Упорядочиваем закладки
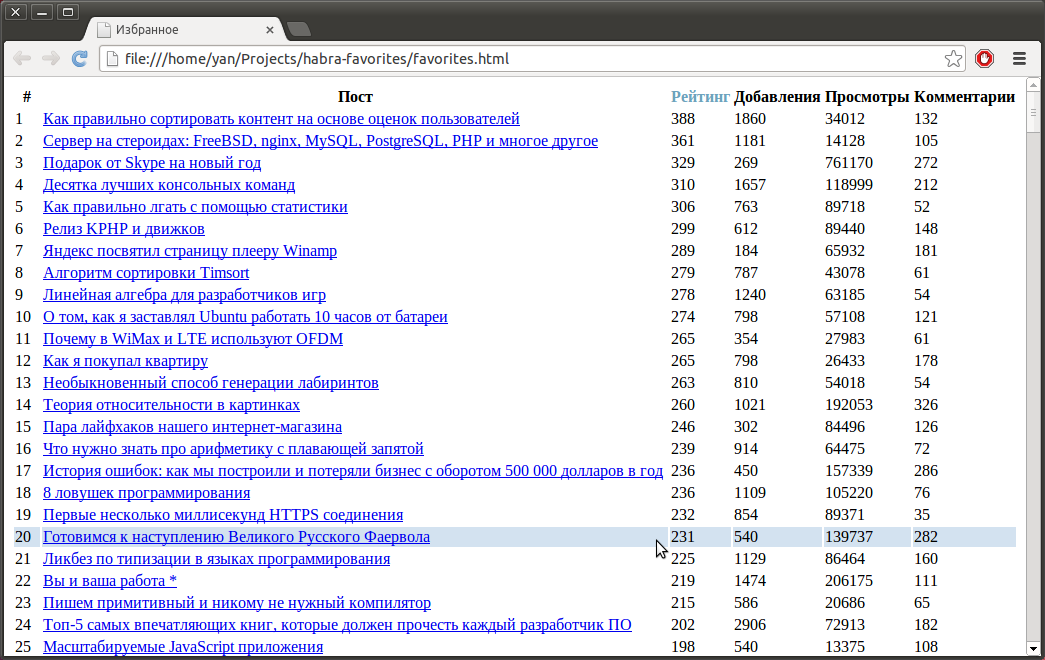
Закладки и их статистика
У меня много статей в закладках. Многие из них я добавил, чтобы прочитать позже. Эта статья не про то, почему так произошло и как с этим бороться, а про то, как выбрать статью для удаления чтения. Давайте найдем самые лучшие статьи. Критериями могут быть, например, рейтинг, просмотры и т.д. И красиво оформим в виде HTML-файла.
Пример закладок @alizar: 800+ статей.
Кратко
$ pip install habra-favorites$ habra_favorites# имя пользователя (не обязательно своё) $ firefox favorites.html # google-chrome favorites.html# Hint: на названия столбцов можно нажимать, чтобы переупорядочить.
Подробнее
Исходный код проекта доступен GitHub и залит на PyPI.
Для парсинга используется библиотека Scrapy. У нее очень хорошая документация, но позволю себе немного повториться и дополнить некоторые моменты.
Scrapy
В Scrapy мне нравится структурированность. Скелет проекта чем-то похож на структуру проекта Django, поэтому при описании будут возникать некоторые сопоставления.
Item
Первым делом объявим класс Item. Item — это описание элементов, которые мы будет сохранять. Если говорить в терминах Django, то это Model, не связанная с БД (хотя это можно добавить).
Вернемся к критериям сортировки. Это как раз и будут поля нашего Item: числовые данные, которые мы можем получить у статьи. Не забудем название с адресом и автора:
class FavoriteItem(Item):
id_ = Field()
ref = Field()
title = Field()
datetime = Field()
author = Field()
# Статистика
rating = Field() # рейтинг
rating_all = Field() # кол-во всех голосов
rating_up = Field() # кол-во голосов "за"
rating_down = Field() # кол-во голосов "против"
views = Field() # кол-во просмотров
count = Field() # кол-во добавлений
comments = Field() # кол-во комментариевLoader
Для упрощения обработки элементов существуют Loader’ы. Loader применяет функции для обработки данных и создает Item. Напоминает обработку форм в Django. Где-то просто приводим к числу, где-то пишем что-то своё:
class FavoriteItemLoader(ItemLoader):
default_item_class = FavoriteItem
default_output_processor = TakeFirst()
id__in = MapCompose(int)
ref_in = MapCompose(urljoin)
datetime_in = MapCompose(process_datetime)
rating_in = MapCompose(process_rating)
rating_all_in = MapCompose(process_rating_all(1))
rating_up_in = MapCompose(process_rating_all(2))
rating_down_in = MapCompose(process_rating_all(3))
views_in = MapCompose(process_views)
count_in = MapCompose(int)
comments_in = MapCompose(int)Spider
Переходим к самому пауку. Нужно сохранить статьи с текущей странички и перейти на следующую, если она есть. Немного упрощенный код:
def parse(self, response, **kwargs):
if response.status == 404:
msg = 'There is no such user.'
self.logger.error(msg)
raise CloseSpider(msg)
yield from response.follow_all(response.css('a#pagination-next-page'), self.parse)
posts = response.css('article.tm-articles-list__item')
for post in posts:
l = FavoriteItemLoader(selector=post, response=response)
l.add_xpath('id_', '@id')
l.add_css('ref', 'a.tm-title__link::attr(href)')
l.add_css('title', 'a.tm-title__link span::text')
l.add_css('author', 'a.tm-user-info__username::text')
l.add_xpath('datetime', '//time/@datetime')
l.add_css('rating', '.tm-votes-meter__value_rating::text')
l.add_css('rating_all', '.tm-votes-meter__value_rating::attr(title)')
l.add_css('rating_up', '.tm-votes-meter__value_rating::attr(title)')
l.add_css('rating_down', '.tm-votes-meter__value_rating::attr(title)')
l.add_css('views', '.tm-icon-counter__value::text')
l.add_css('count', '.bookmarks-button__counter::text')
l.add_css('comments', '.tm-article-comments-counter-link__value::text')
yield l.load_item()Pipeline
Есть еще уровень обработки: Pipeline’ы. Сюда поступают уже созданные Item’ы. В принципе, делать можно что угодно. Именно здесь обычно происходит сохранение в базу и проверка полей. Последним вариантом и воспользуемся: если у статьи нет рейтинга — выставим None.
class FavoriteItemPipeline(object):
def __init__(self):
self.fields = ['rating', 'rating_all', 'rating_up', 'rating_down']
def process_item(self, item, _spider):
for field in self.fields:
if field not in item:
item[field] = None
return itemExporter
Теперь нужно все данные собрать в файл. В Scrapy по умолчанию есть возможность сохранения данных в JSON, XML и СSV, которая реализуется с помощью классов Exporter. Но я решил, что HTML-страничка, где видно все статьи со ссылками и можно всё упорядочить, лишь кликнув мышкой, будет более удобным вариантом. Для этого был написан новый Exporter.
P.S.
Проект был создан 11 лет назад, когда еще был Хабрахабр (и Geektimes), а закладки были избранным. Отсюда и название.
