Утки, Таиланд и T-SQL… или что может подстерегать программистов при работе с SQL Server?
Все начиналось довольно обыденно… Зачитывался Рихтером и усиленно штудировал Шилдта. Думал, что буду заниматься разработкой под .NET, но судьба на первом месяце работы распорядилась иначе. Один из сотрудников неожиданно покинул проект и во вновь образовавшуюся дыру докинули свежего людского материала. Именно тогда и началось мое знакомство с SQL Server.
С тех пор прошло чуть меньше 6 лет и вспомнить можно многое…
Про бывшего клиента Джозефа из Англии, который переосмыслил жизнь, за время отпуска в Таиланде, и в моем скайпе стал подписываться Жозефиной. Про веселых соседей по офису, с которыми приходилось сидеть в одной комнате: один страдал от аллергии на свежий воздух, а другой маялся от неразделенной любви к С++ дополняя это аллергией на солнечный свет. Один раз по команде свыше пришлось на время стать Александром отцом двух детей, чтобы изображать из себя обросшего скилами сениора по JS.
Но самый лютый треш, наверное, связан с историей про резиновую утку-пищалку. Один коллега снимал ею стресс и, однажды, в порыве эмоций, отгрыз ей голову. С тех пор уточка потеряла прежний лоск и вскоре была заменена на мячик, который он пытался иногда грызть… увы, уже безуспешно.
К чему это было рассказано? Если хотите посвятить свою жизнь работе с базами данных, то первое чему нужно научиться… так это стрессоустойчивости. Второе — это взять на вооружение несколько правил при написании запросов на T-SQL, которые многие из начинающих разработчиков не знают или попросту игнорируют, а потом сидят и ломают голову… почему что-то не работает?
1. Data TypesСамое основное, с чего начинается большинство проблем при работе с SQL Server — это неправильный выбор типов данных. Возьмем гипотетический пример с двумя идентичными по своей сути таблицами:
DECLARE @Employees1 TABLE (
EmployeeID BIGINT PRIMARY KEY
, IsMale VARCHAR(3)
, BirthDate VARCHAR(20)
)
INSERT INTO @Employees1
VALUES (123, 'YES', '2012-09-01')DECLARE @Employees2 TABLE (
EmployeeID INT PRIMARY KEY
, IsMale BIT
, BirthDate DATE
)
INSERT INTO @Employees2
VALUES (123, 1, '2012-09-01')Выполним запрос и посмотрим в чем разница:
DECLARE @BirthDate DATE = '2012-09-01'
SELECT * FROM @Employees1 WHERE BirthDate = @BirthDate
SELECT * FROM @Employees2 WHERE BirthDate = @BirthDate
В первом случае, типы данных более избыточные, чем могли бы быть. Зачем хранить битовый признак как строку YES/NO? Зачем хранить дату как строку? Зачем BIGINT по таблице с сотрудниками? Чем простой INT не подошел?
Это плохо по нескольким причинам: таблицы будут занимать больше места на диске, нужно больше страниц прочитать с диска и больше страниц разместить в BufferPool чтобы оперировать этими данными. Кроме того, могут быть и еще серьезные проблемы с производительностью — вопросительный знак об этом легко намекает, но об этом поговорим позже.
2. *Часто приходилось встречать «картину маслом»: из таблицы берутся все данные, а потом на клиенте через DataReader выбираются только те столбцы, которые реально нужны. Это крайне не эффективно, поэтому лучше не использовать подобной практики:
USE AdventureWorks2014
GO
SET STATISTICS TIME, IO ON
SELECT *
FROM Person.Person
SELECT BusinessEntityID
, FirstName
, MiddleName
, LastName
FROM Person.Person
SET STATISTICS TIME, IO OFFРазница будет и во времени выполнении запроса и в том, что будет возможность сделать меньше логических чтений за счет покрывающего индекса:
Table 'Person'. Scan count 1, logical reads 3819, physical reads 3, ...
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 1235 ms.
Table 'Person'. Scan count 1, logical reads 109, physical reads 1, ...
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 227 ms.3. Alias
Создадим таблицу:
USE AdventureWorks2014
GO
IF OBJECT_ID('Sales.UserCurrency') IS NOT NULL
DROP TABLE Sales.UserCurrency
GO
CREATE TABLE Sales.UserCurrency (
CurrencyCode NCHAR(3) PRIMARY KEY
)
INSERT INTO Sales.UserCurrency
VALUES ('USD')Предположим у нас есть запрос, который возвращает количество идентичных строк в обоих таблицах:
SELECT COUNT_BIG(*)
FROM Sales.Currency
WHERE CurrencyCode IN (
SELECT CurrencyCode
FROM Sales.UserCurrency
)И все будет работать, как мы ожидаем, до тех пор, пока кто-то не захочет переименовать столбец в таблице Sales.UserCurrency:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'Выполним запрос и увидим, что возвращается не 1 строка, а все которые есть в Sales.Currency. При построении плана выполнения SQL Server на этапе биндинга посмотрит на столбцы Sales.UserCurrency не найдет там CurrencyCode и подумает что этот столбец относится к таблице Sales.Currency после чего оптимизатор условие CurrencyCode = CurrencyCode отбросит.
Мораль — используйте алиасы:
SELECT COUNT_BIG(*)
FROM Sales.Currency c
WHERE c.CurrencyCode IN (
SELECT u.CurrencyCode
FROM Sales.UserCurrency u
)4. Column order
Предположим у нас есть какая-то таблица:
IF OBJECT_ID('dbo.DatePeriod') IS NOT NULL
DROP TABLE dbo.DatePeriod
GO
CREATE TABLE dbo.DatePeriod (
StartDate DATE
, EndDate DATE
)И данные в нее мы всегда вставляем из того предположения, что мы знаем как по порядку располагаются столбцы:
INSERT INTO dbo.DatePeriod
SELECT '2015-01-01', '2015-01-31'Потом в один прекрасный момент, кто-то поменяет порядок столбцов:
CREATE TABLE dbo.DatePeriod (
EndDate DATE
, StartDate DATE
)И данные будут уже вставляться не в те столбцы в которые ожидает разработчик. Поэтому всегда рекомендуется явно указывать столбцы в конструкции INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)
SELECT '2015-01-01', '2015-01-31'Есть еще один интересный пример:
SELECT TOP(1) *
FROM dbo.DatePeriod
ORDER BY 2 DESCПо какому столбцу будет идти сортировка? А все зависит от текущего порядка в таблице. Если кто-то его изменит, то и запрос будет выводить не то что мы ожидаем.5. NOT IN vs NULL
Бесспорный лидер среди вопросов на собеседовании Junior DB Developer — конструкция NOT IN.
Например, нужно написать пару запросов: вернуть все записи из первой таблицы, которых нет во второй и наоборот. Очень часто начинающие разработчики не заморачиваются и используют IN и NOT IN:
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1))
INSERT INTO @t1 VALUES (1), (2)
DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2))
INSERT INTO @t2 VALUES (1)
SELECT *
FROM @t1
WHERE t1 NOT IN (SELECT t2 FROM @t2)
SELECT *
FROM @t1
WHERE t1 IN (SELECT t2 FROM @t2)Первый запрос вернул нам двойку, второй — единицу. Давайте теперь во вторую таблицу добавим еще одно значение — NULL:
INSERT INTO @t2 VALUES (1), (NULL)При выполнении запроса с NOT IN мы не получим никаких результатов. Неужели какая-то магия вмешалась — IN работает, а NOT IN отказывается. Это первое, что нужно «понять и простить» при работе с SQL Server, который при операции сравнения руководствуется третичной логикой: TRUE, FALSE, UNKNOWN.
При выполнении SQL Server интерпретирует условие IN:
a IN (1, NULL) == a=1 OR a=NULLNOT IN:
a NOT IN (1, NULL) == a<>1 AND a<>NULLПри сравнении любого значения с NULL возвращается UNKNOWN. 1=NULL, NULL=NULL. Результат будет один — UNKNOWN. А поскольку у нас в условии используется оператор AND, то все выражение вернет неопределенное значение и в результате будет пусто.
Написано немного скучно. Но важно понимать, что такая ситуация встречается достаточно часто. Например, раньше столбец был объявлен как NOT NULL, потом какой-то добрый человек разрешил записывать в нее NULL значение. Итог: у клиента перестает работать отчет после того, как в таблицу попадет хотя бы одно NULL значение.
Что делать? Можно явно отбрасывать NULL значения:
SELECT *
FROM @t1
WHERE t1 NOT IN (
SELECT t2
FROM @t2
WHERE t2 IS NOT NULL
)Можно использовать EXCEPT:
SELECT * FROM @t1
EXCEPT
SELECT * FROM @t2Если нет желания много думать, то проще использовать NOT EXISTS:
SELECT *
FROM @t1
WHERE NOT EXISTS(
SELECT 1
FROM @t2
WHERE t1 = t2
)Какой вариант запроса более оптимальный? Предпочтительнее выглядит последний вариант с NOT EXISTS, который генерирует более оптимальный predicate pushdown оператор при доступе к данным из второй таблицы.
Вообще с NULL значениями много приколов. Можно поиграться с такими вот запросами:
USE AdventureWorks2014
GO
SELECT COUNT_BIG(*)
FROM Production.Product
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color = 'Grey'
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color <> 'Grey'и не получить ожидаемого результата только потому, что для NULL значений предусмотрены отдельные операторы сравнения:
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color IS NULL
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color IS NOT NULLЕще курьезнее выглядит ситуация с CHECK констрейнтами:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (
Color VARCHAR(15) --NULL
, CONSTRAINT CK CHECK (Color IN ('Black', 'White'))
)Мы создаем таблицу в которую разрешаем записывать только белые и черные цвета:
INSERT INTO #temp VALUES ('Black')(1 row(s) affected)Все работает как мы ожидаем:
INSERT INTO #temp VALUES ('Red')The INSERT statement conflicted with the CHECK constraint...
The statement has been terminated.Но давайте вставим NULL:
INSERT INTO #temp VALUES (NULL)(1 row(s) affected)Наш CHECK констрейнт не сработал, потому что для записи достаточно условия NOT FALSE, т.е. и TRUE и UNKNOWN подходят за милую душу. Есть несколько вариантов обойти эту особенность поведения: явно объявлять столбец как NOT NULL либо учитывать NULL в ограничении.6. Date format
Еще часто спотыкаются на различных нюансах с типами данных. Например, нужно получить текущее время. Выполнили функцию GETDATE:
SELECT GETDATE()Скопировали результат, вставили его в запрос как есть и убрали время:
SELECT *
FROM sys.objects
WHERE create_date < '2016-11-14'Корректно ли так делать?
Дата задается строковой константой, и в некоторой степени SQL Server позволяет вольности при ее написании:
SET LANGUAGE English
SET DATEFORMAT DMY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4Все значения практически везде однозначно интерпретируются:
----------- ----------- ----------- -----------
2016-12-05 2016-05-12 2016-05-12 2016-12-05 И это не будет приводить к проблемам до тех пор, пока запрос с такой бизнес-логикой не начнут выполнять на другом сервере, на котором настройки могут отличаться:
SET DATEFORMAT MDY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4Все эти варианты могут привести к неверному толкованию даты:
----------- ----------- ----------- -----------
2016-05-12 2016-12-05 2016-12-05 2016-12-05 Более того, подобный код может привести к ошибке как явной так и скрытой. Например, нам нужно вставить данные в таблицу. На тестовом сервере все прекрасно работает:
DECLARE @t TABLE (a DATETIME)
INSERT INTO @t VALUES ('05/13/2016')А у клиента, из-за разницы в настройках сервера, вот такой запрос будет приводить к проблемам:
DECLARE @t TABLE (a DATETIME)
SET DATEFORMAT DMY
INSERT INTO @t VALUES ('05/13/2016')Msg 242, Level 16, State 3, Line 28
The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.Так в каком же формате задавать константы для дат? Давайте посмотрим на еще один пример:
SET DATEFORMAT YMD
SET LANGUAGE English
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
GO
SET LANGUAGE Deutsch
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4В зависимости от установленного языка, константы также могут по-разному интерпретироваться:
----------- ----------- ----------- -----------
2016-01-12 2016-01-12 2016-01-12 2016-01-12
----------- ----------- ----------- -----------
2016-12-01 2016-12-01 2016-01-12 2016-01-12 И напрашивается вывод использовать последние два варианта. Сразу скажу, что явно задавать месяц — это хорошая возможность наткнуться на «же не манж па сис жур» ошибку:
SET LANGUAGE French
DECLARE @d DATETIME = '12-jan-2016'Msg 241, Level 16, State 1, Line 29
Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.Итого — остается последний вариант. Если хотите, чтобы константы с датами однозначно толковались в системе вне зависимости от настроек и фазы Луны, то указывайте их в формате YYYYMMDD без всяких тильд, кавычек и слешей.
Еще стоит обратить внимание на различие в поведении некоторых типов данных:
SET LANGUAGE English
SET DATEFORMAT YMD
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2
GO
SET LANGUAGE Deutsch
SET DATEFORMAT DMY
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2В отличии от DATETIME, тип DATE корректно интерпретируется при различных настройках на сервере:
---------- ----------
2016-01-12 2016-01-12
---------- ----------
2016-01-12 2016-12-01Но нужно ли держать этот нюанс в голове? Вряд ли. Главное помните, что задавать даты нужно в формате YYYYMMDD и не будет никаких проблем.7. Date filter
Далее рассмотрим, как фильтровать эффективно данные. Почему-то на DATETIME/DATE столбцы приходится наибольшее число костылей, так что с этого типа данных мы и начнем:
USE AdventureWorks2014
GO
UPDATE TOP(1) dbo.DatabaseLog
SET PostTime = '20140716 12:12:12'Теперь попробуем узнать, сколько строк вернет запрос за определенный день:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime = '20140716'Запрос вернет 0. Почему? При построении плана SQL Server пытается преобразовать строковую константу к типу данных столбца, по которому идет фильтрация:
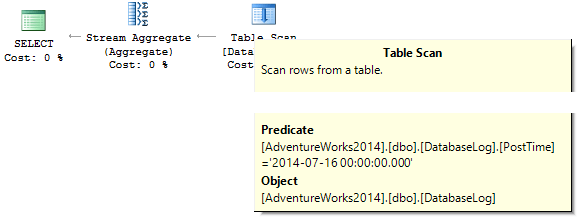
Создадим индекс:
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)Есть правильные и неправильные варианты вывести требуемые данные. Например, обрезать время:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CAST(PostTime AS DATE) = '20140716'Или задать диапазон:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140716' AND PostTime < '20140717'Именно последние два запроса более правильные с точки зрения оптимизации. И дело в том, что все преобразования и вычисления на индексных столбцах, по которым идет поиск, может резко снижать производительность и увеличивать логические чтения (первый и последние три варианта запроса):
Table 'DatabaseLog'. Scan count 1, logical reads 7, ...
Table 'DatabaseLog'. Scan count 1, logical reads 2, ...Поле PostTime ранее не входило в индекс, и особого эффекта от использования «правильного» подхода при фильтрации мы бы не смогли увидеть. Другое дело, когда нам нужно вывести данные за месяц. Чего только не приходилось видеть:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE DATEPART(YEAR, PostTime) = 2014
AND DATEPART(MONTH, PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE YEAR(PostTime) = 2014
AND MONTH(PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE EOMONTH(PostTime) = '20140731'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801'И опять же, последний вариант более приемлем, чем все остальные:

Кроме того, всегда можно сделать вычисляемое поле и создать на его основе индекс:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL
ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDay
GO
ALTER TABLE dbo.DatabaseLog
ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED
GO
CREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay)В сравнении с прошлым запросом разница в логических чтениях будет существенная (если мы говорим про большие таблицы):
SET STATISTICS IO ON
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE MonthLastDay = '20140731'
SET STATISTICS IO OFFTable 'DatabaseLog'. Scan count 1, logical reads 7, ...
Table 'DatabaseLog'. Scan count 1, logical reads 3, ...8. Сalculation
Как я уже говорил, любые вычисления на индексных полях снижают производительность и приводят к увеличению логических чтений:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT BusinessEntityID
FROM Person.Person
WHERE BusinessEntityID * 2 = 10000
SELECT BusinessEntityID
FROM Person.Person
WHERE BusinessEntityID = 2500 * 2
SELECT BusinessEntityID
FROM Person.Person
WHERE BusinessEntityID = 5000Table 'Person'. Scan count 1, logical reads 67, ...
Table 'Person'. Scan count 0, logical reads 3, ...Если взглянуть на планы выполнения, то в первом случае SQL Server приходится выполнить IndexScan:
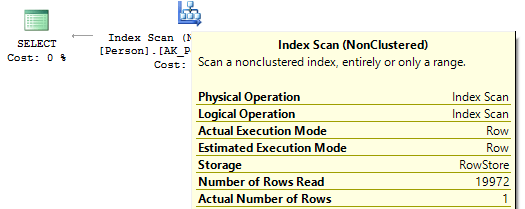
Во втором и третьем случае, когда вычисления на индексном поле, нет мы увидим IndexSeek:
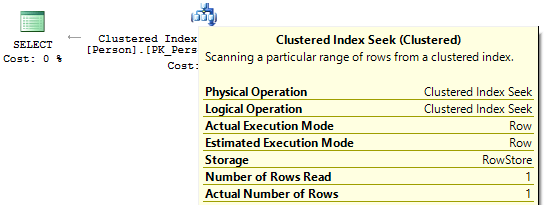
Для начала посмотрим на эти два запроса, которые фильтруют по одному и тому же значению:
USE AdventureWorks2014
GO
SELECT BusinessEntityID, NationalIDNumber
FROM HumanResources.Employee
WHERE NationalIDNumber = 30845
SELECT BusinessEntityID, NationalIDNumber
FROM HumanResources.Employee
WHERE NationalIDNumber = '30845'Если посмотреть на планы выполнения:
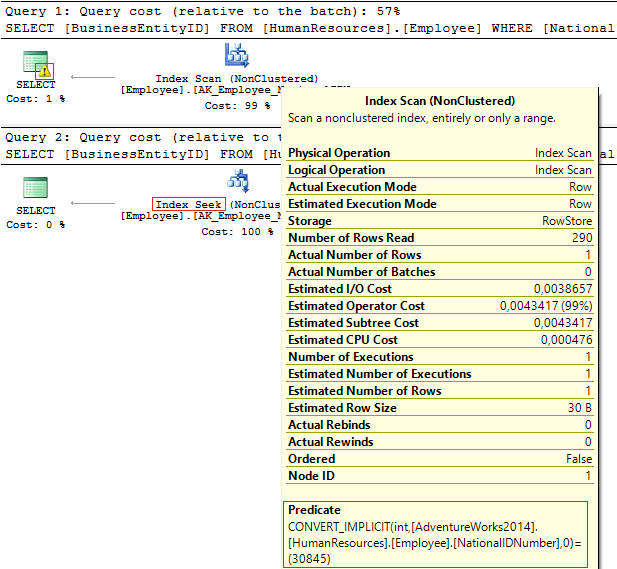
В первом случае — предупреждение и IndexScan, во втором — IndexSeek:
Table 'Employee'. Scan count 1, logical reads 4, ...
Table 'Employee'. Scan count 0, logical reads 2, ...Что произошло? Столбец NationalIDNumber имеет тип данных NVARCHAR (15). Константу, по значению которой необходимо отфильтровать данные, мы передаем как INT и в итоге получаем неявное преобразование типов, которое может снижать производительность. Такое очень часто происходит, когда кто-то меняет тип данных на столбце, но при этом запросы остаются прежними.
Однако, важно понимать, что не только проблемы с производительностью нас могут поджидать. Неявное преобразование типов может приводить к ошибкам на этапе выполнения. Например, раньше поле PostalCode было числовым, потом пришло указание сверху, что почтовый код может содержать буквы. Тип данных поменяли, но как только вставится буквенный почтовый код, то старый запрос уже не будет работать:
SELECT AddressID
FROM Person.[Address]
WHERE PostalCode = 92700
SELECT AddressID
FROM Person.[Address]
WHERE PostalCode = '92700'Msg 245, Level 16, State 1, Line 16
Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.Еще интереснее, когда на проекте используется EntityFramework, который все строковые поля по умолчанию интерпретирует как Unicode:
SELECT CustomerID, AccountNumber
FROM Sales.Customer
WHERE AccountNumber = N'AW00000009'
SELECT CustomerID, AccountNumber
FROM Sales.Customer
WHERE AccountNumber = 'AW00000009'И в итоге у нас генерируются не совсем оптимальные запросы:
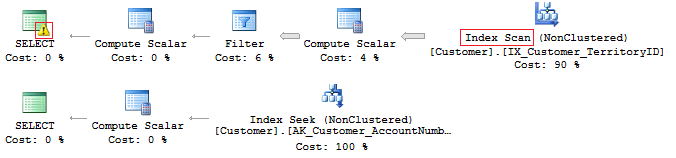
Решение проблемы достаточно простое — нужно контролировать, чтобы типы данных при сравнении совпадали.
10. LIKE & Suppressed indexДаже когда у вас есть покрывающий индекс, еще не факт что он будет эффективно использоваться. Например, нам нужно вывести все строки, которые начинаются с…
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT AddressLine1
FROM Person.[Address]
WHERE SUBSTRING(AddressLine1, 1, 3) = '100'
SELECT AddressLine1
FROM Person.[Address]
WHERE LEFT(AddressLine1, 3) = '100'
SELECT AddressLine1
FROM Person.[Address]
WHERE CAST(AddressLine1 AS CHAR(3)) = '100'
SELECT AddressLine1
FROM Person.[Address]
WHERE AddressLine1 LIKE '100%'Мы получим такие логические чтения:
Table 'Address'. Scan count 1, logical reads 216, ...
Table 'Address'. Scan count 1, logical reads 216, ...
Table 'Address'. Scan count 1, logical reads 216, ...
Table 'Address'. Scan count 1, logical reads 4, ...Планы выполнения, по которым быстро можно найти победителя:
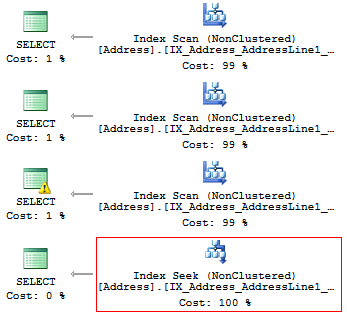
Результат является итогом, о чем мы так долго говорили до этого. Если есть индекс, то на нем не должно быть никаких вычислений и преобразований типов, функций и прочего. Только тогда он будет эффективно использоваться SQL Server.
Но что если нужно найти все вхождения подстроки в строку? Это задачка уже явно интереснее:
SELECT AddressLine1
FROM Person.[Address]
WHERE AddressLine1 LIKE '%100%'Но сначала нам нужно узнать много чего занимательного про строки и их свойства.11. Unicode vs ANSI
Первое, что нужно помнить — строки бывают UNICODE и ANSI. Для первых предусмотрены типы данных NVARCHAR/NCHAR (по 2 байта на символ — увы UTF8 не завезли). Для хранения ANSI строк — VARCHAR/CHAR (1 байт — 1 символ). Есть еще TEXT/NTEXT, но про них лучше забыть изначально (потому что при их использовании можно существенно снизить производительность).
И вроде бы на этом можно было закончить, но нет…
Если в запросе задается юникодная константа, то перед ней нужно обязательно ставить символ N. Чтобы показать разницу, достаточно простого запроса:
SELECT '文本 ANSI'
, N'文本 UNICODE'------- ------------
?? ANSI 文本 UNICODEЕсли не указывать N перед константой, то SQL Server будет пытаться искать подходящий символ в ANSI кодировке. Если не найдет, то подставит знак вопроса.12. COLLATE
Вспомнился один очень интересный пример, который любят спрашивать при собеседовании на позицию Middle/Senior DB Developer. Вернет ли данные следующий запрос?
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @bИ да… и нет… Тут как повезет. Обычно я так отвечаю.
Почему такой неоднозначный ответ? Во-первых, перед строковым константами не стоит N, поэтому они будут толковаться как ANSI. Второе — очень многое зависит от текущего COLLATE, который является набором правил при сортировки и сравнении строковых данных.
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CI_AS
GO
USE test
GO
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @bПри таком COLLATE вместо кириллицы мы получим знаки вопросов, потому что символы знака вопроса равны между собой:
---- ----
? ?Стоит нам поменять COLLATE на какой-нибудь другой:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_ASИ запрос уже не вернет ничего, потому что кириллица будет правильно интерпретироваться.
Поэтому мораль тут простая: если строковая константа должна принимать UNICODE, то не надо лениться ставить N перед ней. Есть еще и обратная сторона медали, когда N лепиться везде, где можно, и оптимизатору приходится выполнять преобразования типов, которые, как я уже говорил, приводят к неоптимальным планам выполнения (это было показано выше).
Что еще я забыл упомянуть про строки? Еще один хороший вопрос из цикла «давайте проведем собеседование»:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a = @b, 'TRUE', 'FALSE')Эти строки равны? И да… и нет… Опять ответил бы я. Если мы хотим однозначного сравнения, то нужно явно указывать COLLATE:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')Потому что COLLATE могут быть как регистрозависимыми (CS), так и не учитывать регистр (CI) при сравнении и сортировке строк. Разные COLLATE у клиента и на тестовой базе — это потенциальный источник не только логических ошибок в бизнес-логике.
Еще веселее, когда COLLATE между целевой базой и tempdb не совпадают. Создадим базу с COLLATE, отличным от дефолтного:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Albanian_100_CS_AS
GO
USE test
GO
CREATE TABLE t (c CHAR(1))
INSERT INTO t VALUES ('a')
GO
IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL
DROP TABLE #t1
IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL
DROP TABLE #t2
IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL
DROP TABLE #t3
GO
CREATE TABLE #t1 (c CHAR(1))
INSERT INTO #t1 VALUES ('a')
CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)
INSERT INTO #t2 VALUES ('a')
SELECT c = CAST('a' AS CHAR(1))
INTO #t3
DECLARE @t TABLE (c VARCHAR(100))
INSERT INTO @t VALUES ('a')
SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation')
UNION ALL
SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')
UNION ALL
SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t
UNION ALL
SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1
UNION ALL
SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2
UNION ALL
SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3
UNION ALL
SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @tПри создании таблицы COLLATE наследуется от базы данных. Единственное отличие — для первой временной таблицы, для которой мы явно определяем структуру без указания COLLATE. В этом случае она наследует COLLATE от базы tempdb.
------ --------------------------
tempdb Cyrillic_General_CI_AS
test Albanian_100_CS_AS
t Albanian_100_CS_AS
#t1 Cyrillic_General_CI_AS
#t2 Albanian_100_CS_AS
#t3 Albanian_100_CS_AS
@t Albanian_100_CS_ASСейчас остановимся на нашем примере с #t1, потому что если COLLATE не совпадают — это может привести к потенциальным проблемам.
Например, данные не будут правильно фильтроваться из-за того, что COLLATE может не учитывать регистр:
SELECT *
FROM #t1
WHERE c = 'A'Либо SQL Server будет ругаться на невозможность соединения таблиц из-за различающихся COLLATE:
SELECT *
FROM #t1
JOIN t ON [#t1].c = t.cПоследний пример очень часто встречается. На тестовом сервере все идеально, а когда развернули бэкап на сервере клиента, то получаем ошибку:
Msg 468, Level 16, State 9, Line 93
Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.После чего приходится везде делать костыли:
SELECT *
FROM #t1
JOIN t ON [#t1].c = t.c COLLATE database_default13. BINARY COLLATE
Теперь, когда «ложка дегтя» пройдена, посмотрим, как можно использовать COLLATE с пользой для себя. Помните пример про поиск подстроки в строке?
SELECT AddressLine1
FROM Person.[Address]
WHERE AddressLine1 LIKE '%100%'Данный запрос можно существенно оптимизировать и сократить время его выполнения.
Но для того, чтобы была видна разница, нам нужно сгенерировать большую таблицу:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CS_AS
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB)
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB)
GO
USE test
GO
CREATE TABLE t (
ansi VARCHAR(100) NOT NULL
, unicod NVARCHAR(100) NOT NULL
)
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO t
SELECT v, v
FROM (
SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '')
FROM E8
) tСоздадим вычисляемые столбцы с бинарными COLLATE, не забыв при этом создать индексы:
ALTER TABLE t
ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2
ALTER TABLE t
ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2
CREATE NONCLUSTERED INDEX ansi ON t (ansi)
CREATE NONCLUSTERED INDEX unicod ON t (unicod)
CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin)
CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin)Выполняем фильтрацию:
SET STATISTICS TIME, IO ON
SELECT COUNT_BIG(*)
FROM t
WHERE ansi LIKE '%AB%'
SELECT COUNT_BIG(*)
FROM t
WHERE unicod LIKE '%AB%'
SELECT COUNT_BIG(*)
FROM t
WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2
SELECT COUNT_BIG(*)
FROM t
WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2
SET STATISTICS TIME, IO OFFИ можем увидеть результаты выполнения, которые приятно удивят:
SQL Server Execution Times:
CPU time = 350 ms, elapsed time = 354 ms.
SQL Server Execution Times:
CPU time = 335 ms, elapsed time = 355 ms.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 18 ms.
SQL Server Execution Times:
CPU time = 17 ms, elapsed time = 18 ms.Вся суть в том, что поиск на основе бинарного сравнения происходит намного быстрее, и если нужно часто и быстро искать вхождение строк, то данные можно хранить с COLLATE, которые заканчивается на BIN. Единственное, что нужно помнить все бинарные COLLATE регистрозависимые при сравнении.14. Code style
Стиль написания кода — это строго индивидуальное, но, чтобы не вносить хаос в разработку, все уже давно придерживаются тех или иных правил. Самое парадоксальное, что за все время работы я не видел ни одного вменяемого свода правил при написании запросов. Все их пишут по принципу: «главное, чтобы работало». Хотя потом рискуют хорошо хлебнуть при разворачивании базы на сервере клиента.
Давайте создадим отдельную базу и таблицу в ней:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_CI_AS
GO
USE test
GO
CREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY)и напишем такой запрос:
select employeeid from employeeРаботает? Теперь попробуйте поменять COLLATE на какой-нибудь регистрозависимый:
ALTER DATABASE test COLLATE Latin1_General_CS_AIИ попробуем повторно выполнить запрос:
Msg 208, Level 16, State 1, Line 19
Invalid object name 'employee'.Оптимизатор использует правила текущего COLLATE при построении плана выполнения. Точнее, на этапе биндинга, когда производится проверка на существование таблиц, колонок и других объектов и сопоставление каждого объекта синтаксического дерева с реальным объектом системного каталога.
Если хочется генерировать ручками запросы, которые будут везде работать, то нужно всегда придерживаться правильного регистра в именах объектов, которые используются в запросе.
Еще интереснее обстоят дела с переменными…
Для них COLLATE наследуются от базы master. Поэтому нужно соблюдать правильный регистр при работе с переменными:
SELECT DATABASEPROPERTYEX('master', 'collation')
DECLARE @EmpID INT = 1
SELECT @empidТо ошибки скорее всего не будет:
-----------------------
Cyrillic_General_CI_AS
-----------
1При этом на другом сервере ошибка в регистре может дать о себе знать:
--------------------------
Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4
Must declare the scalar variable "@empid".15. [var]char
Не секрет, что есть строчные типы данных с фиксированной (CHAR, NCHAR) и переменной длиной (VARCHAR, NVARCHAR):
DECLARE @a CHAR(20) = 'text'
, @b VARCHAR(20) = 'text'
SELECT LEN(@a)
, LEN(@b)
, DATALENGTH(@a)
, DATALENGTH(@b)
, '"' + @a + '"'
, '"' + @b + '"'
SELECT [a = b] = IIF(@a = @b, 'TRUE', 'FALSE')
, [b = a] = IIF(@b = @a, 'TRUE', 'FALSE')
, [a LIKE b] = IIF(@a LIKE @b, 'TRUE', 'FALSE')
, [b LIKE a] = IIF(@b LIKE @a, 'TRUE', 'FALSE')Если строка имеет фиксированную длину скажем в 20 символов, но в нее записали только 4, то в этом случае SQL Server автоматически добавит 16 пробелов справа (при этом обратите внимание функции LEN и DATALENGTH ведут себя по-разному):
--- --- ---- ---- ---------------------- ----------------------
4 4 20 4 "text " "text"Кроме того, важно понимать — при сравнении строк через равно пробелы справа не учитываются:
a = b b = a a LIKE b b LIKE a
----- ----- -------- --------
TRUE TRUE TRUE FALSEДругое дело оператор LIKE:
SELECT 1
WHERE 'a ' LIKE 'a'
SELECT 1
WHERE 'a' LIKE 'a ' -- !!!
SELECT 1
WHERE 'a' LIKE 'a'
SELECT 1
WHERE 'a' LIKE 'a%'Пробелы у правого операнда всегда учитываются при сравнении.16. Data length
Нужно всегда указывать размерность типа, чтобы не натыкаться на подобного рода грабли:
DECLARE @a DECIMAL
, @b VARCHAR(10) = '0.1'
, @c SQL_VARIANT
SELECT @a = @b
, @c = @a
SELECT @a
, @c
, SQL_VARIANT_PROPERTY(@c,'BaseType')
, SQL_VARIANT_PROPERTY(@c,'Precision')
, SQL_VARIANT_PROPERTY(@c,'Scale')В чем суть данной проблемы? Явно не указали размерность типа и вместо дробного значения получаем «вроде целое»:
---- ---- ---------- ----- -----
0 0 decimal 18 0Со строками все еще веселее:
DECLARE @t1 VARCHAR(MAX) = '123456789_123456789_123456789_123456789_'
DECLARE @t2 VARCHAR = @t1
SELECT LEN(@t1)
, @t1
, LEN(@t2)
, @t2
, LEN(CONVERT(VARCHAR, @t1))
, LEN(CAST(@t1 AS VARCHAR))Если явно не указывается размерность, то у строки длина будет 1 символ:
----- ------------------------------------------ ---- ---- ---- ----
40 123456789_123456789_123456789_123456789_ 1 1 30 30При этом поведение преобразовании типов имеет свою особенность: не указали размерность в CAST/CONVERT, то браться будут первые 30 символов.17. ISNULL vs COALESCE
Что еще потенциально интересного можно показать? Есть две функции: ISNULL и COALESCE. С одной стороны все просто — если первый оператор NULL, то вернуть второй оператор или следующий, если мы говорим про COALESCE. С другой стороны, есть коварное различие между ними.
Что вернут эти функции?
DECLARE @a CHAR(1) = NULL
SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')
DECLARE @i INT = NULL
SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)Ответ и вправду не очень очевидный:
---- ----
N NULL
---- ----
7 7.1Почему? Функция ISNULL преобразует к наименьшему типу из двух операндов. COALESCE преобразует к наибольшему типу. Вот мы и получаем такую радость, над которой я в первый раз очень долго просидел в попытках понять, «что не так».
С точки зрения производительности, ISNULL будет немного быстрее отрабатывать в ряде случае, COALESCE же раскладывается в CASE WHEN оператор о котором поговорим ниже.
18. MathЕще интереснее, когда сталкиваешься с математикой на SQL Server. Вроде бы разницы не должно быть:
SELECT 1 / 3
SELECT 1.0 / 3Но по факту оказывается, что разница есть — все зависит от того, какие данные участвуют в запросе. Если целочисленные, то и результат будет целочисленным:
-----------
0
-----------
0.333333Еще интересный пример, который часто встречается на собеседованиях в том или ином виде:
SELECT COUNT(*)
, COUNT(1)
, COUNT(val)
, COUNT(DISTINCT val)
, SUM(val)
, SUM(DISTINCT val)
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)
SELECT AVG(val)
, SUM(val) / COUNT(val)
, AVG(val * 1.)
, AVG(CAST(val AS FLOAT))
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)Что вернет запрос? COUNT (*)/COUNT (1) вернет общее число строк. COUNT по столбцу вернет количество не NULL строк. Если добавить DISTINCT, то количество уникальных значений, которые не NULL.
Интереснее с подсчетом среднего. Операция AVG раскладывается оптимизатором на SUM и COUNT. И тут мы вспомним про пример выше — при подсчете среднего не будут учитываться NULL. Кроме того, если значения целочисленные, то какой будет результат? Целочисленный. Об этом часто забывают.
19. UNION vs UNION ALLТут все просто: если мы знаем, что данные не пересекаются, и нас не волнуют дубликаты, то, с точки зрения производительности, предпочтительнее использовать UNION ALL. Если нужно убрать дублирование, то смело используем UNION.
Например, в случае когда дубликатов точно не будет лучше использовать UNION ALL:
SELECT [object_id]
FROM sys.system_objects
UNION
SELECT [object_id]
FROM sys.objects
SELECT [object_id]
FROM sys.system_objects
UNION ALL
SELECT [object_id]
FROM sys.objects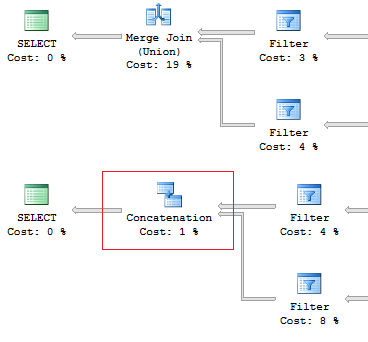
Еще важно знать об интересном различии между этими двумя конструкциями: оператор UNION выполняется параллельно, а UNION ALL — последовательно. И это не относится к параллельным планам, просто это такая особенность доступа к данным, которая может помочь при оптимизации.
Предположим, нам нужно вернуть 1 строку, исходя из разного набора условий:
DECLARE @AddressLine NVARCHAR(60)
SET @AddressLine = '4775 Kentucky Dr.'
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
OR AddressLine2 = @AddressLineТогда за счет использования OR в условии у нас будет IndexScan:

Table 'Address'. Scan count 1, logical reads 90, ...Перепишем запрос с использованием UNION ALL:
SELECT TOP(1) AddressID
FROM (
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
UNION ALL
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine2 = @AddressLine
) tПосле выполнения первого подзапроса, SQL Server смотрит, что вернулась 1 строка, которой достаточно, чтобы вернуть результат, и далее не продолжает искать по второму условию:
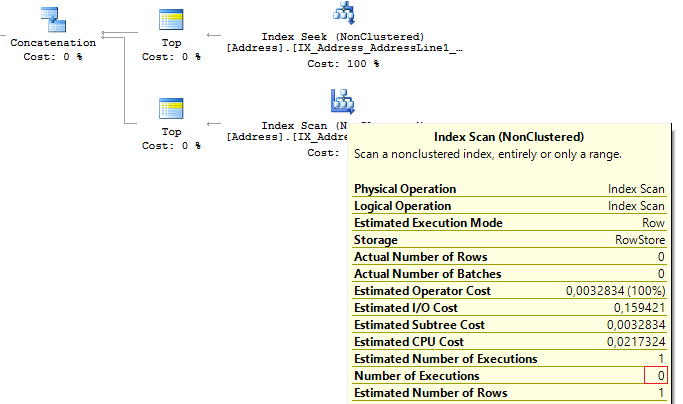
Table 'Worktable'. Scan count 0, logical reads 0, ...
Table 'Address'. Scan count 1, logical reads 3, ...20. Re-read
Очень часто доводилось видеть ситуацию, когда данные можно вытащить с помощью одного JOIN при этом в запросе гордилось куча подзапросов:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT e.BusinessEntityID
, (
SELECT p.LastName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
, (
SELECT p.FirstName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
FROM HumanResources.Employee e
SELECT e.BusinessEntityID
, p.LastName
, p.FirstName
FROM HumanResources.Employee e
JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityIDВедь чем меньше идет лишних обращений к таблице — тем меньше логических чтений:
Table 'Person'. Scan count 0, logical reads 1776, ...
Table 'Employee'. Scan count 1, logical reads 2, ...
Table 'Person'. Scan count 0, logical reads 888, ...
Table 'Employee'. Scan count 1, logical reads 2, ...21. SubQuery
Предыдущий пример весьма показательный, потому что будет работать только если связь между таблицами один-к-одному.
Давайте предполо
