Уравнение с тремя неизвестными: как отлавливать баги в системах хранения данных
Привет! Меня зовут Никита, я инженер в компании YADRO и занимаюсь разработкой ПО для системы хранения данных TATLIN.UNIFIED. С системами хранения данных (СХД) я работаю уже много лет и люблю эту тему. Она постоянно бросает новые вызовы, заставляя решать довольно сложные и нестандартные проблемы, что очень увлекательно само по себе, а удачные решения приносят огромное удовлетворение.
В статье я попытаюсь погрузить вас в проблемы, с которыми нам, инженерам YADRO, приходится сталкиваться при отладке программного обеспечения СХД. Также покажу особенности работы с такими системами. Расскажу, какие инструменты, а иногда и решения, которые мы пишем сами, приходится для этого применять. А еще постараюсь сформулировать условия, которые необходимы для нахождения причин возникновения ошибок обработки данных в системе.
Текст про особенности поиска багов был бы пустым без конкретных примеров, поэтому под катом вас ждет разбор случая, который произошел в нашей лаборатории при тестировании производительности СХД.

Поиск багов и отлаживание СХД: почему это непростая задача
Для начала — пара слов о том, что же такое СХД и TATLIN.UNIFIED в частности. Если упрощать, корпоративная система хранения данных — это большая и красивая коробка размером от двух юнитов (конкретно TATLIN.UNIFIED занимает 7U). Она монтируется в стойку и подключается к другим частям инфраструктуры с помощью Ethernet или Fibre Channel. Для приложений, которые используют СХД, она выглядит как обычный диск, блочное устройство или сетевая папка, доступная SMB или NFS.
Возникает резонный вопрос: почему нельзя использовать обычный жесткий диск или твердотельный накопитель, зачем платить больше? Дело в том, что современные системы хранения используют сложные технологии, которые позволяют:
защищать данные от возможной потери или повреждения,
использовать кеширование и параллелизацию для существенного повышения скорости работы по сравнению с обычными дисками,
реплицировать данные между разными СХД и многое другое.
Из-за возможности СХД обрабатывать огромные потоки данных на высоких скоростях этот класс систем относится к высоконагруженным. Это значит, что их тестирование и отладка представляют отдельную и совсем не простую задачу.
Как тестируются обычные приложения? Допустим, мы хотим проверить корректность переключения приложения со светлой темы на темную. Тогда в тесте в качестве начального условия мы фиксируем режим приложения со светлой темой и проверяем доступность кнопки переключения на темную тему, нажимаем на кнопку переключения на темную тему. Если при этом приложение переключилось на темную тему, то тест прошел успешно. Если нет — тест провален.
Этот пример, разумеется, сильно упрощен. Тем не менее, большую часть тестов обычных приложений можно представить как валидацию корректности работы программы конечного автомата: мы фиксируем начальное состояние системы, генерируем какое-то конечное количество управляющих сигналов, а затем проверяем, что финальное состояние системы соответствует нашим ожиданиям.
С высоконагруженными системами такой подход не работает из-за высокой интенсивности поступления входящих запросов и их большой вариативности. Также свои коррективы в поведение системы вносят такие случайные факторы, как задержки сети при передаче данных, задержки дисков при обработке запросов и прочие. Поэтому для тестирования и отладки СХД мы используем другой подход: генерируем различные нагрузки и проверяем, что система обрабатывает их корректно.
Это означает, что мы пишем много-много разных данных, а затем читаем эти данные и проверяем, что они сохранены без ошибок. Многообразие профилей нагрузок и сопутствующих сценариев, таких как имитация выхода из строя различных компонентов системы, определяет полноту тестирования. Тем не менее, создать исчерпывающий набор тестовых сценариев, который бы гарантировал абсолютную корректность работы системы, очень и очень сложно. Всегда остается вероятность, что существует редкий набор факторов, который не был протестирован и который в итоге приводит к ошибкам в работе СХД.
Когда такое происходит, задача инженеров — найти и устранить причину как можно быстрее. Для этого у нас есть определенный подход, который я опишу далее.
Три кита поиска багов в системах хранения данных
По опыту отладки программного обеспечения TATLIN.UNIFIED могу сказать, что для успешного обнаружения и исправления ошибки должны выполняться три условия: локализуемость, воспроизводимость и наблюдаемость. Далее я разберу каждое из них, а поможет мне в этом довольно хитрый баг, который проявился на нашем тестовом стенде.
Как мы обнаружили проблему
Клиенты могут использовать СХД для решения широкого спектра задач: обслуживания облачной инфраструктуры, предоставления дискового пространства базам данных, создания «файлопомоек» и многих других. Достаточно часто эти задачи совмещаются — например, создается сервер баз данных в облачной инфраструктуре, то есть СУБД запускается внутри виртуальной машины, гипервизор которой в качестве дискового бэкенда использует СХД.
При планировании конфигурации инфраструктуры пользователю очень важно понимать различные характеристики СХД, чтобы быть уверенным, что конечная среда будет способна решать возложенные на нее задачи. Одна из самых важных характеристик СХД — это производительность. Чаще всего она оценивается с помощью общих синтетических тестов, которые могут дать приближенную оценку для разных видов реальных нагрузок. Но иногда клиента интересуют результаты исполнения конкретных бенчмарков в определенном окружении, поэтому мы периодически гоняем их в некоторых типичных условиях.
Один из сценариев — это СУБД PostgreSQL, которая запущена внутри виртуальной машины. Периодически мы тестируем такой стек с помощью стандартного бенчмарка pgbench, который запускаем внутри виртуальной машины под управлением Linux (в нашем случае это CentOS).
Для этого собираем конструкцию из сервера виртуализации и тестового стенда СХД. Создаем там виртуальную машину с PostgreSQL и запускаем pgbench. Но нас ожидает сюрприз: вместо результатов измерений получаем ошибку. PostgreSQL ругается, что какой-то из внутренних файлов базы данных не прошел проверку контрольной суммы. Это означает, что сервер записал одни данные, а прочитал другие.
Стандартные тесты не нашли ошибку. Почему? Вероятнее всего, тестовый стенд генерирует специфическую нагрузку, которую мы не используем в тестах. Проблема в том, что собранная инсталляция содержит в себе несколько уровней абстракции, которые делают поиск ошибки чрезвычайно трудной задачей.
Для начала хотелось установить, в какой части системы происходит ошибка.
Условие 1: локализуемость
Что такое локализуемость? Давайте рассмотрим следующий пример. Допустим, мы пытаемся загрузить виртуальную машину в гипервизоре, где дисковое пространство предоставляет тестовая СХД, и на этапе загрузки операционная система виснет. При этом с другой СХД или со стандартным диском гипервизора таких проблем мы не наблюдаем. Очевидно, проблема связана с тестовой системой хранения. Но мы не можем по этим симптомам сказать, в каком именно компоненте и на каком уровне произошла ошибка. Такой тест позволяет нам однозначно утверждать, что в СХД существует ошибка обработки данных, но не позволяет понять ее источник.
То есть локализуемость — это возможность определить компонент системы, в котором произошла проблема, и адрес на диске, который стал источником проблемы. Эти данные нам нужны для дальнейшего анализа ситуации.
Чаще всего в стандартных тестах СХД мы не сталкиваемся с проблемой локализации ошибки, так как используем специальные инструменты генерации нагрузки (о них чуть позже), которые предоставляют нам всю необходимую информацию об ошибке, если такая происходит. Локализовать ошибку далее — дело техники.
Дополнительные сложности возникают, если между генератором нагрузки и тестируемым блочным устройством есть какой-то уровень абстракции — например, файловая система. В этом случае генератор нагрузки укажет на ошибку проверки данных как на смещение в файле, поэтому придется предпринять дополнительные шаги, чтобы сопоставить смещение внутри файла блоку на тестируемом устройстве. Однако почти все современные популярные файловые системы предлагают стандартные инструменты для определения положения файлов на блочном устройстве.
Как и файловая система, любая другая абстракция, например, система виртуализации, приносит дополнительные сложности. При этом особенную проблему представляет проприетарное ПО, внутреннее устройство которого является закрытой информацией. Такой непрозрачный уровень абстракции делает невозможным локализацию ошибки на уровне блока тестируемого устройства.
На практике
Посмотрим на ситуацию с багом, который мы воспроизвели. У нас есть система хранения, на которой создан блочный ресурс. Сверху — гипервизор. На нем есть диск, который предоставлен разным виртуальным машинам на CentOS c файловой системой ext4, сверху — PostgreSQL Server со своими файлами.
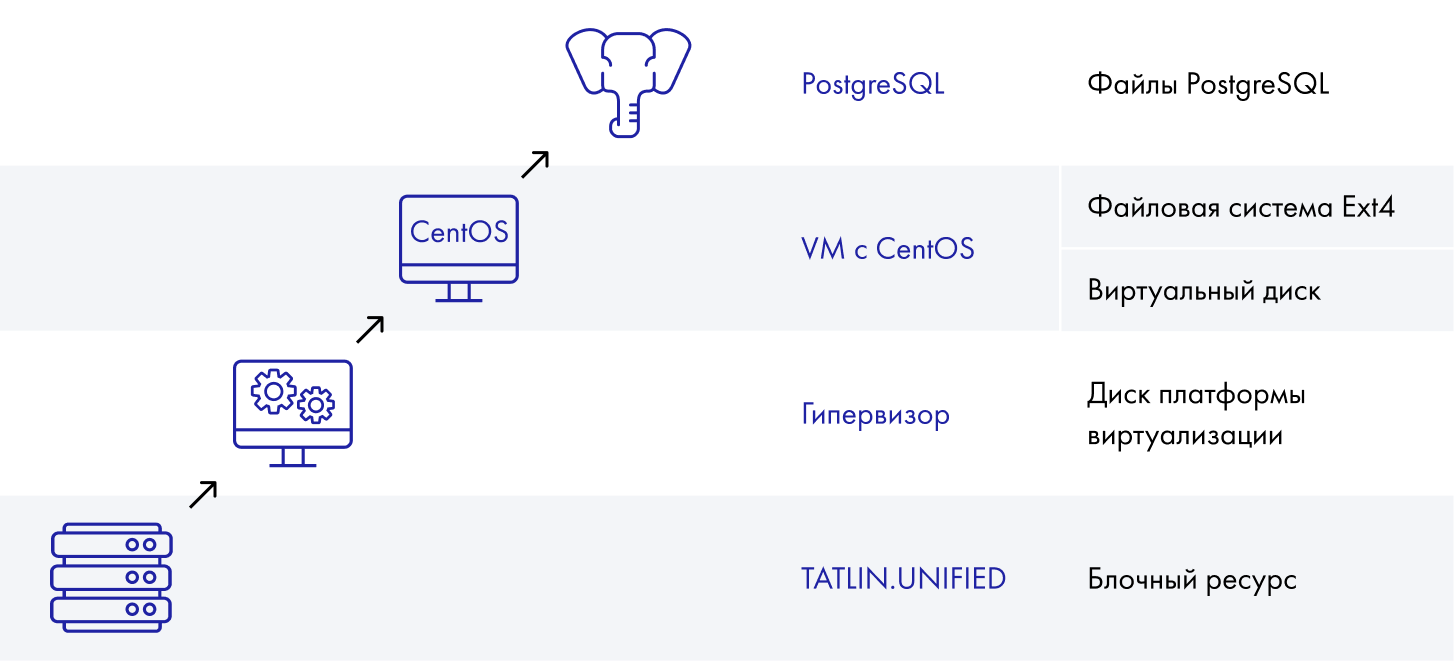
Структура тестового окружения
К сожалению, мы не знаем, как устроен проприетарный гипервизор, как он работает с блочным устройством. А значит, этот уровень становится для нас непрозрачным и мы не можем преодолеть его при анализе нашего бага.
Первое, что приходит в голову, — это попробовать уменьшить число компонентов. Раз у нас есть уровень, который мешает нам с локализацией проблемы, значит, можно исключить его из рассмотрения в надежде, что специфическая нагрузка, вызывающая ошибку, не изменится настолько, чтобы проблема перестала воспроизводиться.
Собираем конструкцию в сокращенном виде:
внизу — блочное устройство, созданное на TATLIN.UNIFIED,
далее — физический сервер под управлением CentOS с файловой системой ext4,
верхний уровень — PostgreSQL.

Конструкция в «укороченном» виде для проверки гипотезы
FAIL: Наша гипотеза не подтвердилась: после исключения платформы виртуализации из тестовой конструкции баг перестал воспроизводиться.
Условие 2: воспроизводимость
Что такое воспроизводимость? Это условие, которое подразумевает возможность выработать некий повторяемый сценарий, приводящий к ошибке. Запуская его снова и снова, можно получать больше информации о проблеме, применять дополнительные инструменты и таким образом продвигаться к пониманию, что именно идет не так.
Чтобы воспроизводимость работала на поиск ошибки, нужны:
Понятные условия эксперимента. Если у нас нет полной информации о том, что предшествовало и сопутствовало появлению ошибки, есть большая вероятность, что хитрый баг поймать не получится.
Оптимальная продолжительность эксперимента. Если мы будет тратить недели или месяцы на каждое воспроизведение проблемы, мы рискуем с ней вообще никогда не разобраться.
Как я отмечал выше, для тестирования и отладки СХД мы генерируем различные нагрузки и проверяем, как с ними справляется система. На первый взгляд кажется, что для генерации нагрузки логично использовать те же приложения, что работают у наших пользователей. В таком случае тестовые сценарии будут максимально точно повторять реальность использования наших систем заказчиками. Но это только на первый взгляд.
На самом деле использование для тестирования настоящих приложений, работающих с СХД, — это очень трудоемкий процесс, а время исполнения теста может вырасти до неприемлемых значений:
Реальные приложения, как правило, не работают сами по себе, а обслуживают какие-то бизнес-процессы в инфраструктуре клиента. То есть мы должны воссоздать у себя в лаборатории кусок инфраструктуры клиента, наполнить его данными, похожими на реальные, и эмулировать процессы, взаимодействующие с приложением.
Реальные приложения, как правило, требуют нетривиальной настройки, что сильно усложняет тестовые сценарии.
Число реальных приложений достаточно большое, а учитывая разнообразие вариантов их использования, количество тестовых сценариев будет исчисляться многими тысячами. Нам просто не хватит времени и ресурсов на их исполнение.
Поэтому обычно для тестирования СХД используют генераторы нагрузки — специальные приложения, которые умеют отправлять I/O запросы в устройства и контролировать их выполнение.
Одним из популярных генераторов нагрузки для СХД является утилита FIO (Flexible IO Tester). Она позволяет описывать и воспроизводить сценарии с учетом большого количества деталей, в числе которых размер I/O запросов, механизм записи в устройство, глубина очереди и другие параметры. Утилита работает как с блочным, так и файловым хранилищем. А главное, она умеет проверять целостность данных, которые были записаны ею ранее. При этом, когда FIO обнаруживает ошибку при проверке данных, утилита указывает на проблемный блок на диске, что значительно упрощает дальнейший анализ.
Как может выглядеть сообщение об ошибке при завершении теста

С помощью FIO мы можем строить готовые тестовые сценарии, которые позволяют нам добиваться воспроизводимости результатов снова и снова. Если у нас есть кейс, который можно закодировать в виде сценария FIO, победа над багом не заставит себя ждать. Мы проигрываем сценарий и получая ошибку, добавляем дополнительную статистику или точки трассировки, смотрим результат, воспроизводим еще раз, смотрим результат — и так до тех пор, пока не обнаруживаем проблему.
На практике
Для облегчения поиска ошибки в нашем случае было бы здорово использовать эквивалентный сценарий для FIO, чтобы при нахождении поврежденных блоков утилита указывала нам адреса поврежденных данных. Но мы не знаем, как выглядит нагрузка, создаваемая нашим «слоеным пирогом».
Тут нам на помощь приходит другая замечательная утилита — blktrace, которая умеет регистрировать нагрузку, подключаясь к любому блочному устройству. Обычно blktrace используют в паре с blkparse — другой утилитой, которая умеет превращать записанные blktrace данные в человекочитаемый формат. Вывод blkparse выглядит так:
259,13 86 1 0.343494823 18067 Q WS 35665024 + 72 [etcd]
259,13 86 2 0.343495938 18067 G WS 35665024 + 72 [etcd]
259,13 86 3 0.343507106 18067 U N [etcd] 1
259,13 86 4 0.343508532 18067 D WS 35665024 + 72 [etcd]
259,13 86 5 0.349054348 18067 Q WS 35665096 + 56 [etcd]
259,13 86 6 0.349054752 18067 G WS 35665096 + 56 [etcd]
259,13 86 7 0.349073576 18067 Q WS 35665152 + 64 [etcd]
259,13 86 8 0.349074211 18067 G WS 35665152 + 64 [etcd]
259,13 86 9 0.349077026 18067 U N [etcd] 2
259,13 86 10 0.349078440 18067 D WS 35665096 + 56 [etcd]
259,13 86 11 0.349079444 18067 D WS 35665152 + 64 [etcd]
259,13 80 1 0.386271923 14550 Q WS 35665216 + 8 [etcd]
259,13 80 2 0.386274097 14550 G WS 35665216 + 8 [etcd]
259,13 80 3 0.386283533 14550 U N [etcd] 1
259,13 80 4 0.386284664 14550 D WS 35665216 + 8 [etcd]
259,13 117 1 0.408320608 14549 Q WS 35665224 + 8 [etcd]
259,13 117 2 0.408321872 14549 G WS 35665224 + 8 [etcd]
259,13 117 3 0.408327769 14549 U N [etcd] 1
259,13 117 4 0.408328485 14549 D WS 35665224 + 8 [etcd]
259,13 120 1 0.410082359 19846 Q WS 42756864 + 128 [etcd]
259,13 120 2 0.410083585 19846 G WS 42756864 + 128 [etcd]
259,13 120 3 0.410090911 19846 U N [etcd] 1
259,13 120 4 0.410091431 19846 D WS 42756864 + 128 [etcd]Среди прочих записываются следующие данные:
идентификатор блочного устройства,
адрес блока и его размер,
timestamp события (отсчитывается от момента запуска blktrace),
тип операции (чтение, запись),
фаза (завершение, начало, постановка в очередь и подобное).
А еще генератор нагрузки FIO умеет проигрывать трассы, записанные blktrace, поэтому решение напрашивается само собой. В стандартном эксперименте, который происходит в полном окружении со «слоем» виртуализации, мы записываем нагрузку, а потом проигрываем ее с помощью FIO. Кажется, все просто, но нет.
FAIL: Мы не смогли обеспечить третье важное условие — наблюдаемость. Оказалось, в режиме, когда FIO проигрывает записанные трейсы, утилита не умеет проверять целостность данных. Мы можем запустить сценарий, но не увидим, сломалось ли что-то и, если сломалось, то где и как. Мы теряем одно из условий, и поэтому данный подход нас тоже не устраивает.
Условие 3: наблюдаемость
Что такое наблюдаемость? Это возможность понять суть проблемы: что именно пошло не так. Возможность использовать инструменты, которые дают нам больше информации о том, что происходило с тем блоком данных или частью диска, который в итоге сломался.
Обычно приложения пишут логи. Если возникает проблема, инженер смотрит и анализирует их, понимает, что пошло не так, и принимает решение, что нужно поправить. Системы хранения данных тоже пишут логи, но только в контексте настройки и управления конфигурацией (control plane). В контексте обработки данных интенсивность процессинга такая высокая, что мы не можем использовать логи по двум причинам*:
никакого места не хватит, чтобы их хранить, так как количество событий может достигать нескольких сотен тысяч или даже миллионов в секунду,
производительная система деградирует настолько, что будет непригодна для использования.
*в целом, вы можете попробовать включить логи, но тайминги съедут настолько, что система начнет вести себя абсолютно по-другому и, скорее всего, проблема не будет воспроизводиться.
Поэтому разработчики СХД используют специальные инструменты для сбора информации о событиях в системе, которые устроены несколько иначе, чем стандартные логи. При этом важно, чтобы инструмент минимально влиял на быстродействие системы.
Выбор таких средств довольно большой, выбирать стоит исходя из конкретных задач. Чтобы узнать о них больше, можете прочитать неплохую обзорную статью про средства трассировки в Linux — в ней автор пытается систематизировать информацию о существующих инструментах.
Наша команда в свое время остановилась на LTTng. Это интересный инструмент, который позволяет собирать большое количество отладочной информации в единицу времени без существенного влияния на систему.
Как ему это удается? Точки трассировки добавляются в нужные места в программе. При обычной работе, когда сбор трасс выключен, влияние на производительность незначительное или полностью отсутствует. Когда же мы включаем трассировку, влияние минимальное — такой результат достигается за счет того, что LTTng использует для каждого канала трассировки несколько кольцевых буферов в памяти, события записываются в оперативную память с минимальными задержками. Пока события заполняют одни буферы, другие, заполненные ранее, сбрасываются на диск или в сеть. Подробнее про внутреннее устройство LTTng читайте по ссылке.
Все потенциально полезные точки трассировки должны быть добавлены в компоненты системы заранее. Когда нужно изучить определенную проблему, включается необходимый набор точек трассировки, проводится эксперимент, анализируются полученные данные. Если картина остается неясной, набор точек трассировки корректируется, а эксперимент проводится заново. Обычно за несколько таких итераций удается понять причину некорректного поведения системы.
Основные точки трассировки, которые мы используем, — это события на входе и выходе из нашего компонента. К каждому из событий мы прикрепляем внутренний идентификатор, адрес блока и главное — контрольную сумму данных.

Примерно такие данные можно получить с помощью LTTng. Слева направо: время, название точки, событие (чтение, запись), идентификатор команды, адрес блока и контрольная сумма.
Если контрольная сумма при чтении не соответствует контрольной сумме при записи, это говорит о проблеме: мы записали одни данные, а прочитали другие. Этого достаточно, чтобы потенциально локализовать блок, где произошло повреждение.
На практике
После проведения ряда тестов нам стало понятно, что все данные у нас под рукой. Если мы каким-то образом проанализируем все трассы, то найдем всю необходимую информацию. У нас записаны все события, есть адреса блоков и их контрольные суммы. Единственное, что мы не знаем, — в каком именно блоке (или блоках) произошли повреждения. А значит, для определения проблемы нужно найти способ так обработать собранные данные, чтобы обнаружить поврежденный блок: сгруппировать все данные по адресам блоков, проанализировать для каждого блока последовательность событий и понять, были ли нарушения целостности данных.
Для этого в оригинальном облачном окружении с PostgreSQL можно провести эксперимент с включенной трассировкой и отгрузить данные на отдельный сервер. Затем на нем запустить анализатор, который найдет проблемные блоки.
Когда не собираются все три условия
Итак, в поиске решения мы пришли к тому, что не можем провести эксперимент, в котором выполнялись бы все три условия: локализуемость, воспроизводимость и наблюдаемость. Но есть возможность найти баг через более глубокий анализ трасс. Для этого нужно написать отдельную программу, состоящую из двух частей: парсера трасс, которые генерирует LTTng (на диске они хранятся в бинарном формате CTF — Common Trace Format), и анализатора, который с помощью базы данных может найти поврежденные блоки.
Такую программу мы несколько лет назад разработали в YADRO. Пользуемся ей в редких нестандартных случаях, когда в задаче много неизвестных, а привычные утилиты не справляются.
Как работает программа: Поток событий, поступающий с выхода парсера трасс, всегда упорядочен по времени возникновения события. С помощью базы данных события группируются по адресам блоков, которым они принадлежат. При добавлении каждого нового события мы смотрим на последовательность предыдущих для этого же блока данных. Проанализировав последовательность событий для каждого блока данных и соответствующие им контрольные суммы, программа находит несоответствия прочитанных данных записанным. Все несоответствия добавляются в конечный отчет, который использует инженер для дальнейшего анализа проблемы.

В чем преимущества написанной программы:
она получилась компактной — вышло порядка 10 000 строк на C++,
у нее модульная архитектура, которая позволяет подключать различные парсеры и анализаторы для расширения возможностей,
довольно высокая скорость работы — примерно 50 000 событий в секунду — за счет параллелизации обработки трасс (конечно, не очень много в сравнении со скоростью работы СХД, но все же).
Главное, что мы таким образом заложили основу для построения инструментария, который позволит за счет добавления новой подключаемой функциональности покрыть более широкий класс потенциальных проблем. А значит, будет помогать быстрее и эффективнее анализировать баги.
Ответ на загадку тестового стенда
Пара слов о том, как устроен кеш в TATLIN.UNIFIED. Вся память, отведенная под кеш, разбита на страницы. Каждая страница кеша в любой момент времени содержит в себе данные, относящиеся к какому-то из фрагментов дискового пространства. Сама страница состоит из блоков, каждый из которых может содержать:
«грязные» данные — те, что еще не записаны на диск,
«чистые» данные — те, что синхронизированы с диском,
или быть пустым. Если страница содержит хотя бы один «грязный» блок, то вся она помечается «грязной», то есть требующей синхронизации с диском

Во время записи данных в СХД они сначала помещаются в кеш — соответствующие страницы и блоки помечаются как «грязные». Через некоторое время «грязная» страница должна быть записана на диск, после завершения записи она помечается как «чистая».
Во время обработки операции чтения сначала проверяется, нет ли нужных данных в кеше. Если такие данные есть, то они сразу возвращаются наружу. Если данных нет, то они читаются с диска, а соответствующие страницы кеша обновляются — данные копируются в кеш.

Что же произошло? Неудачное чтение. Пришла команда на чтение определенного блока в странице, в которой были и «грязные», и пустые блоки (1). Чтение попало в пустой блок, поэтому операция была перенаправлена в диск, чтобы дочитать недостающие данные (2). В этот же момент политика кеширования приняла решение, что эту страницу необходимо записать на диск (3), поэтому была сформирована соответствующая команда записи и отправлена на обработку в диск (4). Почти сразу после этого операция чтения закончилась, и мы получили новые данные, которых не было в кеше, поэтому мы обновили страницу кеша прочитанными блоками данных (5). Это произошло в то время, как страница записывалась в диск. То есть мы «подменили» содержимое страницы в тот момент, когда этого никак нельзя было делать. Так и родилась проблема, которую благодаря тестам мы отловили еще несколько лет назад.
Решить ее несложно: нужно сделать так, чтобы страница в кеше не обновлялась, если в это время она записывается на диск. Мы поправили логику обработки операций чтения и записи страницами кеша, и подобные ситуации больше не возникали.
Заключение
Конечно, с такими неуловимыми багами мы встречаемся нечасто. Большинство ошибок можно достаточно быстро обнаружить стандартными утилитами — чаще всего связка FIO + LTTng отлично справляется с этой задачей. Бывает и так, что проблема может «открыться» не сразу — не воспроизводиться или не локализовываться, но каждый случай помогает нам вырабатывать новые методы решения этих непростых уравнений с разными неизвестными.
