Визуализация новостей рунета

Представьте себе, что вы поспорили с друганом, что было раньше — курица или яйцо повышение какого-то налога, к примеру, или новости на эту тему, или вовсе важное событие заглушили тучей новостей про новую песню, скажем, Киркорова. Удобно было бы посчитать, сколько новостей на каждую тему было в каждый конкретный момент времени, а потом наглядно это представить. Собственно, этим и занимается проект «радар новостей рунета». Под катом мы расскажем, при чём здесь машинное обучение и как любой доброволец может в этом поучаствовать.
Краткая справка
Machine Learning for Social Good (ML4SG) — это инициатива внутри сообщества ODS, нацеленная на создание условий для проектов, как следует из названия, которые применяют машинное обучения для принесения какой-то пользы обществу. Под созданием условий здесь подразумеваются в основном организационные ресурсы. Выглядит это примерно так: кто-то формулирует идею проекта и призывает добровольцев, а кто-то просто присоединяется к проекту, ради идеи, опыта или ещё каких-то интересов. Всё держится на энтузиазме, чаще всего в свободное от основной работы время. Радар новостей рунета, или как мы его коротко зовём в команде «ньюзвиз», один из проектов в рамках ML4SG.
Дисклеймер
В некоторых иллюстрациях в этой статье будут упоминаться какие-то политические события или персоны. Давайте оставим мнения о них при себе. Хабр не для политики.
Что мы делаем
В двух словах о мотивации
Сейчас проект позиционируется как инструмент для анализа СМИ в целом. Если есть какая-то гипотеза о том, как развивалось внимание в новостях к разным темам, событиям, персонам и так далее, то можно говорить опираясь на конкретные числа, а не на домыслы.
Изначальный замысел был такой: берём все новостные данные, какие найдём, применяем тематическое моделирование, раскладываем результаты по времени и рисуем результат.
Тематическая модель (topic model) — модель коллекции текстовых документов, которая определяет, к каким темам относится каждый документ коллекции. Алгоритм построения тематической модели получает на входе коллекцию текстовых документов. На выходе для каждого документа выдаётся числовой вектор, составленный из оценок степени принадлежности данного документа каждой из тем. Размерность этого вектора, равная числу тем, может либо задаваться на входе, либо определяться моделью автоматически.
Подробнее здесь.
Понятно, что для этого нужны сами новости, и мы их качаем. И раз у нас будут большие корпуса новостей, то можно сделать ещё много всего интересного, не ограничиваясь тематизацией. Но учитывая реальные условия, о которых мы ещё поговорим, а именно, что реализовывать проект будет толпа добровольцев, а не хорошо сработавшаяся команда оплачиваемых специалистов, сначала мы всё-таки решаем задачу почти без изменений.

Сейчас мы пришли к такому формату визуализации, он называется ridgeline plot. На слайде, кстати, настоящие темы, — это скрин из старого внутреннего демо. То есть здесь у нас по оси абсцисс время, толщина полоски пропорциональна тому, насколько тема в этот момент представлена среди других новостей. В данном случае агрегация по месяцам.
В базовом плане у нас есть выбор источника новостей и выбор способа, как показывать график. Также можно выбрать дополнительные данные не из новостей, например, как в это время вела себя цена на нефть или любой другой показатель на том же временном промежутке. Выбор рубрики и набора тем в ней. В дополнение к этому ещё много идей, но об этом позже.
Похожие проекты
Есть много разных других проектов, связанных с визуализацией новостей. Мне нравятся вот этидва. Первый сравнивает, как подаются одни и те же новости в разных источниках, и при этом очень хорошая форма изложения и интерактив. Второй просто имеет очень хорошее отношение информативности к простоте. Там сравнивается, как много говорится о разных причинах смерти в новостях, как часто какие причины смерти упоминаются в поисковых запросах, и как оно по статистике. Ну и в выводах о том, как катастрофически переоценивается терроризм и как недооцениваются сердечные заболевания и рак.
Как мы это делаем.
Проект довольно прямолинейный. Сначала качаем данные, потом обрабатываем, делаем всякий машинлёрнинг, ну и рисуем графики. Потом делаем сайт, и все смотрят. Всё понятно (ну да, конечно).

Сбор данных.
Для старта у нас был датасет ленты ру за 20 лет. В основном все эксперименты мы делали на нём. Сейчас мы собрали ещё несколько источников и продолжаем собирать всё, до чего дотянемся. О скрапинге и пауках есть достаточно много подробных материалов, поэтому мы не будем здесь подробно останавливаться на этой теме.
NLP
Я больше всего переживал за NLP часть, потому что тяжело формализовать требования к результату тематизации. К тому же, достаточно много побочных подзадач. Сейчас мы проделали довольно много экспериментов с разными инструментами для тематического моделирования, перед этим разделались с препроцессингом, наделали много бенчмарков и сравнений. На данный момент бесспорным лидером по тематизации с точки зрения ресурсов и качества оказался bigARTM. Теперь это наш рабочий вариант, пока кто-нибудь не покажет что-то лучше.
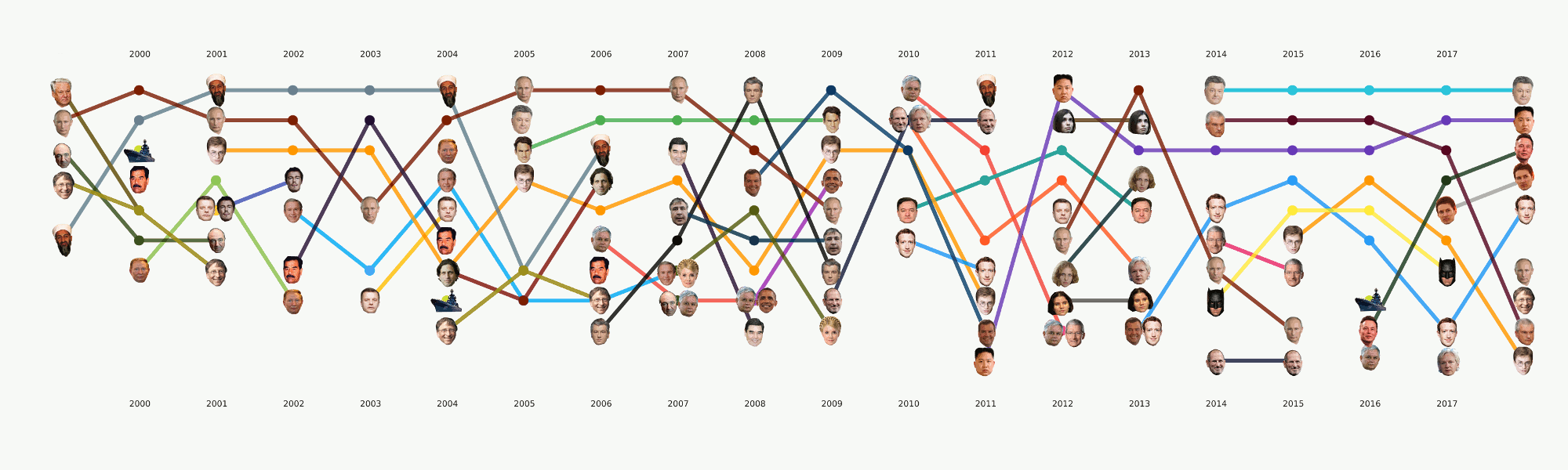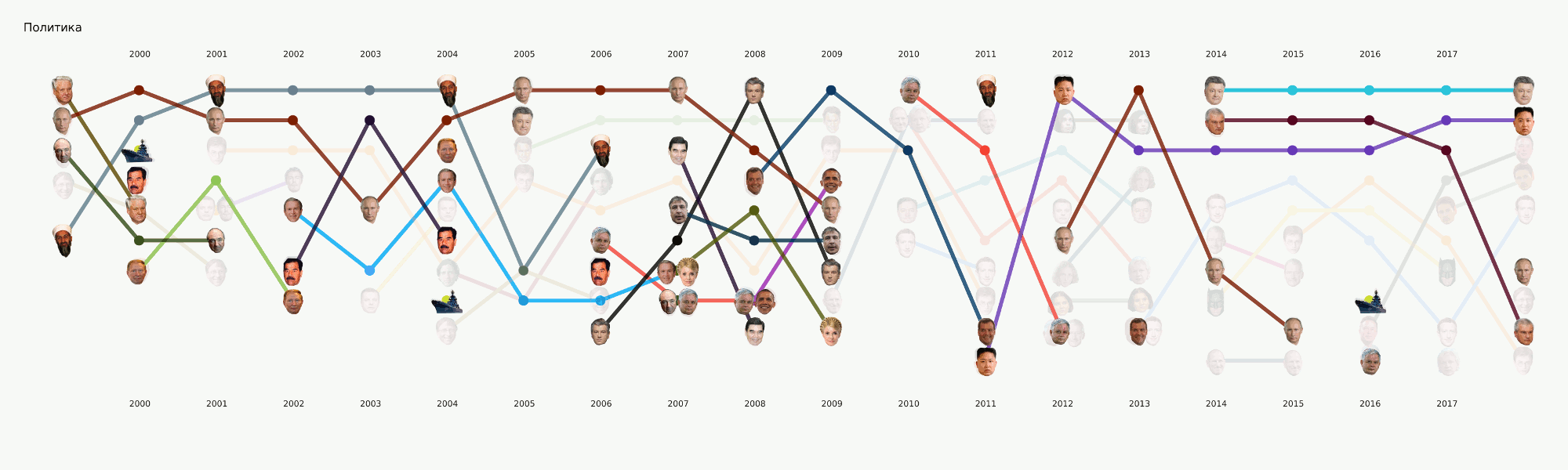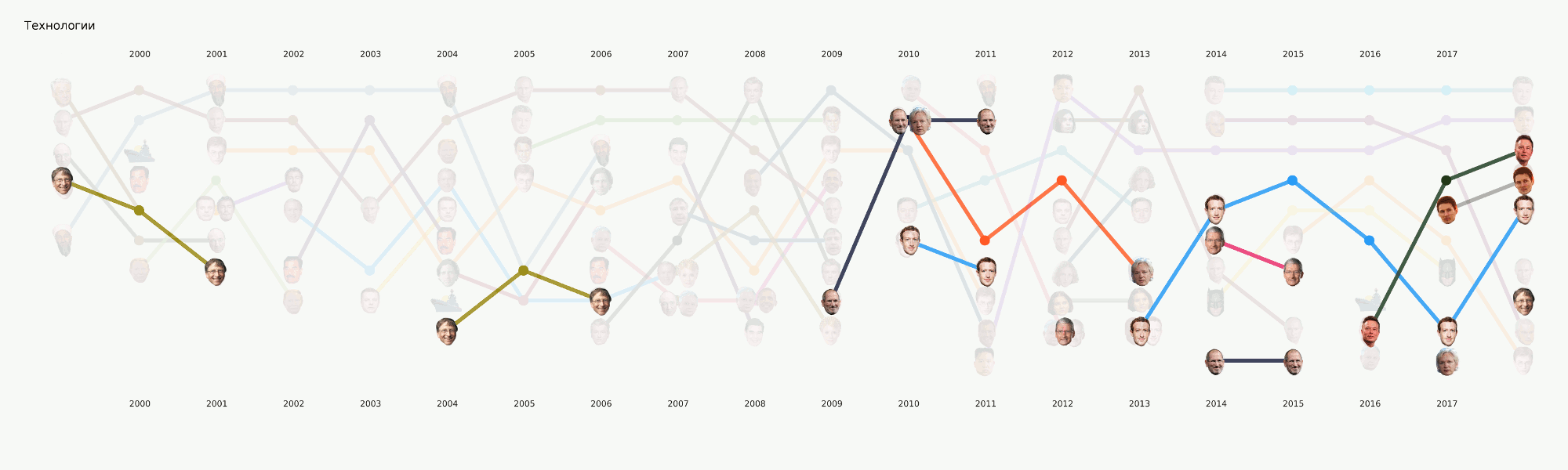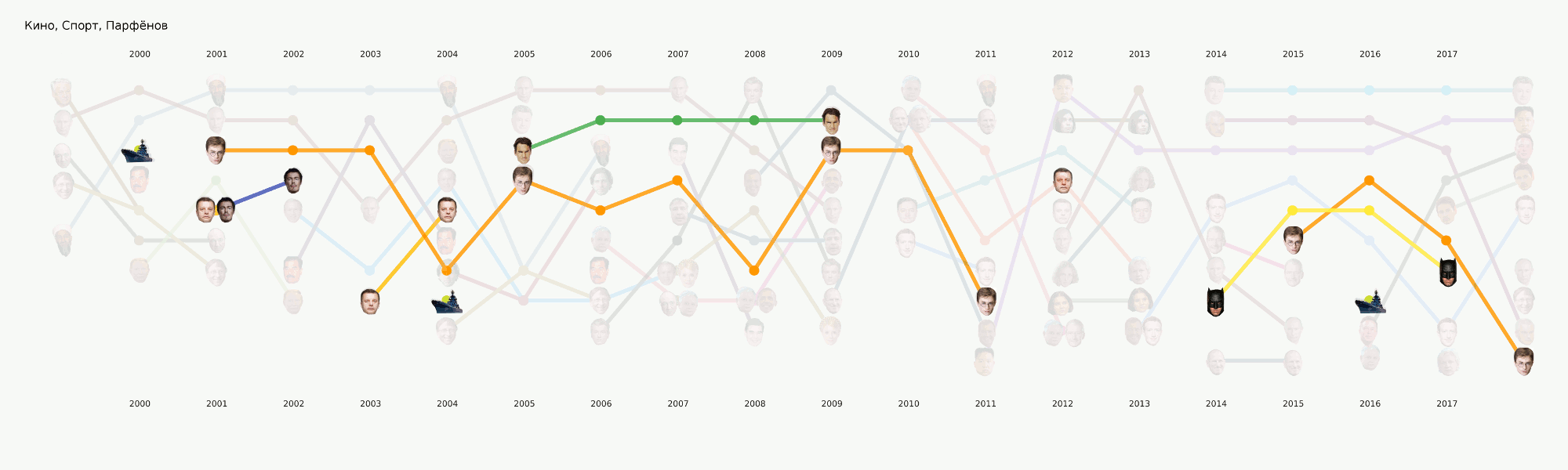
В общем-то весь машинлёрнинг сосредоточен по большей части именно в этой секции. Кроме изначально поставленной основной задачи тематизации есть ещё много других, которые тоже принесут интересные выводы. Например, NER. Мы уже вытащили все имена из тех данных, что у нас есть, составили словари, посчитали, кого сколько раз упоминают. Вышло, например, что про Порошенко в Ленте.ру за всё время писали в четыре раза больше, чем про Путина. Мне интересно стало, что Ассанж идёт синхронно с Магнитским, и всё это ровно после ухода Буша. А Бэтмен популярнее, чем Медведев.
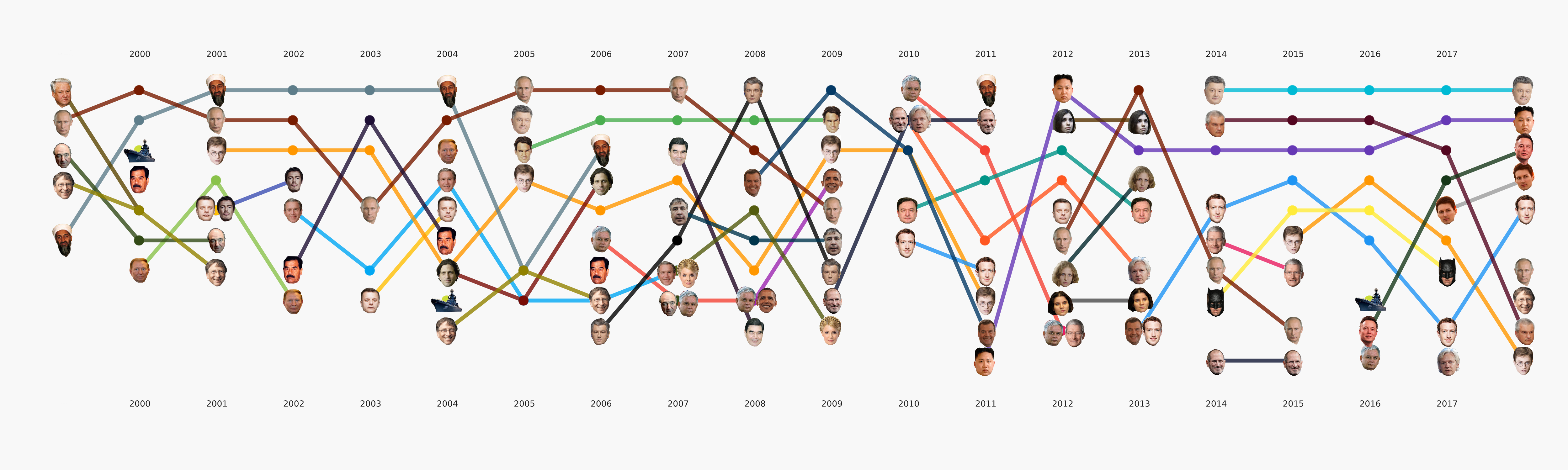

Хотя этот этап всё ещё в процессе, мы сделали большое количество экспериментов и сравнили много инструментов и подходов. В процессе большой туториал по разным задачам NLP с примерами кода и бенчмарками самых популярных и некоторых необычных инструментов.
Визуализация
Этот этап не казался слишком сложным, однако почему-то почти никто не готов им заниматься. Требования к визуализациям идут чуть дальше, чем привычный подход к EDA в датасаенсе. Нарисовать график для себя или другого датасентиста — это гораздо проще, чем нарисовать график для широкой публики. Мы очень долго возились с форматами и инструментами и сейчас пришли к некоторым подходам, которые кажутся наиболее разумными, но впереди ещё много работы, так как готовых инструментов для наших задач практически нет. Например, график с лицами выше делался в два этапа — основные элементы сгенерированы в коде, а затем следовал длинный этап ручной перерисовки, чтобы хоть что-то читалось. В плане подробный разбор этой визуализации в отдельной статье — она отражает в какой-то мере историю России за последние 20 лет.
Команда
Условно можно на две группы разделить участников: новички и профи. У новичков мотивация простая — положить в копилку какой-то проект, чтобы показывать работодателям, или просто приобрести опыт, чему-то научиться. И мне уже сообщали, что разные вещи, которые мы делали в рамках проекта, пригодились в работе участников, начальство оценило. Профи приходят либо из-за самой цели проекта, потому что им интересно присоединиться к идее, либо потому что хотят попробовать что-то из своих идей на новостных данных.
На самом деле есть ещё одна группа участников — это вот такие неуловимые ниндзя, которые вписались и ничего не делают либо только стартуют, а потом исчезают. Но как я уже пояснял, никто не работает в проекте за деньги, поэтому неорганизованность человеческих ресурсов неизбежна. Наблюдать со стороны из любопытства тоже можно.

Сейчас формально числится около 80 человек, из них около 10–20 бывают активны и 2–4 человека из них активны почти постоянно. В таком формате можно компенсировать отсутствие опыта временем. Многие пишут, что нет знаний, как делать, есть страх подвести из-за неумелости, но по факту важно только делать, а не ждать момент. Потому что ml4sg это очень крутая активность. Можно принести пользу и одновременно получить профит в виде опыта и портфолио, при этом из рисков только время, для менеджера ещё и репутация, конечно, но основной ресурс здесь это время, которое в итоге окупается.
Дальнейшие планы
Сейчас я это пытаюсь позиционировать как инструмент для исследований. Мы планируем добавить «разведочный» поиск, который может оценивать тему запроса и давать статистики по новостям этой темы, графики разных неновостных данных, но релевантных теме проекта. Тогда можно будет проверять всякие гипотезы о том, как ведут себя СМИ, как связаны события и другие произвольные показатели, социальные или экономические. Такой инструмент, чтобы исследовать СМИ в целом.
Кто нужен проекту.
- У нас очень мало кто занимается визуализацией. Мы выходим за рамки привычных датасаентисту инструментов вроде matplotlib или plotly, поэтому нужны люди, которые действительно любят визуализацию данных и хотят глубоко в ней прокачаться.
- Нужны люди, которые что-то понимают в веб-разработке.
- Нужны люди, которые подскажут нам, что искать. По сути это должны быть наши заказчики, которым интересно провести исследование и докопаться до каких-то вещей о том, как менялись русскоязычные СМИ в последнее время.
- Нам всегда нужны спецы в NLP, я думаю, тут пояснять не надо. Причём найдётся чем заняться и тем, кто хочет поучиться, и опытным ребятам, так как есть много таких интересных проблем в этой области.
- Ну и конечно нам надо собирать приличный проект, чтобы всё работало не на изоленте, поэтому если вы шарите в архитектуре проектов, умеете пересобирать кучу экспериментов в один пайплайн и готовы поделиться опытом, то велком. Если хотите научиться на ходу, то тоже добро пожаловать.
