Вопросы, которые я бы хотел услышать на техническом собеседовании
Я занимаюсь разработкой больше 10 лет, прошел множество разных собеседований на самые разные позиции, и вот какая мысль сегодня пришла мне в голову. Ни на одном собеседовании мне не задавали вопросов, которые бы действительно осветили мой опыт и знания, а главное — ценность как сотрудника, эффективно решающего задачи.
На написание статьи меня подтолкнула собственная боль, пронесенная через года, размышления о роли Google и GPT в работе программиста и старый анекдот про инженера и объем резинового мяча.
Анекдот
Физику, математику и инженеру дали задание — найти объём красного резинового мячика. Физик погрузил мяч в стакан с водой и измерил объём вытесненной жидкости. Математик измерил диаметр мяча и рассчитал тройной интеграл. Инженер достал из стола свою «Таблицу объёмов красных резиновых мячей» и нашёл нужное значение.
КДПВ взята с devhumor
Большинство алгоритмов, паттернов проектирования и прочих стандартных решений (и даже критерии их выбора под конкретную ситуацию) сегодня можно найти в интернете, а еще проще — попросить ChatGPT сгенерировать код. Именно поэтому я считаю, что наличие этих знаний у современного разработчика сильно переоценено. Хороший инженер всегда знает, какой справочник нужно использовать.
Однако есть класс прикладных (особенно с точки зрения бизнеса) задач, которые не решаются одним лишь справочником, а требуют определенного набора знаний и опыта. Именно эти задачи и определяют программиста как эффективного сотрудника, и именно вопросы о них я бы хотел слышать (и задавать) на собеседованиях. Кроме того, я верю, что человек, который ответил для себя на эти вопросы, действительно является хорошим программистом уровня Middle+. Я постараюсь не давать свои ответы на эти вопросы, так как абсолютно правильного ответа чаще всего нет — все зависит от конкретной ситуации и команды.
Так как большинство моего опыта связано с Java и Web-сервисами, заранее извиняюсь за возможный перекос в эту сторону.
Дизайн и архитектура
Основная цель этих вопросов — понять, насколько разработчик умеет работать в команде и грамотно расходовать ресурсы (время и деньги) компании. Оптимальная скорость и удобство разработки часто определяется тем, насколько сложен код в чтении и поддержке.
Когда стоит закладывать в код расширяемость, а когда нет?
Никто не любит слишком большого количества абстракций. Хороший разработчик должен понимать, а еще лучше — уметь спрашивать у руководителя (Product Owner-а, например), какие планы по развитию функциональности у приложения, которое он разрабатывает. Нет смысла использовать фабрики фабрик, мудреные стратегии и фасады, если код предполагается написать один раз и лишь поддерживать в дальнейшем. Пример — утилиты, скрипты командной строки, миграции. И наоборот, хорошим тоном будет заложить расширяемость в те места, которые предполагается развивать в будущем. Даже если не планируется развивать, но есть прогноз на интенсивное использование — стоит это сделать, так как в дальнейшем с увеличением кодовой базы, резко возрастает цена поддержки и модернизации. Сервисы, комплексные фронтенды, API, библиотеки — в них стоит продумать точки расширения, едва написав первую абстракцию.
Как бы вы распределили код по пакетам/модулям/директориям?
Все современные языки в том или ином виде поддерживают такую возможность, и при работе в команде крайне важно ее правильно использовать. Об это сломано много копий, но в целом можно выделить две концепции распределения кода: по техническому назначению и по доменной принадлежности. Важно понимать, какую концепцию лучше использовать в разработке конкретного приложения и исходя из целей и привычек команды. Так, например, вынесение по техническому назначению очень хорошо (на мой взгляд) подходит микросервисам и небольшим приложениям. Монолитный же сервис есть смысл организовать по доменам — таким образом, чтобы код, связанный по смыслу, находился рядом.
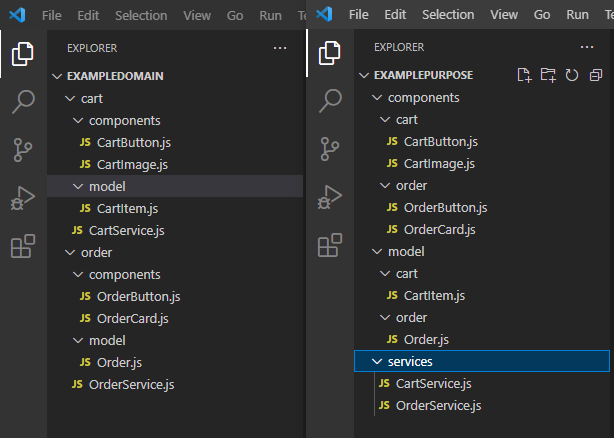
Описываемые подходы в иерархии
Как использовать чистые функции и функции с состоянием?
Чистая функция — это функция, которая принимает входные данные и возвращает результат, не меняя глобальное состояние программы (состояние между вызовами). Часто их использование связано с дополнительными расходами памяти, однако делает программу более читаемой. Промежуточное хранимое состояние в свою очередь часто позволяет повысить производительность, но при этом создает дополнительные ограничения и взаимосвязи. Так, например, разнообразные лексеры и парсеры часто реализованы с сохранением состояния в объекте (паттерн «Посетитель») и поэтому ограничены в многопоточном использовании, например, многострадальный java.util.DateFormat. В то же время, чистые функции могут быть использованы без опасений.
Большинство остальных вопросов, таких как конкретные архитектуры и их применения, я считаю слишком частными. В дальнейшем я еще вернусь к дизайну и архитектуре, но это произойдет в рамках блока о качестве и тестировании.
Логирование и диагностика
Здесь мы снова возвращаемся к вопросу эффективного использования ресурсов. Большинство самых трудоемких задач относятся к диагностированию и разбору ошибок. Вне зависимости от того, как в компании организован сбор, хранение и анализ логов, разработчику важно понимать, как он может ускорить диагностику проблем бизнеса в случае сбоев.
На каком этапе необходимо закладывать возможности диагностики?
В общем случае, чем раньше — тем лучше. Я встречал множество разработчиков, которые добавляют логирование только тогда, когда что-то сломалось в продакшне. Чем раньше мы заложим возможности диагностики и выработаем культуру логирования, тем меньше будут расходы на диагностику в будущем.
Что и на каких уровнях логировать?
В разных средах и в разных ситуациях нужно понимать, что логировать и на каком уровне. Так, в боевом окружении довольно часто включено логирование только на уровне информации (в целях повышения производительности), а на тестовой среде — добавлено отладочное логирование. Однако информационные сообщения в стиле «Job completed» часто не помогают в диагностике, а только раздражают. Разработчик должен уметь оценивать количество данных, которые он хочет использовать в диагностике на каждом окружении. В то же время, если писать в информационные сообщения все параметры, переданные методу, это может вызвать накладные расходы (например, на строковое представление и сериализацию), поэтому такие сообщения нужно выносить в уровень отладки или трассировки.
Что такое сквозная трассировка идентификаторов и как ее использовать?
В многопоточных приложениях, таких как Web-сервисы, не всегда можно абсолютно точно идентифицировать, какие сообщения лога относятся к каким операциям. В Java, например, для этого служат MDC/NDC. Они позволяют задать сквозные идентификаторы, которые в дальнейшем позволяют сгруппировать сообщения лога в рамках одного конктекста (в базовом случае — потока). В асинхронных средах (таких как реактивные фреймворки с переиспользованием потоков) это может быть реализовано сложнее, но это не умаляет важность использования сквозных идентификаторов. Программист должен уметь выбрать идентификаторы и знать как настроить их сквозную трассировку.
Как организовать вывод ошибок пользователю?
Важно понимать, какая информация должна показываться конечному пользователю, обеспечить возможность предоставить технические детали поддержке и ускорить диагностику. Если мы говорим о трассировке стека, важно понимать, насколько доступ пользователя к трассировке может подвергнуть приложение возможности реверс-инжениринга и проникновения. Есть разные пути предотвратить это и при этом не усложнять диагностику: уникальные идентификаторы сообщений (в случае серверов), коды ошибок, уникальная формулировка сообщений. Выбор способов зависит от конкретного приложения и среды запуска.
Качество и тестируемость кода
В этом блоке вопросов я уделяю больше всего внимания двум аспектам. Во-первых, это конкретно юнит-тесты, так как из всего многообразия уровней тестирования, именно за юнит-тесты чаще всего отвечает непосредственно разработчик, и именно с неумением их проектировать и писать связано большинство проблем. Во-вторых, это взаимодействие с отделом контроля качества при проведении остальных видов тестирования.
Что такое тестируемость кода и как ее обеспечить?
В общих чертах, тестируемость кода — это количество трудозатрат на написание тестов. Код, который спроектирован с учетом необходимости писать тесты, потребует меньших трудозатрат на их написание. Существует множество подходов к написанию собственно тестов (тот же TDD, к примеру), и выбор конкретного подхода не является сутью этого вопроса. Здась гораздо важнее поговорить об архитектуре приложения, разбиении его на отдельные изолированные блоки. Так, с большой вероятностью, человек, который озабочен тестируемостью своего кода, следует принципам SOLID автоматически. На примере Web-приложения тестируемость проявляется в разделении REST-контроллеров, сервисов, трансформеров и слоя доступа к данным. Если вся логика (даже самая правильная) сложена в REST-контроллер, тесты будут максимально комплексными и трудозатратными. С другой стороны, при грамотном разбиении на функциональные части, можно отбросить (поставить заглушки) на каждый из слоев и протестировать, например, бизнес-логику, доступ к данным и соблюдение REST-контракта, по отдельности. Такие тесты будут небольшими, изолированными и простыми в поддержке.
Как можно приоритизировать тесты? Что покрывать в первую очередь?
Как правило, наибольшие проблемы возникают там, где имеются неконтролируемые входные данные. Пользовательский ввод, данные третьих систем при интеграции — все это потенциальный источник проблем. С другой стороны, крайние ситуации (corner cases) в бизнес-логике так же часто являются неочевидными. Разработчик должен понимать, с какой системой он работает, и в зависимости от этого выбирать, какую ее часть наиболее экстенсивно покрыть тестами. Очень хорошо, если есть возможно согласовать покрытие юнит-тестами с отделом тестирования, подключить аналитиков для выявления нестандартных ситуаций и реакций на них. Очень часто тестами покрываются только позитивные сценарии, но важно правильно приоритизировать и протестировать так же поведение в негативных.
Ревью кода и работа в команде
Очень часто про это так же забывается, как и про тестирование. Однако ревью кода повышает уровень взаимодействия в команде и общее качество продукта (хотя оно и отбирает время на первый взгляд, в долгосрочной перспективе это не так).
На что вы обращаете внимание при ревью кода в первую очередь?
Мы все люди, у каждого свой уровень и свой способ мышления. Возможно, разработчик, который зацепляется за выбор библиотеки, но игнорирует покрытие тестами, привнесет в процесс ревью больше токсичности, чем реальной пользы. Что действительно важно в процессе ревью — это понимание разработчика, что для команды важнее на этом этапе, как сформировать культуру кода, которая будет устраивать всех. Правильно расставленные приоритеты при ревью существенно повышают общую эффективность.
Общий вывод
Я довольно часто слышу на собеседованиях вопросы про HashMap/TreeMap, различные реализации List и основы JDBC, даже на вакансии уровня Senior. Все это безусловно важно, но инженер уровня Middle+ должен обладать этими знаниями по умолчанию. В конечном счете, в большой бизнес-машине важна именно производительность сотрудника и его экономичность. Все выливается не в конкретные знания библиотек, особенностей, алгоритмов, а в способность писать читаемый, поддерживаемый и масштабируемый код, который может быть передан любому другому сотруднику без потери его (любого сотрудника) производительности.
А что вы бы добавили/изменили в этом списке?
