Ускоряем кеш проекта в NoVerify (линтер для PHP) в 10 раз
Одним вечером, обсуждая с Искандером @quasilyte сложности в разработке линтера для PHP на Go, Искандер упомянул, что тесты как-то долго идут при локальном прогоне (около минуты, и, как мне кажется, для Go это довольно долго). Стали копать, и быстро выяснилось, что в основном «тормозят» тесты, которые запускают NoVerify (название линтера) в режиме со включенным race-детектором. На каждый запуск индексируется репозиторий phpstorm-stubs, в котором содержатся все определения встроенных функций/классов/констант, которые есть в PHP, и индексация этого репозитория занимает около 4 секунд на 4-ядерной машине (замечу, что без race detector всё существенно быстрее). Поскольку таких прогонов делается несколько, по одному на каждый тестируемый open-source проект, суммарное время исполнения всех тестов может занимать минуты. NoVerify позиционирует себя как очень быстрый линтер для PHP, поэтому, конечно же, такая производительность несколько печалит и нужно было найти какое-то решение.
Архитектура NoVerify
Для начала всё же стоит немного рассказать о том, как работает NoVerify. Работа линтера разделена на две большие фазы: индексация и непосредственный анализ.
Индексация проекта заключается в том, что из всех PHP-файлов извлекаются определения и типы всех функций, классов, методов, констант и глобальных переменных, и вся эта информация сохраняется в оперативной памяти для быстрого доступа. Также эта информация сохраняется в кеш на диске в формате gob, чтобы избежать необходимости парсить весь проект заново каждый раз. Важно, что даже для анализа одного файла должен быть проиндексирован весь проект, потому что если для классов в PHP есть autoload, то для функций, констант и уж тем более глобальных переменных такого нет, и определены они могут быть где угодно. Безусловно, в современных проектах на PHP обычно используются только классы и таких проблем не возникает, но для проектов с длинной историей это всё ещё бывает актуально. Именно необходимость индексации всего проекта для его анализа и послужила причиной написания NoVerify на Go, поскольку этот язык хорошо поддерживает многопоточность, а значит сможет индексировать проект намного быстрее, чем это возможно на PHP.
Анализ может производиться как для выбранных файлов (например, тех, что изменились в текущем коммите), так и для всего проекта сразу. В первом случае анализ занимает меньше времени, чем построение индекса, иногда значительно (как в примере выше с тестами, где индексация phpstorm-stubs занимает 90+% времени работы). Для анализа используется информация о типах всех объявленных функций/классов/методов, которая была собрана на этапе индексации.
Ускорение индексации phpstorm-stubs
Первым интересным, на мой взгляд, наблюдением, было то, что репозиторий phpstorm-stubs, который, напомню, содержит просто «заглушки» (т.е. функции без реализации) для всех встроенных функций/констант/классов в PHP, индексируется на 25% быстрее, если не используется дисковый кеш для индекса проекта, то есть когда все файлы просто целиком парсятся заново. Это было немного неожиданно, но в целом объяснимо: поскольку в phpstorm-stubs содержатся только «заглушки» для функций, без реализации, то особого выигрыша от кеша и не может быть, ведь в кеше хранятся только определения функций, их типы, расположение в файле, и т.д., и основная экономия достигается за счет того, что не хранится само тело функции.
Есть несколько возможностей ускорить загрузку «заглушек» в тестах:
Загружать только те файлы, которые реально нужны в конкретном проекте. Поскольку это тестовые данные, то возможно просто составить весь список нужных файлов из phpstorm-stubs заранее.
Скопировать только нужные объявления из phpstorm-stubs в отдельный файл для конкретного проекта, чтобы ещё сильнее уменьшить количество файлов, которые нужно обрабатывать.
Попробовать использовать более эффективный формат для дискового кеша, чем gob.
Учитывая, что phpstorm-stubs тоже статичны, можно сгенерировать Go-код из структур для кеша в памяти и инициализировать индекс для phpstorm-stubs на старте программы. Неизвестно, какой это выигрыш может дать, но кажется, что он может быть в 2–3 раза при прочих равных за счёт отсутствия необходимости парсить файлы.
Были испробованы все варианты, кроме (2), то есть копирования только нужных определений функций. В конечном итоге, вариант (1), то есть парсить только нужные файлы, оказался самым простым в поддержке и давал шестикратный прирост производительности, которого оказалось вполне достаточно. Однако, было бы странно умолчать о том, что вариант с генерацией Go кода тоже был протестирован и с помощью компиляции кода удалось сократить время загрузки phpstorm-stubs до ~200 мс (т.е. ускорить в 20 раз загрузку статичных данных), однако даже со всеми оптимизациями для уменьшения времени компиляции, сборка всё равно занимала порядка 18 секунд, что сводило весь выигрыш от ускорения загрузки заглушек на нет, и добавляло много сложного в поддержке кода для генерации максимально компактного кода для инициализации кеша.
Как насчёт ускорения кеша для всего проекта?
Несмотря на то, что для ускорения golden-тестов кодогенерация была сомнительным решением, сложно игнорировать тот факт, что этот подход дает настолько большой прирост скорости, что наверняка можно применить его для чего-то кроме тестов. Так у меня родилась идея попробовать ускорить вообще весь кеш проекта, а не только первую его часть, то есть загрузку phpstorm-stubs. Так сказать, сделать турбо-кеш.
Кеш проекта настолько быстрый, что для индексации даже весьма большого проекта (я тестировал на пустом проекте Laravel, созданном с помощью командыcomposer create-project --prefer-dist laravel/laravel blog, которая генерирует 1.6 млн строк кода на PHP) на одном ядре процессора требуется порядка 450 мс, что дает возможность запускать NoVerify локально, например, при каждом сохранении файла и сразу видеть новые предупреждения, без необходимости использовать его, как language server.
Недостатки/особенности решения
Время сборки Go-кода для кеша для проекта в 1.6 млн строк занимает 20–60 секунд, в зависимости от режима сборки, поэтому использовать его для ускорения цикла разработки и тестирования самого линтера, возможно, и не получится. Время сборки не являлось первым приоритетом при разработке кеша на основе кодогенерации.
Сам кеш также сильно увеличивает размер бинарника: на вышеупомянутом проекте бинарник noverifyturbo вырос в размере с 20 мб до 100 мб, то есть прирост составил ~80 мб на 1.6 млн строк PHP-кода.
Также, из-за особенностей реализации кеша в NoVerify, пути до файлов являются частью пути до файла с кешом и они должны в точности совпадать у пользователя с путями, использовавшихся во время сборки NoVerify. Эта проблема решаема, но требует доработок в механизме работы кеша в линтере.
Как работает турбо-кеш
Основная идея кеша на основе кодогенерации очень проста: берем структуры данных, в которых хранится кеш в памяти и печатаем их как Go-код с помощью обычного fmt.Printf("%#v", value).
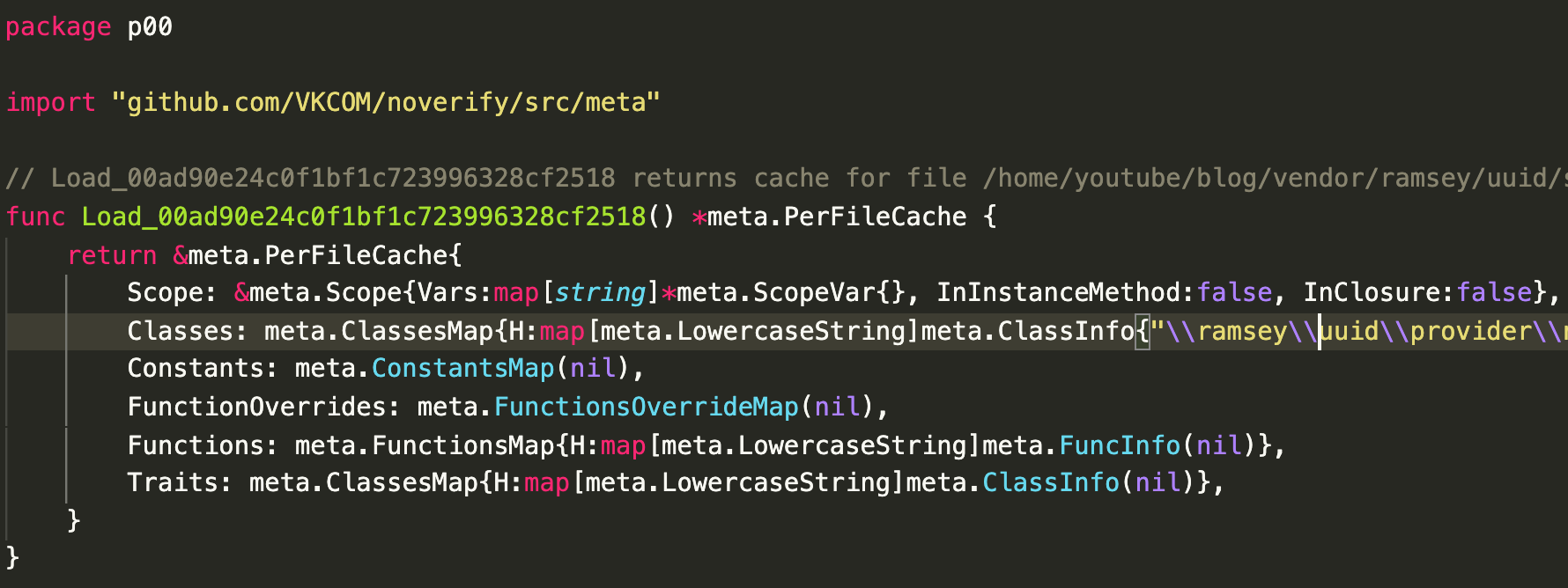 пример сгенерированного кода
пример сгенерированного кода
Для этого, правда, все поля структур в кеше должны быть публичными, но это при желании тоже можно обойти, если определять свой метод GoStringer (), в котором вызывать конструкторы для инициализации значений.
Для каждого файла создадим свой Go-файл, и объявим один большой map[string]func()*PerFileCache, где в качестве ключа будет указываться обычный путь до файла с кешом (этот путь зависит от имени файла и от хеша от его содержимого, и он у нас уже есть, поскольку файловый кеш всё ещё полезен), а в качестве значения будет функция, возвращающая уже инициализированную структуру с кешом для конкретного файла. Вместо того, чтобы возвращать функции, можно сразу сделать указатели на значения, но не факт, что нам понадобятся все записи из этого map (поскольку турбо-кеш можно использовать только для тех файлов, которые не менялись с момента создания этого кеша), и заодно, при желании, объекты можно создавать из нескольких горутин одновременно, а если мы сразу инициализируем весь map значениями сразу, то эту логику нам придется писать самим.
В качестве дополнительной оптимизации можно кешировать соответствие между размером файла+временем его модификации и хешом от его содержимого, чтобы не требовалось читать содержимое всех файлов в проекте во время индексации, а всего-лишь звать системный вызов stat () на каждый файл, который обычно работает намного быстрее чтения файла целиком.
Реальное использование
Сделанный мной кеш — это лишь эксперимент, который мне было интересно провести в своё личное время, поэтому применимость этой конкретной реализации на практике может быть никакой, всё зависит от мейнтейнеров проекта, коим я не являюсь (я в данный момент работаю в Google, но этот эксперимент делался в свободное от работы время и не имеет отношения к компании).
Поскольку NoVerify написан на Go, то он может компилироваться в один нативный бинарный файл, в который уже встроен phpstorm-stubs и также может быть встроен «прогретый» кеш проекта. Такой бинарник может стартовать и проверять отдельные файлы достаточно быстро даже на слабых ноутбуках. Это, в теории, позволяет разработчикам легко встроить NoVerify в свой workflow разработки, например запускать его локально каждый раз при сохранении файла в PHPStorm или VS Code и сразу видеть новые предупреждения линтера, если таковые имеются.
Ссылки
NoVerify — быстрый линтер PHP от ВКонтакте.
phpstorm-stubs — репозиторий с «заглушками» для встроенных в PHP функций и классов.
Пример реализации кеша на основе кодогенерации в NoVerify
Эксперимент с кодогенерацией для статичных phpstorm-stubs
Сравнение различных форматов сериализации данных в Go
