В Data Science не нужна математика (Почти)
Привет, чемпион!
Ребята с «вышкой» всё время умничают, что в Data Science нужна «математика», но стоит копнуть глубже, оказывается, что это не математика, а вышмат.
В реальной повседневной работе Data Scientist’а я каждый день использую знания математики. Притом очень часто это далеко не «вышмат». Никакие интегралы не считаю, детерминанты матриц не ищу, а нужные хитрые формулы и алгоритмы мне оперативнее просто загуглить.
Решил накидать чек-лист из простых математических приёмов, без понимания которых — тебе точно будет сложно в DS. Если ты только начинаешь карьеру в DS, то тебе будет особенно полезно. Мощь вышмата не принижаю, но для старта всё сильно проще, чем кажется. Важно прочитать до конца!
Дисклеймер: Сам я — человек с высшим образованием. Закончил бакалавриат и магистратуру Физтеха (последнее с отличием). Не буду с кем-либо спорить о том, нужен ли вышмат в работе Data Scientist’a. Просто покажу вам реальный список математических приёмов, которые я действительно часто использую в работе. Вы удивитесь, но рассчитывать вероятность достать чёрный шар из корзины мне не приходится. Я не выступаю против того, чтобы знать много и лишь хочу, чтобы получаемые знания были актуальными.
▍ Разогреваемся на простой математике
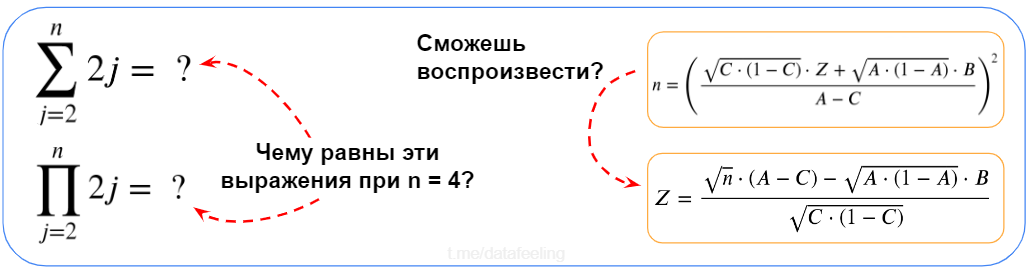
Ответь на вопросы с рисунка
Если обозначения слева тебя не пугают и ты с лёгкостью расшифруешь их при чтении научных статей, а вывод справа ты воспроизведёшь даже с закрытыми глазами, то могу сказать, что ты уже на хорошем старте. Умение выражать одни переменные через другие и понимать математические обозначения — это базовый навык, без которого ты будешь часто застревать даже в рутинных задачах. Кстати, формулы редко бывают ещё сложнее, чем я привёл.
▍ Простые преобразования функций

Ответь на вопросы с рисунка
Если ты с ходу отвечаешь на эти вопросы, значит, ты точно не пропускал в школе уроки математики и легко умеешь отражать и смещать функции. Казалось бы, тут нет ничего сложного, но эти знания я часто использую при feature engineering'е или когда просто хочу понять, как ведёт себя некоторая функция.
▍ Сложные преобразования функций
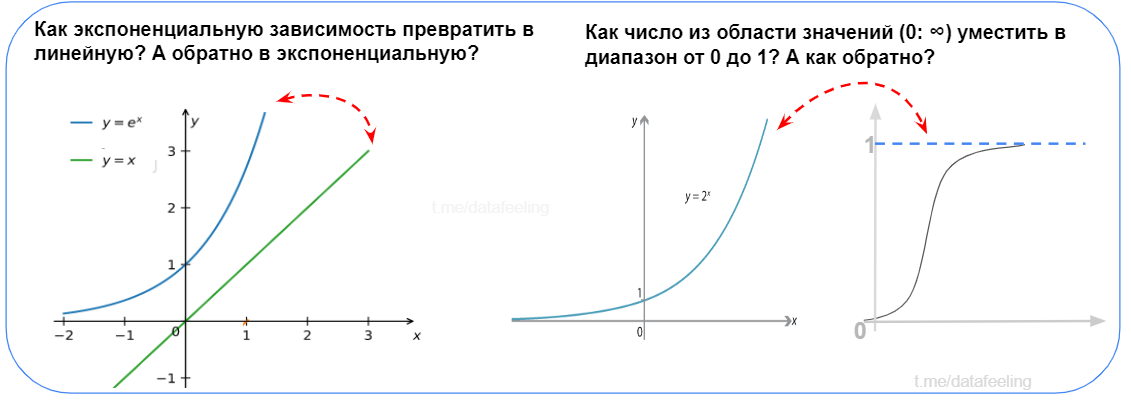
Ответь на вопросы с рисунка
Если не успело пройти и 5 секунд, а ты уже назвал в первом случае функцию логарифма, а во втором — сигмоиду в связке со сдвигом и растяжением, то ты точно уже на многое способен. Тогда различные преобразования данных в работе Data Scientist’а тебе покажутся детским лепетом.
▍ Нормирование данных

Ответь на вопросы с рисунка
Пусть ты никогда и не слышал про Min-Max Scaling или Standart Scaling, но ты с ходу придумал, как превратить диапазон значений данных в интервал от 0 до 1, то я могу только сказать — «Браво!». А если ты при этом ещё и знаешь, как среднее выборки сделать нулём, а дисперсию — равной единице, то ты нереально хорош! Кстати, такие нормировки я делал ещё на уроках физики в школе, чисто на уровне логики. В реальной работе частенько приходится нормировать данные.
▍ Геометрия
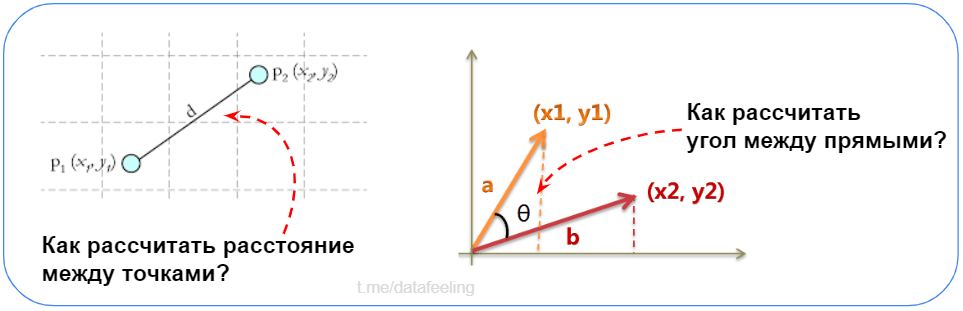
Ответь на вопросы с рисунка
Быстро ли ты вспомнил про Теорему Пифагора и формулу косинуса между двумя векторами?! Если для тебя не составило труда оперативно написать эти формулы, то смело прыгай в Data Science!
Казалось бы, зачем в Data Science знания из геометрии?! Однако, на практике эти знания дают тебе мощные инструменты и не только для информативного описания объектов новыми признаками, но и для понимания методов машинного обучения, таких как KNN, а с помощью формулы косинуса ты легко можешь решать такие задачи как face recognition или face verification и многие другие, где нужно сравнивать между собой многомерные объекты. В одном из соревнований по картинкам, мне очень пригодились эти знания.
▍ Ловим зависимости на фоне шума

Ответь на вопросы с рисунка
А в этот раз ты быстро справился? Пусть ты не знаешь ничего про p-value или что такое линейная регрессия, но если на этих вопросах у тебя как минимум закружилось в голове что-то про правило 3-х сигм или уравнение прямой а-ля y = kx + b, то поздравляю, у тебя есть хорошая начальная база. А вот если в твоей речи прозвучит ещё p-value и метод наименьших квадратов, то вряд ли бытовая рутина по очистке шумных данных в работе Data Scientist’а легко выбьет тебя из седла спокойствия.
▍ Статистики и распределения
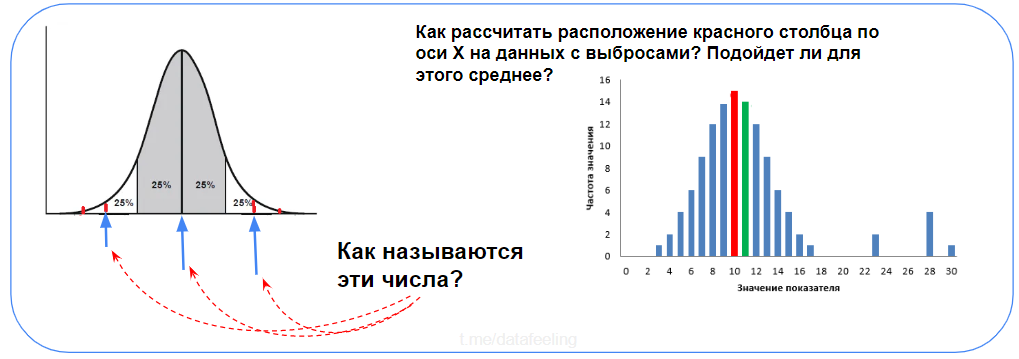
Ответь на вопросы с рисунка
Опять лёгкие вопросы? Это хороший показатель!
Со школы я знал про медиану, но вот реальную её пользу почувствовал, только когда начал работать с реальными данными, в которых крайне редко нет выбросов или другого мусора. Чтобы понять её суть, достаточно вспомнить анекдот — «Когда Билл Гейтс заходит в бар, в среднем люди в баре становятся миллиардерами». Что касается квантилей и прочих статистик, они пригодятся тебе либо при работе со статистическими критериями и проверкой гипотез, либо, как минимум — при feature engineering«а на временных рядах, где такие квантильные фичи часто хорошо себя показывают.
▍ Виды распределений
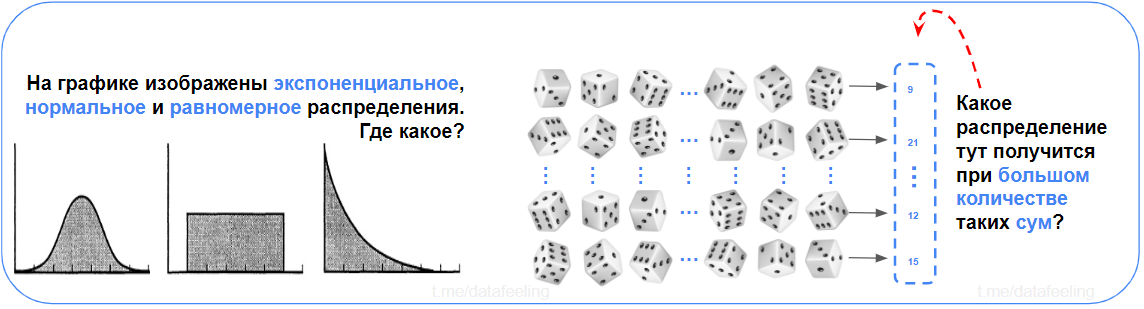
Ответь на вопросы с рисунка
Просто? И ты даже не задумался и сразу выдал ответы? Нормальное распределение ты узнаешь из тысячи? А ЦПТ ты сформулируешь, даже если ночью разбудить? — Хорош, хорош!
Не помню, чтобы в школе или вузе случалось много опираться на распределения данных, но вот на реальных задачах в работе мне с таким сталкиваться приходится. Зная распределения и их свойства, твоя математическая интуиция при работе с реальными данными становится разрушительной силой. В вопросах проверок гипотез или уже пресловутого feature engineering'а тебе будет сильно проще.
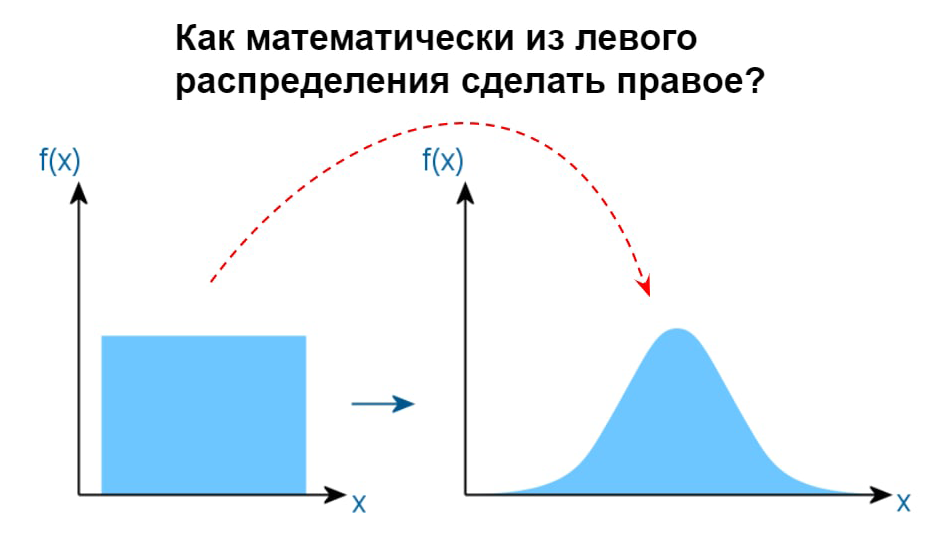
▍ Преобразование распределений
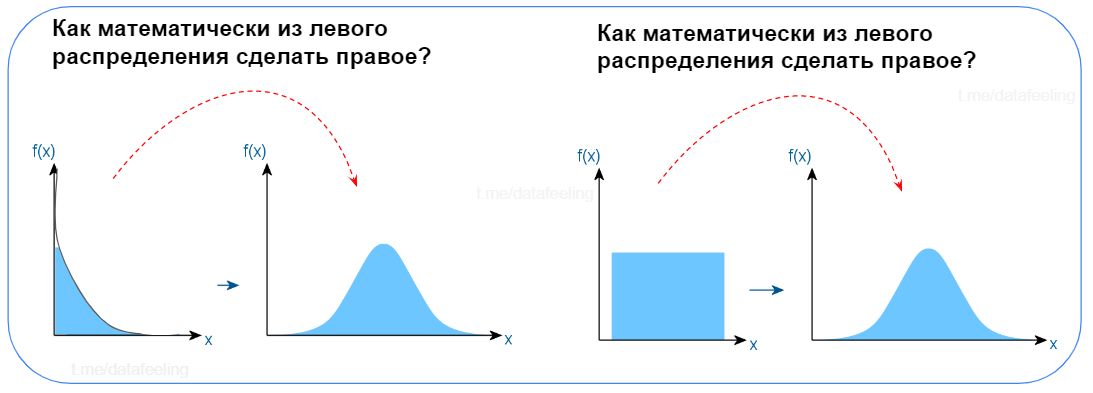
Ответь на вопросы с рисунка
Легко? Или всё-таки задумался? Такими вопросами можно сбить с толку даже опытного Data Scientist’а. Вот тут даже мои коллеги задумаются, как провернуть такие математические финты. И если для левой ситуации многие предлагают логарифмирование, то правый случай запросто может вызвать синдром самозванца. А ведь это всё та же ЦПТ из предыдущего вопроса. В народе этот метод ещё называют бустрапом. Этот приём мне часто помогает при выравнивании распределений или увеличении чувствительности статистических критериев. Мощная штука. Бери на вооружение!
▍ Временные ряды

Ответь на вопросы с рисунка
А как ты справился с этими задачами? Раз ты легко оперируешь такими понятиями, как дисперсия или квадратичное отклонение да ещё и визуально эти значения оцениваешь, то ты запросто осилишь и другие вещи по типу скользящих статистик и так далее. А чтоб убрать тренд в правом графике достаточно посчитать разницу между соседними точками ряда. При работе с временными рядами — это частая практика, до которой запросто догадаешься и без спец. курсов.
▍ Корреляция и зависимости

Ответь на вопросы с рисунка
Ещё один навык, без которого тебе будет сложно — отделять «шумные» данные от «чистых». «Шум» только мешает объяснить исследуемые эффекты или зависимости. Даже если ты не знаешь, что такое корреляция Пирсона и как её посчитать, но легко среди графиков выбираешь верный, то в целом — ты уже молодец. Ты сможешь без труда сориентироваться и объяснить, что и отчего в твоих данных зависит. А разобраться в сложных формулах или заумных названиях это уже дело времени.
▍ Производные
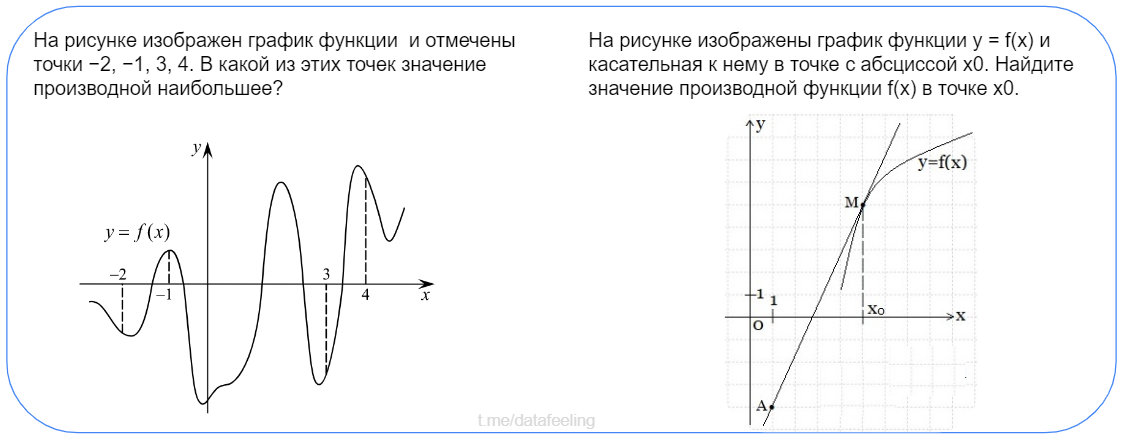
Ответь на вопросы с рисунка
Тут уж, как бы я ни лукавил, в производных разобраться всё же надо бы. Займёт максимум один вечер, но зато на выходе сможешь сразу нырять в нейронки. И вообще, поймёшь, зачем и как минимизировать хотя бы простые функции. В случае многомерных функций, за тебя уже давно все написали и реализовали, надо только понять и выработать интуицию.
▍ Заключение и главный посыл статьи
В Data Science на практике нет неподъемной математики. Не надо тратить годы на изучение вышмата, чтобы просто начать работать в этой индустрии.
Да, без более глубокой базы — тебе будет иногда сложно что-то понять или пройти собеседование. Однако стажировки и соревнования имеют порог входа в разы ниже.
Да, соревноваться с лидерами индустрии или другими кандидатами с большим опытом будет поначалу непросто, но и у тебя рано или поздно при должном усердии накопится опыт и разовьются навыки.
Да, на высоких оборотах ресёрча надо глубоко погружаться в сложные вещи. А будешь ли ты вообще в реальности заниматься исследованиями, и руками имплементировать сложные математические концепции из статей? Что если тебе вообще больше подходит инженерный подход к анализу данных? Содрать модели с Hugging Face и закинуть в прод — это тоже не всегда просто и тут уж точно вышмат тебе не сильно потребуется. Может, ты реально захочешь быть ML engineer«ом? А что если твоё — это быть Data Engineer«ом? Зачем тебе вообще тогда глубокие знания математики?!
Вижу часто острую проблему, что люди боятся начать работать в сфере, потому что им всё время кажется, что они ещё недостаточно знают. TODO-лист необходимых курсов у этих людей растёт быстрее, чем они успевают их проходить. Хватит собирать бесконечное образовательное комбо! Лучше начать практиковаться сейчас!
В случае если ты только на пороге входа в DS, то советую как можно раньше начать практиковаться в решении реальных кейсов. Уже по ходу дела навёрстывать необходимые математические знания. Будучи в реальных боевых условиях на зарплате хотя бы «джуна», ты быстрее раскачаешься, чем сперва 4 года отучишься, а уже потом придёшь работать тем же джуном, но с бОльшим запасом знаний.
Спасибо за ревью статьи Марку!

