Устройство памяти процессов в ОС Linux. Сбор дампов при помощи гипервизора

Всем привет! Я Евгений Биричевский, занимаюсь в Positive Technologies обнаружением вредоносного ПО.
Иногда для анализа ВПО или, например, для отладки какого-либо процесса может потребоваться дамп памяти процесса. Но как его собрать без отладчика? Постараемся ответить на этот вопрос в статье.
Задачи:
Обозначить цель сбора дампа процесса.
Описать структуру памяти процессов в Linux и отметить различия в старой и новой версиях ядра ОС.
Рассмотреть вариант снятия дампа памяти процесса внутри виртуальной машины на базе связки гипервизора Xen и фреймворка с открытым исходным кодом DRAKVUF.
Что такое дамп памяти и зачем он нужен?
Дамп памяти процесса — сохраненная копия содержимого памяти одного процесса в определенный момент времени. Внутри, помимо копии самого исполняемого файла, могут находиться различные библиотеки, которые используются процессом во время исполнения, а также дополнительная информация о процессе. В Linux дамп памяти называется core, в Windows — minidump.
Довольно часто вредоносное программное обеспечение (ВПО) до исполнения упаковано или обфусцировано с целью избежать обнаружения антивирусом. Дамп памяти процесса может помочь снять простую упаковку или обфускацию (такую как UPX или его производные, которые не снимаются стандартной утилитой). Если ВПО полностью распаковывается в памяти в процессе исполнения, то можно снять его дамп и извлечь из него «чистую» версию ВПО или просканировать дамп статическими сигнатурами напрямую (например, при помощи YARA).
В качестве примера можно рассмотреть образец из статьи с алгоритмом распаковки кастомной версии UPX. Запустим образец в изолированной ВМ, снимем его дамп, а после откроем оба файла в дизассемблере (рисунок 1).
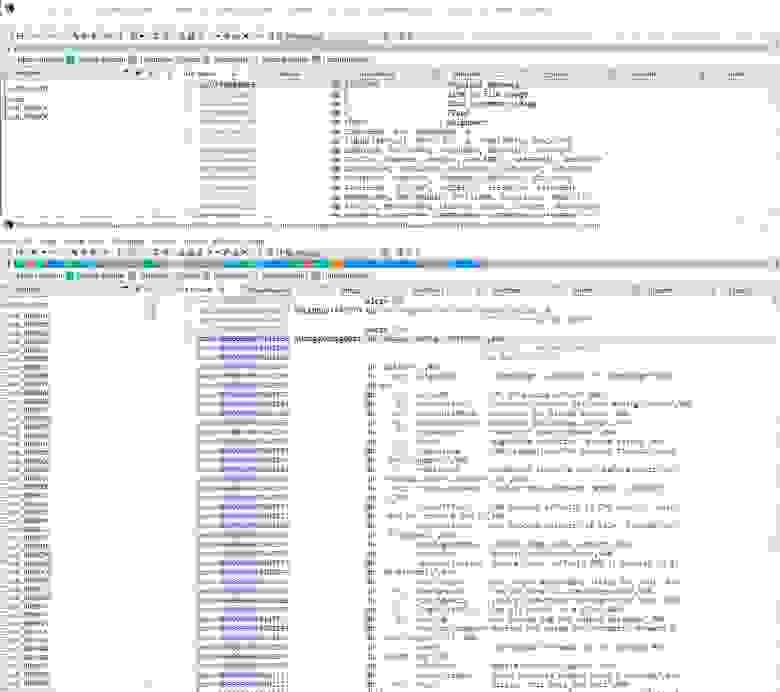
Рисунок 1. Упакованный образец ВПО (сверху) и его снятый дамп (внизу)
В дампе, в отличие от упакованного образца, есть разная полезная для анализа информация (строки, функции), а его снятие требует меньше времени и сил, чем извлечение тех же данных вручную.
Как организована память процессов в ОС Linux?
Рассмотрим, как устроена виртуальная память процессов в Linux, а если быть точнее — как и какие структуры используются. Как Linux работает с памятью в целом, можно прочитать в открытых источниках. Например, статью «Числа и байты: как работает память в Linux?». Для сбора дампа достаточно информации о структуре памяти отдельного процесса.
Виртуальное (линейное) адресное пространство некоторого процесса можно представить в виде схемы, изображенной на рисунке 2. Из всей виртуальной памяти процессу доступны некоторые области (выделены серым цветом), в которых располагаются необходимые для его исполнения данные. Забегая вперед, отмечу, что каждую из этих областей описывает некоторая структура в ядре ОС. Если собрать все эти области в один файл, то можно получить дамп памяти этого процесса.
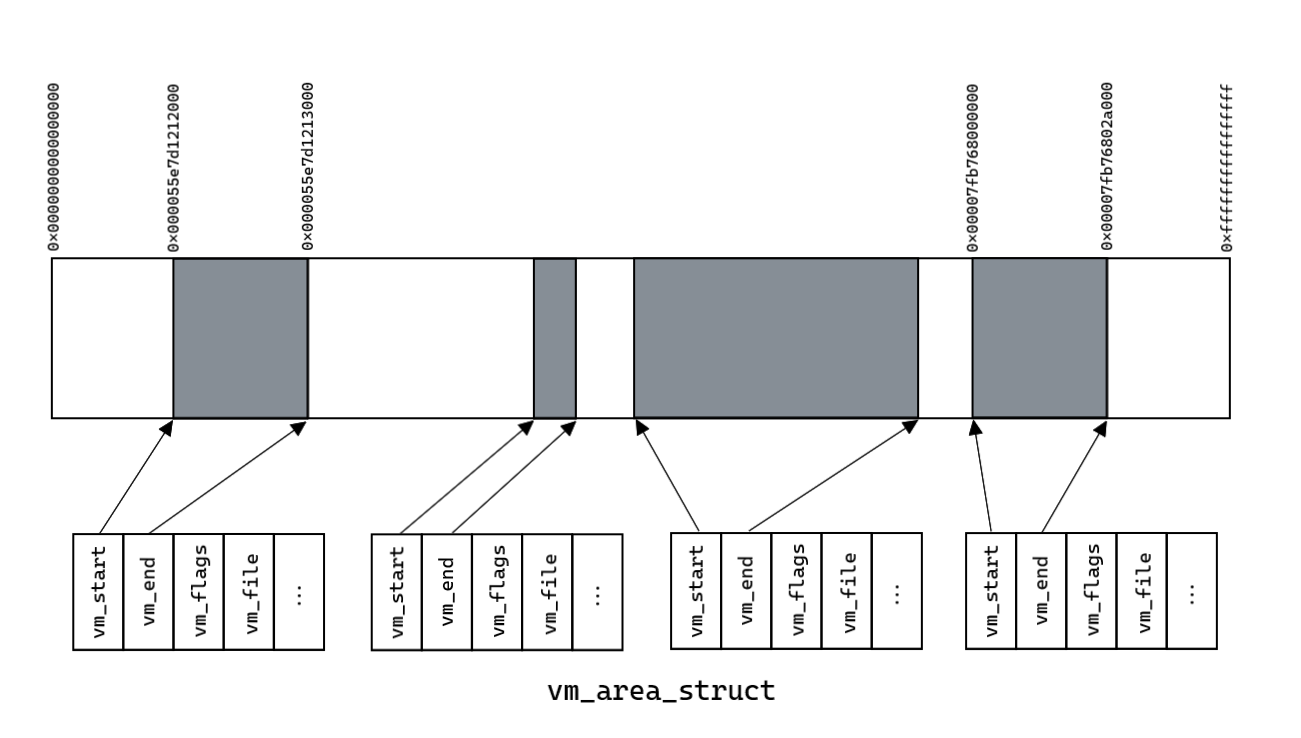
Рисунок 2. Линейное адресное пространство процесса
В userspace доступ к памяти осуществляется при помощи виртуальной файловой системы procfs, которая служит некоторым интерфейсом для получения информации из ядра ОС о системе и процессах. Информацию об областях памяти можно прочитать в файле /proc/pid/maps, саму же память — из /proc/pid/mem. Но откуда берется эта информация и можно ли как-то иначе получить память процесса? Можно, но нужно углубиться в ядро ОС.
У каждого процесса в ядре Linux есть собственная структура, которая содержит его описание — task_struct, ее определение есть в файле sched.h. Информация об адресном пространстве находится в структуре mm_struct, на которую указывает поле mm:
struct task_struct {
...
struct mm_struct *mm;
...
};Информация обо всех областях виртуальной памяти хранится в mm_struct двумя способами:
Также в этой структуре этой же структуре хранится информация о количестве областей (поле map_count). Определение структуры находится в mm_types.h (для Kernel 6.6 и для Kernel 6.0).
struct mm_struct {
...
// Kernel 6.1+
struct maple_tree mm_mt;
...
// Kernel 6.1-
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
...
int map_count; /* number of VMAs */
};Наличие разных структур хранения памяти процессов — основное отличие новых версий ядра от старых. Подробнее структуры будут рассмотрены далее.
Для сбора дампа о каждой области нужна следующая информация:
Начало и конец области (поля vm_start и vm_end соответственно).
Флаги доступа к памяти на чтение, запись и исполнение (поле vm_flags).
Загруженный в память файл, если таковой имеется, и смещение в нем (поля vm_file и vm_pgoff).
Для версии 6.1- указатель на следующий элемент списка (поле vm_next).
Вся эта информация находится внутри структур типа vm_area_struct. Определение структуры находится в mm_types.h (для Kernel 6.6 и для Kernel 6.0).
struct vm_area_struct {
...
unsigned long vm_start; // Our start address within vm_mm.
unsigned long vm_end; // The first byte after our end address within vm_mm. */
...
struct vm_area_struct *vm_next, *vm_prev; // linked list of VM areas per task, sorted by address
...
pgprot_t vm_page_prot; // Access permissions of this VMA.
unsigned long vm_flags; // Flags, see mm.h. */
...
unsigned long vm_pgoff; // Offset (within vm_file) in PAGE_SIZE units */
struct file * vm_file; // File we map to (can be NULL). */
void * vm_private_data; // was vm_pte (shared mem) */
...
};Почему в новых ядрах используется иная структура (maple tree)?
Судя по данным на LWN, основные причины — удобство и эффективность.
До версии ядра Linux 6.1 VMA хранились в красно-черном дереве (rbtree):
rbtree плохо поддерживает диапазоны, с ними трудно работать без блокировки (операция балансировки rbtree затрагивает несколько элементов одновременно).
обход rbtree неэффективен, поэтому существует дополнительный двусвязный список.
Новая структура данных на свежих ядрах — maple_tree — относится к семейству B-деревьев, поэтому:
ее узлы могут содержать более двух элементов — в данном случае до 16 в листовых узлах или десяти во внутренних узлах. Обход B-дерева значительно проще, поэтому необходимость в двусвязном списке отпала.
меньше необходимости создавать новые узлы, поскольку узлы могут включать в себя пустые слоты, которые можно заполнить со временем без выделения дополнительной памяти.
для каждого узла требуется не более 256 байт, что кратно популярным размерам строк кэша. Увеличенное количество элементов в узле и размер, выровненный по кэшу, означают меньшее количество промахов кэша при обходе дерева.
Сбор областей виртуальной памяти на версии ядра до 6.0
В старых версиях ядра схема работы с памятью довольно простая. Примерная структура памяти показана на рисунке 3. Двусвязный список структур vm_area_struct описывает все области виртуальной памяти процесса, которые были показаны на рисунке 2.
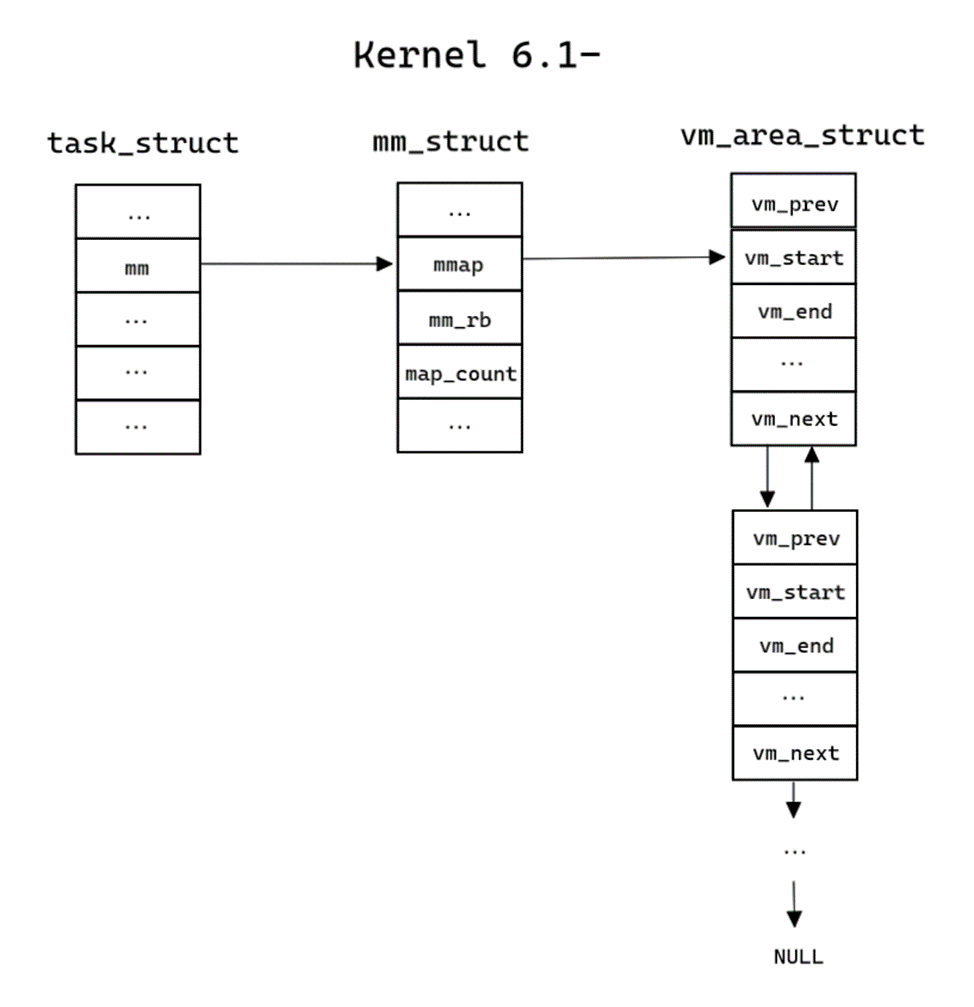
Рисунок 3. Представление структуры памяти на ядре до 6.0
Сбор областей виртуальной памяти, начиная с версии 6.1
В новых версиях схема несколько усложнилась. Для сбора нужно понять, что такое maple_tree и как получить области памяти. Вся необходимая информация о maple_tree находится в файлах maple_tree.h и maple_tree.c. В дереве могут быть ячейки нескольких типов, которые описаны в maple_type:
enum maple_type {
maple_dense,
maple_leaf_64,
maple_range_64,
maple_arange_64,
};Ячейки типа maple_dense не используются для взаимодействий с памятью. Ячейки типа maple_range_64 и maple_leaf_64 используют одну структуру, однако в листах дерева вместо указателя на потомков хранятся указатели на искомые области виртуальной памяти. Указатели находятся в поле slot. Поле pivot — оно же «ключи» — обозначает границы между разными слотами, однако для сбора дампов оно не используется:
struct maple_range_64 {
struct maple_pnode *parent;
unsigned long pivot[MAPLE_RANGE64_SLOTS - 1];
union {
void __rcu *slot[MAPLE_RANGE64_SLOTS];
struct {
void __rcu *pad[MAPLE_RANGE64_SLOTS - 1];
struct maple_metadata meta;
};
};
};Ячейки типа maple_arange_64 обладают следующей структурой и хранят указатели на потомков в поле slot:
struct maple_arange_64 {
struct maple_pnode *parent;
unsigned long pivot[MAPLE_ARANGE64_SLOTS - 1];
void __rcu *slot[MAPLE_ARANGE64_SLOTS];
unsigned long gap[MAPLE_ARANGE64_SLOTS];
struct maple_metadata meta;
};Сходство структур заметить нетрудно, а отличаются они в основном количеством потомков:
#define MAPLE_RANGE64_SLOTS 16
#define MAPLE_ARANGE64_SLOTS 10Этим сходством можно воспользоваться для обхода дерева.
Но как определить тип ячейки, если в структурах нет специализированного поля? На самом деле специализированное поле есть: вся нужная информация хранится в указателях (адресах) ячеек.
Non-leaf nodes store the type of the node pointed to (enum maple_type in bits 3-6), bit 2 is reserved. That leaves bits 0-1 unused for now.
За тип отвечают биты с 3-го по 6-й. Пара примеров:
Адрес ячейки равен 0xFFFF92ADD6C5681E. Его последние биты:
… 01101000 00011110
Следовательно, тип ячейки — maple_arange_64.Аналогично для адреса 0xFFFF92ADC8A10E0C. Его последние биты:
… 00001110 00001100
Следовательно, тип ячейки — maple_leaf_64.
Функция для определения типа ячейки в коде Linux:
#define MAPLE_NODE_MASK 255UL
#define MAPLE_NODE_TYPE_MASK 0x0F
#define MAPLE_NODE_TYPE_SHIFT 0x03
static inline enum maple_type mte_node_type(const struct maple_enode *entry)
{
return ((unsigned long)entry >> MAPLE_NODE_TYPE_SHIFT) &
MAPLE_NODE_TYPE_MASK;
}Этой информации достаточно для составления схемы. Итого примерная структура памяти и дерева представлена на рисунках 4 и 5. Вместо двусвязного списка из mm_struct мы попадаем в корень maple_tree, в листах которого находится искомая информация об областях виртуальной памяти.
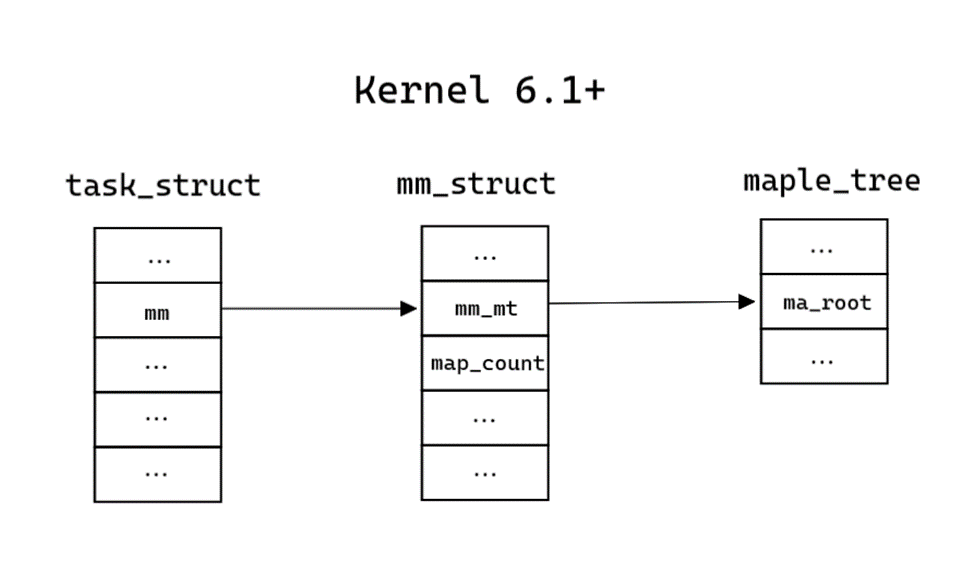
Рисунок 4. Представление структуры памяти на ядре с 6.1
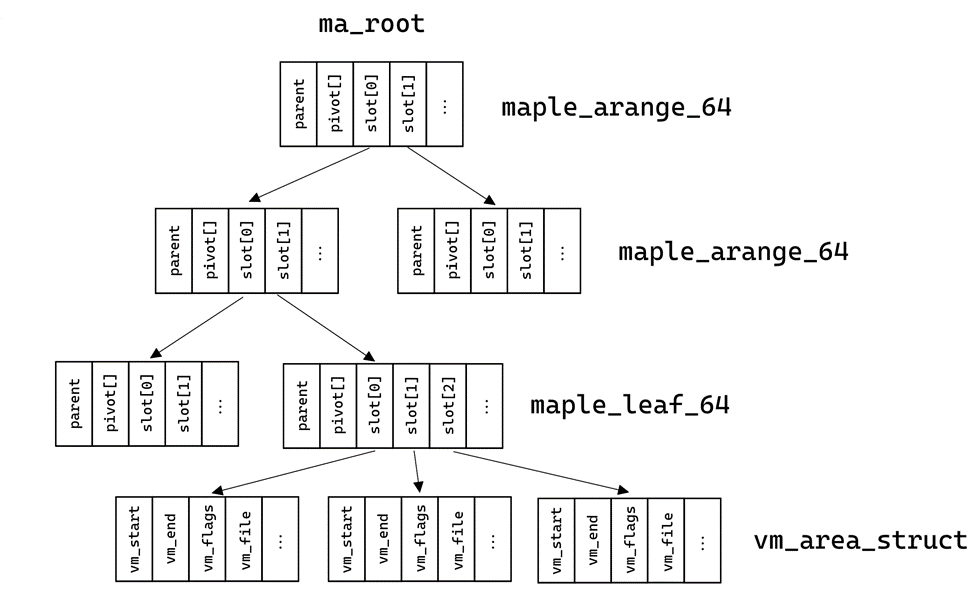
Рисунок 5. Схематичное представление структуры maple_tree
Реализация при помощи Xen и DRAKVUF
Код реализации
В данной реализации процесс исполняется внутри виртуальной машины. Гипервизор нужен для получения доступа к ядерному пространству гостевой ОС и для перехвата системных вызовов. В реализации используется гипервизор с открытым исходным кодом Xen. DRAKVUF — это система анализа по типу «черного ящика», основанная на виртуализации. DRAKVUF позволяет отслеживать выполнение произвольных двоичных файлов без установки специального программного обеспечения на гостевой виртуальной машине, а также взаимодействовать с гипервизором и собирать всю необходимую информацию.
Дисклеймер
Далее в этом разделе будет представлено много фрагментов кода, которые отвечают за сбор дампов и используют информацию, описанную в предыдущем разделе.
С самого начала рассмотрим функции для получения массива с информацией об областях виртуальной памяти.
На старых версиях ядра для получения массива со всей нужной информацией достаточно функции для обхода списка:
std::vector procdump_linux::get_vmas_from_list(drakvuf_t drakvuf, vmi_instance_t vmi, proc_data_t process_data, uint64_t* file_offset)
{
uint32_t map_count = 0;
addr_t active_mm = 0;
addr_t vm_area = 0;
ACCESS_CONTEXT(ctx,
.translate_mechanism = VMI_TM_PROCESS_PID,
.pid = process_data.pid,
.addr = process_data.base_addr + this->offsets[TASK_STRUCT_ACTIVE_MM]);
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &active_mm))
...
ctx.addr = active_mm + this->offsets[MM_STRUCT_MAP_COUNT];
if (VMI_FAILURE == vmi_read_32(vmi, &ctx, &map_count))
...
ctx.addr = active_mm + this->list_offsets[MM_STRUCT_MMAP];
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &vm_area))
...
std::vector vma_list;
vma_list.reserve(map_count);
for (uint32_t i = 0; i < map_count; i++ )
{
read_vma_info(drakvuf, vmi, vm_area, process_data, vma_list, file_offset);
ctx.addr = vm_area + this->list_offsets[VM_AREA_STRUCT_VM_NEXT];
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &vm_area))
...
}
...
return vma_list;
} На новых версиях понадобится несколько функций. В первую очередь функция для определения типа ячейки. Она используется практически в неизменном виде относительно используемой в исходниках Linux и в модуле для DRAKVUF:
static uint64_t node_type(addr_t node_addr)
{
return (node_addr >> MAPLE_NODE_TYPE_SHIFT) & MAPLE_NODE_TYPE_MASK;
}Для обхода дерева вглубь нужна рекурсивная функция. Функции для обхода ячеек, кроме листьев, отличаются только количеством возможных ячеек и их смещениями внутри структуры, поэтому они используют общую подфункцию. Так как в адресах хранится тип ячейки, нужно их обрезать при помощи маски. Итоговая функция для спуска вглубь:
void procdump_linux::read_range_node_impl(drakvuf_t drakvuf, vmi_instance_t vmi, addr_t node_addr, proc_data_t const& process_data, std::vector& vma_list, int count, uint64_t offset)
{
ACCESS_CONTEXT(ctx,
.translate_mechanism = VMI_TM_PROCESS_PID,
.pid = process_data.pid,
.addr = (node_addr & ~MAPLE_NODE_MASK) + offset);
addr_t slot = 0;
// get all non-zero slots
for (int i = 0; i < count; i++)
{
slot = 0;
if (VMI_FAILURE == vmi_read_64(vmi, &ctx, &slot))
...
if (slot)
{
switch (node_type(slot))
{
case MAPLE_ARANGE_64:
read_arange_node(drakvuf, vmi, slot, process_data, vma_list);
break;
case MAPLE_RANGE_64:
read_range_node(drakvuf, vmi, slot, process_data, vma_list);
break;
case MAPLE_LEAF_64:
read_range_leafes(drakvuf, vmi, slot, process_data, vma_list);
break;
default:
PRINT_DEBUG("[PROCDUMP] Unsupported node type\n");
break;
}
}
ctx.addr += 8;
}
} Когда мы добираемся до листьев, нужно собрать информацию обобластях памяти из листа. Функция обходит все слоты, содержащие указатели на vm_area_struct. Функция для сбора информации об областях памяти из листьев:
void procdump_linux::read_range_leafes(drakvuf_t drakvuf, vmi_instance_t vmi, addr_t node_addr, proc_data_t process_data, std::vector &vma_list, uint64_t* file_offset)
{
ACCESS_CONTEXT(ctx,
.translate_mechanism = VMI_TM_PROCESS_PID,
.pid = process_data.pid,
.addr = (node_addr & ~MAPLE_NODE_MASK) + this->tree_offsets[MAPLE_RANGE_SLOT]);
addr_t slot = 0;
for(int i = 0; i < MAPLE_RANGE64_SLOTS; i++)
{
slot = 0;
if (VMI_FAILURE == vmi_read_64(vmi, &ctx, &slot))
...
// some slots may be set to 0
// last slot sometimes filled with used slot counter
if(slot > MAPLE_RANGE64_SLOTS)
{
read_vma_info(drakvuf, vmi, slot, process_data, vma_list, file_offset);
}
ctx.addr += 8;
}
} Итоговая функция для сбора массива с информацией об областях виртуальной памяти из maple_tree:
std::vector procdump_linux::get_vmas_from_maple_tree(drakvuf_t drakvuf, vmi_instance_t vmi, proc_data_t process_data, uint64_t* file_offset)
{
ACCESS_CONTEXT(ctx,
.translate_mechanism = VMI_TM_PROCESS_PID,
.pid = process_data.pid,
.addr = process_data.base_addr + this->offsets[TASK_STRUCT_ACTIVE_MM]);
uint32_t map_count = 0;
addr_t active_mm = 0;
addr_t ma_root = 0;
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &active_mm))
...
ctx.addr = active_mm + this->offsets[MM_STRUCT_MAP_COUNT];
if (VMI_FAILURE == vmi_read_32(vmi, &ctx, &map_count))
...
ctx.addr = active_mm + this->tree_offsets[MM_STRUCT_MM_MT] + this->tree_offsets[MAPLE_TREE_MA_ROOT];
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &ma_root))
...
std::vector vma_list;
vma_list.reserve(map_count);
// Start VMA search from maple tree root
if(node_type(ma_root) == MAPLE_ARANGE_64)
read_arange_node(drakvuf, vmi, ma_root, process_data, vma_list, file_offset);
else if(node_type(ma_root) == MAPLE_RANGE_64)
read_range_node(drakvuf, vmi, ma_root, process_data, vma_list, file_offset);
else if(node_type(ma_root) == MAPLE_LEAF_64)
read_range_leafes(drakvuf, vmi, ma_root, process_data, vma_list, file_offset);
else
return {};
...
return vma_list;
} Перед чтением каждой области виртуальной памяти нужно собрать о ней всю необходимую информацию. В функции выполняется чтение ядерной памяти по определенным смещениям внутри структуры vm_area_struct (читаются определенные поля). Функция для сбора информации об области виртуальной памяти:
void procdump_linux::read_vma_info(drakvuf_t drakvuf, vmi_instance_t vmi, addr_t vm_area, proc_data_t process_data, std::vector &vma_list, uint64_t* file_offset)
{
ACCESS_CONTEXT(ctx,
.translate_mechanism = VMI_TM_PROCESS_PID,
.pid = process_data.pid,
.addr = vm_area + this->offsets[VM_AREA_STRUCT_VM_START]);
vm_area_info info = {};
addr_t vm_file = 0;
addr_t dentry_addr = 0;
uint32_t flags = 0;
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &info.vm_start))
...
ctx.addr = vm_area + this->offsets[VM_AREA_STRUCT_VM_END];
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &info.vm_end))
...
ctx.addr = vm_area + this->offsets[VM_AREA_STRUCT_VM_FLAGS];
if (VMI_FAILURE == vmi_read_32(vmi, &ctx, &flags))
...
ctx.addr = vm_area + this->offsets[VM_AREA_STRUCT_VM_FILE];
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &vm_file))
...
ctx.addr = vm_file + this->offsets[_FILE_F_PATH] + this->offsets[_PATH_DENTRY];
if (VMI_FAILURE == vmi_read_addr(vmi, &ctx, &dentry_addr))
{
dentry_addr = 0;
}
//get mapped filename if file has been mapped
char* tmp = drakvuf_get_filepath_from_dentry(drakvuf, dentry_addr);
info.filename = tmp ?: "";
g_free(tmp);
if (!info.filename.empty())
{
ctx.addr = vm_area + this->offsets[VM_AREA_STRUCT_VM_PGOFF];
if (VMI_FAILURE == vmi_read_32(vmi, &ctx, &info.vm_pgoff))
...
}
...
vma_list.push_back(info);
} В начале дампа процесса собирается массив информации об областях памяти при помощи функций, описанных выше. При наличии массива можно прочитать эти области, и дамп будет собран. Функция дампа процесса:
void procdump_linux::dump_process(drakvuf_t drakvuf, std::shared_ptr task)
{
if (!drakvuf_get_process_data(drakvuf, task->process_base, &task->process_data))
...
auto vmi = vmi_lock_guard(drakvuf);
std::vector vma_list;
if (use_maple_tree)
vma_list = get_vmas_from_maple_tree(drakvuf, vmi, task->process_data, &task->note_offset);
else
vma_list = get_vmas_from_list(drakvuf, vmi, task->process_data, &task->note_offset);
...
start_copy_memory(drakvuf, vmi, task, vma_list);
...
} Функция для чтения областей из полученного массива:
void procdump_linux::start_copy_memory(drakvuf_t drakvuf, vmi_instance_t vmi, std::shared_ptr task, std::vector vma_list)
{
...
for (uint64_t i = 0; i < vma_list.size(); i++)
{
read_vm(drakvuf, vmi, vma_list[i], task);
}
...
} Полный исходный код разработанного плагина можно просмотреть в репозитории DRAKVUF.
О формате дампа
Извлеченные области можно сохранить в любом удобном формате. Например, в формате core, который был выбран в данной реализации.
Почему core?
Формат используется системой и gcore.
Формат в elf-заголовке хранит некоторую информацию об ОС (разрядность, тип ОС).
Все области виртуальной памяти имеют свои смещения в заголовках, поэтому при желании файл можно разбить на файлы меньшего размера.
Файлы можно удобно открыть при помощи различных программ (IDA, readelf, 7z и других).
В заголовках областей памяти хранится исчерпывающая информация об областях: виртуальный адрес, флаги доступа, размер.
В дампе может храниться дополнительная информация: информация о потоках, общая информация о процессе и другие. В данной реализации в разделе дополнительной информации находятся имена файлов, которые были загружены в память.
Более подробная информация о формате находится в заголовочном файле llvm/BinaryFormat/ELF.h.
Пример части вывода программы readelf на собранный файл
readelf -a procdump.0
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: CORE (Core file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 64 (bytes into file)
Start of section headers: 5771126 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 39
Size of section headers: 64 (bytes)
Number of section headers: 41
Section header string table index: 40
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] note0 NOTE 0000000000000000 005808c8
0000000000000698 0000000000000000 0 0 1
[ 2] load PROGBITS 0000591e7b400000 000008c8
000000000000e000 0000000000000000 AX 0 0 1
[ 3] load PROGBITS 0000591e7b60d000 0000e8c8
0000000000001000 0000000000000000 A 0 0 1
[ 4] load PROGBITS 0000591e7b60e000 0000f8c8
0000000000001000 0000000000000000 WA 0 0 1
[ 5] load PROGBITS 0000591e7b60f000 000108c8
0000000000023000 0000000000000000 WA 0 0 1
[ 6] load PROGBITS 0000591e7c09e000 000338c8
0000000000021000 0000000000000000 WA 0 0 1
[ 7] load PROGBITS 000078e4736c0000 000548c8
000000000000a000 0000000000000000 AX 0 0 1
..................................................................
[40] .shstrtab STRTAB 0000000000000000 00580f60
0000000000000016 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
There are no section groups in this file.
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
NOTE 0x00000000005808c8 0x0000000000000000
0x0000000000000698 0x0000000000000000 0x1
LOAD 0x00000000000008c8 0x0000591e7b400000 0x0000000000000000
0x000000000000e000 R E 0x1
LOAD 0x000000000000e8c8 0x0000591e7b60d000 0x0000000000000000
0x0000000000001000 R 0x1
LOAD 0x000000000000f8c8 0x0000591e7b60e000 0x0000000000000000
0x0000000000001000 RW 0x1
LOAD 0x00000000000108c8 0x0000591e7b60f000 0x0000000000000000
0x0000000000023000 RW 0x1
LOAD 0x00000000000338c8 0x0000591e7c09e000 0x0000000000000000
0x0000000000021000 RW 0x1
LOAD 0x00000000000548c8 0x000078e4736c0000 0x0000000000000000
0x000000000000a000 R E 0x1
..................................................................
Section to Segment mapping:
Segment Sections...
00 note0
01 load
02 load
03 load
04 load
..................................................................
There is no dynamic section in this file.
There are no relocations in this file.
The decoding of unwind sections for machine type Advanced Micro Devices X86-64 is not currently supported.
No version information found in this file.
Displaying notes found at file offset 0x005808c8 with length 0x00000698:
Owner Data size Description
CORE 0x00000683 NT_FILE (mapped files)
Page size: 64
Start End Page Offset
0x0000591e7b400000 0x0000591e7b40e000 0x0000000000000000
/bin/ping
0x0000591e7b60d000 0x0000591e7b60e000 0x000000000000d000
/bin/ping
0x0000591e7b60e000 0x0000591e7b60f000 0x000000000000e000
/bin/ping
0x000078e4736c0000 0x000078e4736ca000 0x0000000000000000
/lib/x86_64-linux-gnu/libnss_files-2.24.so
..................................................................
Заключение
В статье мы рассмотрели и описали структуру хранения областей виртуальной памяти на актуальных версиях ядра. Также была предложена реализация модуля для сбора дампов памяти при помощи гипервизора.
Само собой, реализованный подход не идеален. Он представляет собой proof of concept для сбора дампа памяти процесса, что может пригодиться для анализа как обычных программ, так и ВПО.
Возможные улучшения:
Расширение списка информации, которая сохраняется в core-файл
Разработка более эффективного метода для получения областей виртуальной памяти и их чтения
Возможно, поддержка различных форматов дампов (например, сбор дампа в сыром виде)
Если есть предложения по улучшению подхода, описанного в статье, — делитесь в комментариях!
