В очередь, ...! Как управлять состоянием системы через события
 Х/ф «Собачье сердце»
Х/ф «Собачье сердце»
Существует множество разных подходов к построению архитектуры серверных приложений. В данной статье рассмотрим Event-driven архитектуру (она же событийно-ориентированная). Рассмотрим основные принципы, как перейти от связей Компонент А <-> Компонент В, к связям через события Компонент А → Событие B → Компонент B, и зачем это нужно.
Немного скучной теории
Любое программное обеспечение можно представить в очень упрощённом виде:
 рис. 1
рис. 1
У нас есть программа, которая реализует некоторую бизнес-логику. В подавляющем большинстве случаев, программа не работает сама по себе в вакууме. Она берет определенные данные (входящие данные), некоторым образом их преобразует и отдает вовне (исходящие данные).
Входящими данными могут быть:
Файлы на диске;
Пользовательский ввод;
Данные полученные по сети;
Данные полученные от другой программы;
И т.д.
Исходящими данными могут быть:
Данные отображаемые на мониторе;
Распечатка на бумаге;
Данные переданные по сети;
Запись в БД.
И т.д.
Конечно, реальные системы намного сложнее. Они делятся на кучу подсистем и компонентов, которые связаны между собой:
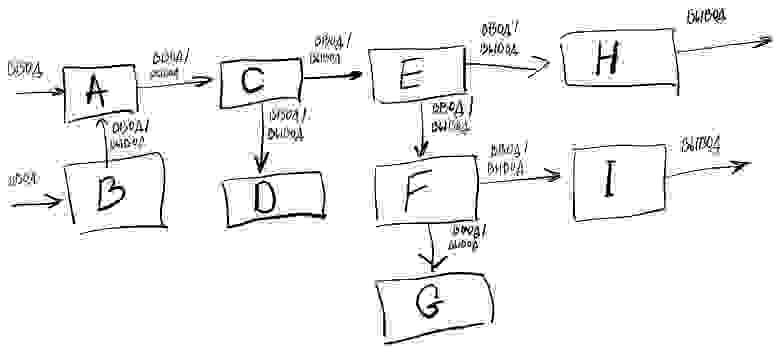 рис. 2
рис. 2
В данном примере компонентами системы являются блоки A-I.
Между ними есть связи, которые обозначают обмен данными между компонентами. Так, каждая связь является исходящими данными для одного компонента и входящими для другого.
Компоненты A и B принимают данные извне.
Компоненты H и I отдают данные наружу.
На этой схеме можно заметить, что главным связующим элементом нашей системы, состоящей из разрозненных компонентов, являются данные. То, как эти данные двигаются из одних компонентов в другие, отображают связи в нашей системе.
В процессе разработки мы структурируем наши данные, описывая их в привычные нам модели/сущности, которые перетекают в том или ином виде между компонентами.
В больших и сложных системах потоки данных могут быть очень разветвлёнными и иногда даже запутанными. Для того, чтобы упростить схему связей между компонентами, мы можем ориентироваться не на то, какие данные и в какой компонент нужно передавать, а на события, которые происходят с нашими данными, то есть с сущностями.
Event-driven (или событийно-ориентированная) архитектура основана на событиях, которые происходят с сущностями в нашей системе.
Например, рассмотрим небольшую часть системы, отвечающую за создание заказа:
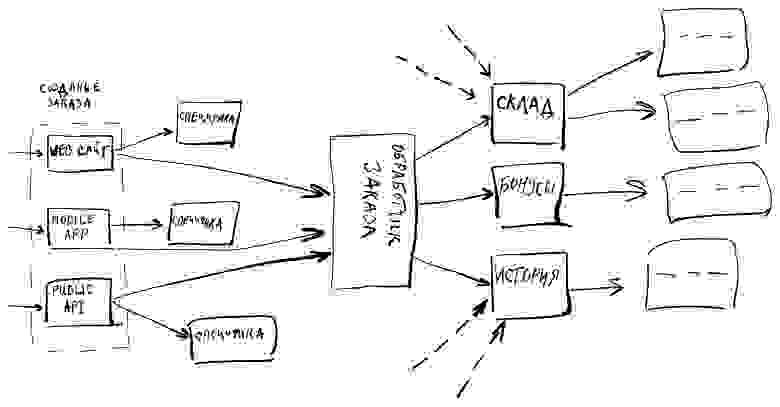 рис. 3
рис. 3
У нас есть несколько точек создания заказа: веб-сайт, мобильное приложение и публичное API (для наших партнеров). Для каждого канала у нас есть специфичные для него действия, это могут быть вещи связанные с аналитикой или чем-то еще, что нам важно внутри нашего бизнес-процесса.
Дальше у нас есть некоторый процессор, который обрабатывает сам заказ: передает информацию о нем на склад для компоновки, начисляет бонусы клиенту, записывает заказ в историю клиента, считает статистику и т.д. Причем действия, связанные с компонентами склада, бонусов и истории, могут вызываться и из других частей нашей системы. Это создает сильную связность системы, усложняет её поддержку и дальнейшее расширение.
Если мы переходим на событийно-ориентированную архитектуру системы, эта схема могла бы выглядеть следующим образом:
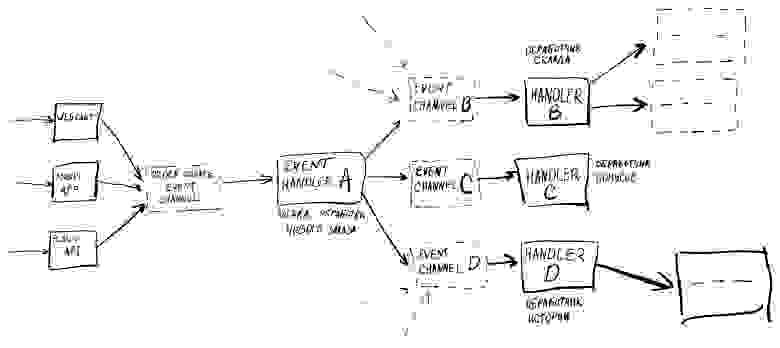 рис. 4
рис. 4
Каждая точка создания заказа (веб-сайт, мобильное приложение и публичное API) генерирует событие создания заказа. Эти события складываются в выделенный для них канал, который слушает специальный обработчик (event handler A).
Наш Event Handler A принимает событие и создает на основе него три новых события, адресованных для разных подсистем: Склада (Handler B), Бонусов (Handler C) и Истории (Handler D), и отправляет их в соответствующие каналы. В эти каналы события могут поступать из разных источников, но для соответствующих обработчиков они являются единственной точкой входа. В такой архитектуре мы можем выделить основные элементы:
Сущность (Order, User, etc.);
Событие, связанное с сущностью (Order create event, etc.);
Генератор событий (Web-сайт, Mobile app, etc.);
Канал событий (Event channel B, etc.);
Обработчик событий (Event handler A, etc.).
Такой подход позволяет нам сильно уменьшить связность нашей системы и упростить её поддержку и расширяемость. Также это позволяет обрабатывать тяжелые операции независимо друг от друга в асинхронном формате.
Основные элементы архитектуры
Сущность — любая сущность в системе, которая имеет некоторое состояние. Обычно является моделью в нашей системе. Примерами могут быть: заказы, пользователи, сообщения, корзина покупок и т.д.
Событие — событие может произойти при создании/удалении сущности или изменения её состояния. Примеры: создание заказа, смена его статуса, регистрация пользователя, добавление товара в корзину, прочтение сообщения, отмена заказа, удаление товара из корзины и т.д. Каждое событие представляет из себя простую структуру, которая содержит тип события и данные, которые позволяют это событие нужным образом обработать. В нашем случае это может быть простой JSON объект:
{
"event_type": "order_create",
"data": {
"order_id": 12345
}
}Генератор событий — компонент системы, который реализует логику создания или изменения состояния сущности. Например, веб-форма оформления заказа создает сущность заказа и генерирует соответствующее событие.
Канал событий — механизм передачи события от его генератора к обработчику. Это может быть специальный файл, сеть, очередь, БД.
Обработчик — компонент, который принимает события из канала, и реализует некоторую бизнес-логику обработки этих событий. В рамках бизнес-логики обработчика могут быть сгенерированы новые события и отправлены в соответствующие события. Тем самым мы можем получить целый каскад из каналов и их обработчиков, как это показано на рисунке 4.
Где применим данный подход
Исходя из рассмотренного нами примера, можно сделать вывод, что такая архитектура хорошо показывает себя в больших системах, где есть тяжелая бизнесс логика, которая может быть декомпозирована на последовательные или параллельные шаги выполнения. Там, где нам не требуется синхронного взаимодействия с клиентами. То есть в большинстве систем :)
Данный подход не требует полного переписывания проекта с нуля, он может внедряться в уже существующих системах, построенных на (микро)сервисной архитектуре или в монолитах. Основная задача — разбить связи между компонентами Компонент А → Компонент Б, переведя их на схему: Компонент А, генерация события → канал → обработчик Компонента Б.
Как бы это могло выглядеть в (микро)сервисной архитектуре:
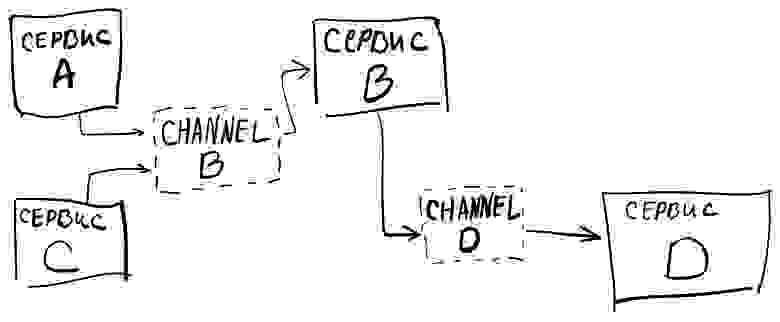 рис. 5
рис. 5
И как бы это могло выглядеть в рамках монолита:
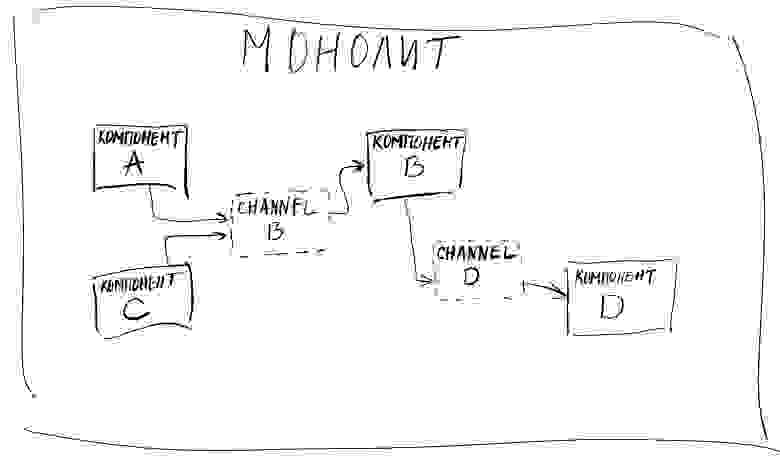 рис. 6
рис. 6
¯\_(ツ)_/¯
Поговорим про инструменты
В рамках данной статьи будет очень сложно глубоко рассмотреть различные инструменты и провести их сравнительный анализ. Однако, я попробую рассмотреть в общих чертах инструменты и технологии, которые мы можем использовать для построения событийно-ориентированной архитектуры в рамках PHP-стека.
Сущности, события, генераторы
Кажется, здесь всё выглядит достаточно просто: берем свой любимый фреймворк (symfony, laravel, yii, свой самописный велосипед) и разрабатываем на нём.
Каналы событий
Так как нам нужно передавать данные между компонентами/сервисами, будем использовать подходящие для этого инструменты:
RabbitMQ — популярный брокер очередей, который позволяет строить сложный роутинг сообщений в очередях.
Kafka — event-streaming платформа, которая позволяет пропускать через себя огромное количество событий, сохранять их и переиспользовать в будущем, а также при необходимости заново обрабатывать, начиная с какого-то определенного события в прошлом.
Redis — in-memory key-value СУБД, которая из коробки поддерживает кучу структур данных и операций с ними, на основе которых можно строить собственные реализации очередей. А если не хватает функциональности из коробки — её можно расширить самописными Lua-скриптами.
SQS — если вы пользуетесь облачной инфраструктурой, можно попробовать SQS или его аналоги. Простой инструмент, которым можно пользоваться из коробки, не нужно заморачиваться с установкой и настройкой — берёте и используете. Облачный провайдер берёт заботы по администрированию на себя.
Выбираем любой из тех, которые мы знаем. Если ничего из этого не знаем — гуглим документацию. Благо для базового использования очередей нам не нужно иметь глубокой экспертизы по какому-то конкретному инструменту. Для любого фреймворка можно найти соответствующую библиотеку.
Обработчики событий
А теперь самое интересное: как же нам обрабатывать информацию из очередей? Самым очевидным решением являются демоны — программы/скрипты, которые работают в фоне в системе, они постоянно считывают информацию из очереди, и при получении сообщения оттуда — обрабатывают его.
Все мы знаем, что PHP был создан для того, чтобы постоянно умирать :)
Каждый раз, когда к нам приходит запрос от клиента, мы поднимаем PHP-скрипт, в рамках его выполнения отрабатывает бизнес-логика, после чего скрипт завершает свою работу.
Для того, чтобы скрипт запустился, достаточно реализовать нашу бизнес-логику внутри бесконечного while цикла.
С 7-ой версии PHP это стало работать достаточно стабильно, память перестала постоянного утекать в неизвестном направлении, но конечно же, такого простого хака не хватает для того, чтобы получить полноценных демонов. Нам нужно правильным образом научиться управлять нашими демонами: запускать и останавливать в безопасной точке, чтобы не прерывать исполнение нашей бизнес-логики где-то на середине задачи. Если наш скрипт по какой то причине умрёт, он должен автоматически перезапускаться.
Я не буду останавливаться на реализации всей этой функциональности демонов, так как это выходит за рамки текущей статьи, благо для каждого современного фреймворка уже существует ни одна реализация команд демонов.
Также можно посмотреть в сторону таких проектов как ReactPHP, roadrunner, либо за пару вечеров накидать свою реализацию демонов на PHP и process manager для них, который будет соответствовать вашим требованиям.
Пишем своего чат-бота на event-driven архитектуре
Пользователь пишет нашему погодному боту в Telegram сообщение «Привет бот! Какая завтра погода?». Telegram отправляет нашему серверу вебхук о полученном сообщении. Мы должны обработать этот вебхук и отправить пользователю по Telegram API нужный ответ.
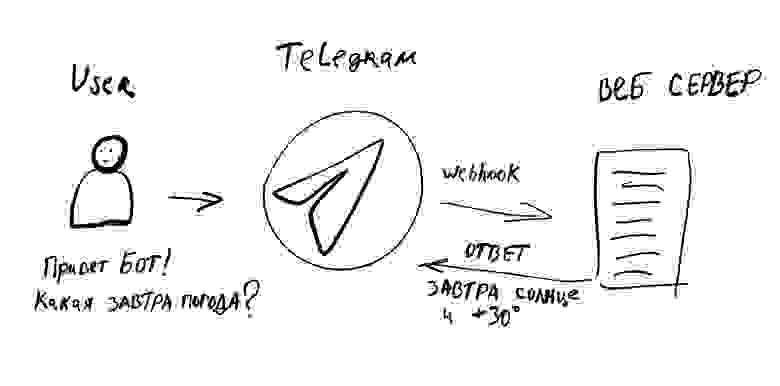 рис. 7
рис. 7
Как мог бы выглядеть обычный контроллер по обработке вебхука от Telegram?
getHttpInput();
if (false === $this->validateInput($input)) {
throw new HttpException('Wrong data', 400);
}
// Создаем нашу сущность Message на основе данных из вебхука
$message = MessageBuilder::build($input);
$message->save(); // сохраняем в БД
// Добавляем сообщение в движок полнотекстового поиска
FullTextSearch::addToIndex($message);
// Считаем статистику с учетом нового сообщения
Statistics::add($message);
// Проверяем текст сообщения, если там есть запрос на погоду
// идем во внешнее API, запрашиваем погоду на завтра.
// После этого отправляем прогноз погоды
// пользователю через Telegram API
if (TextMatch::contains($message->text, 'погода')) {
$weather = WeatherAPI::getTomorrowWeather();
TelegramAPI::send($message->userId, $weather);
}
// Отвечаем платформе Telegram, что успешно обработали сообщение
return HttpResponse('ok', 200);
}
}Да, здесь максимально упрощенная реализация, зато она наглядно показывает, что здесь происходит. Мы видим, что здесь выполняются 6 последовательных действий, до того как клиент в виде Telegram-платформы получит от нас ответ, что мы обработали вебхук.
Получение и валидация входящих данных;
Создание и сохранение сущности Message в БД;
Добавление сущности Message в движок полнотекстового поиска;
Подсчет статистики;
Запрос прогноза погоды из стороннего сервиса;
Отправка сообщения с прогнозом погоды пользователю в Telegram.
Некоторые из этих действий могут быть достаточно ресурсоёмкими и выполняться продолжительное время. Особенно подсчёт и агрегация статистики, запросы к сторонним сервисам. Пока все эти действия будут последовательно обрабатываться, клиент будет держать соединение с сервером в ожидании ответа. Долгое ожидание ответа не всегда приемлемо для работы со сторонними сервисами. А что будет, если нагрузка на этот endpoint будет 100 RPS? 10»000 RPS? В какой-то момент наш сервер просто перестанет принимать новые подключения, так как весь пул будет исчерпан.
Поразмыслив над этой ситуацией, мы можем прийти к выводу, что нашему клиенту (в лице Telegram-платформы) абсолютно все равно, что мы делаем с полученным вебхуком. Единственное, что он хочет знать — получили ли мы сообщение с вебхуком. Это применимо для любой обработки вебхуков. В примере с заказом в интернет магазине нашему клиенту важно знать, что мы получили его заказ, и ему не нужно ждать пока мы этот заказ реально обработаем на стороне склада и других связанных компонентов. Соответственно, все операции мы можем делать асинхронно, не удерживая соединение с клиентом.
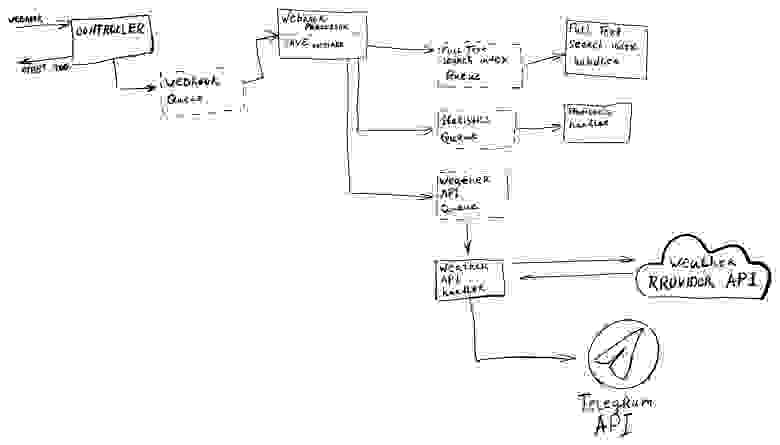 рис. 8
рис. 8
Мы принимаем вебхук от Telegram-платформы, складываем его в соответствующую очередь (Событие: вебхук пришел), и сразу же отдаем успешный ответ клиенту.
Дальше у нас есть некий WebhookProcessor, который считывает сообщения из очереди вебхуков: валидирует их, создает на основе них сущности Message и сохраняет их в БД.
getHttpInput();
// Закидываем в очередь наш вебхук
Queue::push('WebhookCreate', $input);
// Отвечаем платформе Telegram, что успешно обработали сообщение
return HttpResponse('ok', 200);
}
}Теперь наш контроллер по обработке вебхуков выглядит так. Логика максимально простая, клиент получает ответ максимально быстро.
Дальше нам нужно обработать очередь событий WebhookCreate.
isSafePoint()) {
$webhook = Queue::pull('WebhookCreate');
if (null === $webhook) {
sleep(1);
continue;
}
if (false === $this->validateInput($webhook)) {
Log::error('Invalid webhook format');
continue;
}
// Создаем нашу сущность Message на основе данных из вебхука
$message = MessageBuilder::build($webhook);
$message->save(); // сохраняем в БД
//Генерируем соответствующие события
Queue::push('FullTextSearchIndexAdd', $message);
Queue::push('StatisticsAdd', $message);
Queue::push('WeatherAPIRequest', $message);
}
}
}Для каждой очереди с созданными событиями FullTextSearchIndexAdd, StatisticsAdd, WeatherAPIRequest нам нужно создать свой обработчик.
isSafePoint()) {
$message = Queue::pull('WeatherAPIRequest');
if (null === $message) {
sleep(1);
continue;
}
// Идём во внешнее API, запрашиваем погоду на завтра.
// После этого отправляем прогноз погоды
// пользователю через Telegram API
$weather = WeatherAPI::getTomorrowWeather();
TelegramAPI::send($message->userId, $weather);
}
}
}Weather API request handler делает запрос во внешнее API и отправляет полученный прогноз нашему пользователю в Telegram API.
Масштабирование
Данную схему достаточно просто горизонтально масштабировать при росте нагрузки на сервис. Рассмотрим это на примере обработки входящих вебхуков:
 рис. 9
рис. 9
Мы можем распределять большое количество получаемых вебхуков в разные очереди одного типа удобным нам способом. Например, $message→id % 10 = M, отправляем это сообщение в очередь Webhook Queue M. Обрабатываться этот вебхук будет соответственно нашим Webhook Handler M. Разные очереди и их обработчики могут жить на разных инстансах серверов независимо друг от друга. Тем самым мы получаем простое горизонтальное масштабирование.
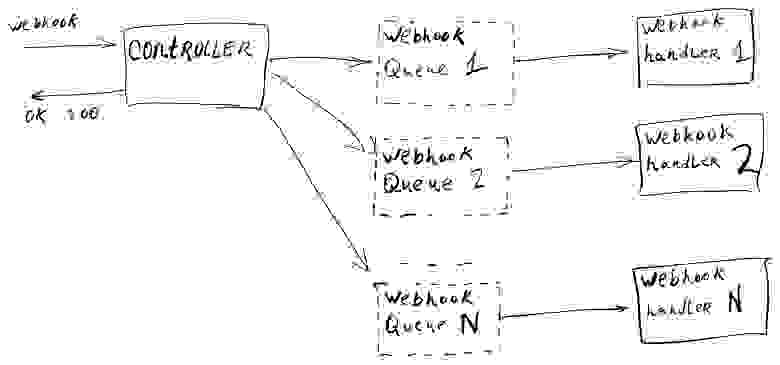 рис. 10
рис. 10
Что еще важно учитывать при работе с event-driven архитектурой
Идемпотентность
Это свойство системы, когда при применении одной и той же операции на один и тот же объект, мы всегда получаем одинаковый результат. Важно следить за соблюдением этого свойства, чтобы не нарушить логику работы системы и не потерять консистентность. Каждое событие попавшее в наш обработчик должно быть обработано только один раз. Могут возникнуть такие ситуации, что одно и то же событие может попасть в обработку несколько раз. Мы должны проверять следующие вещи:
Может ли событие быть успешно обработано при попадании в консьюмер?
Было ли это событие уже успешно обработано?
Если событие было взято в обработку, но успешно не завершено, нам нужно правильным образом восстановить контекст обработки и начать с места ошибки.
Для этого нам нужно использовать достаточный уровень логирования/журналирования обработки наших событий. Логика обработки событий должна быть гранулированной, чтобы обеспечить идемпотентность.
Конкурентность
В многопоточной обработке событий всегда нужно учитывать, что несколько процессов могут работать с общим ресурсом. Чтобы избежать непредсказуемого результата на выходе, нужно использовать блокировки, мьютексы и прочие подходы, применимые в multithread-программировании. Советую изучить базовые принципы многопоточного программирования.
Debug
Дебажить подобные системы не всегда просто. Рекомендую в сообщения, передаваемые через очереди по разными подсистемам, закладывать сквозной uuid сообщения, который позволит вам отслеживать их путь в рамках жизненного цикла. Также этот прием будет полезен для подробного логирования и обеспечения идемпотентности системы.
Тестирование
Чаще всего в автотесты закладывают Unit-тестирование. Безусловно, оно будет полезным для тестирования каждого отдельного компонента, но чаще всего проблемы возникают на стыке компонентов, поэтому не стоит пренебрегать интеграционными тестами.
Выводы
Event-driven архитектура позволяет нам перейти от связей внутри системы «Компонент А» → «Компонент B», к парадигме связей компонентов через события «Компонент А» → «Событие B» → «Компонент B». Тем самым, мы снижаем связность системы, делая ее более гибкой, поддерживаемой и расширяемой. Так же, мы получаем плюсы, в виде асинхронной обработки событий и более простого горизонтального масштабирования нашей системы.
