В поисках идеального файлового хранилища
 Ранее мы рассматривали прототип масштабируемой read-only файловой системы. Удалось показать, что, используя предложенную архитектуру, можно построить файловую систему любой емкости, с гарантированным временем доступа, соизмеримым с таковым для доступа к файлу в пределах одного физического диска.Далее постараемся разобраться, может ли подобный подход принести пользу при построении файловой системы общего назначения.Стоит заранее отметить, что автор не является признанным специалистом в области распределенных файловых систем и не ставит своей целью осчастливить человечество очередным гениальным изобретением. Скорее, хочется продемонстрировать сообществу здравую идею и попробовать расшатать её в обсуждении. Кроме того, публичное обсуждение способно спасти идею от огораживания патентами.Итак, вспомним основные выводы,
которые были сделаны при построении прототипа read-only системы: Содержимое файловой системы можно разделить на две частиСобственно данные, содержимое файлов
Метаданные, описывающие расположение файлов и сопутствующую информацию
Метаданные не должны быть частью структуры файловой системы, это просто данные о других данных. Не должно быть специальных механизмов, ответственных за определяемую пользователями структуру файловой системы.
Для описания файловой системы хорошо подходит её представление деревом, в котором ключом являются пути, а значением — данные файла (и довесок из атрибутов)
Метаданные легко сжимаются.
Данные и метаданные можно хранить на различных носителях, в том числе носителях с разной физической структурой. Так, относительно небольшие по объему метаданные могут быть размещены на более быстрых и дорогих устройствах, а собственно файловые данные — на чём-либо попроще.
Теперь цели, которых хочется достичь: Модульность (масштабируемость) по емкости
Модульность по производительности
Модульность по внешним интерфейсам
Логарифмическая деградация производительности при росте объема данных
Под модульностью понимается возможность поблочно наращивать соответствующие мощности, если они становятся узким местом.В целом, речь не идет о распределенной сети устройств, положенной на физическую сеть непонятной топологии. Предполагается, что внешне всё выглядит как единое устройство, реализующее функции файловой системы общего назначения. А внутреннее устройство — наше сугубо внутреннее дело.
Ранее мы рассматривали прототип масштабируемой read-only файловой системы. Удалось показать, что, используя предложенную архитектуру, можно построить файловую систему любой емкости, с гарантированным временем доступа, соизмеримым с таковым для доступа к файлу в пределах одного физического диска.Далее постараемся разобраться, может ли подобный подход принести пользу при построении файловой системы общего назначения.Стоит заранее отметить, что автор не является признанным специалистом в области распределенных файловых систем и не ставит своей целью осчастливить человечество очередным гениальным изобретением. Скорее, хочется продемонстрировать сообществу здравую идею и попробовать расшатать её в обсуждении. Кроме того, публичное обсуждение способно спасти идею от огораживания патентами.Итак, вспомним основные выводы,
которые были сделаны при построении прототипа read-only системы: Содержимое файловой системы можно разделить на две частиСобственно данные, содержимое файлов
Метаданные, описывающие расположение файлов и сопутствующую информацию
Метаданные не должны быть частью структуры файловой системы, это просто данные о других данных. Не должно быть специальных механизмов, ответственных за определяемую пользователями структуру файловой системы.
Для описания файловой системы хорошо подходит её представление деревом, в котором ключом являются пути, а значением — данные файла (и довесок из атрибутов)
Метаданные легко сжимаются.
Данные и метаданные можно хранить на различных носителях, в том числе носителях с разной физической структурой. Так, относительно небольшие по объему метаданные могут быть размещены на более быстрых и дорогих устройствах, а собственно файловые данные — на чём-либо попроще.
Теперь цели, которых хочется достичь: Модульность (масштабируемость) по емкости
Модульность по производительности
Модульность по внешним интерфейсам
Логарифмическая деградация производительности при росте объема данных
Под модульностью понимается возможность поблочно наращивать соответствующие мощности, если они становятся узким местом.В целом, речь не идет о распределенной сети устройств, положенной на физическую сеть непонятной топологии. Предполагается, что внешне всё выглядит как единое устройство, реализующее функции файловой системы общего назначения. А внутреннее устройство — наше сугубо внутреннее дело.
Немного о проблемах .Модульность — это хорошо, но начнем с конца, с логарифмической деградации производительности. Что подразумевает использование сбалансированного дерева.Дерево — хорошо известная и понятная структура давно и успешно применяемая в СУБД и файловых системах. Несомненным плюсом сбалансированных деревьев является способность расти и уменьшаться без деградации, сохраняя приемлемой утилизацию дискового пространства.
В нашем случае, файловая система и есть дерево, где ключом является путь до файла, а значением — его атрибуты и тело файла. Причем, тело является аналогом BLOB«а и может быть расположено в другом адресном пространстве, например, в другой среде хранения.
Изначальный порыв был именно такой —, а что если сделать «супер-дерево», «супер-страницами» которого будут автономные дисковые подсистемы, которые при переполнении логически разваливаются надвое, аналогично тому, как это происходит в В-дереве. При недополнении, две супер-страницы логически сливаются в одну, ненужное дисковое пространство уходит назад в резерв. Предполагается, что переходы внутри супер-страницы относительно дёшевы, а между ними — дорогостоящи.
К сожалению, будучи реализованной в лоб, такая схема нежизнеспособна. Объяснение довольно занудно, но оно необходимо.
Деревья подразумевают страничную организацию дискового пространства. Раз страницы ссылаются друг на друга, должны существовать идентификаторы страниц. Идентификатор страницы — это число, которое несложным образом может быть преобразовано в смещение внутри файла/устройства. Пространство идентификаторов одномерно, даже если страницы лежат на куче дисков, мы должны заранее (возможно, неявно) указать, как собираемся пилить пространство адресов на эти устройства.
Что из этого следует? С одной стороны, при записи в файловую систему мы имеем дело с одномерным порядком путей файлов, причем этими путями мы не управляем, пользователь волен называть файлы/директории, как ему заблагорассудится.С другой стороны, есть одномерное пространство идентификаторов страниц, порядок которых как-то связан с последовательностью создания файлов. Этим порядком мы тоже не управляем.
Никакой естественной связи между порядком обхода дерева файлов и порядком страниц, которые при этом придется прочитать, не существует. Корреляции, конечно могут возникать, например, при распаковке из архива, но опираться на такую связь вряд ли разумно. И ситуация, когда логически близкая информация физически сильно разделена (нарушена локальность ссылок) вполне нормальна и весьма вероятна.
Вот так выглядит фазовая диаграмма чтения страниц при траверзе тестового В-дерева, построенного вставкой в произвольном порядке:  Фиг. 1
Фиг. 1
По абсциссе — номер текущей читаемой страницы, по ординате — прочитанной в прошлый раз.
А так — дерево, содержащее те же данные, пропущенные через «отстойник», буфер- накопитель, при переполнении которого данные перед записью сортируются:  Фиг 2
Фиг 2
В идеале, когда порядок вставки совпадает с естественным порядком ключа, мы бы имели просто диагональную линию.
В случае записи метаданных файловой системы, использование «отстойника» невозможно и при заполнении дерева, страницы будут выделяться в соответствии, скорее, с первым вариантом.
Чем это грозит? Тем, что когда придёт пора пилить супер-страницу, перед нами встанет непростой выбор:
либо перезалить содержимое половины страницы на свободное пространство новой страницы, что может потребовать немало времени. В обычном В-дереве такой проблемы нет т.к. переполненная страница уже находится в оперативной памяти и скопировать часть её содержимого пренебрежительно дешево по сравнению с выделением новой страницы. либо смириться с тем, что изолировать супер-страницы друг от друга не удастся и при расщеплении возникнет масса горизонтальных связей. Со временем это приведет к размыванию локальности ссылок и деградации производительности…Обратимся еще раз к Фиг1 и представим, что у нас образовалось 6 супер-страниц (по числу клеточек) и каждый раз, когда линия траверза пересекает сетку, мы переключаемся с одной супер-страницы на другую. И, естественно, платим за это временем. Можно, конечно, утешать себя тем, что логарифмическая деградация производительности при росте дерева достигнута самим фактом существования дерева. Даже если каждый шаг при спуске по дереву будет сопровождаться переходом на другую супер-страницу, всё равно это будет логарифм, пусть и с неприятным коэффициентом. Как если бы мы в обычной файловой системе отключили дисковый кэш и каждое обращение требовало физических операций с устройством. Но нет, хочется чего-то более эффективного. О размерности пространства идентификаторов. Неловкий вопрос, а почему мы считаем пространство идентификаторов страниц одномерным? Отчасти по историческим причинам, но в основном потому, что это всех устраивает и нет причин что-то менять. Технически не сложно, имея сотни/тысячи дисков, сделать двумерную адресацию страниц — (ID диска, позиция на диске) или трехмерную (ID кучки, ID диска, место на диске). Непонятно, правда, что делать с таким анизотропным пространством адресов, но сам факт технической возможности еще предстоит осмыслить.Забавно, раньше автору приходилось ломать голову над вопросом, как бы поэффективнее утрамбовать 2–4 мерный пространственный индекс в одномерное пространство адресов страниц. А сейчас нам надо так сконструировать пространство страниц, чтобы разместить в нём два одномерных пространства — путей и порядка создания файлов. Удачная конструкция сможет выполнять роль «отстойника», повысить локальность файловой системы и уменьшить число длинных/дорогих переходов в ней.
Приступим, пожалуй.
Начнём с описания базовых элементов: дерево метаданных — хранилище метаданных файловой системы. Ключом в дереве является путь файла, значением — метаданные файла и ссылка на тело файла. Дерево полностью сбалансировано. Ожидаемая высота дерева зависит от числа элементов, которые удастся разместить на странице. Например, если это в среднем 10 элементов, то для миллиарда файлов потребуется дерево высоты 9, если 100 — то 5. Соответственно, и скорость доступа будет различаться в 2 раза.
страница — элемент дерева метаданных. Листовые страницы содержат и ключ и метаданные, промежуточные страницы — только ключи и ссылки на дочерние страницы. Ссылка на страницу должна быть уникальна в пределах всей файловой системы. С тем, как этого достичь, разберемся ниже. Ожидается, что страницы лежат на быстрых устройствах хранения с минимальным временем позиционирования, SSD, например.Отдельно остановимся на корневой странице дерева. По мере роста дерева корневая страница может блуждать с места на место и необходим механизм, с помощью которого в любой момент можно узнать, какая страница на данный момент корневая. Это указывает на необходимость системного реестра.Вообще-то предполагается, что страница дерева содержит минимум 2 элемента. А в каждом элементе у нас ключ произвольной длины. Это непростой момент, не будем пока углубляться в него, предположим просто, что решение существует исходя, например, из того, чтоЭлементы страницы упорядочены и с большой вероятностью содержат общий префикс
Этот префикс можно вычислять при просмотре вышестоящих страниц
Пути легко поддаются сжатию
Возможно использование словарей
Размер страницы мы выбираем сами
Возможны разумные ограничения на длины имен и путей
тело файла — то, ради чего все и затевалось. Всё остальное лишь оправа к этой драгоценности. Будем предполагать, что в отличие от страниц, доступ к телам более потоковый и менее беспорядочный. А значит можно располагать их на более дешевых обычных жестких дисках. Тело может состоять из нескольких фрагментов, для каждого фрагмента заводится своя запись в дереве. Важно, чтобы фрагменты одного тела по возможности физически располагались неподалёку.
диск. Бывает двух типов — SSD (для страниц) и обычных жестких дисков (ЖД) (для тел файлов). Будем считать, что он сбоеустойчив, например, будучи реализован как RAID. Имеет уникальный в рамках всей файловой системы идентификатор.
модуль хранения. То, что мы выше называли «супер-страницей». Предназначен для работы как со страницами, так и с телами файлов. Следовательно, состоит из двух типов дисков. При этомМодуль содержит те фрагменты тел, ссылки на которые есть в её страницах. В этом смысле он автономен.
Имеет уникальный в рамках всей файловой системы идентификатор.
Модуль может состоять из различного, пусть и ограниченного количества дисков обоих типов
Предполагается, что существует пул свободных дисков, из которого модуль может их черпать по мере того, как растёт его заполненность
Этот пул может быть общим для всех модулей и тогда должен существовать механизм коммутации дисков с модулями хранения. Либо другой крайний вариант — модуль держит некоторое к-во дисков в резерве и сигнализирует когда резерв заканчивается, после чего диски можно подключить «руками». А возможно и некоторый промежуточный вариант.
В какой то момент к-во обслуживаемых дисков одного из типов заканчивается и модуль хранения становится переполненным
исполнительный модуль — реализует работу с деревом. А также проводит соответствующую работу с телами файлов. Умеет искать, добавлять, удалять и модифицировать элементы на страницах и данные вне зависимости от того, на каких модулях хранения всё это расположено. А следовательно берет на себя роль менеджера распределенных транзакций.
Разберём, как происходит заполнение нашей файловой системы.
Допустим, мы просим исполнительный модуль создать файл с некоторым именем в некоторой директории.
Исполнительный модуль создает глобальную транзакцию.
А так же готовит ключ — полное имя файла и пытается вставить новую запись в дерево. В запись входят, конечно и метаданные файла (хозяин, права, …), но мы о них для простоты умолчим.
Информация о местонахождении корневой страницы является общеизвестной.
Вычитываем её и находим в ней в соответствии с нашим ключом ID нижестоящей страницы (если есть).
Каждая страница расположена на каком-то диске, который в свою очередь принадлежит какому-то модулю хранения. Будет логичным, если идентификаторы модуля и диска вместе с позицией на диске составят идентификатор страницы.
Таким образом из ID нижестоящей страницы исполнительный модуль узнает к какому модулю хранения за какой страницей с какого диска следует обратиться.
Вычитываем эту страницу и т.д. рекурсивно спускаемся до листовой страницы
В листовой странице находим место для нашей новой записи и пытаемся ее вставить. Для этого нам придётся захватит её на запись у соответствующего модуля хранения. Для чего в свою очередь нужна локальная транзакция
Может так случиться, что на листовой странице недостаточно места для нашей новой записи. В этом случае, как и положено, мы создадим новую страницу и разделим примерно поровну содержимое старой. При этомлогично, если мы будем создавать новую страницу в том же модуле хранения. Модуль выбирает подходящий диск и создает для нас на нем страницу
Поднимаемся на шаг вверх по стеку прочитанных страниц и пытаемся вставить запись, соответствующую вновь созданной странице, в вышестоящую страницу.
Для этого нам придется захватит её на запись у её модуля хранения
Может случиться, что эта страница тоже переполнится и нам придётся подняться еще на шаг выше. И так вплоть до наращивания высоты дерева и создания новой корневой страницы.
В результате, после вставки новой записи мы имеем глобальную транзакцию и некоторое количество локальных транзакций. Чтобы зафиксировать вставку так и напрашивается механизм двухфазного коммита, например, XA транзакции, где менеджерами ресурсов (RM) являются модули хранения и системный реестр, а менеджером транзакций ™ — исполнительный модуль
Т.к. речь идет о параллельной работе нескольких исполнительных модулей, скорее, применима модель XA+. Вопрос, кто возьмет на себя роль CRM (communication resource manager), остаётся открытым. Скорее всего тот же, кто держит системный реестр
При создании новой страницы может оказаться, что узел хранения листовой страницы переполнен. Выбор в такой ситуации невелик — либо создать новый модуль хранения, либо прицепиться к уже существующему недозаполненному. Создавать новые модули опасно, это довольно дорогостоящий ресурс, да и их количество физически ограничено.
За списком недозаполненных модулей хранения можно обратиться в системный реестр, но реестр ничего не знает о контексте текущего запроса и способен выдать только случайный модуль. Это чревато тем, что новые страницы, прорастающие из нашего переполненного модуля начнут расползаться по всем другим модулям, разрушая локальность данных и угнетая общую производительность. Сценарий, которого хотелось бы избежать.
С другой стороны, никто не знает контекст текущего запроса лучше, чем сам текущий запрос. У нас уже есть стек прочитанных страниц, каждая из которых приписана к какому-то модулю хранения. Таким образом мы имеем возможность найти новый модуль среди вышестоящих.
В системный реестр тем не менее придётся обратиться чтобы проверять переполненность модулей
Если так случилось, что среди них нет недозаполненных (или все страницы лежат в одном модуле), можно копнуть глубже. Просмотреть содержимое всех нелистовых страниц в стеке в надежде отыскать в нем ссылки на уже использованные ранее модули хранения. Если ссылок несколько, следует выбрать ближайшую.
Можно пойти еще дальше, но для этого придётся изменить структуру страницы. Будем распространять вверх по стеку информацию об использованных модулях хранения.Заставим каждую нелистовую страницу хранить список модулей хранения, в которых расположена сама страница и все её потомки
Каждый раз после создании новой страницы и после того, как структура дерева установилась (после возможной перебалансировки, например), мы распространяем информацию о модуле хранения этой страницы вверх по стеку ее предшественников.
Если этот модуль уже зарегистрирован, ничего не происходит. В противном случае, придётся захватывать вышестоящие страницы на запись и регистрировать в них новый модуль. Как сделать так, чтобы при этом не пришлось перебалансировать дерево заново, вопрос открытый, возможно, следует ограничить число регистрируемых модулей каким-то разумным числом и резервировать место под них
Теперь, когда у нас возникнет вопрос, к какому модулю привязать новую страницу (точнее, у какого модуля хранения выпрашивать новую страницу), мы будем подниматься вверх по стеку и искать подходящий модуль в списках зарегистрированных.
Ну, а если и это не поможет, придется обращаться к системе за созданием нового модуля хранения.
Вот так втихушку мы и избавились от одномерного пространства адресов страниц. Идентификатор страницы имеет аж три размерности (ID модуля, ID диска, позиция на диске), хотя, можно было обойтись и двумя, если выкинуть идентификатор диска и возложить на модуль хранения задачу самому разбираться со своими адресами. Что это даёт? Гибкость. Например, если вдруг дерево начинает усиленно расти в каком-то локальном месте, наши адреса просто растут вширь, более-менее сохраняя свою локальность. в одномерном случае добиться этого было бы намного труднее.
Хорошо, мы создали запись в дереве, как насчет тела файла? С ними ситуация попроще т.к. тела не зависят друг от друга.Модуль хранения файла выбирается вместе со страницей, ссылка с которой на это тело указывает.
Так же, как и в случае страницы, идентификатор тела состоит из ID модуля хранения, ID диска и места на диске.
Несомненно, в модуле хранения должен существовать раздатчик дисковой памяти, один на всех или свой для каждого подключаемого диска, сейчас не важно.
Так же в данный момент не важно, как устроен этот раздатчик памяти
Зато важно, чтобы работа с телами файлов поддерживала распределенные транзакции на уровне менеджера ресурсов
Стоит отметить один тонкий момент.Допустим, некоторая листовая страница переполнилась и мы собрались её пилить.
Так получилось, что осколки страницы попали в разные модули хранения.
Но ведь в этой странице уже были какие-то записи и они указывали на диски из старого модуля.
Было бы неплохо взять и перекинуть файлы с одного модуля в другой. Но ведь эти файлы могут быть значительного размера и их перенос может занять кучу времени, чего мы не можем себе позволить
Ну и ладно, просто разрешим листовым страницам указывать на файловые диски с другого модуля хранения. Получится что-то вроде NUMA, доступ к чужим файловым дискам из модуля хранения возможен, но стоит дороже.
К счастью, это относительно редкий случай, и он не может существенно сказаться на общей производительности.
А можно представить себе демон, который будет ходить по дереву и в фоновом режиме выправлять последствия подобных эксцессов.
Пришло время посмотреть на общую картину:
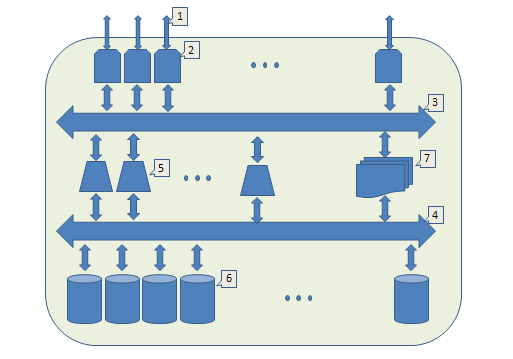 Внешний интерфейс,
Модуль ввода-вывода (IO). Принимает запросы извне, назначает исполнителя, дожидается ответа и отправляет результат. Увеличивая их количество мы масштабируем внешнюю пропускную способность
Внутренняя шина (например, локальный ethernet), через которую общаются модули IO и исполнительные модули.
Еще одна внутренняя шина. Через нее модули хранения общаются с исполнительными модулями.
Исполнительный модуль, реализует работу с деревом и управляет распределенными транзакциями. Увеличивая их количество, мы масштабируем возможности параллельного исполнения запросов.
Модуль хранения. С их помощью мы масштабируем емкость всей системы.
Системный реестр
Настала пора обратить наши взоры в реальный мир и посмотреть, как же фактически решаются описанные проблемы.
GlusterFSРассмотрим режим DHT как наиболее близкий к теме данной статьи.GlusterFS не имеет выделенного сервиса метаданных
Файлы распределяются между серверами, используя файловые системы этих серверов (со всеми их плюсами и минусами)
Файловая структура проецируется на файловые системы серверов (brick в терминах Gluster)
Утверждается, что распределенное хранение основано на технологии последовательного хэширования, но это какой-то вырожденный его случай.Полное имя файла пропускается через хэш-функцию, которая выдаёт 32-битное значение
диапазон в 32 бита заранее, при настройке системы разбивается на диапазоны — каждый из которых указывает на определенный сервер
Диапазоны можно настраивать руками, но в этом случае надо очень точно понимать что ты делаешь
Автоматическое разбиение будет производится кусками по 0xffffffff/(число серверов)
При создании файла вычисляется номер его сервера и файл создается в файловой системе этого сервера
При поиске файла, аналогичным образом вычисляется сервер, где бы ему следовало лежать
Делается попытка прочитать файл с этого сервера
если попытка безуспешна, такого файла нетрассылаются запросы на поиск этого файла ко всем серверам системы
если файл нашелся на одном из них, на исходном сервере создаётся link — файл с нужным именем, но нулевой длиной, включенным sticky-bit и xattr«ом с указанием на актуальный сервер
В следующий раз при поиске этого файла можно не делать широковещательный запрос, а сразу обратиться к нужному серверу
Как же могло случиться, что файл оказался на чужом сервере? Например, штатный сервер этого файла переполнен. Или произошло перераспределение диапазонов хэш-значения, например, после добавления нового сервера.
Добавление нового сервера инвалидирует долю в 1/(новое число серверов) хэш-значений при последовательном хэшировании. Но в случае Gluster эта доля может быть значительно больше из-за его «наивного» способа распределения диапазонов хэшей
Всё это приводит к тому, что со временем хранилище деградирует и нужно предпринимать специальные усилия чтобы поддерживать его в адекватном состоянии.«fix-layout» — ходим по ноде и пытаемся перетащить на нее файлы, доступные через Link-и «migration» — для каждого файла вычисляется сервер, где он должен быть и при необходимости делается попытка туда перенести. Весьма дорогостоящая процедура.
Источники: http://www.gluster.org/http://cloudfs.org/index.php/2012/03/glusterfs-algorithms-distribution/http://people.redhat.com/ndevos/talks/Gluster-data-distribution_20120218.pdfSWIFT
Внешний интерфейс,
Модуль ввода-вывода (IO). Принимает запросы извне, назначает исполнителя, дожидается ответа и отправляет результат. Увеличивая их количество мы масштабируем внешнюю пропускную способность
Внутренняя шина (например, локальный ethernet), через которую общаются модули IO и исполнительные модули.
Еще одна внутренняя шина. Через нее модули хранения общаются с исполнительными модулями.
Исполнительный модуль, реализует работу с деревом и управляет распределенными транзакциями. Увеличивая их количество, мы масштабируем возможности параллельного исполнения запросов.
Модуль хранения. С их помощью мы масштабируем емкость всей системы.
Системный реестр
Настала пора обратить наши взоры в реальный мир и посмотреть, как же фактически решаются описанные проблемы.
GlusterFSРассмотрим режим DHT как наиболее близкий к теме данной статьи.GlusterFS не имеет выделенного сервиса метаданных
Файлы распределяются между серверами, используя файловые системы этих серверов (со всеми их плюсами и минусами)
Файловая структура проецируется на файловые системы серверов (brick в терминах Gluster)
Утверждается, что распределенное хранение основано на технологии последовательного хэширования, но это какой-то вырожденный его случай.Полное имя файла пропускается через хэш-функцию, которая выдаёт 32-битное значение
диапазон в 32 бита заранее, при настройке системы разбивается на диапазоны — каждый из которых указывает на определенный сервер
Диапазоны можно настраивать руками, но в этом случае надо очень точно понимать что ты делаешь
Автоматическое разбиение будет производится кусками по 0xffffffff/(число серверов)
При создании файла вычисляется номер его сервера и файл создается в файловой системе этого сервера
При поиске файла, аналогичным образом вычисляется сервер, где бы ему следовало лежать
Делается попытка прочитать файл с этого сервера
если попытка безуспешна, такого файла нетрассылаются запросы на поиск этого файла ко всем серверам системы
если файл нашелся на одном из них, на исходном сервере создаётся link — файл с нужным именем, но нулевой длиной, включенным sticky-bit и xattr«ом с указанием на актуальный сервер
В следующий раз при поиске этого файла можно не делать широковещательный запрос, а сразу обратиться к нужному серверу
Как же могло случиться, что файл оказался на чужом сервере? Например, штатный сервер этого файла переполнен. Или произошло перераспределение диапазонов хэш-значения, например, после добавления нового сервера.
Добавление нового сервера инвалидирует долю в 1/(новое число серверов) хэш-значений при последовательном хэшировании. Но в случае Gluster эта доля может быть значительно больше из-за его «наивного» способа распределения диапазонов хэшей
Всё это приводит к тому, что со временем хранилище деградирует и нужно предпринимать специальные усилия чтобы поддерживать его в адекватном состоянии.«fix-layout» — ходим по ноде и пытаемся перетащить на нее файлы, доступные через Link-и «migration» — для каждого файла вычисляется сервер, где он должен быть и при необходимости делается попытка туда перенести. Весьма дорогостоящая процедура.
Источники: http://www.gluster.org/http://cloudfs.org/index.php/2012/03/glusterfs-algorithms-distribution/http://people.redhat.com/ndevos/talks/Gluster-data-distribution_20120218.pdfSWIFT
Swift является не универсальной файловой системой, а S3-совместимым хранилищем объектов. Любой объект описывается тройкой »/account/container/object», где account указывает на пользователя, container — определяемый пользователем способ группировки объектов, ну, а object — собственно путь.
Для имитации файловой системы используются сервера обработки контейнеров и аккаунтов, которые хранят данные на своих базах sqlite3
Хранилище объектов похоже на оное в GlusterFS, но использует честное последовательное хэширование, в местной терминологии это кольцо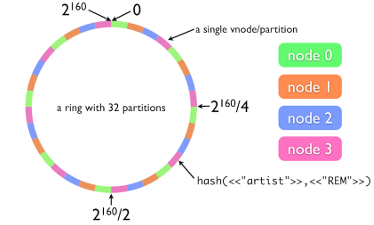 Из имени файла получается 160-битное SHA-1 хэш значение
Для хранения данных (в данном примере) используем 4 ноды
Диапазон значений хэш ключа (в данном примере) делится на 32, т.к. мы решили что нам достаточно 32 разделов
Каждый раздел закрепляется за своей нодой, возможно неравномерное распределение в соответствии с заданными весами
Таким образом по хэш значению мы узнаем номер раздела, а по нему номер ноды хранения
Нода хранения хранит файлы как есть, используя родную файловую систему (важно, чтобы она поддерживала xattrs)
Теперь, если мы решим добавить в систему пятую ноду, мы должныпереназначить пятую часть разделов каждой ноды на новую ноду
мигрировать данные, хэш -значения которых находятся в диапазонах этих переназначенных разделов на новую ноду. 8 (т.е. 32/4) разделов делятся на 5 не очень хорошо, но на больших значениях гранулярность не так заметна.
Как бы то ни было, миграция данных весьма затратная процедура, даже чтобы просто заполнить терабайтный диск нужно несколько часов. Но без миграции в рамках архитектуры с последовательным хэшированием увы никак.
Для целей репликации данных вводится понятие зоны — единицы хранения, не зависящей в отношении единичных отказов от других зон. По умолчанию каждый раздел состоит из трёх зон. Не обязательно все зоны должны быть рабочими в момент записи файла, после того, как отсутствовавшие ноды поднимутся, данные автоматически реплицируются на них.
Свои кольца есть и у серверов контейнеров и аккаунтов, Их sqlite3 базы тоже хранятся и реплицируются на нодах хранения.
Источники: http://docs.openstack.org/developer/swift/http://habrahabr.ru/company/mirantis_openstack/blog/176195/https://julien.danjou.info/blog/2012/openstack-swift-consistency-analysisCephFS
Из имени файла получается 160-битное SHA-1 хэш значение
Для хранения данных (в данном примере) используем 4 ноды
Диапазон значений хэш ключа (в данном примере) делится на 32, т.к. мы решили что нам достаточно 32 разделов
Каждый раздел закрепляется за своей нодой, возможно неравномерное распределение в соответствии с заданными весами
Таким образом по хэш значению мы узнаем номер раздела, а по нему номер ноды хранения
Нода хранения хранит файлы как есть, используя родную файловую систему (важно, чтобы она поддерживала xattrs)
Теперь, если мы решим добавить в систему пятую ноду, мы должныпереназначить пятую часть разделов каждой ноды на новую ноду
мигрировать данные, хэш -значения которых находятся в диапазонах этих переназначенных разделов на новую ноду. 8 (т.е. 32/4) разделов делятся на 5 не очень хорошо, но на больших значениях гранулярность не так заметна.
Как бы то ни было, миграция данных весьма затратная процедура, даже чтобы просто заполнить терабайтный диск нужно несколько часов. Но без миграции в рамках архитектуры с последовательным хэшированием увы никак.
Для целей репликации данных вводится понятие зоны — единицы хранения, не зависящей в отношении единичных отказов от других зон. По умолчанию каждый раздел состоит из трёх зон. Не обязательно все зоны должны быть рабочими в момент записи файла, после того, как отсутствовавшие ноды поднимутся, данные автоматически реплицируются на них.
Свои кольца есть и у серверов контейнеров и аккаунтов, Их sqlite3 базы тоже хранятся и реплицируются на нодах хранения.
Источники: http://docs.openstack.org/developer/swift/http://habrahabr.ru/company/mirantis_openstack/blog/176195/https://julien.danjou.info/blog/2012/openstack-swift-consistency-analysisCephFS
Имеет выделенный сервис метаданных — Metadata Cluster, состоящий из нескольких Metadata Storage (MDS) в терминах Ceph
Данные хранятся на Object Storage Data (OSD)
В том числе на ODS хранят свои данные и MDS
Структура файловой системы явным образом описана в MDS Изменения в файловой системе журналируются и реплицируются на ODS.
Считается, что MDS должен большей частью работать с кэшем и читать данные с ODS только в крайнем случае. Поэтому в какой-то момент MDS переполняется.
Переполненный MDS расщепляется. Для того, чтобы безболезненно сделать этоВыглядит это примерно так 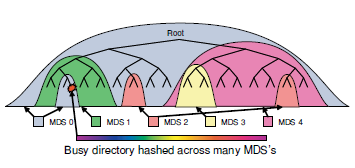 Каждый MDS измеряет популярность своих поддиректорий, используя счетчик обращений с экспоненциальным затуханием по времени. Каждая операция с директорией увеличивает этот счетчик у самой директории и всех ее вышестоящих директорий этого MDS
При переполнении MDS, вычленяется подходящая под-иерархия и переносится в другой MDS
Делается это незаметно для пользователей, используя транзакционные механизмы
Если обнаружена сверх-популярная директория, обращения к которой сильно превосходят всё остальное, есть механизм размазать эту директорию по нескольким MDS
Для записи данных в ODS используется алгоритм CRUSHНа основании пути, описания иерархии хранилища и политики распределения, вычисляется место, где физически располагается (будет располагаться) нужный файл.
Алгоритм работает так, чтобы исключить потерю данных при любом одиночном отказе.
Например, у нас есть несколько залов со стойками, отдельный зал может быть затоплен или в нём возникнет пожар. Если у нас несколько ethernet интерфейсов, любой из них может отвалиться. Стойки могут быть запитаны от разных источников энергии, причем источник может иссякнуть.
Иерархия настраивается, например, так — в каждом зале стойки группируются по источникам питания и по интерфейсу.
И, если политика репликации CRUSH настроена на хранении в трёх экземплярах, для хранения файла алгоритм выдаст такие три ODS, что каждый из них будет в своём зале, со своим интерфейсом и запитаны они все будут от разных источников.
Помимо всего этого предпринимаются усилия по минимизации работ, которые необходимо проделать при миграции данных в случае разрастания хранилища.
Помимо работы Ceph в режиме ФС (CephFS) есть более низкоуровневый S3 совместимый интерфейс: RADOS. Ceph S3 и CephFS и прочая фактически являются надстройками над ним. Концептуально RADOS аналогичен SWIFT с другой хэширующей функцией — вместо колец работает CRUSH.
Источники: http://ceph.com/http://ceph.com/papers/weil-ceph-osdi06.pdfhttp://ceph.com/papers/weil-mds-sc04.pdfhttp://ceph.com/papers/weil-crush-sc06.pdfhttp://ceph.com/papers/weil-rados-pdsw07.pdfЛюбопытно наблюдать, как в существующих решениях народ пытается обойти объективные проблемы, связанные с опорой на определяемую пользователями структуру файловой системы.
Каждый MDS измеряет популярность своих поддиректорий, используя счетчик обращений с экспоненциальным затуханием по времени. Каждая операция с директорией увеличивает этот счетчик у самой директории и всех ее вышестоящих директорий этого MDS
При переполнении MDS, вычленяется подходящая под-иерархия и переносится в другой MDS
Делается это незаметно для пользователей, используя транзакционные механизмы
Если обнаружена сверх-популярная директория, обращения к которой сильно превосходят всё остальное, есть механизм размазать эту директорию по нескольким MDS
Для записи данных в ODS используется алгоритм CRUSHНа основании пути, описания иерархии хранилища и политики распределения, вычисляется место, где физически располагается (будет располагаться) нужный файл.
Алгоритм работает так, чтобы исключить потерю данных при любом одиночном отказе.
Например, у нас есть несколько залов со стойками, отдельный зал может быть затоплен или в нём возникнет пожар. Если у нас несколько ethernet интерфейсов, любой из них может отвалиться. Стойки могут быть запитаны от разных источников энергии, причем источник может иссякнуть.
Иерархия настраивается, например, так — в каждом зале стойки группируются по источникам питания и по интерфейсу.
И, если политика репликации CRUSH настроена на хранении в трёх экземплярах, для хранения файла алгоритм выдаст такие три ODS, что каждый из них будет в своём зале, со своим интерфейсом и запитаны они все будут от разных источников.
Помимо всего этого предпринимаются усилия по минимизации работ, которые необходимо проделать при миграции данных в случае разрастания хранилища.
Помимо работы Ceph в режиме ФС (CephFS) есть более низкоуровневый S3 совместимый интерфейс: RADOS. Ceph S3 и CephFS и прочая фактически являются надстройками над ним. Концептуально RADOS аналогичен SWIFT с другой хэширующей функцией — вместо колец работает CRUSH.
Источники: http://ceph.com/http://ceph.com/papers/weil-ceph-osdi06.pdfhttp://ceph.com/papers/weil-mds-sc04.pdfhttp://ceph.com/papers/weil-crush-sc06.pdfhttp://ceph.com/papers/weil-rados-pdsw07.pdfЛюбопытно наблюдать, как в существующих решениях народ пытается обойти объективные проблемы, связанные с опорой на определяемую пользователями структуру файловой системы.
В CephFS прибегают к перебалансировке на основе подсчета кумулятивной популярности потомков. Такое решение не гарантирует сбалансированности дерева, например, дерево, которое растёт только в одну сторону (например, вправо вниз) так и останется несбалансированным.
Еще одна видимая проблема с CephFS заключается в распространении популярности. Фактически, любое обращение к файлу, которое влияет на популярность, должно распространиться до самого корня. При этом соответствующая директория перед обновлением популярности должна захватываться на запись плюс затраты на журналирование. Немного слишком расточительно, ситуацию спасает то, что вся верхушка дерева находится в памяти и эти блокировки относительно дешевы.
А в S3-совместимых системах можно увидеть принудительное балансирование дерева административным давлением — в пути всегда три директории. В большинстве практических случаев этого достаточно или можно приспособиться. Впрочем, приспособиться можно и к деревянной ноге и ко крюку вместо руки.
Подводя итоги. Что отличает предложенный подход от существующих решений? Логическая целостность и концептуальная ясность. Разделение данных и метаданных «само по себе и не ново»©. Однако, мы отказались от привязки к пользовательской структуре файловой системы. Да и предложенный механизм распределенных транзакций выглядит предпочтительнее неизбежной миграции данных при изменениях емкости системы.PS Автор выражает признательность Александру Артюшину (DataEast), Алексею Князеву (2ГИС) и Алексею Медведчикову (2ГИС) за помощь в подготовке данной работы.
PPS В шапке статьи использован кадр из к.ф. «Индиана Джонс: в поисках утраченного ковчега».
