Ускоряем Cycle Time и растим счастье в команде

Куда и зачем смотреть, что поменять, чтобы в два раза ускорить командное время от взятия задачи в работу до её попадания в артефакты продакшена? Как при этом не мучить бесполезной рутиной команду, а сделать её счастливее? Для этого нужно автоматизировать подсчёты Cycle Time и научиться правильно читать графики. Посмотрим, как это сделать.
Меня зовут Никита Дубко, я беларус и мастер подземелий в D&D. А ещё — доброжелюбный бородач из подкаста «Веб-стандарты» и руководитель службы разработки HR Tech Яндекса. Моя задача — оптимизация процессов. О том, как я это делаю, и пойдёт речь в статье. Текст написан по мотивам моего доклада на TeamLead Conf 2022.
Эффективность
Начнём с того, что такое эффективность. В Википедии сказано, что эффективность — «это соотношение между достигнутым результатом и использованными ресурсами». Красивое определение, но давайте посмотрим, как с ним работать.
Рассмотрим Scrum. В нём есть разные методики работы с теми или иными артефактами. Можно заставить команду бежать одну или две недели, то есть устроить спринт. Также можно попытаться оценивать задачи с помощью сторипоинтов (SP): вот эта задача на 500 сторипоинтов, а эта — на 3. Таким образом, эффективность можно рассчитать, измерив, на сколько сторипоинтов команда выполнила работы в спринте:
E = SP / спринт
Но действительно ли, чем больше сторипоинтов, тем выше эффективность? Иногда бывает так, что много SP запихивают в одну задачу. Кажется, что всё здорово, спринт закрыт, но у команды не появляется ощущение принесённой пользы, а эффект для пользователя непонятен. Ещё может быть вот такой интересный бёрндаун:
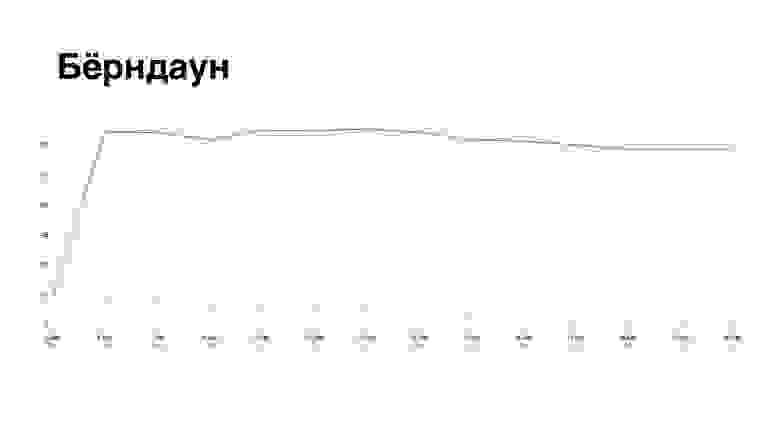
Потому что не всегда получается взять и всё сделать идеально. В 2021 году на Saint TeamLead Conf был классный доклад Яна Ашенкампфа «Как я выбираю, кому повысить зарплату?». Там он разбирал много примеров, показывающих, почему любой способ оценить эффективность по количественным метрикам обречён на манипуляции со стороны команды.
Например, если вы будете оценивать строчки кода, то рано или поздно появится правило в линтере, которое будет мотивировать добавлять эти самые строчки где попало. А если оценивать количество коммитов, то любая задача начнёт дробиться на мелкие правки, чтобы коммитов стало больше. Ну и даже, если оценивать по сторипоинтам, то команда сможет обосновать, почему задача была выполнена не за 2 SP, а за 8. Потому что команда, как правило, сама устанавливает «стоимость» 1 SP, при этом она же и оценивает задачи — чувствуется неувязка.
А что, если попробовать оценивать не по сторипоинтам, а по количеству фич в спринте? То есть:
E = количество фич / спринт
Ведь пользователи ждут именно фичи. Им не важно, сколько сторипоинтов вы на это потратили и сколько ретро провели, чтобы выкатить фичу быстрее. Они ждут, когда в продакшене появится то, чего они хотят.
Допустим, что фича — это тикет в трекере задач. Тут можно подсмотреть, как работают адепты Kanban.
В Kanban есть Cycle Time. Cycle Time — это время, которое задача находилась в разработке от момента, когда ей начали заниматься, до момента, когда она прошла фазу конечной поставки. С точки зрения тикета, это время перехода из In Progress в Closed, то есть в продакшен. Будем считать, что релиз — это тот самый статус Closed. Если на этот переход тратить меньше времени, фича будет быстрее попадать в прод. А чем быстрее она окажется в проде, тем выше эффективность команды.
Как с этим работать? Я расскажу вам две истории из личного опыта о том, как Cycle Time можно использовать в разных местах с разным объёмом задач.
История №1: большой продукт
Началось всё с того, что я стал скрам-подмастерьем. Принялся изучать, как эффективнее двигать процессы, как сделать команде хорошо. Со временем я стал техлидом, а потом, внезапно, — тимлидом. Когда проходишь этот путь, начинаешь понимать, где и что может болеть.
Особенности Поиска
Поиск — это большой проект с большой аудиторией. Процессы уже давно налажены — понятно, как и что с ними делать. Релизы там катаются дважды в день: вечером и утром. Они хорошо автоматизированы. Нужно просто успеть попасть на этот релизный паровозик, но в целом команда не зависит от того, когда катится релиз.
У нас есть «зелёный» транк. Это такой подход, когда всё максимально покрывается тестами, чтобы что-то упало в CI на любую правку в коде, если тесты при этом не поправили. И даже если всё хорошо, тестировщики всё равно посмотрят релиз. Не дай бог какой-то баг! Баги нельзя пропускать, потому что их увидят миллионы — такая особенность.
Статусы задач
Статусы задач в этом процессе выкатки были такие:
- Open — менеджер завёл тикет, но пока в нём нет ничего, кроме описания.
- Need info — разработчик начал что-то делать, но ему не хватает информации. Например, где дизайн или указаний о том, что делать с бэкендом.
- In progress — разработчик уже работает над задачей.
- In review — разработчик написал код, закоммитил и ждёт, когда его коллеги придут и скажут, где всё замечательно, а где нужно поправить.
- Review completed — ревью пройдено, можно работать с тикетом дальше. Этот промежуточный статус иногда очень полезен для торможения тикета.
- Ready for test — статус говорит тестировщикам, какие задачи можно забирать.
- Testing — идёт тестирование.
- Tested — задача протестирована.
- Ready for Dev — тикет готов к тому, чтобы его залили в основную ветку, которая называется Trunk.
- Dev — код попал в ветку Trunk и готов к выкатке релиза.
- Release candidate — код попал в релиз, который сейчас едет в продакшен.
- Closed — всё классно, код в продакшене.
Важно объяснить команде значение всех этих статусов — особенно новичкам. Когда люди обладают общим понятийным аппаратом, они не задают вопрос, почему нужно переводить тикет в такой-то статус. Для этого, например, можно завести вики-страничку, документацию или просто давать информацию на онбординге. Ещё можно диаграмму в Miro нарисовать и пошарить со всеми.
Как считать, сколько тикет находился в каждом статусе? С одной стороны, можно зайти в трекер, покликать и подсчитать с калькулятором, сколько тикетов выполнено, а сколько — в работе.
С другой стороны, мы же технари. Почти у всех трекеров задач есть API. Где-то он платный, где-то — бесплатный. Через API можно, как правило, брать и получать данные скриптами. Не надо делать ничего руками, пускай страдают машины. Тем более, что машины могут строить сложные внутри, но удобные пользователям графики.
Графики
Как работают эти графики? Что на них происходит? Во-первых, есть фильтр задач.
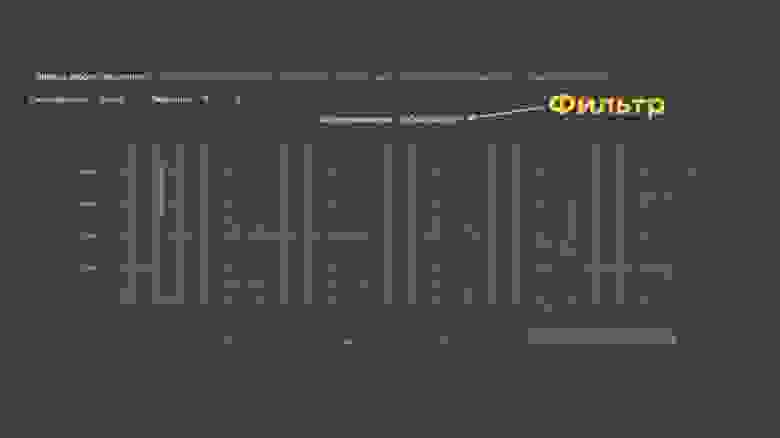
В вашем таск-трекере может быть много разных задач, они лежат в разных очередях, с ними работают разные команды и так далее. Поэтому вы собираете фильтр — его, при необходимости, можно сделать кастомным внутри очереди. С помощью этого фильтра вы говорите графику, с какими тикетами ему работать.
Во-вторых, есть скользящее окно. Что это и зачем оно? Представим, что мы считаем, как долго задачи находились в статусах от In progress до Closed. Возьмём задачи, которые перешли в Closed за последние 28 дней. Это нам показывает график:

Но если мы будем просто смотреть на каждую задачу отдельно, то нормальной статистики не увидим. Будет много выбросов, зависимостей от встреч в календаре, фаз луны. Такие графики очень тяжело анализировать. Нужно взять скользящее окно и провести его по заданному перцентилю.

85-й перцентиль в окне в 28 дней — это значение метрики, в которое попадает 85% задач за эти 28 дней. Оно и попадёт на график.
Самое классное, что вы можете использовать скользящее окно, чтобы ставить цели перед командой. Например, если вы хотите ускориться за следующие полгода, можно выставить скользящее окно в 6 месяцев, и позднее оно покажет, как вы продвинулись в деле улучшения эффективности работы с тикетами.
В-третьих, есть второй график, который показывает все статусы с таким же скользящим окном и перцентилем:
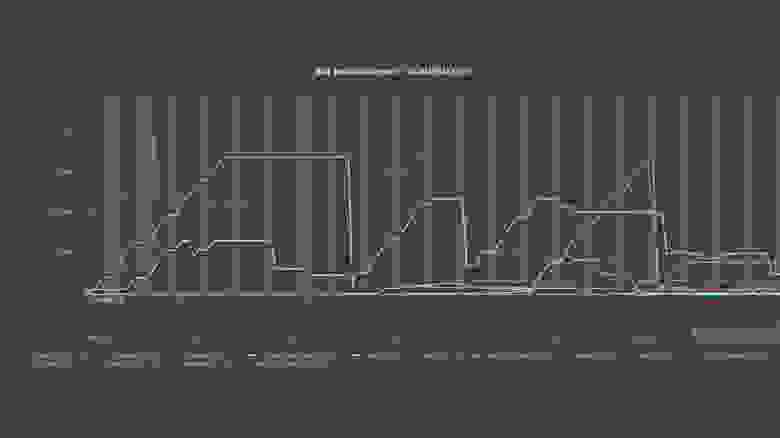
Можно также выделять конкретные статусы и смотреть на их динамику:
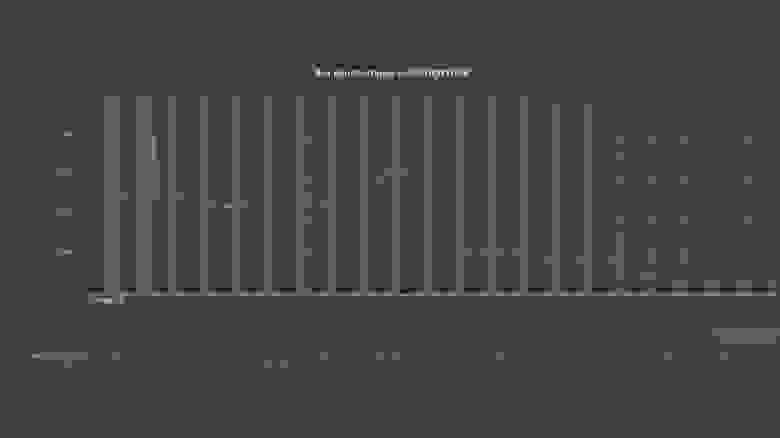
И, наконец, есть график, который показывает, за сколько была выполнена каждая отдельная закрытая задача:

Это тоже полезный инструмент, потому что здесь можно выцепить аномалии. Например, тикет потенциально был простым, но на графике видно, что его закрыли за два или три месяца — повод присмотреться внимательнее.
Как сделать лучше?
Задача оптимизаторов — минимизировать время в статусе. Мы смотрим на эти графики и пытаемся придумать, как сделать лучше. Конечно, самый простой способ — прийти в команду и попробовать заставить её работать быстрее, сказав: «Тестировщик, ты чего медленно тестируешь? Давай быстрее». Но это вряд ли сработает. По-хорошему, нужно спрашивать у команды, что ей мешает делать быстрее. Что нужно сделать внутри команды, чтобы ей стало лучше?
Конвейерный метод

Это Генри Форд. В 1914 году он внедрил конвейерный метод, перевернув индустрию — один человек теперь не должен был отвечать за всё, ведь появился выстроенный процесс. Каждый делает одну часть работы и передаёт её дальше. Причём значительную долю задач взяли на себя машины. Если присмотреться, движение тикетов — это тоже в какой-то мере конвейер доставки задач в продакшен.
Я выписал три принципа оптимизации производительности труда по Форду:
- Ограничивать число операций, которые выполняет рабочий. Если мы говорим про тестировщика или разработчика, то нужно посмотреть, что он делает, и убрать лишнее и ненужное из этого процесса.
- Приближать задачу к исполнителю. Разработчики должны не просто продвигать тикеты и внедрять код, а понимать, зачем они это всё делают, иметь продуктовое видение.
- Учитывать последовательность выполнения операций. Если мы оптимизируем процесс в каком-то одном месте, в другом он может сломаться. Так бывает. Поэтому нужно проводить ретро.
Ретро про процессы
Поговорите с командой, принесите ей графики и обсудите, почему где-то работа стала идти медленнее, что можно с этим сделать. Прямо такая мини психологическая сессия. Она много чего покажет, если у вас с командой доверительные отношения.
Вот какие вопросы можно задавать:
- Что хорошо в процессах? Что нужно закрепить?
- Что болит? Где стало плохо? Почему процессы замедлились?
- Как улучшить процессы? Что мы можем сделать, чтобы не болело?
Принцип Парето

Это Вильфредо Парето — человек, который научил менеджеров использовать числа 20 и 80 где попало. Принцип Парето гласит, что 20% усилий приводят к 80% результата. Фишка в том, что, конечно, команда может нагенерировать много идей — обалденных и не очень — однако не всегда они реализуемы и по-настоящему полезны. Например, у нас была идея убрать встречу об оценке задач из календаря и переложить этот муторный процесс на ML. Казалось бы, классная и современная идея. У нас есть исторические знания о старых тикетах, берём их и просто скармливаем модели. А она уже пусть оценит, сколько там было сторипоинтов и реального времени на разработку. Но вот нюанс: тикеты не всегда хорошо заполнены. Иногда это просто заголовок, что, прямо скажем, грустно. И участники команды не всегда корректно присваивают статусы тикетам. К тому же, теряется очень важный этап обсуждения сути
Что мы сделали в нашей команде?
- Стали реализовывать простые идеи и сделали автоматизацию призывов в тикеты. Теперь, когда нужно, чтобы тестировщик посмотрел ту или иную задачу, трекер призывает его в комментарии через триггеры, а ещё присылает на почту письмо с призывом. Выглядит это примерно так. Допустим, назначается демо в конце спринта. Тогда трекер просит через триггер заполнить блок «Тезисы для демо внутри тикета»:

Человеку, который собирает презентацию для демо, почти ничего не нужно делать: он просто копирует тезисы из тикета. Такая небольшая автоматизация очень удобна и значительно экономит время. Ещё она помогает развивать продуктовое видение — люди лучше понимают, для чего они работают.
- Добавили умные подсказки-комментарии в нужные моменты. Важно, чтобы человек был ближе к задаче. Когда разработчик переводит тикет в статус In Review, поднимается стенд с доработанной версией приложения, которую тут же можно тестировать. Триггер добавляет комментарий о том, как подготовить тикет к тестированию:

Это очень полезно новичкам. Тестировщики иногда меняются, поэтому для сменщика, который, например, работает вместо заболевшего коллеги, процессы будут новыми. В таком случае нужно просто перевести тикет в статус Testing. Тестировщику тут же придёт в комментарии форма с чекбоксами, ссылками и инструкциями, что нужно проверить:

- Порой можно нарушать общие правила в части кросс-ревью. Поиск большой — его делает огромное количество людей. Полезно делать «перекрёстное опыление», когда на код-ревью приходят разработчики из разных команд. Однако иногда это очень сильно тормозит Cycle Time, так как погружаться в чужой код долго, в бизнес-процессы другой команды — сложно, а релиз желательно выкатить уже завтра. Поэтому мы решили ревьювить код только у себя внутри. Но если вдруг кто-то захочет прийти, то пусть приходит — мы не будем игнорировать замечания и внесём правки в рамках техдолга.
- Написали генераторы кода. Мы заметили особенность наших экспериментов: обёртка в коде у них везде повторяется. Сама генерация — очень банальная, она просто подставляет названия флагов («включателей» экспериментов) и правильно называет папки. Но такая генерация экономит огромное количество времени. Причём автогенерация может быть какой угодно. Можно взять и придумать инструмент, а затем протащить его тикетом в спринт. Например, инструмент, помогающий удобнее дебажить сниппеты. Так мы в Поиске делали сниппеты, а также отдельный инструмент под них, который принимает JSON и рисует сниппет такой же, как в проде, но без доступа к бэкенду. Если у вас, например, React-стек или Storybook, напишите какую-то обёртку, которая поможет посмотреть всё, что нужно.
Ещё пример. Один человек в команде взял и написал полезного бота, которому передаётся ссылка на борду со спринтом, а сам он ходит по тикетам и собирает из них презентацию для демо. Так человек сэкономил и своё время, и помог всей команде.
- Завели шаблоны тикетов. Если какое-то поле не заполнено, в тикете оно выделяется жёлтым или красным цветом. Так можно проверять менеджеров на халтуру. Мы даже договорились, что плохо заполненные тикеты не будем брать в работу.
- Придумали, как поднять команде настроение. Когда мы добавляем автоматизацию, появляется слишком много роботов, но слишком мало настроения. Мы начали разбавлять описания тикетов и комментарии в них мемами и похвалой.
- Оптимизировали календарь встреч. Мы выяснили, что ребятам не нравится, когда за встречей на 15 минут следует получасовой перерыв, после которого — снова встреча на 15 минут и так далее. В таких условиях работать невозможно. Поэтому мы прошлись по календарю и выпилили ненужные встречи к чёрту.
- Сделали отбивки по Cycle Time. Графики Cycle Time можно взять и вставить в комментарии через iframe, чтобы показать, какой Cycle Time был у той или иной задачи. Мы назвали это «отбивки в тикет с Cycle Time». Для тех, кто занимается оптимизацией, это очень удобно. Если вдруг проявилась какая-то аномалия, можно зайти в тикет и посмотреть:
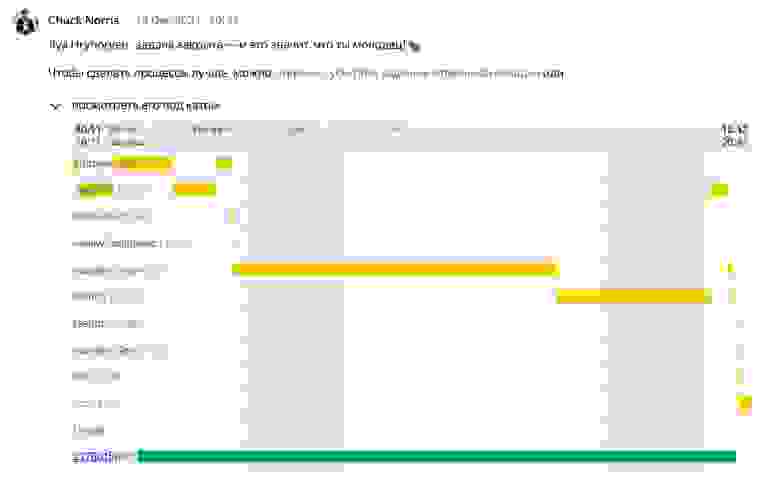
Здесь, например, тикет долго висел в статусах Need Info и Ready For Test — тестировщик не приходил.
Ещё удобно, что включается эффект наблюдателя — человеку, который выполнял эту задачу, тоже приходит отбивка. Таким образом, команда сама начинает задумываться, что пошло не так.
Как мы это внедрили? В команде был ответственный за Cycle Time — я. Сейчас этим занимается кто-то другой, но такая роль есть в каждой команде. В целом, это тот же человек, который смотрит на графики. Возможно, у вас им может стать скрам-мастер.
- Оптимизация должна быть на пользу, не должна мешать работе команды. Именно для этого стоит проводить ретро. Когда вы собираетесь на ретро, важно, чтобы команда превращала свои обещания в тикеты. И, естественно, важно периодически проводить ретро про процессы — смотреть, что помогает, а что мешает.
Ещё у нас появилась прикольная штука — клуб по интересам. Там люди, которые оптимизируют Cycle Time, стали обсуждать разные интересные фишки: что они сделали и где собрали какой-то инструмент. Это позволило делиться идеями.
- Мы устроили багатоны. Если баги не критичные, мы не чиним их в течение всего спринта, а выделяем для этого отдельные дни — багатоны. Чем это полезно? Когда мелкие баги прилетают в течение недели, они меняют контекст. Например, я занимался большой фичей, но, вдруг, переключился на мелкий баг, для которого нужно писать тесты. В результате — фича не доделана. Это очень тормозит разработку. Теперь же мы с командой в один день просто накидываемся на баги, и, не поверите, так мы стали лидерами по ZBP — Zero Bug Policy.
- Потраченное на внедрение улучшалки время должно привести к экономии и/или приросту настроения в будущем. Это важно, потому что если команда довольна своей работой, она работает чуть лучше и эффективнее. А если потратить много времени на сложную оптимизацию, но она в итоге почти не принесёт пользы, вряд ли команда будет рада.
Результаты
Хочется поделиться результатами оптимизации:
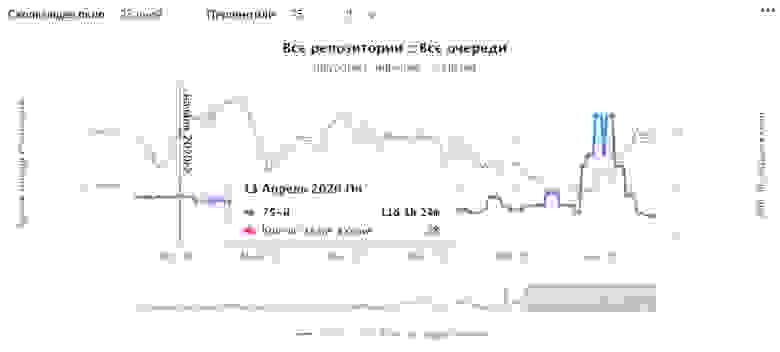
Если посмотреть на начало семестра, на 75-м перцентиле по плавающему окну в 28 дней тикеты находились в работе около 11 дней. А в конце семестра — 7 дней. То есть оптимизация достаточно сильная.
История №2: почти аутсорс
В своё время я перешёл из Поиска в HR Tech. В мае нам исполнится два года — команда HR Tech достаточно молодая. По процессам мы похожи на аутсорс, потому что у нас много проектов, некоторые из которых живут по полгода — то есть после запуска работают в режиме саппорта. Кроме того, мы используем разные стеки технологий, а сама команда небольшая.
Сейчас я руковожу службой разработки. Сначала думал, что изученные на предыдущем месте практики оптимизации будут работать «из коробки», но всё оказалось иначе. Потому что большая продуктовая разработка — это одно, а маленькая команда с маленькими проектами — совсем другое. Здесь процессы большого продукта с налаженными схемами перестают работать.
Проблемы
- Не работало скользящее окно. Потому что есть проекты на саппорте, в которых тикеты проходят путь от взятия в работу до релиза медленно.
- У разных команд отличаются релизные циклы и процессы. Например, бэкендеры релизятся раз в неделю, фронтендеры — после мёржа в trunk. Нужно их всех как-то синхронизировать, чтобы ничего не сломалось.
- В некоторых местах не было такой крутой автоматизации, как в Поиске. Поиск обмазан своими автоматизациями, но лучшие решения — кастомные. Их нельзя просто взять и переиспользовать, как есть.
- Проекты на поддержке. Сложно вспоминать, что с ними делать. Такие проекты тяжело деплоить, потому что там легаси. И задачи там редкие — приходят раз в полгода.
Как я внедрял Cycle Time?
Можно было бы сдаться и жить без графиков Cycle Time. Но я решил, что не смогу так.
- Вместо общей очереди настроил свой график каждому проекту. Теперь можно посмотреть, что происходит в проекте, используя фильтры для конкретной очереди.

- Дополнительно сделал отдельную очередь и отдельные фильтры для задач. Оптимизируя бэклог для графиков, я сделал для самого себя работу с бэклогом по проектам удобнее.
- Вместо времени до Closed начали измерять время до Merged. Почему? Потому что есть проекты на саппорте, у которых релиз выкатывается раз в полгода. В этих случаях исправление багов и вливание изменений могут происходить уже после закрытия задачи.
- Начали работать над унификацией процессов, чтобы в командах было что-то общее. Для этого мне пришлось сесть и нарисовать, как движется тикет:
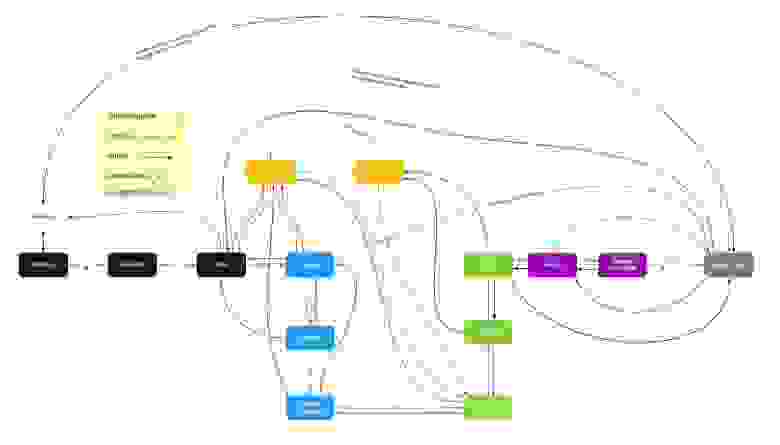
КликабельноНа этой схеме объясняется, что должно происходить, когда тикет переходит из одного статуса в другой, какие статусы и переходы полезны, а какие — вредны.
- Каждому проекту пришлось выставить индивидуальный перцентиль. Это необходимо, чтобы отсечь аномалии на графике. Дело в том, что есть проекты, в которых очень много задач. Для них стоит ставить 90-й перцентиль, так аномалии будут лучше видны. Но если брать проекты, где задач мало, лучше ставить 60-й перцентиль, так как из-за малой выборки получается очень много аномалий. С ними нужно разбираться отдельно.
- Важно было объяснить команде, что такое приборы для наблюдения. Хотя эти графики изучает, в первую очередь, руководитель, команда тоже должна о них знать. Так обеспечивается эффект наблюдателя. Зачем? У меня был такой случай: я принёс графики Cycle Time, а команда никогда с ними не работала. Ребята подумали, что графики нужны, чтобы я следил, как медленно команда решает задачи. Мне пришлось объяснять, что это не слежка, а придумано для того, чтобы найти места, где можно оптимизироваться. Смысл графиков нужно объяснить всей команде и конкретно тем, кто против такого подхода, чтобы в целом все более или менее с ним согласились.
- В моём календаре появилась встреча с самим собой. Раз в неделю примерно один час я трачу на изучение графиков и аномалий. Потом аномалии приношу, например, на ретро или подхожу к людям и спрашиваю, почему так получилось. Они знают, что я делаю это не для того, чтобы узнать, почему у них так медленно идёт тикет. Они знают, что я пытаюсь оптимизировать процесс, придумать какую-то автоматизацию.
- У нас появилось ретро про процессы с командой. Оно привнесло в работу много интересного, потому что я в команде был новым человеком, а разработчики уже давно сидели с какими-то болями. Что мы выяснили на ретро? Низкий бас-фактор в некоторых проектах, иногда только один человек знал, как что-то делать. Эту проблему надо было решать.
- Получилось улучшить декомпозицию некоторых задач. Теперь, когда менеджер приносит задачу, мы пробуем сделать в одном тикете бэкенд, а в другом — фронтенд. Или большую фичу дробим на самостоятельные кусочки, которые можно показать на стенде и протестировать независимо.
- Мы ускорили код-ревью — перестали ждать, когда кто-то придёт на код-ревью, а начали прямо в чате команды писать: «Ребята, посмотрите, пожалуйста, #review_request».
- Выстроили новые процессы работы с дизайнерами. В этом месте процессы шли медленнее, потому что у нас есть и внутри дизайнеры, и на аутсорсе. С ними нужно работать по-разному. Пришлось подумать, как сделать удобнее.
- Завели шаблоны для создания новых задач. Причём для багов и фич шаблоны разные. Для багов важно уметь их воспроизвести, а для фич — понимать ожидаемый результат.
- Я сходил в команду инфраструктуры, они добавили автоматизацию — закрытие тикетов по релизу. Теперь, когда выкатывается релиз, тикеты автоматически закрываются. Например, я качу релиз, в котором 20 тикетов, но мне не нужно проходить по каждому и закрывать руками. Экономия каких-то пяти минут, но каждый раз радует.
- В некоторых проектах убрали тестирование из PR, оставили только релизное. Благодаря такому решению мы очень сильно ускорились в определённых местах.
Помогло ли это?
Посмотрим на графики.

По этому фильтру работа началась приблизительно в июне, то есть мы с 19 дней на задачу ускорились до 9 дней. Результат ещё круче, чем в Поиске!
Обратите внимание на зелёную линию. Это количество задач, которые попали на график. Мы стали чуть больше декомпозировать и, как следствие, выполнять больше задач.
Итоги и советы
→ Графики Cycle Time — полезный инструмент. Не считайте Cycle Time в Excel, попробуйте внутри команды сделать свой инструмент. Дайте задачу фронтендерам сверстать эти графики, бэкендерам — собрать для них данные. Это не сложно. Ещё и приятное переключение с рутины на сайд-проект.
→ Не мешайте команде делать работу. Не нужно постоянно приходить к людям с предложением: «Давайте оптимизировать Cycle Time, давайте бежать быстрее». Команда хочет работать, а не оптимизировать ваши процессы и графики.
→ Убирайте мусор в процессах. Везде, куда ни придёшь, есть легаси. Однако много от чего можно отказаться, избавиться от старья. Конечно, стоит спросить у команды, но иногда нужно просто взять и переписать проект, чтобы работа пошла в разы быстрее. Или посмотреть на встречу в календаре, на которой ничего полезного не происходит, и отменить её. Или вообще отказаться от всех встреч, кроме одного синка в неделю, а коммуникацию перенести в чат.
→ Донесите до команды, что Cycle Time — это не про наказание. Этот инструмент не для того, чтобы следить и заставлять работать быстрее — он призван сделать процессы лучше.
→ Автоматизируйте рутину. Вещи, которые можно переложить на скрипты, обязательно перекладывайте на скрипты. Многие делают руками и не задумываются, что можно ничего не делать, а только смотреть на результаты.
→ Попытайтесь сделать рутину веселее и проще. Добавьте настроения в ваш трекер.
→ Обязательно спрашивайте у команды, где болит. Если у вас где-то болит, это не значит, что у команды та же проблема. Может, у разработчиков всё нормально. Тут важно придумать, как поддерживать баланс.
→ Доверяйте инструментам, а не только ощущениям. Вам может казаться, что процесс идёт плохо, а на приборах — отличные показатели. Или наоборот — может казаться, что стало лучше, а по инструментам — хуже. Но иногда к ощущениям тоже нужно прислушиваться.
→ При любой аномалии задавайте вопрос «Почему?». О каждой бесполезной встрече в календаре я спрашиваю: почему она произошла? Здесь явно что-то пошло не так в процессах. Может быть, нужно что-то автоматизировать или просто убрать какие-то задачи, не делать их больше никогда.
→ Иногда люди просто ленятся или не могут работать по объективным причинам. Бывает такое, когда приходишь на работу, открываешь новости и работать не хочется. К этому тоже нужно относиться с пониманием.
→ Работа над процессами — не факультатив. Если вы будете заниматься Cycle Time, не делайте это факультативно. Это ваша работа. Берёте тикет «Работа над процессами» и доводите его до ума в рабочее время. У меня, по крайней мере, не получалось факультативно.
→ Подсматривайте и не упарывайтесь. Мы в взяли что-то из Scrum, подсмотрели что-то в Kanban, а в итоге получилось классно. Не упарывайтесь по процессам, потому что иногда слишком хочется оптимизировать, чтобы всё было идеально. Не нужно — помните про принцип Парето. Берите то, что ближе к вам, и пытайтесь в этих местах улучшиться.
→ Старайтесь делать команду счастливее. Я искренне верю, что команда, которая довольна своей работой и радуется тому, что у неё мало рутины, начинает работать лучше. Моя личная статистика показывает, что это так.
→ Feature Time. Можно попробовать оптимизировать, если с Cycle Time уже всё хорошо. Это классная метрика, но, внедряя её, важно выстроить работу с менеджерами. Feature Time используется, когда берётся не отдельный тикет, а эпики — например, когда мы целый экран хотим выпустить в прод. С этой важной метрикой тоже нужно уметь работать.
→ Lead Time. Эта метрика измеряет время от момента, когда мы завели тикет, до момента, когда мы его закрыли. То есть не от взятия в работу, а от его появления в трекере. Используя эту метрику, можно находить «бриллианты» в бэклоге и чистить его от того, что никогда в работу не попадёт.
Надеюсь, что эти две истории и перечисленные мной советы позволят вам достичь оптимального Cycle Time коротким путём, не получив местами болезненный опыт, который получил я. Материалы моих коллег тоже помогут — скоро пройдёт следующая TeamLead Conf, на которой можно будет подключиться к Яндекс треку и другим нашим докладам.
