Вариант развёртывания Linux систем на базе Puppet 4. Часть V: базы данных (cfdb)
Вкратце:
- cfdb — модуль развёртывания и автонастройки узлов и кластеров баз данных и доступа к ним с высокой доступностью и защитой от сбоев.
- Как proof-of-concept поддерживаются MySQL и PostgreSQL на базе Percona Server/XtraDB Cluster и официальных сборок PostgreSQL+repmgr.
- Изоляция ресурсов на базе cgroups, интеграция с настройками сетевого фильтра через модуль
cfnetworkи строгий контроль доступа средствами СУБД.- Запись на один узел для минимизации конфликтов и распределение нагрузки для read-only доступа.
- Автоматическая проверка здоровья кластера и фактической осуществимости доступа.
- Ручное и автоматическое локальное резервное копирование, автоматизированное восстановление данных.
- Поддержка автоматической миграции уже существующих баз данных
Тематический цикл:
- Часть I: сеть и сетевой фильтр (cfnetwork + cffirehol)
- Часть II: доступ и стандартное окружение (cfauth + cfsystem)
- Часть III: установка Puppet Server (cfpuppetserver)
- Часть IV: централизованное управление (cftotalcontrol)
- Часть V: базы данных (cfdb)
Введение в концепцию и терминологию
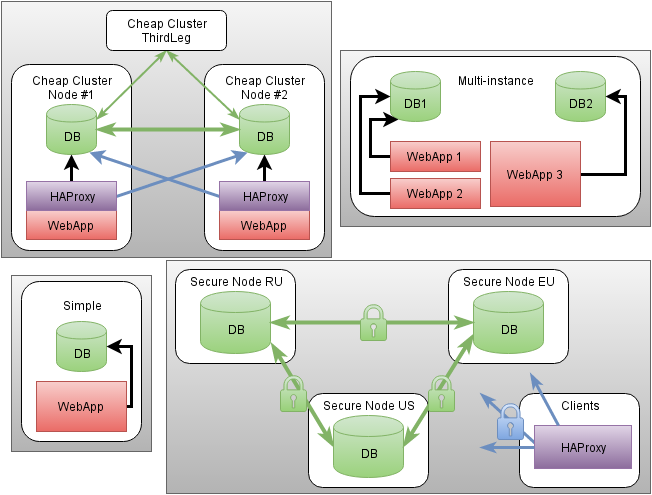
Типы сущностей в абстрактной конфигурации:
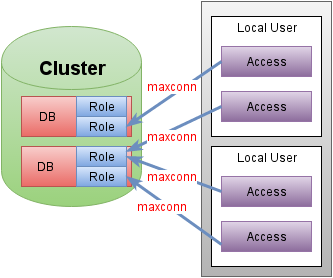
cluster— абстрактная именованная совокупность узлов СУБД, работающих как одно целое.instance— физический узел, принадлежащийcluster.database— именованная база данных, принадлежащаяcluster.role— учётная запись с доступом к определённойdatabase. По умолчанию всегда существует одноимённая сdatabaseроль с полным доступом к соответствующей базе.access— декларируется необходимость доступа к определённой базе под определённой учётной записью базы с определённым максимальным числом соединений из указанной локальной учётной записи конкретного узла.
Специфика конфигурации кластера в некоторой степени продиктована живой работой DBA — есть основной узел, через который вносятся все изменения. По этому принципу сущности типа database и role допускается задавать только на одном узле, а остальные узлы должны быть сконфигурированны как второстепенные или вообще арбитраторы. Такое положение может добавить немного дискомфорта, если требуется вносить изменения во время fail-over, но ничто не ограничивает возможность временных ручных изменений.
Для унификации и упрощения отладки инфраструктуры прозрачно используется универсальный прокси-сервис HAProxy. Явное преимущество заключается: в отсутствии специальных изменений в приложениях, в продвинутом контроле статуса полностью готовых к работе узлов кластера, создании защищённых каналов связи вне процесса СУБД (TLS offloading), поддержке сбора статистических данных из коробки, строгое ограничение количества допустимых соединений даже от кривых приложений. HAProxy автоматически вступает в игру в следующих случаях:
- В
clusterболее одного узла и соответственно требуется контролировать статус каждого. - Декларация доступа
accessпринудительно требует защищённый канал связи с удалённым узлом. - Факт
cf_locationклиентского и серверного узла не совпадают (разные ЦОД) и явно не указано небезопасное соединение для случая с VPN.
В отличии от резиновых «производительных» ресурсов (CPU, I/O), главная проблема возникает с распределением памяти. Для этого в модуле cfsystem был создан универсальный фреймворк для распределения памяти в системе по относительным весам (приоритетам) сервисов с учётом возможных минимальных и максимальных лимитов. Совокупность процессов каждого instance запускается в собственном cgroup срезе systemd. Помимо управления распределением ресурсов и лимитами вроде максимального количества файловых дескрипторов, systemd ещё и выступает в роли хранителя процесс и автоматически перезапускает любое нештатное падение. Для дискового пространства всё же подразумевается монтирование отдельных томов для максимальной изоляции и скорости.
Мета-информация данного модуля собирается и хранится в виде фактов Puppet, что требует некоторого понимания, что факты генерируются на целевой системе и загружается в PuppetDB в начале развёртывания. Т.е. требуется повторное развёртывание чтобы сохранить свежие факты после изменений. Автоконфигурация доступа, ограничения количества соединений и прочие нюансы конфигурируются именно из этих централизованно сохранённых фактах о всех управляемых системах. Здесь явно есть простор для улучшений и соответственный план, но пока так.
Ближе к делу
Данный модуль почти на столько же многогранен на сколько многогранна полноценная настройка СУБД.Частично прояснить функционал поможет документация по cfdb, но нагружать всем данную статью будет излишним.
Поднимим СУБД
- Добавляем конфигурацию системы с базой
# Добавляем класс cfdb для подхвата настроек classes: [cfdb] # Собственно задаём узел кластера cfdb::instances: mysrv: type: mysql port: 3306 databases: db1: {} db2: roles: ro: readonly: true custom: custom_grant: 'GRANT SELECT ON $database.* TO $user; GRANT SELECT ON mysql.* TO $user;' - Развертываем два раза. Пока так — на втором шаге будут собраны необходимые факты для централизованной базы.
@db$ sudo /opt/puppetlabs/bin/puppet agent --test; sudo /opt/puppetlabs/bin/puppet agent --testПопробуем разобраться что произошло:
- Устанавливается полный список пакетов Percona Server
- Мы создаём узел СУБД, принадлежащий абстрактному кластеру с уникальным именем
mysrv - В кластере определеяем две базы данных
db1иdb2 - Автоматически создаются роли
db1иdb2с полным доступом к соответствующим базам - Дополнительно создаётся роль
db2roс доступом только на чтение кdb2и поддержкой распределения нагрузки по узлам - Дополнительно создаётся роль
db2customс абсолютно произвольными правами доступа. Обратите внимание на обязательное использование ключей подстановки$databaseи$user. - Все пароли генерируются случайным образом, но могут быть принудительно установлены.
- В централизованной базе PuppetDB появляется информация о существующих кластерах, их узлах, базах данных и ролях.
Декларируем доступ к ролям кластера
- Добавляем конфигурацию системы с приложением
# Добавляем класс cfdb для подхвата настроек classes: [cfdb] # Непосредственно декларация доступа cfdb::access: # название произвольное, но уникальное webapp_mysrv_db1: cluster: mysrv role: db1 local_user: webapp max_connections: 100 webapp_mysrv_db2ro: cluster: mysrv role: db2ro local_user: webapp max_connections: 500 config_prefix: 'DBRO_' - Развертываем два раза на клиентской системе. Должны появиться предупреждения о невозможности получить доступ при автоматических проверках.
@web$ sudo /opt/puppetlabs/bin/puppet agent --test; sudo /opt/puppetlabs/bin/puppet agent --test - Развёртываем один раз на системе с базой
@db$ sudo /opt/puppetlabs/bin/puppet agent --test - При необходимости перегружаем СУБД для увеличения максимального количество всех соединений, которые кратны 100 по умолчанию. Процесс оазвёртывания сам подскажет необходимые действия.
@db$ sudo /bin/systemctl restart cfmysql-mysrv.service - Финальный этап — развёртываем ещё раз на клиентской системе чтобы убедиться, что все доступы работают.
@db$ sudo /opt/puppetlabs/bin/puppet agent --test
Что же произошло:
- На клиентской системе под локальным пользователем
webappбыл создан файл.env:- в нём набор переменных с префиксом
DB_(по умолчанию) для доступа к ролиdb1одноимённой с базой, - плюс набор переменных с префиксом
DBRO_ для доступа к ролиdb2roв базеdb2, - при желании кроме
.envможет использоваться любой специфичный подход (см.cfdb::access::custom_config).
- в нём набор переменных с префиксом
- На втором проходе загружаем факты.
- Потом обновляем конфигурацию СУБД, где для каждой роли добавится клиентский узел в список разрешённых и увеличится максимальное количество соединений.
- Проверяем, что все доступы работают — делается автоматически при развёртывании
Вот собственно и всё, нет существенной разницы в типе СУБД. Всё однотипно.
Миграция существующих каталогов с данными
Для удобства перехода с ранее установленных конфигураций СУБД была добавлена фича в виде init_db_from параметра тонкой настройки. Формат значения несколько отличается для разных типов СУБД ввиду специфики upgrade процессов. Пример использования:
cfdb::instances:
mymigrate:
type: mysql
...
settings_tune:
cfdb:
init_db_from: '/var/lib/mysql'
pgmigrate:
type: postgresql
...
settings_tune:
cfdb:
init_db_from: '9.5:/var/lib/postgresql/9.5/main/'К слову, обновлённый модуль cfpuppetserver уже использует cfdb для организации высокой доступности. Во время установки происходит миграция базы фактов без потери мета-информации.
Выполняем ручные операции над instance
По умолчанию, домашние папки имеют вид /db/{type}_{name}/, где расположен каталог bin/ с полезным обёртками стандартных команд mysql, psql, repmgr и др. с префиксом cfdb_. Их можно запускать от пользователя root, но это небезопасно ввиду возможной подмены через расширения того же PostgreSQL. Пример входа в базу под супер-пользователем:
@db$ sudo -u mysql_mysrv /db/mysql_mysrv/bin/cfdb_mysql
# ИЛИ с некоторым риском
@db$ /db/mysql_mysrv/bin/cfdb_mysqlРезервное копирование и восстановление
Возможность ручного резервного копирования и восстановления всегда доступна через команды ~/bin/cfdb_backup и ~/bin/cfdb_restore в домашней папке instance. Автоматическое периодическое резервное копирование включается при $cfdb::instance::backup = true. Настройка производится через параметр $cfdb::instance::backup_tune. Специфика реализации зависит от типа СУБД. В данный момент xtrabackup используется для MySQL и pg_backup_ctl для PostgreSQL.
Примечание: в XB 2.4 есть проблема — требует минимум 1GB свободной памяти для инкрементального восстановления
Для примера поднимим hot standby кластер PostgreSQL с repmgr
- Конфигурация главного узла
classes: [cfdb] cfdb::instances: pgcluster: type: postgresql port: 5432 # Всё отличие is_cluster: true databases: - db1 - Конфигурация второстепенных узлов
classes: [cfdb] cfdb::instances: pgcluster: type: postgresql port: 5432 # этого достаточно для второстепенных узлов is_secondary: true Клиент конфигурируется точно так же, как и с одним узлом, но в игру автоматически прозрачно вступает HAProxy.
- Развёртываем на всех связанных системах. Повторяем ещё два раза: на первом шаге вносим факты в PuppetDB, а на втором доводим до ума. На третьем повторе уже не должно быть изменений. *Если требуется перезапустить некоторые узлы кластера, то в случае repmgr нужно это делать, начиная с ведущего (
~/bin/cfdb_repmgr cluster show), в силу специфики параметраmax_connectionsи репликации.
Кто хоть раз настраивал типовой кластер PostgreSQL с repmgr, почувствовали разницу?
Интеграция с контейнерами вроде Docker и внешней инфраструктурой
Тут есть две стороны: первая — сами СУБД, вторая — условно клиенты СУБД. В статичном варианте проблем особо быть не должно, а вот при динамическом наращивании требуется изначально развернуть максимальную инфраструктуру, а потом убрать лишнее с graceful отключением узлов кластера для сохранения кворума.
В случае «неуправляемых» внешних клиентов есть параметр $cfdb::role::static_access, который позволяет гибко задавать факты о декларированном доступе вручную в обход централизованных мета-данных.
Что мы имеем в итоге
Очевидно, что подобный подход позволяет «клепать» и поддерживать кластеры баз данных в промышленных масштабах за короткое время, значительно уменьшая риск ошибок в столь чувствительной области. Безусловно, в данный момент занесение мета-данных инфраструктуры в централизованную базу несколько усложняет процесс развёртывания. На определённом этапе есть возможность улучшить это, сразу учитывая ещё не развёрнутые части, но всему своё время. В то же время, данный модуль Puppet позволяет минимальными усилиями получить защищённую и относительно оптимально подогнанную к конкретным условиям СУБД, с крайне гибкой возможностью контроля как процесса оптимизации, так и подгонки финального конфига. Общая концепция универсальна и позволяет без особого труда добавлять поддержку других типов СУБД по мере необходимости.
При всём при этом сохранность данных стоит на первом месте — автоматизация имеет жёсткие ограничения, если появляется риск потери данных, тогда необходимо ручное вмешательство по подсказкам при развёртывании.
UPD: подправлены глюки обработки Markdown на Хабре.
