Vectorization Advisor, ещё один пример — разгоняем фрактал
Мы недавно уже писали о новом Vectorization Advisor. О том, что это такое и зачем нужно, читайте в первой статье. Этот же пост посвящён разбору конкретного примера оптимизации приложения с помощью этого инструмента.Приложение взято из примеров библиотеки Intel® Threading Building Blocks (Intel TBB). Оно рисует фрактал Мандельброта и распараллелено по потокам с помощью Intel TBB.Т. е. преимущества многоядерного процессора оно использует — посмотрим, как обстоят дела с векторными инструкциями.
 Тестовая система: • Ноутбук с Intel® Core i5–4300U (Haswell, 2 ядра, 4 аппаратных потока)• IDE: Microsoft Visual Studio 2013• Компилятор: Intel® Composer 2015 update 2• Intel® Advisor XE 2016 Beta• Приложение: фрактал Мандельброта, слегка модифицированное. См.
Тестовая система: • Ноутбук с Intel® Core i5–4300U (Haswell, 2 ядра, 4 аппаратных потока)• IDE: Microsoft Visual Studio 2013• Компилятор: Intel® Composer 2015 update 2• Intel® Advisor XE 2016 Beta• Приложение: фрактал Мандельброта, слегка модифицированное. См.
Итак, первый шаг: замеряем базовую версию, время работы: 4.51 секунды. Дальше запускаем Survey анализ в Intel® Advisor XE: 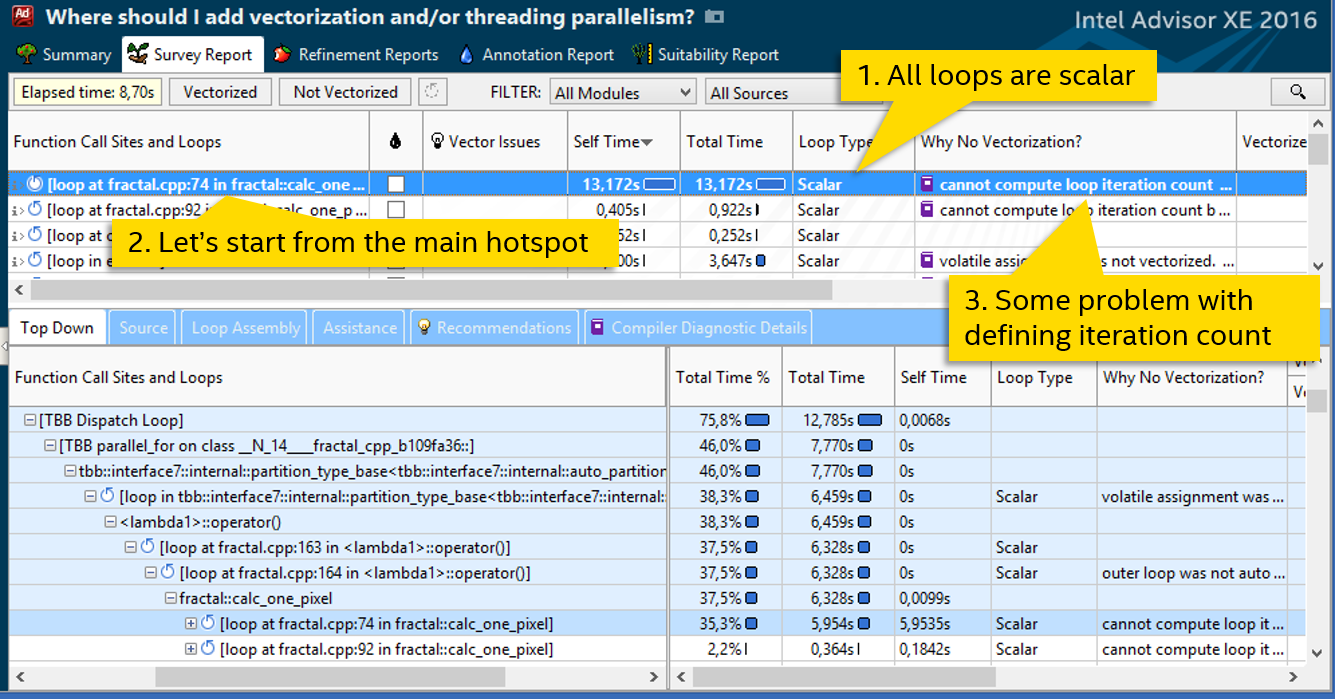
Колонка «Loop Type» говорит о том, что все циклы скалярные, т.е. не используют SIMD инструкции. Самый затратный цикл в файле fractal.cpp на строке 74. Он тратит больше 13 секунд процессорного времени — им и займёмся. Колонка «Why No Vectorization» содержит сообщение о том, что компилятор не смог оценить количество итераций цикла, поэтому и не векторизовал его. Двойной клик на подсвеченный цикл, смотрим код:
while (((x*x + y*y) <= 4) && (iter < max_iterations) ) {
xtemp = x*x - y*y + fx0;
y = 2 * x*y + fy0;
x = xtemp;
iter++;
}
Становится ясно, почему количество итераций не известно во время компиляции. Прежде, чем погружаться в детали алгоритма и пробовать переписать while, попробуем пойти более простым путём. Посмотрим, откуда вызывается наш цикл – закладка Top Down: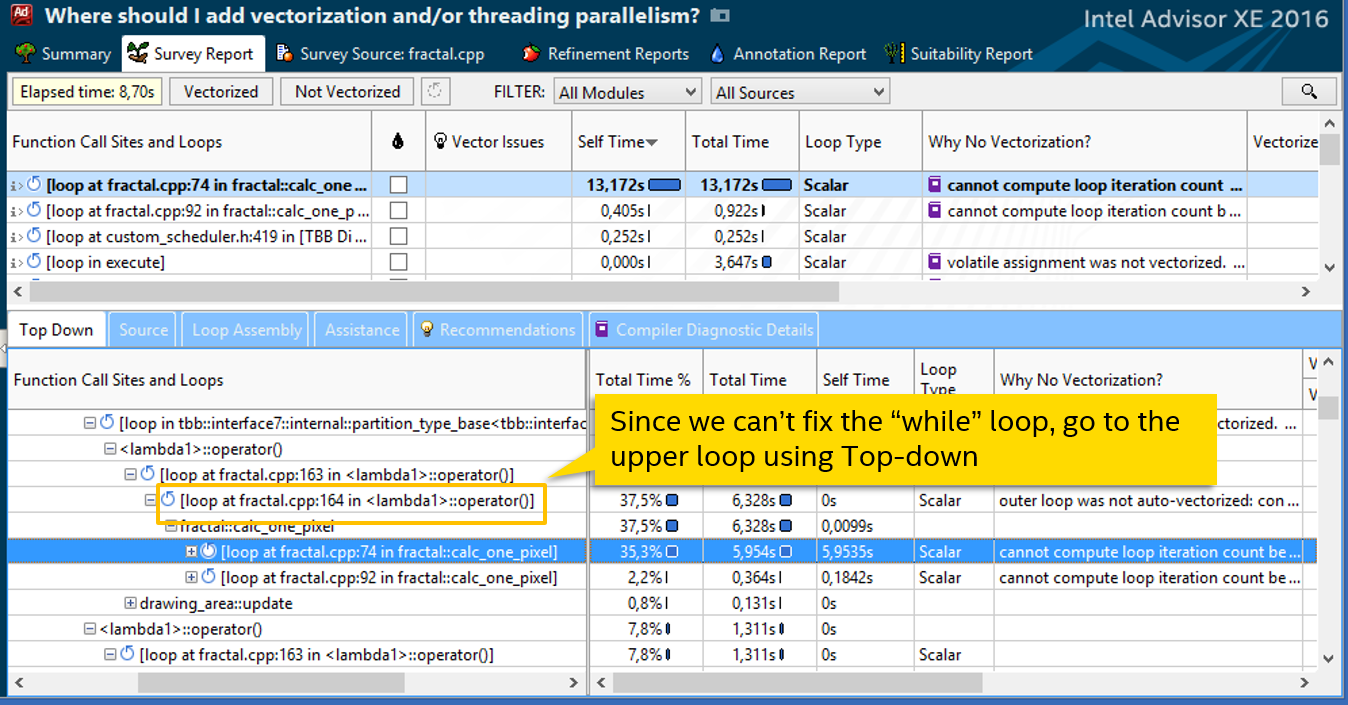
Следующий по стеку вызовов цикл на строке 164. Это нормальный с виду for, который компилятор тоже не векторизовал (Scalar в колонке Loop Type), вероятно, не посчитав это эффективным. Диагностическое сообщение предлагает попробовать форсировать векторизацию, например, с помощью директивы SIMD: 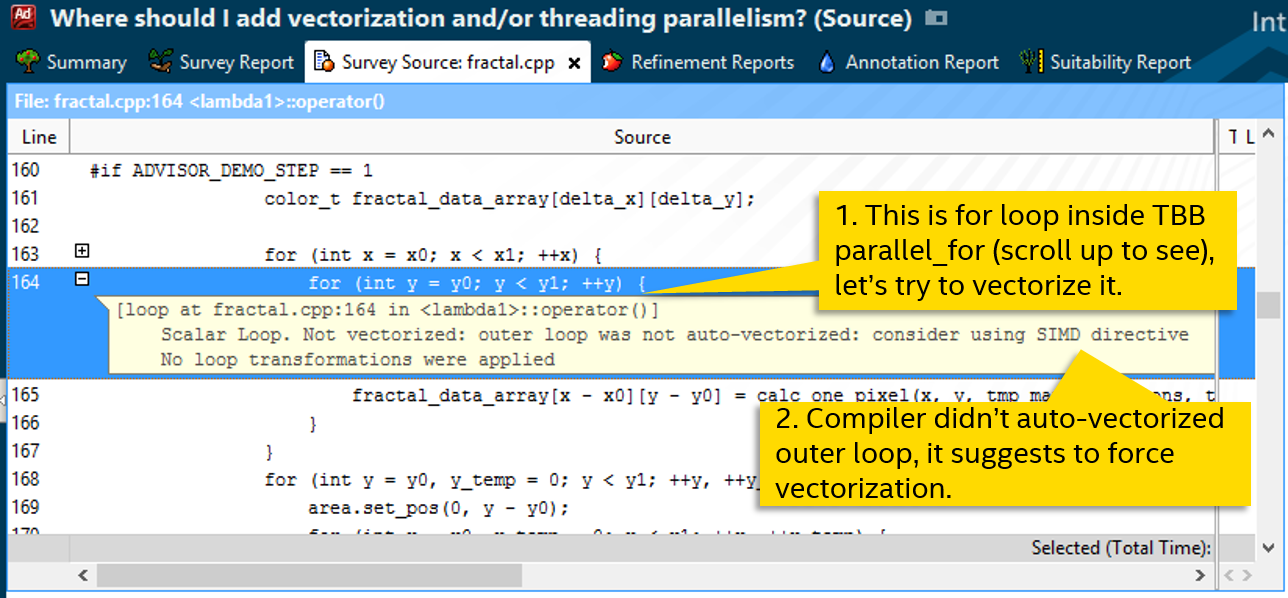
Следуем совету:
#pragma simd // forced vectorization
for (int y = y0; y < y1; ++y) {
fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255);
}
Пересобираем программу и запускаем Survey опять. С #pragma simd цикл стал не «Scalar», а «Remainder»:
SIMD циклы, как известно, могут делиться на peel, body и remainder. Body — собственно, векторизованная часть, где за одну инструкцию выполняется сразу несколько итераций. Peel появляется, если данные не выровнены на длину вектора, remainder — некратные итерации, остающиеся в конце.
У нас есть только Remainder. Это значит, что цикл векторизовался, но body не исполнялось. Закладка с рекомендациями говорит о неэффективности такой ситуации — нужно, чтобы больше итераций исполнялось в body, поскольку remainder здесь — обычный последовательный цикл. Проверим, сколько там всего итераций с помощью анализа Trip Counts:

В нашем цикле всего 8 итераций, что довольно мало. Если бы их было больше, векторизованному body было бы что исполнять. Номер строки изменился после модификаций кода, теперь это строка 179. Посмотрим, как определяется количество итераций:
tbb: parallel_for (tbb: blocked_range2d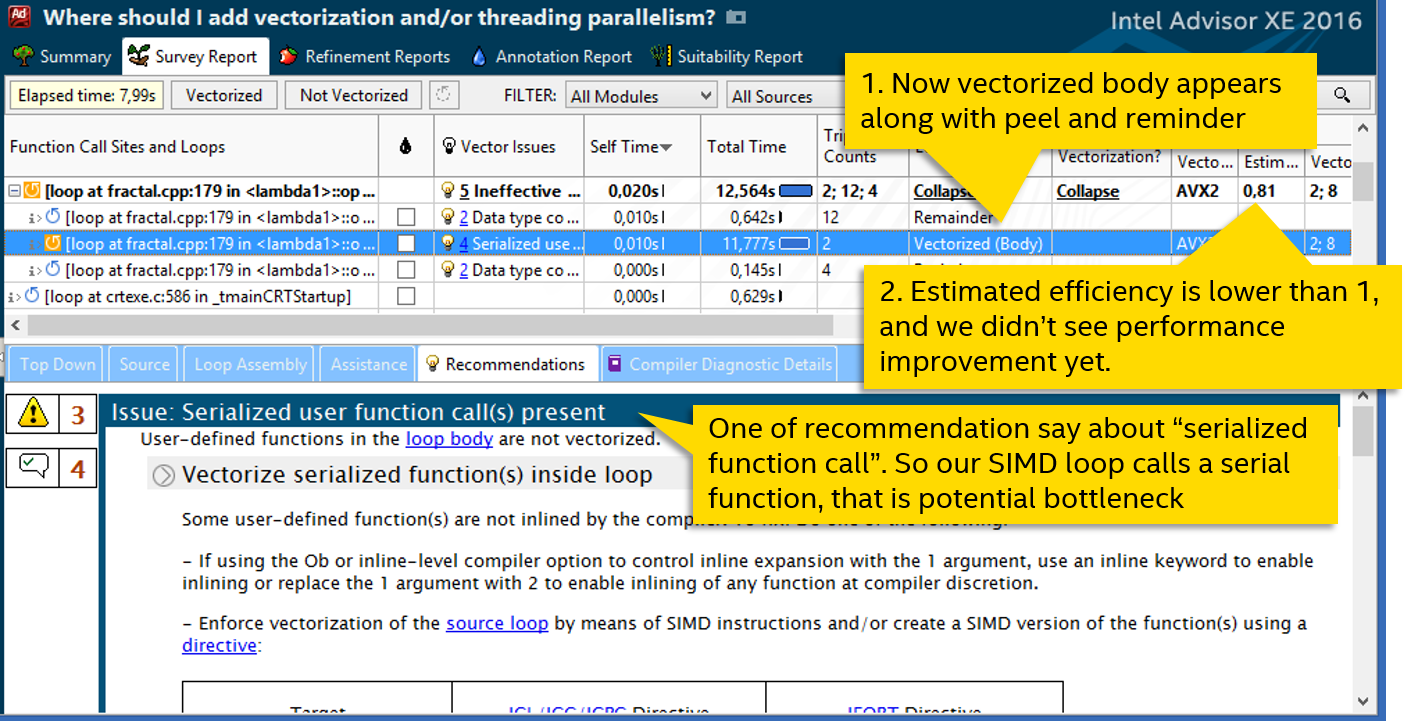
Теперь в цикле появляется векторизованное body, мы наконец добились реального использования SIMD инструкций, цикл векторизован. Но радоваться рано — производительность никак не выросла.
Смотрим рекомендации Advisor XE — одна из них говорит о вызове сериализованной (последовательной) функции. Дело в том, что если векторный цикл вызывает функцию, то для неё нужна векторизованная версия, которая может принять параметры векторами, а не обычными скалярными переменными. Если компилятор не смог сгенерировать такую векторную функцию, то используется обычная, последовательная версия. И вызывается она тоже последовательно, сводя на нет всю векторизацию.Снова смотрим код цикла:
for (int y = y0; y < y1; ++y) { // цикл на строке 179
fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255);
}
Благо, вызов функции здесь один: calc_one_pixel. Раз компилятор не смог сгенерировать векторный вариант, попробуем ему помочь. Но сначала давайте посмотрим на шаблоны доступа к памяти, это пригодится для явной векторизации: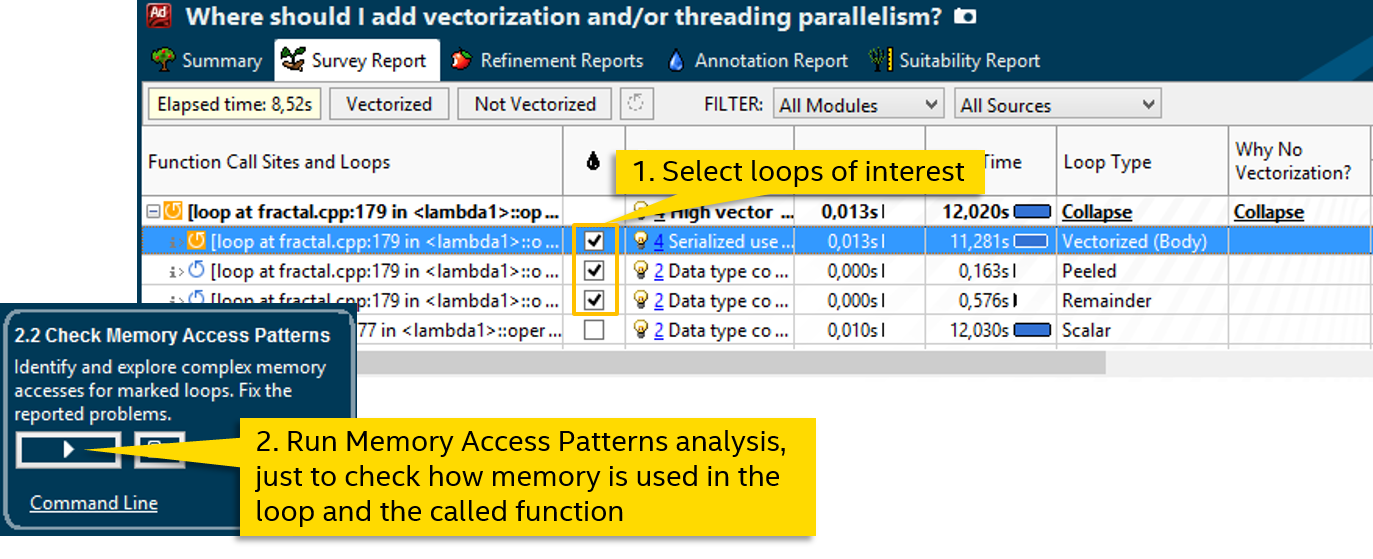
Анализ Memory Access Patterns нашего цикла (вместе с вызываемой функцией) говорит нам, что все операции чтения или записи — unit stride с шагом 0. Т.е. при обращении к внешним данным из каждой итерации читается или пишется одна и та же переменная:
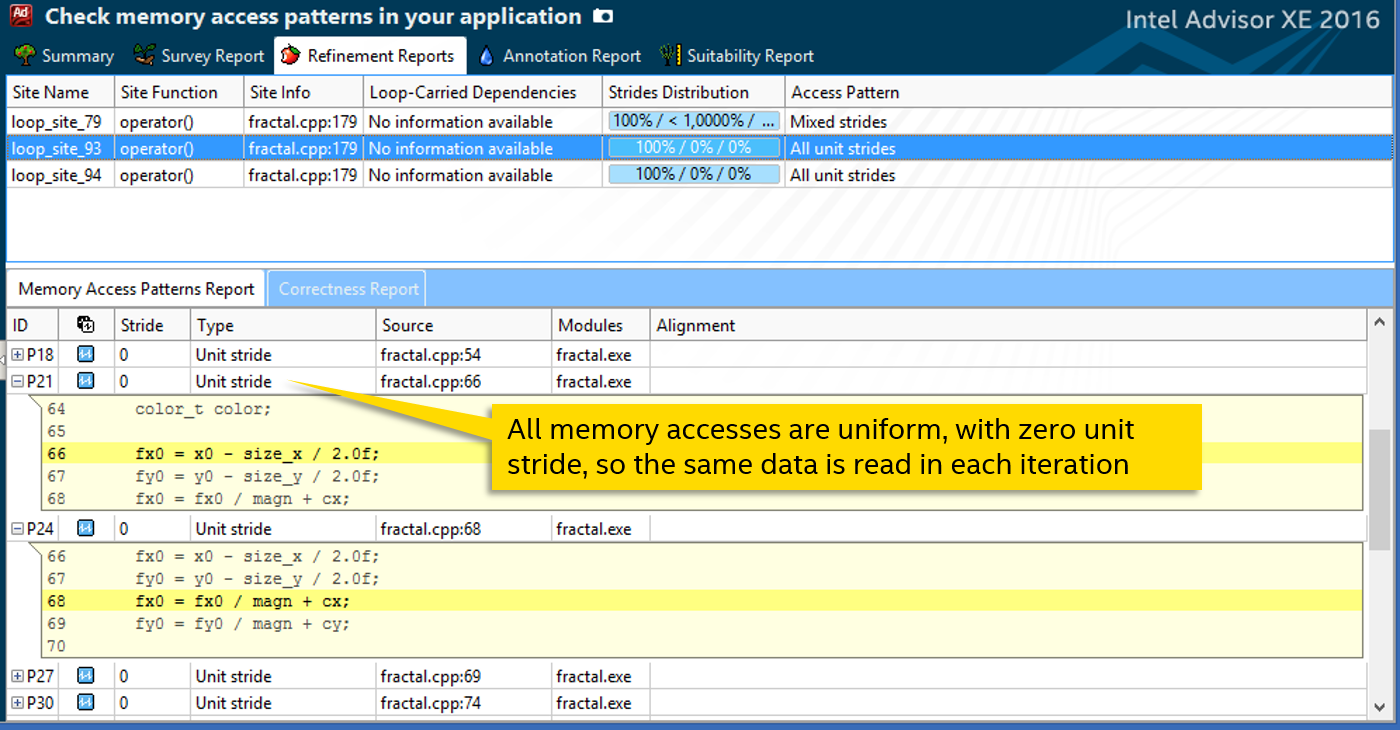
Это знание нам пригодится для ручной векторизации функции. Мы воспользуемся директивой #pragma omp simd из стандарта OpenMP 4. У неё есть опции, определяющие шаблон доступа к параметрам. Например, «linear» используется для монотонно растущих величин, в основном итерационный переменных. Нам же подойдёт uniform — для доступа к одним и тем же данным.
#pragma omp declare simd uniform (x0, max_iterations, size_x, size_y, magn, cx, cy, gpu)
color_t fractal: calc_one_pixel (float x0, float y0, int max_iterations, int size_x, int size_y, float magn, float cx,
Добавив директиву над определением функции, мы дали возможность компилятору сгенерировать её векторную версию, которая может обрабатывать массивы данных вместо объявленных скалярных. Получаем заметный рост скорости — цикл исполняется 7.5 секунд вместо 12: 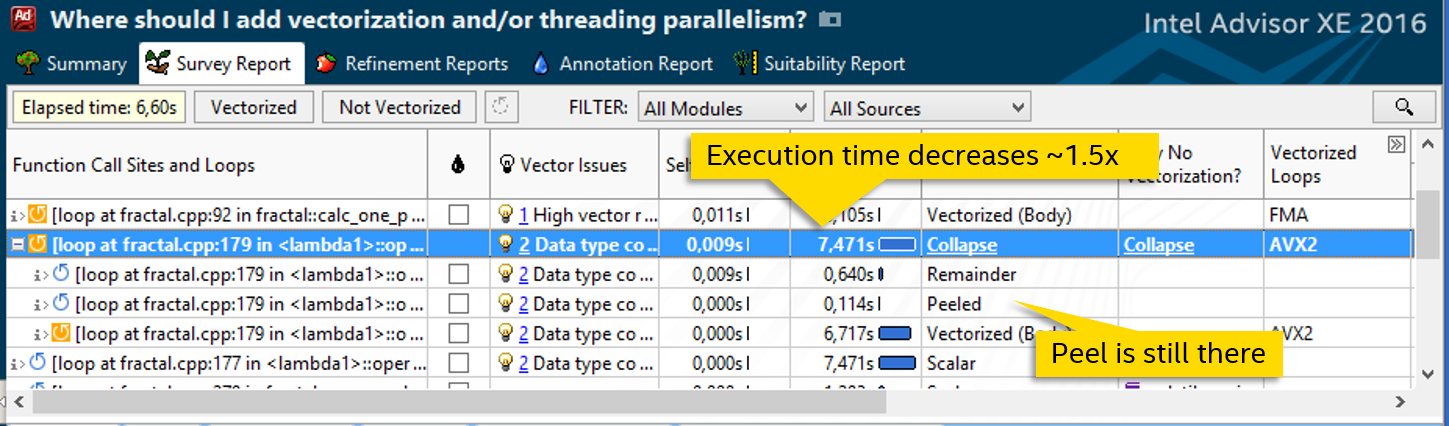
Попробуем побороться с другими причинами неэффективности векторного цикла. Наличие части peel говорит о том, что данные не выровнены. Добавим __declspec (align (32)) перед определением массива, в который записываются результаты calc_one_pixel: __declspec (align (32)) color_t fractal_data_array[delta_x][(delta_y / 16 + 1) * 16]; // aligned data
for (int x = x0; x < x1; ++x) {
#pragma simd
for (int y = y0; y < y1; ++y) {
fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255);
}
}
После этого peel пропадает:
В таблице диагностик Advisor XE можно обратить внимание ещё на одну вещь — колонка «Transformations» говорит, что компилятор развернул цикл (unrolled) с фактором 2:  Т.е. в целях оптимизации количество итераций сокращено вдвое. Само по себе это не плохо, но в третьем шаге мы специально старались их увеличить, и получается, что компилятор делает обратное. Попробуем отключить развёртку с помощью #pragma nounroll:
Т.е. в целях оптимизации количество итераций сокращено вдвое. Само по себе это не плохо, но в третьем шаге мы специально старались их увеличить, и получается, что компилятор делает обратное. Попробуем отключить развёртку с помощью #pragma nounroll:
#pragma simd
#pragma nounroll // added unrolling
for (int y = y0; y < y1; ++y) {
fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255);
}
После этого количество итераций ожидаемо увеличилось вдвое: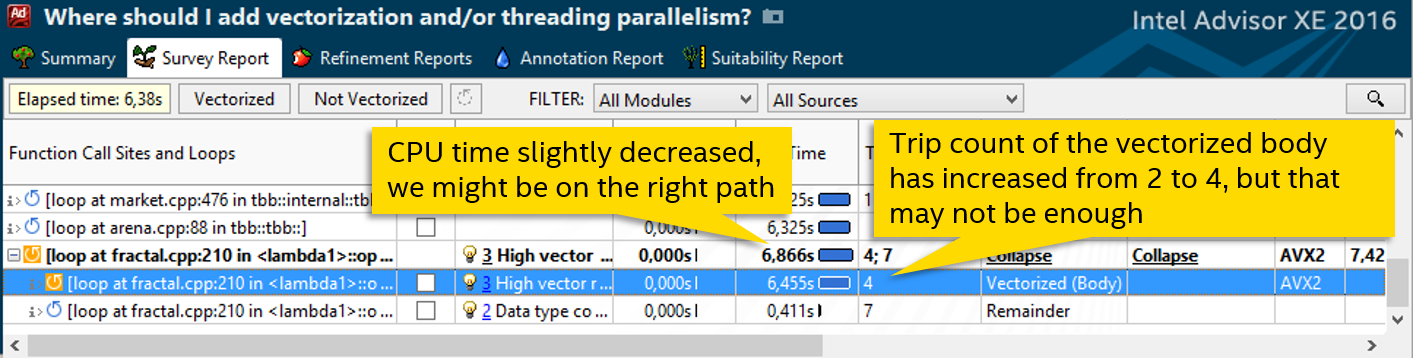
Манипуляции с unrolling позволили увеличить количеств итераций, но улучшения производительности не последовало. Посмотрим, что будет, если ещё сильнее увеличить grain_size, как в шаге 3. Просто эмпирически прощупываем оптимальное значение:
int grain_size = 256; // increase from 64
int inner_grain_size = 64; // increase from 8
Получается выжать ещё немного, хоть и совсем чуть-чуть: 
После всех манипуляций время работы тестового приложения сократилось с 4.51 до 1.92 секунд, т.е. мы достигли ускорения примерно в 2.3 раза. Напомню, что наш вычислительный тест уже был частично оптимизирован — неплохо распараллелен по потокам на Intel TBB, достигая хорошего ускорения и масштабируемости на многоядерных процессорах. Но из-за того, что векторизация не была использована полностью, мы всё равно недополучали половину возможной производительности. Первый вывод — векторизация может иметь большое значение, не стоит ей пренебрегать.Теперь посмотрим эффект от различных изменений:

Форсирование векторизации и увеличение числа итераций (шаги 2 и 3) сами по себе программу не ускорили. Самый главный прирост скорости мы получили на шаге 4 после векторизации функции. Однако это совокупный эффект от шагов 2–4. Для реальной векторизации цикла было нужно и увеличить число итераций, и форсировать векторизацию, и векторизовать функцию.
А последующие шаги особого эффекта не имели, в нашем случае их можно было совсем пропустить. Шаг 7 можно более или менее отнести к успешным, и то из-за того, что в шаге 3 мы сразу не выставили большее число итераций. Однако целью поста было показать возможности Advisor XE на конкретном примере, поэтому описаны все проделанные действия.
