Ускоряем процесс разметки с помощью интерактивной сегментации
Всем привет! Сегодня поговорим про задачу интерактивной сегментации на основе кликов (click-based) и как она может ускорить процесс разметки данных для различных типов сегментации. Сегментационные модели применяются в распознавании событий и объектов в видео (Video Understanding), анализе медицинских снимков и в управлении беспилотных автомобилей, а также с их помощью реализована замена фона в приложениях для видеозвонков, бьютификация и автоматическая ретушь фотографий. SberDevices тоже активно разрабатывают свои решения для семантической сегментации — недавно мы рассказывали про задачу замены фона и бьютификацию в нашей статье, в которой представили новый большой opensource датасет для Portrait Segmentation и Face Parsing вместе с набором предобученных моделей.

Пример работы интерактивной сегментации на основе модели SimpleClick
Что такое сегментация изображений?
Сегментация изображений — это задача компьютерного зрения, целью которой является классифицировать каждый пиксель изображения и тем самым выделить объекты на нем в отдельные сегменты (маски). Задача сегментацииделится на следующие подзадачи: семантическая сегментация, инстанс-сегментация и паноптическая сегментация, каждая из них имеет свои подвиды и особенности при решении.

Семантическая сегментация — это сегментация, целью которой является отнести каждый пиксель к заданному классу или набору классов. При единственном целевом классе такая задача называется бинарной сегментацией. Извлечение сегментов лица (Face Parsing), сегментация заднего фона на портретных изображениях (Portrait Segmentation), распознавание объектов окружения (Scene Understanding) являются подвидами семантической сегментации.
При инстанс-сегментации необходимо локализовать каждую полученную область пикселей с целевыми классами в отдельные сегменты (инстансы). Такая сегментация особенно полезна, если мы решаем задачу трекинга объектов, или сегментируемые объекты слишком малы и находятся слишком близко друг к другу для точной попиксельной сегментации. Чаще всего примеры использования инстанс-сегментации можно видеть в задачах анализа геопространственных данных и медицинских снимков, распознавании окружения для беспилотных машин и робототехники.
Паноптическая сегментация объединяет семантическую и инстанс-сегментацию, возвращая сумму их масок. Но нужно учитывать, что при данном виде сегментации каждый пиксель изображения должен иметь только одну метку класса, т. е. если объекты на изображении накладываются друг на друга, то паноптическая сегментация справится с таким перекрытием хуже, чем описанная выше инстанс-сегментация.
Все три вида сегментации изображений имеют свои особенности, но их главный общий минус — это разметка нового набора данных, если существующие датасеты не подходят по каким-либо критериям. Нейросетевые модели для сегментации обучаются через аппроксимацию целевых масок-образцов (ground-truth masks) для каждого объекта, поэтому если подходящего датасета нет, то такие маски-образцы можно получить либо через ручную разметку на специальных платформах для аннотации данных (Toloka.AI, Amazon Mechanical Turk, Supervisely, Elementary), либо через генерацию синтетических данных. Качество моделей, обученных на синтетических изображениях, в общем случае будет хуже при работе на реальных данных. Также необходимо дополнительно разработать подход, который будет качественно генерировать данные и разметку. Поэтому чаще всего выбирают процесс ручной разметки, несмотря на ее дороговизну и длительность, а также вероятность человеческой ошибки.
С помощью интерактивной сегментации можно упростить процесс ручной разметки и привнести дополнительный вклад в обучение моделей, а именно:
ускорить процесс разметки с возможной минимизацией количества разметчиков, т. к. частично автоматизируется отрисовка сегментационных масок;
улучшить качество работы моделей из-за увеличения набора качественно размеченных данных;
снизить стоимость финальной разметки.
Ниже подробнее обсудим работу интерактивной сегментации.
Интерактивная сегментация
Один из подходов к интерактивной сегментации основан на использовании кликов, с помощью которых пользователь может размечать маски. Существует два вида кликов: положительные, которые отрисовывают маску заданного класса, и отрицательные, с помощью которых можно поправить исходную маску. Если полученная сегментационная маска не покрывает полностью нужную область пикселей, то можно сделать еще один положительный клик. В случае, если в сегментационную маску попали лишние пиксели, можно поставить отрицательный клик, который ее уточнит.

Уточнение сегментационной маски с помощью положительных и отрицательных кликов
Все подходы, которые используются при решении данной задачи, нацелены на то, чтобы за минимальное количество кликов получить максимально высокое значение метрики Intersection over Union (IoU). Обычно в качестве такого значения выбирают 90 и пишут NoC@90, где NoC (Number of Clicks) — количество кликов.

Разница между обычной ручной разметкой и разметкой на основе интерактивной сегментации
Таким образом, за один клик или несколько кликов можно получить желаемую сегментационную маску для целевого объекта и снизить затрачиваемое время на разметку через точки полигона, как это обычно реализовано на краудсорсинг-платформах. Стоит также отметить, что при использовании подходов интерактивной сегментации, маски получаются с плавными краями, максимально повторяя форму сегментируемого объекта. Для достижения такого эффекта классическим способом с помощью отрисовки маски через создание полигона нужно поставить большее количество точек, что сильно увеличит время разметки.
К примеру, на внутренних площадках SberDevices для разметки данных уже ведутся исследования и внедрение state-of-the-art подходов интерактивной сегментации, , а также команда Google не прошла мимо ее преимуществ и добавила в свой MediaPipe Studio возможность с помощью одного клика сегментировать объекты целевых классов. Их решение с названием Magic Touch основывается на архитектуре, которая похожа на MobileNetV3, но имеет кастомизированный декодер. Выбор подобной архитектуры позволил получить модель размером меньше 10 Мбайт и предоставляет скорость работы на CPU ≈130 миллисекунд.

Демонстрация работы Magic Touch в MediaPipe Studio
Важно дополнительно рассказать, что существует интерактивная сегментация, которая работает не только на кликах. Есть подходы, предполагающие взаимодействие с моделью на основе указанных областей, представляющих из себя прямоугольник, для которого нужно задать 4 координаты. Но подобрать координаты таких областей сложнее, чем поставить клик. А также в выделенной области могут присутствовать лишние объекты, снижающие точность работы сегментации. Еще можно найти упоминание подходов, которые принимают набор линий (scribble-based), отрисованных пользователям по области объекта для сегментации. Но данная идея сложна тем, что при обучении требует реалистичной симуляции отрисовки таких «каракулей». Некоторые модели для интерактивной сегментации объединяют сразу несколько доменов данных для лучшего результата сегментации. К примеру, текст, описывающий объект для сегментации, и клики.
Общая схема работы интерактивной сегментации выглядит следующим образом:

Схема работы последних решений в интерактивной сегментации
Существующие подходы в интерактивной сегментации
Рассмотрим наиболее популярные подходы к решению задачи интерактивной сегментации:
Reviving Iterative Training with Mask Guidance for Interactive Segmentation (RITM)
Эта работа представила идею исправления сегментационных масок даже от других моделей, взаимодействуя с ними через негативные и положительные клики пользователя. Данная идея легла в основу последних state-of-the-art подходов интерактивной сегментации, поэтому она заслуживает отдельного внимания.

Исправление ранее полученных результатов через итеративный подход и корректирующие клики
Авторы RITM выбрали итеративный подход к обучению своей модели, используя информацию о сегментации на предыдущем шаге. В качестве базового узла модели была выбрала сверточная нейронная сеть с архитектурой HRNet + OCR.
Пользователь взаимодействует с моделью через положительные и отрицательные клики, которые представлены на изображении координатами. Чтобы выбранная модель могла вернуть корректный результат на основе заданных кликов, необходимо их перевести в пространственное представление. Для этого в RITM клики рассматривались как круговые диски небольшого радиуса. Значение для радиуса этих круговых обычно выбирают в диапазоне от 3 до 5.

Демонстрация работы RITM
Также авторы отметили, что в большинстве случаев сегментационные модели предобучены на датасете ImageNet и работают только с RGB-изображением в качестве входной информации. Чтобы отдать модели дополнительную информацию на вход, необходимо изменить первый сверточный слой. Он будет принимать не только RGB-изображение, но и уже пространственно представленные клики пользователей в виде дополнительных каналов. Авторы назвали эту модификацию первого сверточного слоя как Conv1E, особенности архитектуры которого изображены на рисунке ниже.
DFM (Distance Maps Fusion) — это модуль, который трансформирует входное изображение и канал с дополнительной информацией во вход с тремя каналами. Conv1S — это модифицированный блок сверток, который позволяет использовать в качестве входа RGB-изображение и клики пользователя, сохраняя при этом размерности всех тензоров. На основе своих экспериментов авторы сделали вывод, что наилучшие результаты дает комбинация HRNet-18 + ResNet-34 + Conv1S.

Архитектура модифицированных входных слоёв RITM
Также RITM использует обновленный подход к симуляции пользовательских кликов:
в начале клики случайно генерируются без учета связи между ними, а далее применяется итеративный подход, который заключается в следующих шагах:
клики распределяются не только в центре неправильно размеченных сегментационных масок, но и в этих же областях после уменьшения их площади в 4 раза через морфологические эрозии. Если располагать клики только в центре — это влечёт переобучение модели и плохо симулирует реальное расположение кликов пользователя;
во время обучения для каждого батча клики генерируются индивидуально, поэтому количество итераций семплирования кликов было ограничено.
Согласно представленным метрикам, с помощью данного подхода можно получить модель, которая позволяет в среднем за 2–4 клика получить довольно точную сегментационную маску.
![Результаты работы RITM на датасете Berkeley. При некоторых конфигурациях данной модели достаточно одного клика для достижения значения метрики IoU в промежутке [0.83, 0.85].](https://habrastorage.org/getpro/habr/upload_files/d1e/ec6/7c2/d1eec67c2c653859c09c74ec92f6321f.png)
Результаты работы RITM на датасете Berkeley. При некоторых конфигурациях данной модели достаточно одного клика для достижения значения метрики IoU в промежутке [0.83, 0.85].
SimpleClick
Авторы данной работы сосредоточились на разработке такого решения, которое обладало бы следующими свойствами:
простая архитектура модуля для извлечения признаков изображения;
быстрый отклик модели сочетается с высокой точностью результатов.
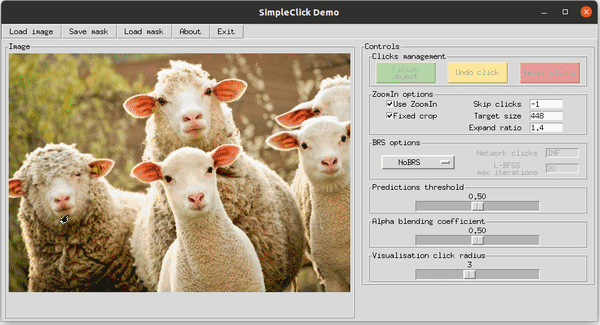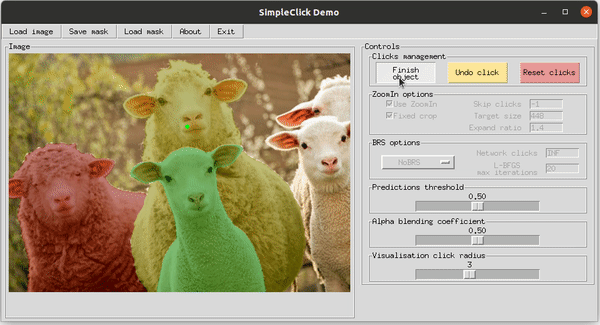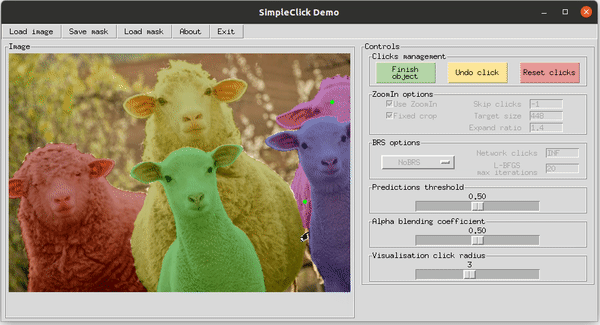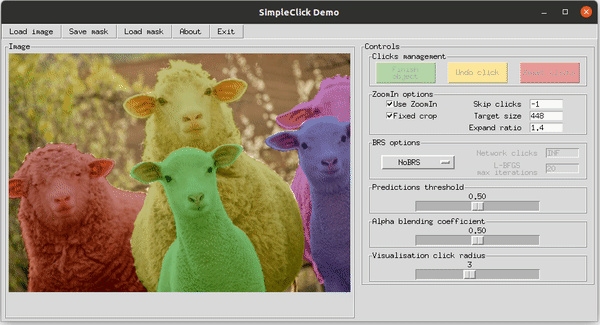
Демонстрация работы SimpleClick
Ранее появившиеся решения для интерактивной сегментации опираются на иерархические архитектуры, используя в своей основе классические модели на свертках с пирамидальной обработкой карт признаков (Feature Pyramid Network) или сложные модели-трансформеры (Swin Transformer). Использовать сложные иерархические архитектуры мотивировано необходимостью извлекать максимальное количество информации о глобальном контексте изображения. Такие архитектуры позволяют это делать через обработку карт признаков (features map), содержащие в себе результат применения на входное изображение сверточных слоев разного уровня.

SimpleClick не отстает по качеству от RITM — при одном клике достигает значений IoU, близких к 90
В основу SimpleClick легла идея из последних успешных решений в задаче детекции объектов — использование Vision Transformer (ViT) с Masked Autoencoders (MAE) и оконной вариацией механизма внимания (window attention). Данная архитектурная комбинация избавляет от сложных иерархических наборов слоев для получения информации о глобальном контексте, потому что все карты признаков в ViT одного размера и глобальный контекст из изображения можно получить через слой внутреннего внимания (self-attention). В SimpleClick используется только последняя карта признаков для предсказания сегментационной маски — она подается в простую пирамиду признаков, которая необходима для реализации механизма сегментации, а далее применяется легковесный многослойный перцептрон. Это решение было протестировано на 10 открытых бенчмарках, включающих в себя обычные изображения и медицинские данные. В среднем SimpleClick нужно 2–3 клика для получения точной маски.

Архитектура решения SimpleClick
Решение SimpleClick можно разделить на три части:
модуль извлечения признаков изображения ViT, обрабатывающий карты признаков одного размера. Также patch embedding слои делят входное изображение и маску с кликом на непересекающиеся части (патчи) фиксированного размера (16×16 для ViT-B), каждая из которых проецируется в вектор указанной длины (768 для ViT-B). Эта последовательность патчей отправляется в очередь блоков трансформера для self-attention. Авторы SimpleClick представили модель с тремя вариациями модуля извлечения признаков: ViT-B, ViT-L, and ViT-H. Все они были предобучены с Masked AutoEncoders на ImageNet-1k. Данный блок всех attention-механизмов возвращает карту признаков, по которой дальше будет происходить предсказание сегментационной маски;
пирамида признаков с упрощенной архитектурой. Она содержит в себе 4 сверточных слоя с разными шагами перемещения фильтра, что является достаточным для качественных результатов работы, т. к. используется только последняя карта признаков, содержащая наиболее подробное представление об изображении;
легковесный многослойный перцептрон, который обрабатывает карту признаков с каждого сверточного слоя и увеличивает их к одному размеру для последующей конкатенации. Далее полученный тензор переводится в формат одноканальной карты признаков, чтобы получить предсказанную сегментационную маску.
Важно уточнить, что клики пользователя тоже обрабатываются на этапе patch embedding слоя в модуле извлечения признаков изображения и используется результат сегментации с предыдущими кликами в качестве входа, позволяя уточнить маску на текущем шаге разметки. Клики пользователя кодируются как двухканальные круговые маски, скомбинированные вместе с предыдущей сегментацией, которая подается на вход. На схеме авторы опустили позиционный энкодинг, чтобы не делать схему сложной для понимания.
Данная модель обучалась с автоматической симуляцией кликов на основе текущих результатов сегментации и целевой маски-образца. Клики распределялись не только случайно, но и итеративно — данная идея была взята из RITM, который мы разобрали выше. Случайные клики генерировались параллельно без учета порядка кликов. Стратегия с интерактивными кликами учитывала особенности человеческого поведения: следующий клик ставился в область, которую нужно было уточнить после предыдущего шага.
Покажем, как выглядела симуляция кликов при обучении на датасете EasyPortrait. Зелёная точка — это клик на область пикселей с целевым классом, т. е. это положительный клик. Синие точки работают как негативные клики.

Распределение кликов во время обучения SimpleClick на датасете EasyPortrait
Segment Anything
На данный момент модель Segment Anything (SAM) можно назвать state-of-the-art решением для интерактивной сегментации. Она была использована для разметки нового датасета SA-1B, в котором 11 миллионам изображений соответствуют более одного миллиарда масок. Авторы SAM называют свою разработку фундаментальной моделью — это модель, которая имеет большое количество параметров и обучается на датасете, где в среднем более одного миллиона экземпляра данных. Из-за приобретенной способности к обобщению фундаментальная модель способна возвращать результат не только для одной конкретной задачи, но и для похожих смежных задач. Это понятие пришло из NLP-моделей.

Cхема работы Segment Anything
Пользователь может взаимодействовать с данной моделью не только через клики, но и через текст-описание искомых на изображении объектов, примерную маску объекта, которая будет автоматически дорисована, или координаты области, содержащей объекты для разметки. С такими новыми форматами взаимодействия SAM работает в режимах few-shot и one-shot, т. е. ей не требуется большое количество данных для возвращения максимально точного результата.

Архитектура mask decoder в SAM
Модель Segment Anything работает следующим образом:
входное изображение подаётся в image encoder и возвращаются эмбеддинги — низкоразмерное представление изображения. В качестве image encoder выбран ViT, предобученный с помощью MAE для лучшего запоминания внутреннего представления, и минимально адаптированный для работы с изображениями большего разрешения (увеличены);
модель может работать не только с масками, но и с боксами, текстом и точками, поэтому в схеме архитектуры решения можно увидеть prompt encoder, mask decoder и сверточный энкодер для работы с ними. Для точек и боксов в prompt encoder используется позиционный энкодинг (positional encoding), для текста — модель CLIP, а для масок — три сверточных слоя с GELU-активациями и слоем нормализации. Закодированные результаты далее суммируются с выученными эмбеддингами изображения;
mask decoder отвечает за перевод суммы эмбеддингов изображений и эмбеддингов промпт-данных в маски. Этот модуль состоит из двух слоёв и каждый слой выполняет 4 шага: self-attention на токены (эмбеддинги промпт-данных), cross-attention с токенов на эмбеддинг изображения, многослойный перцептрон (MLP) c полносвязными слоями обновляет каждый токен и на последнем шаге эмбеддинги изображений получают информацию из токенов промпт-данных через cross-attention. Каждый attention-блок содержит residual-свертки, слои нормализации и дропаут. Далее происходит возвращение к изначальным размерам эмбеддинг изображения через transposed сверточные слои и предсказание масок с метриками IoU.
Да, предсказывается не одна маска, а сразу три. Такое количество было выявлено авторами эмпирически — для сегментации нужного объекта на изображении предсказываемые маски достаточно разложить «в глубину» на целую маску, на часть и на подчасть. Пример такого разложения в глубину можно видеть на картинке ниже:

Разложение в глубину результатов сегментации от SAM
Архитектура решения Segment Anything мотивирована необходимостью эффективной работы. Авторы отмечают, что модель способна работать на ЦПУ в браузере со скоростью ≈50 миллисекунд. Тут нужно уточнить, что указанная скорость работы достигается при заранее вычисленном эмбеддинге изображении. Такое время отклика позволяет использовать SAM для интерактивной сегментации.
Многие платформы для разметки данных оценили возможности модели Segment Anything и стали внедрять к себе, чтобы упростить пользователям процесс получения сегментационных масок. К примеру, команда ABC Elementary уже добавила на свою платформу разметки данную модель:
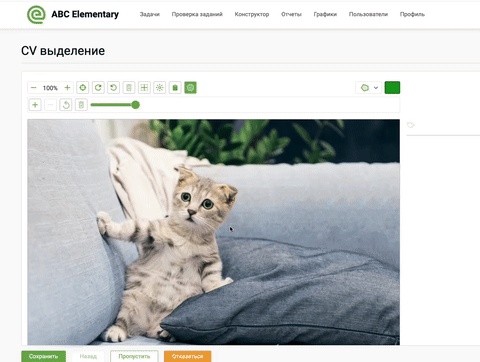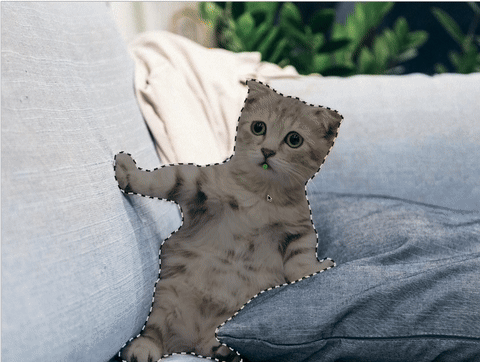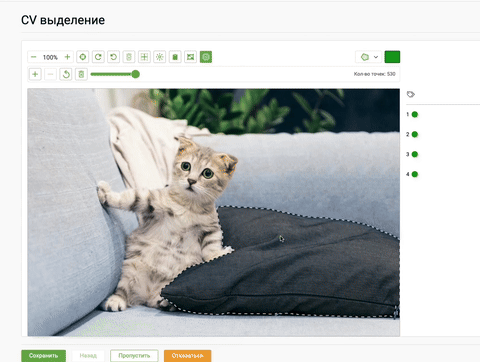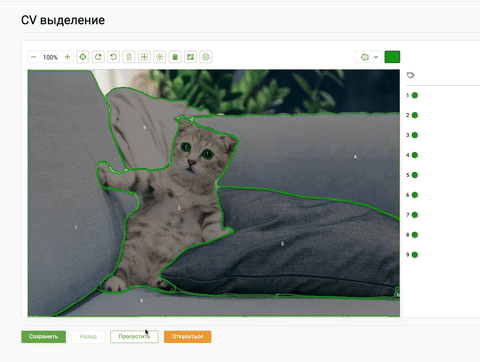
Пример разметки данных с помощью SAM на платформе ABC Elementary
Единственная проблема, которая есть у Segment Anything, — это необходимость дообучать модель на своих данных, если они не похожи на те, что использовались в датасете SA-1B. К примеру, пользователи SAM отмечают, что она плохо справляется с изображениями аэросъемки или медицинскими снимками. Мы тоже тестировали SAM на изображениях своего датасета EasyPortrait и выяснили, что данная модель не подходит для разметки данных под задачу Face Parsing. К примеру, на изображении ниже невозможно получить сегментационную маску с кожей лица.

Failure case в работе Segment Anything
Датасеты для интерактивной сегментации
Во всех задачах машинного обучения данные играют важную роль в итоговом качестве работы моделей. Нейросетевые подходы для интерактивной сегментации не стали исключением, а даже наоборот — для их обучения важно использовать датасеты с качественной разметкой, потому что результат их работы предполагается использовать для обучения моделей в других задачах. Важно добавить, что мы хотим достичь качественной автоматической аннотации данных, поэтому модель интерактивной сегментации должна быть «знакома» с наибольшим количеством возможных целевых классов и их визуальными представлениями.

Примеры изображений и масок из датасета DAVIS
Для обучения моделей интерактивной сегментации используют следующие датасеты: Semantic Boundaries Dataset (SBD), Pascal VOC, LVIS, COCO, DAVIS. Также эти датасеты комбинируют между собой и обучают сразу на большом количестве данных.

Изображения и соответствующие целевым классам сегментационные маски из датасета SA-1B
Теперь к ним добавился датасет SA-1B, содержащий 11 миллионов изображений с 1,1 миллиарда соответствующих сегментационных масок высокого качества. Данные маски были полностью размечены моделью SAM. Для проверки их корректности были отобраны 500 изображений с ≈50 тыс. сегментационных масок и наняты профессиональные разметчики, которые используют инструменты «кисть» и «ластик» для достижения попиксельной точности масок. Далее через метрику IoU оценивалось, насколько автоматически полученные маски отличались от их исправленных версий. Также авторы SAM и SA-1B выложили рейтинг качества разметки, составленный на основе оценок людей. Для этого рейтинга были задействованы оригинальные маски-образцы из разных датасетов и предсказанные маски от моделей SAM и RITM. И как мы можем видеть, на некоторых датасетах результаты сегментации от моделей не уступает оригинальным маскам-образцам, которые были размечены вручную.

Рейтинг качества разметки моделями интерактивной сегментации и нанятыми разметчиками
Перечисленные датасеты обычно используются для решения задач семантической сегментации или инстанс-сегментации. Необходимые данные о взаимодействии модели и пользователя генерируется во время обучения и не требуют дополнительной ручной разметки.
Заключение
Сегодня мы познакомили вас с задачей интерактивной сегментации и последними популярными подходами для ее решения. Данные подходы демонстрируют возможность за пару кликов получить сегментационную маску с попиксельной точностью, которая не уступает разметке вручную. В случае, если нужна аннотация в виде сегментационных масок для узконаправленного домена, например, для медицинских снимков, то добиться таких же высоких результатов на своих данных можно просто дообучив RITM или SimpleClick на датасете с похожим доменом. Да, появляется проблема, что для интерактивной сегментации все равно может понадобиться ручная аннотация, но можно разметить данные лишь частично, используя для оставшихся неразмеченных образцов уже обученную на их домене модель.
Активное внедрение интерактивной сегментации в платформы для разметки может сильно улучшить качество текущих моделей, потому что аннотация большого количества разнообразных данных станет качественнее, дешевле и доступнее. Интерактивную сегментацию можно применять не только для разметки данных, но и в фото/видео-редакторах для обработки области, выбранной с помощью клика, а также в медицинских программах для облегчения рутинной работы врачей.
Подписывайтесь на Telegram-канал RnD CV @ SberDevices, чтобы оставаться в курсе последних новостей компьютерного зрения и отслеживать успехи нашей команды.
Источники
Segment Anything
Reviving Iterative Training with Mask Guidance for Interactive Segmentation
SimpleClick: Interactive Image Segmentation with Simple Vision Transformers
