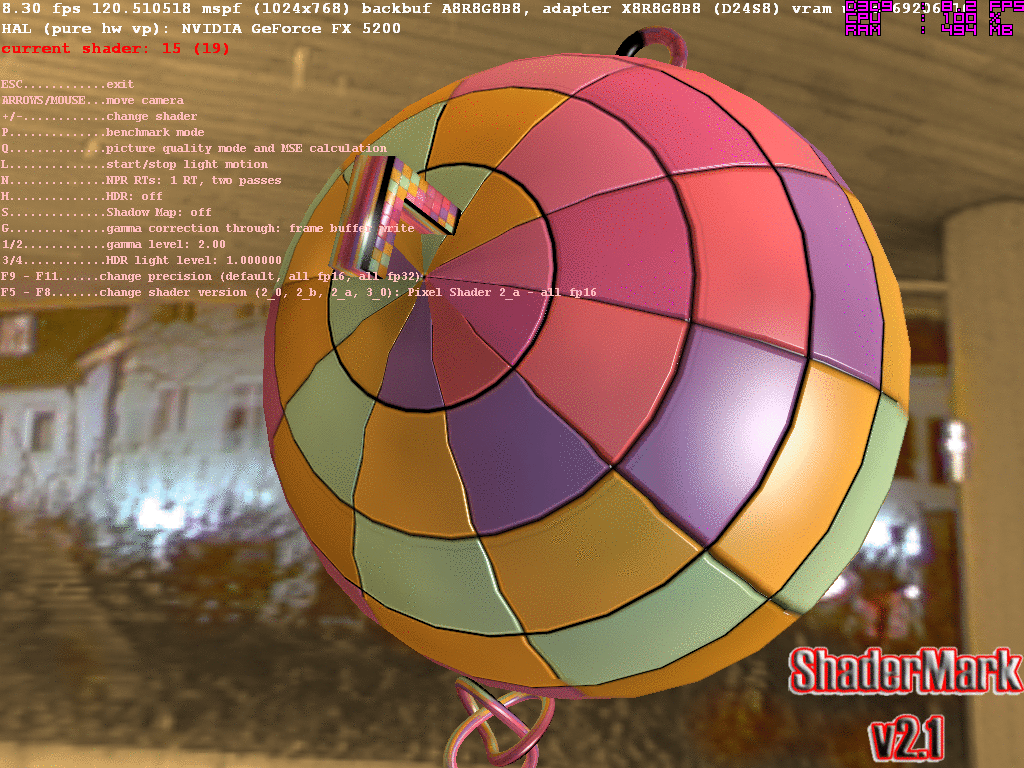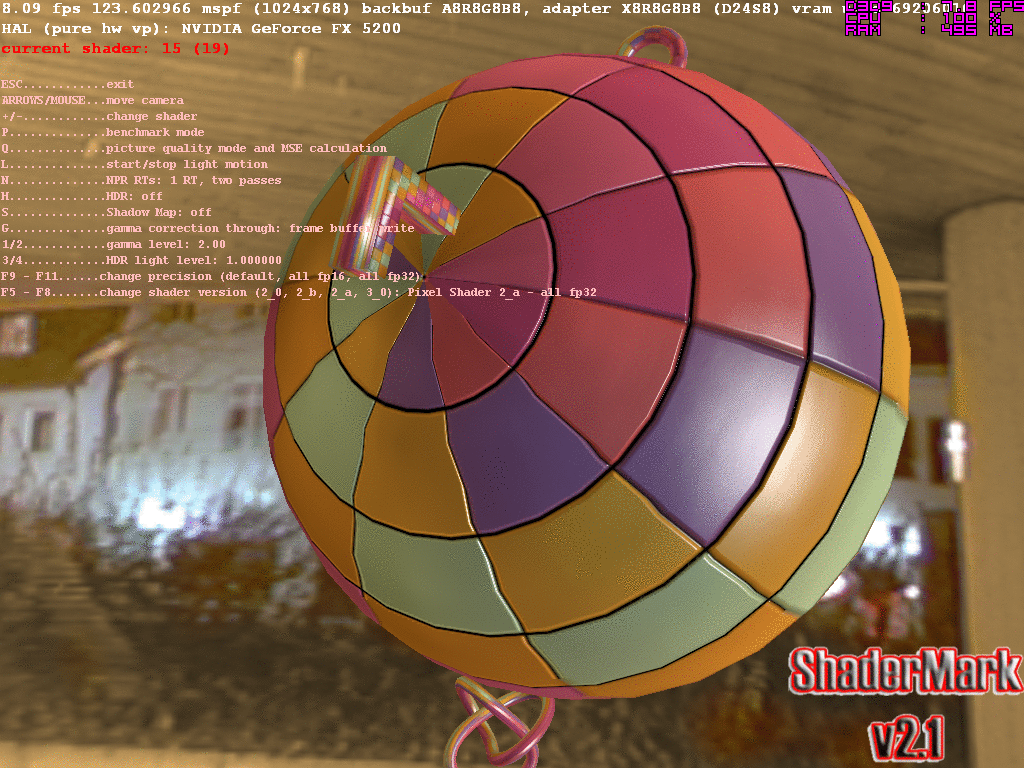
Но главное, именно благодаря такой разрядности графического конвеера, мы наконец смогли наблюдать киношную графику в играх. Суть HDR-рендеринга не только в тупом просчёте пикселей с точностью до тысячных. HDR-рендеринг — это прежде всего адаптивное освещение.
Кому лень читать, я покажу
На анимации выше вы можете наглядно наблюдать эффект, который называется Tone mapping. Тут всё как в жизни: когда многоуважаемый Мистер Фримен смотрит прямо на источник света (солнце), оно кажется ему очень ярким, а всё окружающее от этого кажется сильно темнее солнца. Когда же многоуважаемый Мистер Фримен соизволит неспеша отвернуть голову (в сторону), его глаза постепенно привыкают к новому балансу яркости: теперь уже солнце находится несколько сбоку и не кажется таким уж ярким, а всё остальное становится ярче.
Кстати, что ещё важно отметить: благодаря тому, что теперь весь графический конвеер в GeForce FX работает как минимум с точностью FP16, даже старые игрушки (где активно применялся мультитекстуринг и прочие техники, требующие операции смешивания цветов пикселей в кадре) будут выглядеть качественнее.
- Shader Model 2.0+
Да-да, это те самые пресловутые «шейдеры», благодаря которым вам в своё время наверняка приходилось идти в магазин менять свою видеокарту или только что купленную игру. Для начала давайте определимся: эти самые шейдеры… да кому они вообще нужны?
Ответ на этот вопрос в общем случае будет зависеть от контекста, в котором он задаётся, т. к. термин «шейдеры» вообще многозначен. По обыкновению для начала предлагается определиться с тем, для чего они нужны. То есть, если высказывание «шейдеры — это программы для затенения» для вас целиком олицетворяет шейдеры, настоятельно рекомендую вам прочесть хотя бы вот это:очень упрощённое представлениеДо того, как мы с вами двинемся по конвееру, вот вам его алгоритм:
Даже, если вы нэ бельмэ, полагаю, уже догадались, что есть два варианта обработки геометрии сцены и её прорисовки: с шейдерами и без… Окей, а теперь немного истории.
Что было до шейдеров?
На заре развития 3D-рендеринга было принято решение жёстко стандартизировать 3D-пайплайн (он же — »Графический конвеер»). Таким образом, видеокарты можно было рассматривать как «pixel-blaster’ы», потому как всё, что они тогда делали — это ели команды драйвера и выплёвывали вам на экран пиксели. В результате разработчики игр (гейм-девелоперы) были жёстко ограничены лишь теми возможностями рендеринга, которые предоставлял им тот или иной видеочип.Скажем, наглядно ситуацию можно было посмотреть в Unreal или в Quake II, в каждом из которых есть на выбор несколько API (API — программный интерфейс для «рисования» видеокартой).
Так вот, например, в Quake II при выборе API OpenGL использовались аппаратные 3D-возможности видеочипа. Таким образом, в этом случае видеочип самостоятельно будет накладывать текстуры на объекты и рассчитывать спецэффекты. И всё в игре было красиво, вот только вода выглядела похожей на стекло:

John Carmack предлагал вам альтернативный вариант: API Software, который использовал центральный процессор (CPU) вместо видеокарты для расчёта эффектов и наложения текстур. В этом случае в игре можно было реализовать абсолютно произвольные спецэффекты, а видеокарта только рисовала уже готовые пиксели. Красок особенно не видать (ведь затратно!), но вот вода была подвижной (имитация волн). Обратите внимание на искажение дна или стены на горизонте:

Почему? Всё дело было в стандартизации графического конвеера видеокарт. В каждый конкретный видеочип был жёстко вшит определённый набор фич, например, спец-эффектов. Точно такой эффект подвижных волн было невозможно получить, используя аппаратный 3D-рендеринг (возможно, можно было получить схожий, но не такой же).
Чего ещё не было до шейдеров?
Абсолютной власти (над конвеером)! В те годы использовать, скажем, эффект bump-mapping (рельефное текстурирование) чипа вы могли, но чип сделает его только по вершинам фигуры. И этот алгоритм изменению не подлежит! То есть, вы получите только то, что чип умеет делать.Рассмотрим на примере любимого доната и DX6-видеокарты Voodoo, которая не умеет шейдеры:
Вот донат, состоящий из 20 000 полигонов:

Вот Voodoo набросал на него текстуру:

А вот, что будет, если Voodoo наложит на него эффект рельефного текстурирования:

Красиво? Это потому, что полигонов, из которых сделан наш бублик, достаточно много. Но это сильно уменьшает скорость прорисовки (FPS). А чего мы хотим, так это прежде всего её увеличить. Чтож, придётся уменьшить количество полигонов до 1352:

Отлично, вот он — наш свежеиспечённый бублик:

Теперь вуду наложит ему рельеф:

Видите, как рельеф «поехал» по ближнему к вам краю? Т.е. с уменьшением количества полигонов FPS растёт, но рельефное текстурирование на вуду начинает выглядеть хуже. Потому что применяется оно по вершинам полигонов, которых здесь сильно меньше.
Так как же нам получить более приемлемый результат, не увеличивая количество вершин? Для этого нам нужно применить bump-mapping по-пиксельно. На данной видеокарте это невозможно, так как она не умеет шейдеры. Конечно, вы всё ещё вольны сделать по-пиксельный bump-mapping программным путём через CPU (не используя аппаратные возможности видеочипа). И это будет ой как медленно, знаете…
Всё это и привело к тому, что вскоре в 3D-индустрии придумали шейдеры и постепенно начали внедрять их в графический конвеер.
Что именно дают нам шейдеры?
Как вы, верно, уже догадались, шейдеры позволяют нам получить некоторый контроль над тем, как именно видеочип применит тот или иной спец-эффект. Если быть точным, то стало возможным даже применять абсолютно любые спец-эффекты силами видеочипа, а не CPU. Таким образом, шейдеры потенциально дают нам возможность рендерить точно те эффекты, которые мы хотим получить. А также многое другое, но об этом здесь не будем.Какие они — эти шейдеры?
Существует множество версий и типов этих самых шейдеров. Версии обычно характеризуются как Shader Model x.x (например, SM2.0), а самые распространённые типы шейдеров — это пиксельные, вершинные и геометрические. Очевидно, чем выше поддерживаемая версия SM, тем более абсолютную власть чип нам предоставит. А оперировать этой властью вы сможете с помощью программирования.То есть, с точки зрения гейм-девелопера, шейдер — это некий написанный им программный код, объясняющий видеочипу, что ему нужно будет сделать, например, с конкретным полигоном в сцене. Вдобавок, шейдерные программы могут вычислять (и очень часто это делают в играх) какие либо сложные математическе уравнения с целью дальнейшего использования полученных значений. То есть совершенно необязательно, что каждая шейдерная программа что-нибудь вообще «затенит».
Как бы там ни было, шейдеры прочно вошли в нашу жизнь и начали всё больше развиваться. В частности в NV30 поддержка Shader Model 2.0 (далее SM2.0) — это обобщённый термин, означающий, что NV30 теперь поддерживает спецификации Pixel & Vertex Shaders 2.0. Но NVIDIA на этом не остановились и тот самый »плюс» в названии был призван прибавить свободы гейм-девелоперам за счёт расширения спецификации DX9 до полигонов возможностей.
Всё это очень интересно… скажете вы, но как же вообще эти шейдеры использовать? Ну, а тут всё ещё интереснее:)
С появлением SM2.0 для обоих видов шейдеров (пиксельные и вершинные) стало возможным писать достаточно сложные программы с условиями и циклами. Вопрос только в том, на каком языке вы предпочитали это делать. В эпоху SM1.x выбор был невелик и писали в основном на ARB assembly или на DirectX ASM, которые, как становится ясно даже из названий, являются низкоуровневыми и достаточно сложными в освоении и применении. С приходом же SM2.0 появилось как минимум три C-подобных языка высокого уровня, писать шейдерные программы на которых значительно проще:
- OpenGL Architecture Review Board разработали GLSL;
- NVIDIA разработала C for Graphics (причём не только для себя);
- Microsoft разработала HLSL.
Но какой из языков шейдеров предпочесть и что от этого зависит? С такими нюансами, увы я не познакомлю. Давайте лучше вспомним о реализации этих самых шейдеров в NV30.
Реализация
Большинство мирных дискуссий о производительности того или иного девайса чаще всего так или иначе сваливается в холивар на тему «Что же важнее: Железо или Софт? » На самом деле, как бы многим не хотелось уйти от реальности, но железо без софта — оно железо и есть :)
На момент выхода GeForce FX 5800 (NV30) на дворе уже более квартала забавлялся конкурент в лице Radeon 9700 Pro (ATI R300). Это был февраль 2003 года. Сегодня такое промедление смерти подобно, и вот именно поэтому можно смело назвать 2003 год не иначе, как годом NVIDIA.
Было примерно так: Приходит NV30 на биржу труда, а там в списке вакансий ни одной со знанием DirectX9 и нет. Получается, что NV30 как бы никуда и не опаздывал вроде… И правда, первые сколько-нибудь известные мощные игры под DX9 (такие как DooM3, HL2, NFS Underground 2) появились лишь в 2004 году. Долгожданный Сталкер так и то аж в 2007 году.
Это я всё к тому, что сравнивать производительность карт обзорщикам в 2003 году было просто не в чем. Буду откровенным: при написании статьи я долго анализировал картину, но так и не встретил ни единого обзора NV30 с живыми тестами DX9. В основном возможности DX9 тестировали в 3DMark…

Суть:
…
NVIDIA debuted a new campaign to motivate developers to optimize their titles for NVIDIA hardware at the Game Developers Conference (GDC) in 2002. In exchange for prominently displaying the NVIDIA logo on the outside of the game packaging, NVIDIA offered free access to a state-of-the-art test lab in Eastern Europe, that tested against 500 different PC configurations for compatibility. Developers also had extensive access to NVIDIA engineers, who helped produce code optimized for NVIDIA products…
en.wikipedia.org/wiki/GeForce_FX_series
В итоге всё это, как и любая другая благотворительность, породило увлекательную драму… Вкратце, если на NV30 свернуть с рельс в 3DMark 2003 (нужна девелоперская версия), можно было запросто увидеть результаты таких оптимизаций:

Можно предположить, что оптимизации заключались в том, чтобы не рисовать то, чего не должно быть видно на рельсах. А можно предположить, что всё дело в плохо отлаженной оптимизации исполнения шейдерного кода в драйверах, о которой ниже поговорим тоже.
… Кстати ATI тоже была замечена за подобными оптимизациями в то же время. Тем не менее, всё вышеназванное ещё можно было назвать таковыми, если сравнивать с тем, с чего вообще всё начиналось:

Как следствие, в те годы очень часто можно было слышать что-то навроде:
…
NV30's apparent advantages in pixel processing power and precision might make it better suited for a render farm, which is great for Quantum3D, but these abilities may mean next to nothing to gamers. Developers tend to target their games for entire generations of hardware, and it’s hard to imagine many next-gen games working well on the NV30 but failing on R300 for want of more operations per pass or 128-bit pixel shaders.
…
techreport.com/review/3930/radeon-9700-and-nv30-technology-explored/6
И, хотя тот же John Carmack запросто поспорил бы с этим утверждением, в любом случае, это наглядное подтверждение того, что железо — ничто без софта. Более того, на деле выяснилось, что производительность шейдеров у NV30 была катастрофически зависима в первую очередь от того, как написан код шейдерных программ (важна даже последовательность инструкций). Вот тогда-то NVIDIA и стала всячески продвигать оптимизацию кода шейдеров под NV30.
Зачем это было нужно? А затем, что у NV30 с реализацией шейдеров не всё так просто:
…
Its weak performance in processing Shader Model 2 programs is caused by several factors. The NV3x design has less overall parallelism and calculation throughput than its competitors. It is more difficult, compared to GeForce 6 and ATI Radeon R3×0, to achieve high efficiency with the architecture due to architectural weaknesses and a resulting heavy reliance on optimized pixel shader code. While the architecture was compliant overall with the DirectX 9 specification, it was optimized for performance with 16-bit shader code, which is less than the 24-bit minimum that the standard requires. When 32-bit shader code is used, the architecture’s performance is severely hampered. Proper instruction ordering and instruction composition of shader code is critical for making the most of the available computational resources.…
en.wikipedia.org/wiki/GeForce_FX_series
То есть, архитектура NV30 не давала ему полностью раскрыть себя, используя код стандарта SM2.0. Но вот, если немного перетасовать инструкции перед выполнением, может быть, даже заменить одну на другую (привет, 3DMark 2003)… Но в NVIDIA понимали: гораздо эффективнее бороться с причиной, а не с последствиями.
Take Two. NV35: The Dusk
Это не было новым архитектурным решением, но очень грамотным усовершенствованием. Инженеры NVIDIA так фанатично исправляли свои ошибки, что даже попутно наследили в истории развития шейдеров официально задокументированной Shader Model 2.0a (SM2.0a), которая так и была названа — NVIDIA GeForce FX/PCX-optimized model, DirectX 9.0a. Панацеей NV35, конечно, не стал, но его запомнили:

Впрочем, в силу той самой чрезвычайной сложности микроархитектуры NV30 некоторые весьма любопытные нюансы в NV35 остались без изменений. Поэтому в его спецификациях обзорщики часто указывали что-то навроде:
Vertex pipeline design: FP Array
Pixel pipeline design: 4×2
Вот это — и есть те самые «простейшие составляющие», о которых я упоминал ещё в начале статьи. Да, терминология несколько странная, но это ещё полбеды. На самом деле таким образом маркетологи просто пытались донести до нас простейшие вещи: сколько же вершинных и пиксельных конвееров (шейдерных блоков, если хотите) есть у чипа.
Как и у любого нормального человека, прочитавшего такую спецификацию, моя нормальная реакция: ну так и сколько же их? Так вот вся штука в том, что этого никто не знает :) Казалось бы, самые ординарные характеристики графического чипа, по которым сразу можно было бы сделать какие-то выводы о производительности?
Ну да, вон у того же ATI R300 всё прозрачно: 8 пиксельных и 4 вершинных шейдера… Ок, можно было бы запустить тот же GPU-Z и он, следуя устоявшейся терминологии, сказал бы вам, что у NV35 против этого имеется всего 4 пиксельных и 3 вершинных шейдера. Но это было бы не совсем точно, потому что на заре киноигр у NVIDIA был свой
Начнём с Vertex pipeline — конвеера с вершинными блоками.
В спецификации выше видимо неслучайно упоминается термин »design», потому что:
…
Whereas the GeForce4 had two parallel vertex shader units, the GeForce FX has a single vertex shader pipeline that has a massively parallel array of floating point processors
…www.anandtech.com/show/1034/3
Да, похоже на то, что чип (NV35) был спроектирован таким образом, чтобы максимально эффективно справляться с задачами, распределяя свободные транзисторы в зависимости от востребованности. Т. о., если в NV35 есть три больших отсека с вершинными блоками, то каждый такой отсек можно трансформировать как угодно: можно объединить все силы и задействовать «как бы один мощный вершинный процессор», а можно распараллелить задачи, разделив отсек на несколько блоков. Таким образом, сколько точно будет задействовано вершинных блоков зависит от случая :) Минимальное же их число в NV35 — 3. Между прочим, даже випипипендия намекает!
…
The GeForce FX Series runs vertex shaders in an array…
en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units#GeForce_FX_.285xxx.29_Series
Pixel pipeline.
Если сведения о Vetrex pipeline по крайней мере оглашались самими NVIDIA, то здесь всё несколько интереснее. Изначально NVIDIA заявляли, что вышедший NV30 имеет 8 пиксельных конвееров, и у каждого из них по одному TMU (текстурному блоку). Это и называется »8×1 design» Однако почти сразу же после выхода были проведены интригующие независимые расследования, отмечавшие явное несоответствие реальной скорости заполнения экрана пикселями заявленной в спецификации. Мне несколько удивительно было узнать о подобных расследованиях, но людей можно было понять: ведь больше делать с DX9-картами тогда было нечего…
Так вот, после интриг и расследований всё же выяснилось, что «дизайн» пиксельных конвееров у NV30/NV35 на самом деле 4×2 (4 пиксельных конвеера по 2 TMU на каждом). Всё это сами NVIDIA косвенно подтвердили таким заявлением:
…
«Geforce FX 5800 and 5800 Ultra run at 8 Pixels per clock for all of the following:a) z-rendering
b) Stencil operations
c) Texture operations
d) shader operationsFor most advanced applications (such as Doom3) most of the time is spent in these modes because of the advanced shadowing techniques that use shadow buffers, stencil testing and next generation shaders that are longer and therefore make apps «shading bound» rather than «color fillrate bound. Only Z+color rendering is calculated at 4 pixels per clock, all other modes (z, stencil, texture, shading) run at 8 pixels per clock. The more advanced the application the less percentage of the total rendering is color, because more time is spent texturing, shading and doing advanced shadowing/lighting»
…
www.beyond3d.com/content/reviews/10/5
Но даже этого исповедования фанатикам не хватило и последовали скандалы и, как следствие, шокирующие интервью с чистосердечными признаниями:
…
Beyond3D:
We’ve seen the official response concerning the pipeline arrangement, and to some extent it would seem that you are attempting to redefine how 'fill-rate' is classified. For instance, you are saying that Z and Stencils operate at 8 per cycle, however both of these are not colour values rendered to the frame buffer (which is how we would normally calculate fill-rate), but are off screen samples that merely contribute to the generation of the final image — if we are to start calculating these as 'pixels' it potentially opens the floodgates to all kinds of samples that could be classed as pure 'fill-rate', such as FSAA samples, which will end up in a whole confusing mess of numbers. Even though we are moving into a more programmable age, don’t we still need to stick to some basic fundamental specifications?Tony Tamasi:
No, we need to make sure that the definitions/specifications that we do use to describe these architectures reflect the capabilities of the architecture as accurately as possible.Using antiquated definitions to describe modern architectures results in inaccuracies and causes people to make bad conclusions. This issue is amplified for you as a journalist, because you will communicate your conclusion to your readership. This is an opportunity for you to educate your readers on the new metrics for evaluating the latest technologies.
Let’s step through some math. At 1600×1200 resolution, there are 2 million pixels on the screen. If we have a 4ppc GPU running at 500MHz, our «fill rate» is 2.0Gp/sec. So, our GPU could draw the screen 1000 times per second if depth complexity is zero (2.0G divided by 2.0M). That is clearly absurd. Nobody wants a simple application that runs at 1000 frames per second (fps.) What they do want is fancier programs that run at 30–100 fps.
So, modern applications render the Z buffer first. Then they render the scene to various 'textures' such as depth maps, shadow maps, stencil buffers, and more. These various maps are heavily biased toward Z and stencil rendering. Then the application does the final rendering pass on the visible pixels only. In fact, these pixels are rendered at a rate that is well below the 'peak' fill rate of the GPU because lots of textures and shading programs are used. In many cases, the final rendering is performed at an average throughput of 1 pixel per clock or less because sophisticated shading algorithms are used. One great example is the paint shader for NVIDIA’s Time Machine demo. That shader uses up to 14 textures per pixel.
And, I want to emphasize that what end users care most about is not pixels per clock, but actual game performance. The NV30 GPU is the world’s fastest GPU. It delivers better game performance across the board than any other GPU. Tom’s Hardware declared «NVDIA takes the crown» and HardOCP observed that NV30 outpaces the competition across a variety of applications and display modes.
…
www.beyond3d.com/content/reviews/10/24
Так как же так вышло?
Здесь я даже могу предложить вам своё видение вопроса…
В очередной раз разгромив всех конкурентов на рынке, NVIDIA решили подойти к разработке DX9-чипа с размахом, ибо возможности позволяли. Архитектура чипа NV3x должна была стать самой обаятельной и привлекательной революционной и инновационной в истории:
- NV3x обязательно должен превзойти все требования спецификации DX9, пусть для этого понадобится очень много транзисторов… пусть даже слишком много!
- NV3x обязательно должен поднять рекордную планку рабочей частоты до 500МГц!
- Карты на NV3x должены оснащаться памятью DDR2!
На деле архитектурное решение, превзошедшее все требования DX9 и поднявшее планку рабочей частоты до 500 МГц, насобирало аж 125 миллионов транзисторов (по тем временам рекордная планка) в первом своём исполнении. С этой армией деталей нужно было что-то делать: грелась она непомерно. Приняли решение использовать техпроцесс 0.13 мкм (новаторский по тем временам), который снизил бы тепловыделение. Однако и этого оказалось недостаточно — пришлось применить для охлаждения пылесос.
Ладно, здесь пофиксили, как быть с памятью? Спецификаций DDR2 тогда ещё официально не было, но Samsung вызвался помочь: любой каприз за ваши деньги! В итоге были изготовлены дорогущие микросхемы DDR2, но вот беда: ширина шины памяти контроллера получилась 128 бит. Чем же это плохо?
Это не очень хорошо, потому что изначально планировалось, что NV3x будет иметь 8 честных пиксельных конвееров, по одному TMU на каждом (8×1). Однако в таком случае возникала бы проблема. Как известно, буфер кадра, в котором хранятся все выводимые пиксели, содержится именно в этой вот памяти видеокарты. Также мы знаем, что размерность типичного выводимого на экран пикселя = 32 бита.
Ежели у нас есть 8 пиксельных конвееров, то мы можем передавать в наш буфер кадра одновременно до 8-ми 32-битных пикселей (=256 bit) за один такт. Беда в том, что для этого нам потребуется пропускная способность шины памяти как минимум равная 256 бит. Но у нас в распоряжении только 128-битная шина памяти, что означает, что для передачи 8-ми 32-битных пикселей по этой шине нам потребуется два такта. Это называется переполнение шины и это потеря мнимых fps.
Как же выйти из положения? Да очень просто: оставить только 4 пиксельных конвеера, но каждому выдать по 2 TMU (4×2). Конечно, не только вам сейчас показалось, что вас где-то обманывают:
…
Beyond3D:
Our testing concludes that the pipeline arrangement of NV30, certainly for texturing operations, is similar to that of NV25, with two texture units per pipeline — this can even be shown when calculating odd numbers of textures in that they have the same performance drop as even numbers of textures. I also attended the 'Dawn-Till-Dusk' developer even in London and sat in on a number of the presentations in which developers were informed that the second texture comes for free (again, indicating a 2 texture units) and that ddx, ddy works by just looking at the values in there neighbours pixels shader as this is a 2×2 pipeline configuration, which it is unlikely to be if it was a true 8 pipe design (unless it operated as two 2×2 pipelines!) In what circumstances, if any, can it operate beyond a 4 pipe x 2 textures configuration, bearing in mind that Z and stencils do not require texture sampling (on this instance its 8×0!).Tony Tamasi:
Not all pixels are textured, so it is inaccurate to say that fill rate requires texturing.For Z+stencil rendering, NV30 is 8 pixels per clock. This is in fact performed as two 2×2 areas as you mention above.
For texturing, NV30 can have 16 active textures and apply 8 textures per clock to the active pixels. If an object has 4 textures applied to it, then NV30 will render it at 4 pixels per 2 clocks because it takes 2 clock cycles to apply 4 textures to a single pixel.
…
www.beyond3d.com/content/reviews/10/24
И вот здесь я с NVIDIA согласен, чёрт побери! Нельзя в эпоху шейдеров принимать во внимание тупое окрашивание пикселей, потому что это не есть показатель производительности. Гораздо важнее, сколько текстурных операций за такт успевает чип.
А теперь желающие могут взять в руки (у кого есть) свой Жираф FX, вдумчиво посмотреть на чип и произнести «Всё гениальное — просто!» Мне вся эта история очень напоминает логичного Хэппи Гилмора (Happy Gilmore), который »… единственный снял коньки, чтобы подраться!» :)

Как бы там ни было, если главной целью инженеров NVIDIA в те дни было ярко наследить в истории, — без сомнения, им это удалось! Более того, в NV35 появилась ещё одна интересная фишка, аналога которой у конкурентов не было: UltraShadow Technology, о которой, впрочем, позже:) Но давайте прекратим болтать о прекрасном и вернёмся
С небес на землю
К счастью, дастбастера у меня нет… (но поглазеть на музейный экспонат вы всегда можете). К счастью, потому что уши дороже. К тому же стоил он и его усовершенственный брат GeForce FX 5900 несоразмерно кошельку простого человека с простыми потребностями. А для таких людей NVIDIA предлагали варианты GeForce FX 5600 на чипе NV31, но мне и его не досталось.
И вот, волею случая, спустя 12 лет, мне, можно сказать, «втюхали» вот такой офисный огрызочек:

Зато не жужжит!
То есть, помимо урезанного NV31 был выпущен ещё и NV34, который отнюдь не отличался производительностью, а, скорее, был браком NV31.

Теперь кратко о том, чего интересного в NV34 не поместилось :(
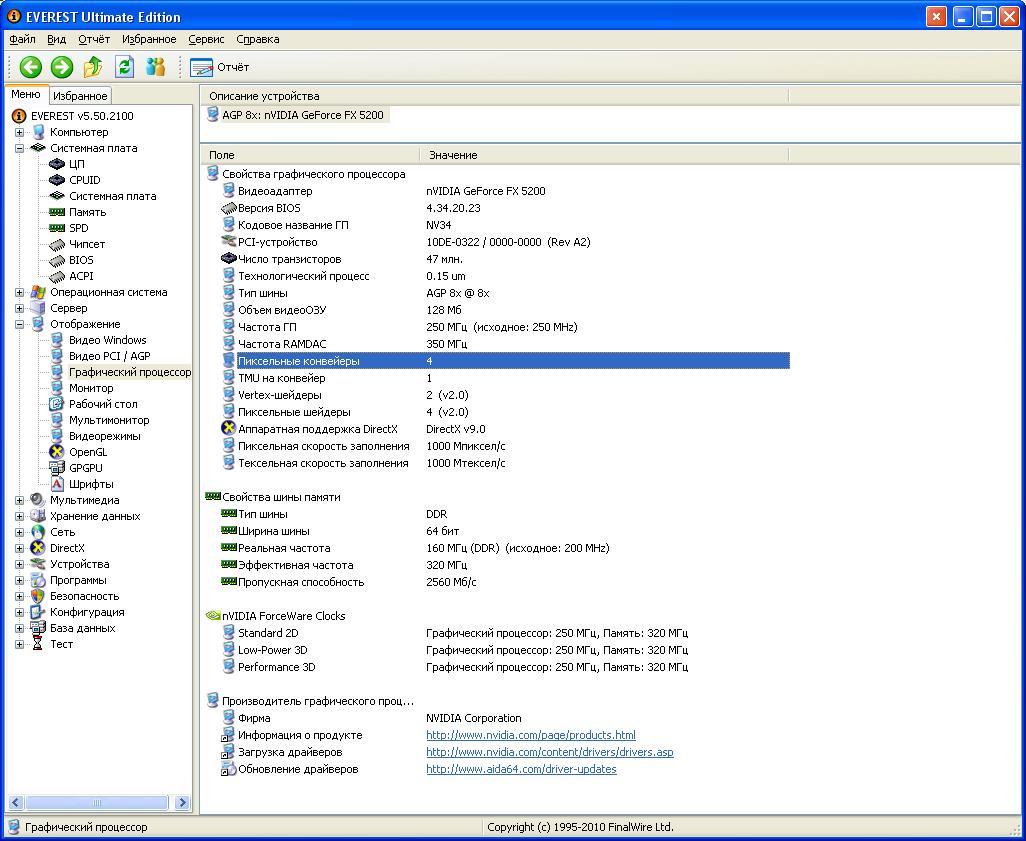
- NV30/NV35 имели 4×2 дизайн пиксельных конвееров, а тут осталось всего 4×1
- Что интересно, Everest и GPU-Z вам скажут, что Vertex-шейдеров у него 2 штуки, тогда как по википедии вроде бы 1. Вот вам и закрытая архитектура FP Array;)
- В NV30/NV35 ввели параноидальное сжатие всего, что только попадало на графический конвеер. Сюда входили не только текстуры, но даже z-buffer и значения цвета каждого пикселя в буфере кадра! Так вот в NV34 этот сложнейший алгоритм lossless-сжатия 4:1 не поместился :)
- UltraShadow Technology тоже не вошла (GeForce FX 5900 and 5700 models only). Но расстраиваться не стоит, всё покажу ;)
- Этот экземпляр имеет ширину шины памяти аж 64bit (да, как у старых 2D-видеокарт)
Как видно, не поместилось почти ничего :) Но самое страшное было даже не в этом. Все знают это слово.
Драйвера
Вот здесь сейчас очень многие из вас, должно быть, улыбаются. Это, наверное, была самая эпичная реализация после TNT2.
Если даже вы не помните это:

… то уж точно должны вспомнить это:

Что и говорить, с приходом DX9 вендоры стали штамповать драйвера с невероятной скоростью, а про WHQL вспоминали только в крайнем случае. Производительность одной и той же DX9-карты могла плясать так динамично, что порой её партнёром могла стать DX8-карта. Так было, например, с GeForce MX 440 (NV18), которому с определённой версии дров запилили эмуляцию аж SM2.0, но позже зарезали обратно. Ибо как-то неприлично получается: NV18 выигрывает у NV34 в шейдерах, которых у неё даже нет…
Вот, например, хорошая статистика популярных траблов с GeForce FX.
И тем не менее, было чем гордиться. Например:
-
Adaptive Texture Filtering
К слову сказать, из всего огромного множества обзоров NV30 в 90% при тестировании использовали анизотропную фильтрацию вкупе с трилинейной! Сначала это показалось мне какой-то массовой эпидемией. Ну, то есть, я понимаю, что в виду столь долгих ожиданий хотелось выжать из карты всё до последней капли, но о практическом смысле тоже надо было как-то подумать?Однако всё оказалось намного интереснее. Копнув глубже, можно было уяснить себе две вещи: есть общепринятые стандарты фильтрации текстур, а есть такие «адаптивные» вещи, как, например, Intellisample. Поскольку в данном случае алгоритм той или иной фильтрации задаётся драйвером, то тут у NVIDIA был ещё один полигон возможностей. Производительность и качество фильтрации текстур различались практически с каждой новой версией дров…
Что интереснее, во всех обзорах тех дней часто можно было найти сравнение алгоритмов работы так жадной до fps анизотропки у ATI и у NVIDIA. Так вот ATI ещё более преуспели на данном поприще: они не только действительно использовали трилинейную фильтрацию вкупе с анизотропной (не поверите: ради экономии!), но даже умудрились придумать гибридный термин: brilinear filtration.
И в общем-то те же ATI были правы: если не видно разницы,- зачем платить больше? Понятно, если у меня бюджетная карта, я буду рад дополнительным 10 кадрам без видимой потери качества. Однако этот замечательный принцип почему-то распространялся и на топовые чипы (NV30 / R300), тогда как вот здесь-то нам хотелось бы получить лучшую в мире картинку. «Да, все эти оптимизации должны быть отключаемыми» — твердили тогда обозреватели. Вендоры же были непреклонны и с каждой версией алгоритмы становились всё бесплатнее и оптимизированнее. В ответ на такое наплевательское отношение к покупателям дорогих карт был выдвинут такой транспарант:

»As long as this is achieved, there is no «right» or «wrong» way to implement the filtering…»
Конечно же, все драйвера тестировать я не стал, ибо нахожу это абсолютно бессмысленным занятием. Хотя
