Вносите изменения в код понемногу

Всегда было любопытно узнать, что и как думают кодеры за океаном? Логично предположить, что техническое мышление и основные процессы должны быть схожими с российскими разработчиками. Под катом возможность сравнить наши походы с «тамошними». Если у вас все хорошо с английским, оригинал публикации и самого автора можно найти по ссылке.

Разработка веб-приложений — это молодой и малоизученный вид деятельности. Инструменты для генерирования и компилирования кода широкодоступны, используются относительно давно и всегда под рукой у программистов. Идея заключается в том (такова тенденция), чтобы брать по одному-два инструмента, запускаемых из командной строки, и отталкиваясь от их возможностей выполнять какую-то часть работы.
Git предоставляет способы решения любых мыслимых проблем со слиянием кода. Также там есть поддержка произвольных сложных схем ветвления и тэгирования. Многие обоснованно считают, что целесообразно всегда использовать эти функции.


Это заблуждение. Следует начать с процедур, которые возымеют эффект уже в процессе текущей работы, и двигаться в обратном направлении, к тому, что было сделано при разработке. Даже с учётом создания выгружаемых MVP (минимальных жизнеспособных продуктов), в конечном итоге в действующем бизнесе большую часть стоимости ПО составляют операционные расходы, а не затраты на разработку.
Приведу пример, который очень хорошо работает на практике с точки зрения операционной деятельности: код нужно развёртывать в production небольшими фрагментами (единицами кода). Полагаю, размер таких фрагментов должен измеряться в десятках строк, а не в сотнях. Вы увидите, что, приняв такой подход за основу, от вас лишь потребуется выполнять только относительно простой контроль изменений.

Ваш последний шанс избежать ошибок в разрабатываемом коде — как раз перед тем, как вы запушите его, поэтому многие команды разработчиков считают хорошей идеей проводить стандартные (как бы) проверки кода (code review). Это не ошибка, но эффект от затраченных усилий невысок.
Проверка сотен строк кода — это серьезная задача. Она требует серьёзных затрат рабочего времени и погружения в процесс. Просмотр больших изменений обычно заканчивается проставлением метки «lgtm» («Думаю, это неплохо»), при этом за суетой небольших исправлений можно не обратить внимание на проблемы более общего характера. Даже в командах с сильнейшей культурой разработки бывают проверки кода, которые превращаются в охоту на ведьм пробелы.

Просмотр сотен строк на наличие ошибок — это эффективная, необременительная процедура. Она не предотвращает всех проблем, и не создаёт новых. Этот процесс представляет собой разумный баланс между возможным и практичным.

Выкатывание больших измененных фрагментов приводит в ужас даже опытных разработчиков. И причина заключается в инстинктивном понимании простой взаимосвязи.

В каждой строке кода с какой-то вероятностью присутствует необнаруженная ошибка, которая всплывёт в процессе эксплуатации. Процесс исполнения кода может повлиять на величину этой вероятности, но не может свести её к нулю. В больших изменённых фрагментах содержится множество строк, и поэтому существует высокая вероятность сбоя при использовании реальных данных и реального трафика. В онлайн-системах код необходимо передавать в работу, чтобы проверить его работоспособность.

Невозможно предотвратить все проблемы в production. Они всё равно возникнут. И лучше пусть это случится, когда мы пушим небольшие изменения.
Многие серьёзные баги в production проявляют себя при выкатывании. Если отсутствует индекс в новом запросе к базе данных на вашей самой большой странице, то, скорее всего, вы быстро получите соответствующее предупреждение. При этом разумно полагать, что ошибка находится в последней версии кода.
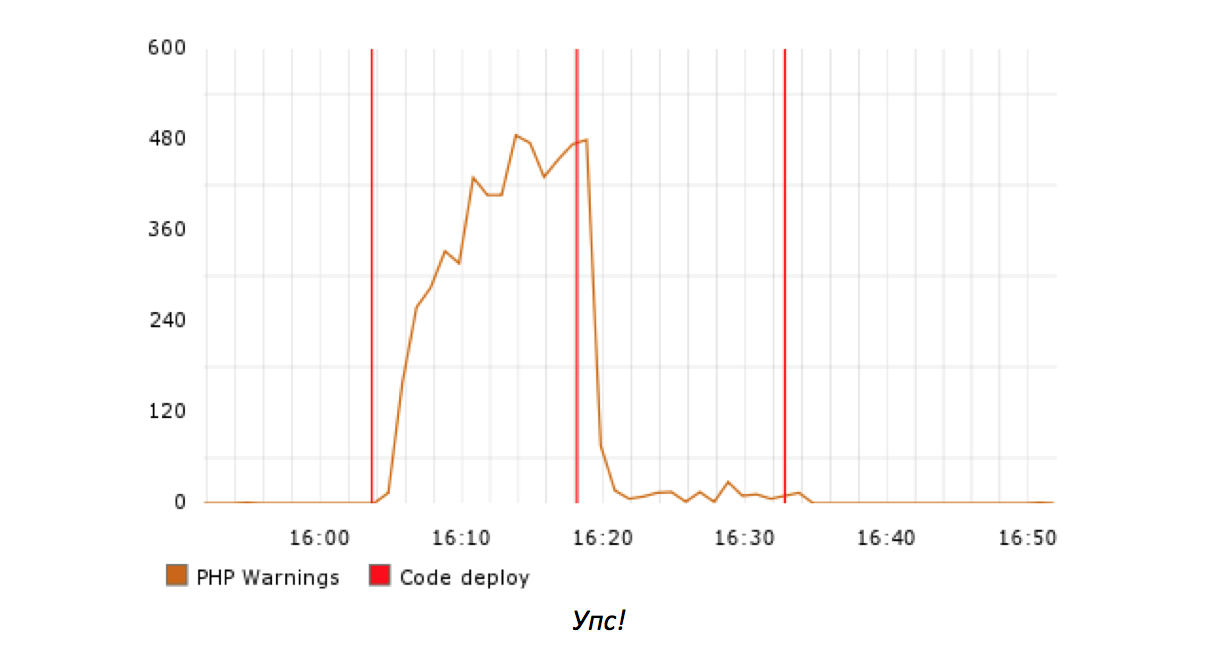
В другом случае вы будете устранять небольшую, но вредную проблему, которая существует уже в течение какого-то времени. Ключевую информацию, необходимую для решения этой проблемы, можно получить при её первом возникновении, а также при анализе внесённых с того момента изменений.
В обоих описанных сценариях отладчик имеет дело с изменёнными фрагментами кода. Обнаружение ошибок в таких фрагментах аналогично проверке кода, но только хуже — это проверка, выполняемая по принуждению. Поэтому длительность устранения проблем в production будет стремиться к пропорциональной зависимости от размера изменяемых фрагментов.

Эффективность проверки кода с профилактической целью ограничивает человеческий фактор. Проблемы в релизах неизбежны и пропорциональны объёмам выпускаемого кода. Время, необходимое для отладки, является функцией (помимо прочего) объёма отлаживаемого кода.
Ниже приведён несложный список указаний. Но если отнестись к ним серьёзно, то можно сделать некоторые интересные выводы.
• Ветви кода инертны, и это плохо. Я говорю людям, что я не возражаю против работы в ветках, если им это помогает, и если я даже не могу сказать с уверенностью, что они это делают. Проще удвоить размер ветки, чем выполнить слияние и развернуть весь код, и разработчики постоянно попадаются в эту ловушку.
• Легкие манипуляции с исходным кодом — это нормально. GitHub-ветки замечательно распиарены, но git diff | gist -optdiff также неплохо работает, если речь идёт о десятках строк кода.
• Вам не нужны тщательно продуманные ритуалы Git-релизов. Церемонии, подобные тэгированию релизов, выглядят пустой тратой времени, если вы выпускаете релизы много раз в день.
• Ваша настоящая проблема заключается в частом выпуске релизов. Ограничение объёма выпускаемого кода может притормозить прогресс, если только вы не сможете одновременно увеличить частоту публикаций. Это не так просто сделать, и при этом ваш арсенал инструментов начнёт тяготеть к средствам, заточенным под решение этой задачи.
Это не исчерпывающий список. Если начать с повседневной операционной деятельности и двигаться в обратном направлении, в направлении разработки кода, то это позволит критически осмыслить весь свой процесс разработки. И это только пойдёт на пользу.
