Версионирование структуры БД при помощи Liquibase
Большая часть приложений, которые мне встречались, хранят данные в SQL базе данных. Если у вас корпоративное приложение, то скорее всего имеется несколько стендов: стенд разработки, пре-прод и прод. А над приложением трудится команда разработчиков.
Такие приложения сталкиваются с проблемой синхронизации схемы БД между контурами и самими разработчиками. Надо как-то передать изменения, которые вы внесли всем остальным и при этом не получить конфликты.
Эти проблемы решает система управления миграциями Liquibase. Это своего рода система контроля версий вашей базы данных.
Liquibase — независимая от базы данных библиотека для отслеживания, управления и применения изменений схемы базы данных.
Изменения для БД записываются в формате понятном Liquibase, а уже он в свою очередь выполняет запросы к базе данных. Таким образом реализуется независимость от конкретной БД. Liquibase поддерживает 10 типов баз данных, включая DB2, Apache Derby, MySQL, PostgreSQL, Oracle, Microsoft® SQL Server, Sybase и HSQL. Список всех поддерживаемых БД можно посмотреть на сайте.
Существует другие системы управления миграциями: Doctrine 2 migrations, Rails AR migrations, DBDeploy и т.д. Но некоторые из них платформо-зависимые, некоторые не обладают таким широким функционалом.
Также серьезный недостаток многих систем — невозможность применения некоторых изменений без потери данных, например, переименование столбца произойдет как две операции: drop + add, что приведет к потере данных.
Как работает Liquibase
Liquibase — кросс платформенное Java приложение, это значит, что вы можете скачать JAR файл и использовать его на Windows, Mac или Linux.
Для примера мы будем рассматривать работу со spring-boot приложением и PostgresSQL базой данных. Но вы должны знать, что liquibase можно использовать и отдельно в виде .jar файла. Вот так:
java -jar liquibase.jar --driver=com.mysql.jdbc.Driver--classpath=lib/mysql-connector-java-5.1.21-bin.jar --changeLogFile=/path/to/changelog.yaml --url="jdbc:mysql://localhost/application" --username=dbuser --password=secret updateChangelog
Изменения структуры базы данных записываются в файлы, которые называются changelog. Поддерживаемые форматы: XML, YAML, JSON или SQL.
Файлы изменений могут быть произвольно включены друг в друга для лучшего управления. Подробнее об этом ниже.
Я являюсь ярым противником XML конфигураций, но в данном случае это самый удобный формат для записи миграций.
ChangeSet
ChangeSet — это аналог коммита в системах контроля версий, таких как Git. ChangeSet может содержать одно или несколько изменений базы данных. Хорошей практикой считается одна команда для одного ChangeSet.
Каждый changeSet имеет составной идентификатор id, author и filename, который должен быть уникальным.
При первом запуске Liquibase создает две технические таблицы:
databasechangelog— Содержит список изменений схемы БД. Туда записываются уже выполненные changeSet.databasechangelock— Используется для блокировки на время работы, чтобы гарантировать одновременную работу только одного экземпляра Liquibase.
Блокировка
Если несколько экземпляров Liquibase будут выполняться одновременно с одной и той же базой данных, вы получите конфликты. Это может произойти, если несколько разработчиков используют один и тот же экземпляр базы данных или если в кластере несколько серверов, которые автоматически запускают Liquibase при запуске.
Для защиты от таких ситуаций Liquibase создает таблицу databasechangelock, в которой есть boolean поле locked. При запуске Liquibase проверяет его состояние, и если оно true, то ожидает смены на false.
Экстренно остановив выполнение программы в самом начале, может сложиться ситуация при котором Liquibase успеет поставить флаг, но не поменяет его на false. В логах это будет выглядеть так:
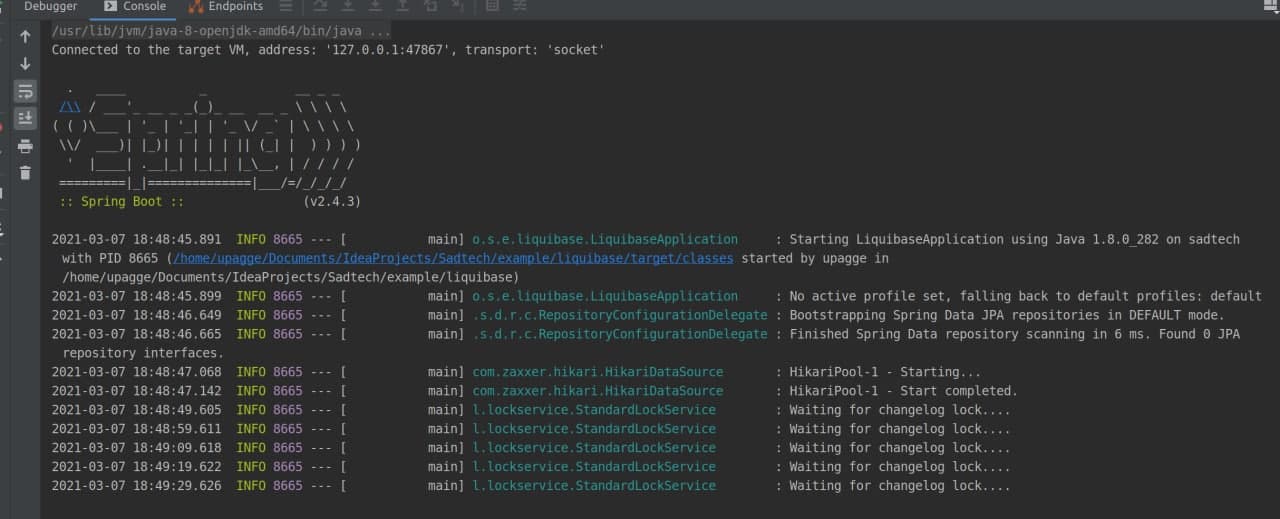 locked-database.jpg
locked-database.jpgЧтобы исправить эту проблему, в таблице databasechangelock измените поле locked на false.
 databasechangelock.jpg
databasechangelock.jpgКонтрольная сумма
Далее Liquibase читает главный changelog, проверяя какие изменения уже были приняты, а какие надо выполнить.
После выполнения changeSet в таблицу databasechangelog со всем прочим записывается MD5 хэш changeSet. Хэш высчитывается на основе нормализованного содержимого XML.
При следующем запуске Liquibase будет сверять вновь рассчитанные хэш суммы, со значениями в его таблице. Если вы изменили уже выполненный changeSet, то хэш сумма будет отличаться, и приложение упадет с ошибкой при старте.
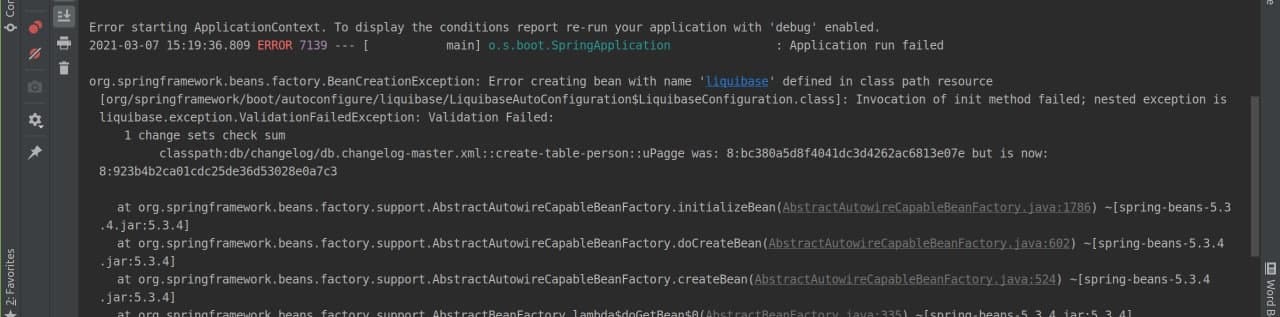 error-md5.jpg
error-md5.jpgПосле выполнения changeset нельзя изменить
Начало работы
И так у нас уже есть spring-boot приложение, в которое мы хотим добавить Liquibase.
Репозиторий с примерами из статьи на GitHub:
https://github.com/Example-uPagge/liqubase
Настройка для spring-boot
Чтобы добавить поддержку Liquibase, нужно указать следующие зависимости в maven:
org.liquibase
liquibase-core
org.springframework.boot
spring-boot-starter-data-jpa
Так же в файл application.yml укажем соединение с базой данных:
spring:
datasource:
url: jdbc:postgresql://localhost:5432/liquibase_example
username: postgres
driver-class-name: org.postgresql.Driver
password: passwordЕсли вы используете Hibernate, то не забудьте отключить создание схемы БД.
Теперь нам необходимо создать главный changelog. По умолчанию в spring-boot Liquibase ищет его в папке resources/db/changelog/db.changelog-master.yml. Как я уже говорил мы будем использовать XML формат.
Создаем файл resources/db/changelog/db.changelog-master.xml. И изменяем путь в application.yml:
spring:
# .. .. .. .. ..
liquibase:
change-log: classpath:db/changelog/db.changelog-master.xmlВставляем начальное содержимое в файл:
// сюда пишутся changeSets
Чтобы быстро получить результат, мы создадим changeSet прямо в этом файле, а потом я расскажу почему так делать не стоит.
Создание таблицы
Создадим таблицу Person.
Тег createTable содержит параметр tableName, который указывает имя новой таблицы. Внутри этого тега мы перечислили колонки, которые нам нужны.
Для колонок обязательно необходимо указать тип. Тип указывается в формате Liquibase, после чего он приводится для конкретной реализации БД.
Отдельного внимания заслуживает колонка id. Для нее мы задали автоинкремент, а так же в constraints указали ограничения колонки:
primaryKey="true"— колонка является первичным ключом таблицы.nullable="false"— значения не могут быть NULL.При использовании primaryKey параметр nullable не обязателен. Но если вы используете H2 для тестов, то у вас могут возникнуть проблемы из-за его отсутствия.
После запуска spring-boot приложения у нас будет создано 3 таблицы, одна из которых и будет person.
Добавление колонки в таблицу
А теперь попробуем добавить новую колонку в таблицу в этом changeSet. Изменим его:
Снова запустив приложение мы получим ошибку.
Если changeSet уже выполнился, и запись об этом есть в databasechangelog, то вы не можете просто изменить changeSet. Вы же не можете в git изменить уже опубликованный коммит.
В этом случае у вас три пути:
Создать новый changeSet с изменениями. [Рекомендуемый]
Выполнить откат средствами Liquibase.
Удалить запись о выполнении changeSet из
databasechangelog. Не рекомендую этот вариант, если changeSet уже был выполнен на каком-то контуре. Этот вариант удобен для локальной разработке.
Вернем changeSet в его предыдущее состояние и создадим новый:
Запускаем приложение. На этот раз успешно, новая колонка добавилась.
 add-new-column-success.jpg
add-new-column-success.jpgСвязь с другой таблицей
Связь между таблицами довольно частое явление. Добавим новую таблицу Book и свяжем ее с таблицей Person. Создадим новый changeSet:
Теперь атрибут author_id связан с атрибутом id в таблице Person.
При этом обязательно нужно указать уникальный foreignKeyName. Я пользуюсь следующим правилом: имя_таблицы + имя_поля + имя_главной_таблицы + имя_поля_главной_таблицы.
Также мы можем указать тип каскадной операции:
Теперь атрибут author_id связан с атрибутом id в таблице Person.
При этом обязательно нужно указать уникальный foreignKeyName. Я пользуюсь следующим правилом: имя_таблицы + имя_поля + имя_главной_таблицы + имя_поля_главной_таблицы.
Также мы можем указать тип каскадной операции:
Теперь, если автор книги будет удален, то книга тоже будет удалена.
Если вам необходима операция каскадного обновления, то вам нужен второй способ связи с таблицей:
Создание представления
Несмотря на то, что к этому моменту вы уже полюбили создание изменений с помощью XML, для создания представления придется использовать SQL:
SELECT p.id as person_id,
p.name as person_name,
b.id as book_id,
b.name as book_name
FROM person p
LEFT JOIN book b on p.id = b.author_id
Советы от бывалых
Познакомился я с Liquibase на своей стажировке в 2017. С тех пор я использую Liquibase на своих домашних проектах, и продвигаю его использование на рабочих.
Мне уже проще написать changeSet, чем SQL. Поэтому далее будет небольшой список рекомендаций, которые облегчат вам жизнь.
Организация ChangeSet
Добавляя все changeSet в один changelog у вас могло закрасться сомнение:, а все ли мы правильно делаем. Схема БД может довольно динамично меняться, особенно в начале создания приложения, поэтому мы ожидаем множество changeSet.
Можно создавать множество ChangeLog и включать их друг в друга. Далее я расскажу о своем подходе к организации changelog.
Я придерживаюсь следующего подхода:
Для каждой текущей версии приложения создаем папку в
db/changelog. Так как у нас еще нет версии приложения, то будем использовать папкуv.1.0.0.В этой папке у нас будет локальный главный чейджлог-файл. Я называю их
cumulative.xml.Когда вам необходимо внести набор изменений для схемы БД, то вы создаете отдельный changelog и включаете его в
cumulative.xml.В
db.changelog-master.xmlмы подключаем всеcumulative.xml.
Во время выпуска релиза у вас могут оказаться запросы на слияния, которые затрагивают добавления новых changeSet. В этих ПР необходимо создать новую папку для новых changeLogs с номером нового релиза и перенести туда changeLogs для этих ПРов.
Правила именования
Правило именования файлов позволяет без просмотра кумулятивных чейнджлогов файлов понять, что за чем следовало, и не допустит случайного повторения id у changeSet.
Вы можете придумать свои правила, но вот что предлагаю я:
Каждый changelog, кроме
cumulative.xml, начинается с текущей даты, а далее короткое описание всех изменений. Например:2020-03-08-create-tables.xmlТак же поступайте с
idу changeSet. Напримерid="2020-03-08-create-table-person".
Не изменяйте данные
абота с данными в БД не входит в число ключевых фич Liquibase и ограничивается лишь простейшими операциями вставки и удаления или изменения. Исходя из своего опыта крайне не рекомендую изменять данные с помощью Liquibase.
Кто-нибудь обязательно ошибется и ошибка уедет на тестовую среду, а откатывать придется вручную.
Идентификаторы к записям чаще всего генерируются автоматически, что может привести к дополнительным конфликтам.
Используйте XML
Иногда хочется «облегчить» жизнь и отказаться от XML, начав использовать более краткий DSL: groovy, yaml, json.
Все это очень хорошо до тех пор, пока вам не захочется иметь:
Авто дополнение в IDE
Автоматическую проверку формальной верности документа по схеме данных
Используйте remark
Разработчики стараются давать понятные имена для переменных, но дополнительное описание не будет лишним. Параметр remark позволяет добавлять описания к таблицам и полям.
Итого
Эта же статья в момем блоге: Версионирование структуры БД при помощи Liquibase.
В этой статье мы обсудили логику работы Liquibase, а так же простое внедрение его в ваше приложение. Этого уже достаточно, чтобы начать пользоваться Liquibase.
В следующей статье я расскажу, как откатывать изменения.
