Юникод: необходимый практический минимум для каждого разработчика
Чтобы по-настоящему разобраться с Юникодом нужно хотя бы поверхностно представлять себе особенности всех письменностей, с которыми позволяет работать стандарт. Но так ли это нужно каждому разработчику? Мы скажем, что нет. Для использования Юникода в большинстве повседневных задач, достаточно владеть разумным минимумом сведений, а дальше углубляться в стандарт по мере необходимости.
В статье мы расскажем об основных принципах Юникода и осветим те важные практические вопросы, с которыми разработчики непременно столкнутся в своей повседневной работе.
Зачем понадобился Юникод?
До появления Юникода, почти повсеместно использовались однобайтные кодировки, в которых граница между самими символами, их представлением в памяти компьютера и отображением на экране была довольно условной. Если вы работали с тем или иным национальным языком, то в вашей системе были установлены соответствующие шрифты-кодировки, которые позволяли отрисовывать байты с диска на экране таким образом, чтобы они представляли смысл для пользователя.
Если вы распечатывали на принтере текстовый файл и на бумажной странице видели набор непонятных кракозябр, это означало, что в печатающее устройство не загружены соответствующие шрифты и оно интерпретирует байты не так, как вам бы этого хотелось.
У такого подхода в целом и однобайтовых кодировок в частности был ряд существенных недостатков:
- Можно было одновременно работать лишь с 256 символами, причём первые 128 были зарезервированы под латинские и управляющие символы, а во второй половине кроме символов национального алфавита нужно было найти место для символов псевдографики (╔ ╗).
- Шрифты были привязаны к конкретной кодировке.
- Каждая кодировка представляла свой набор символов и конвертация из одной в другую была возможна только с частичными потерями, когда отсутствующие символы заменялись на графически похожие.
- Перенос файлов между устройствами под управлением разных операционных систем был затруднителен. Нужно было либо иметь программу-конвертер, либо таскать вместе с файлом дополнительные шрифты. Существование Интернета каким мы его знаем было невозможным.
- В мире существуют неалфавитные системы письма (иероглифическая письменность), которые в однобайтной кодировке непредставимы в принципе.
Основные принципы Юникода
Все мы прекрасно понимаем, что компьютер ни о каких идеальных сущностях знать не знает, а оперирует битами и байтами. Но компьютерные системы пока создают люди, а не машины, и для нас с вами иногда бывает удобнее оперировать умозрительными концепциями, а затем уже переходить от абстрактного к конкретному.
Важно! Одном из центральных принципов в философии Юникода является чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
Вводится понятие абстрактного юникод-символа, существующего исключительно в виде умозрительной концепции и договорённости между людьми, закреплённой стандартом. Каждому юникод-символу поставлено в соответствие неотрицательное целое число, именуемое его кодовой позицией (code point).
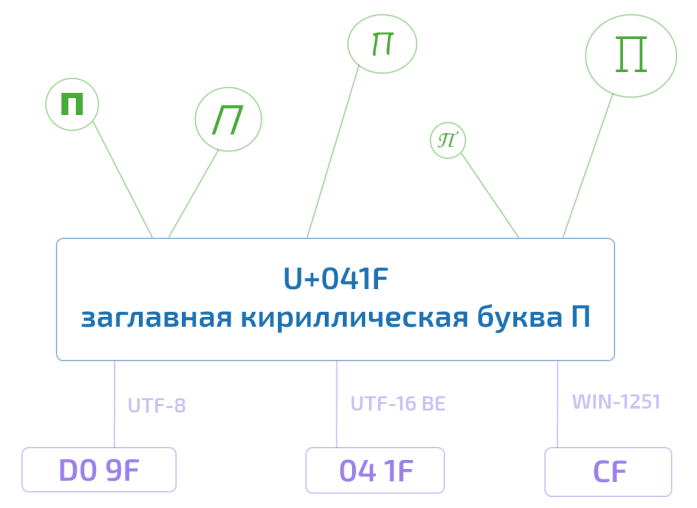
Так, например, юникод-символ U+041F — это заглавная кириллическая буква П. Существует несколько возможностей представления данного символа в памяти компьютера, ровно как и несколько тысяч способов отображения его на экране монитора. Но при этом П, оно и в Африке будет П или U+041F.
Это хорошо нам знакомая инкапсуляция или отделение интерфейса от реализации — концепция, отлично зарекомендовавшая себя в программировании.
Получается, что руководствуясь стандартом, любой текст можно закодировать в виде последовательности юникод-символов
Привет
U+041F U+0440 U+0438 U+0432 U+0435 U+0442
записать на листочке, упаковать в конверт и переслать в любой конец Земли. Если там знают о существовании Юникода, то текст будет воспринят ими ровно так же, как и нами с вами. У них не будет ни малейших сомнений, что предпоследний символ — это именно кириллическая строчная е (U+0435), а не скажем латинская маленькая e (U+0065). Обратите внимание, что мы ни слова не сказали о байтовом представлении.
Кодовое пространство Юникода
Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF. Из них к девятой версии стандарта значения присвоены лишь 128 237. Часть пространства зарезервирована для частного использования и консорциум Юникода обещает никогда не присваивать значения позициям из этих специальный областей.
Ради удобства всё пространство поделено на 17 плоскостей (сейчас задействовано шесть их них). До недавнего времени было принято говорить, что скорее всего вам придётся столкнуться только с базовой многоязыковой плоскостью (Basic Multilingual Plane, BMP), включающей в себя юникод-символы от U+0000 до U+FFFF. (Забегая немного вперёд: символы из BMP представляются в UTF-16 двумя байтами, а не четырьмя). В 2016 году этот тезис уже вызывает сомнения. Так, например, популярные символы Эмодзи вполне могут встретиться в пользовательском сообщении и нужно уметь их корректно обрабатывать.
Кодировки
Если мы хотим переслать текст через Интернет, то нам потребуется закодировать последовательность юникод-символов в виде последовательности байтов.
Стандарт Юникода включает в себя описание ряда юникод-кодировок, например UTF-8 и UTF-16BE/UTF-16LE, которые позволяют кодировать всё пространство кодовых позиций. Конвертация между этими кодировками может свободно осуществляться без потерь информации.
Также никто не отменял однобайтные кодировки, но они позволяют закодировать свой индивидуальный и очень узкий кусочек юникод-спектра — 256 или менее кодовых позиций. Для таких кодировок существуют и доступны всем желающим таблицы, где каждому значению единственного байта сопоставлен юникод-символ (см. например CP1251.TXT). Несмотря на ограничения, однобайтные кодировки оказываются весьма практичными, если речь идёт о работе с большим массивом моноязыковой текстовой информации.
Из юникод-кодировок самой распространённой в Интернете является UTF-8 (она завоевала пальму первенства в 2008 году), главным образом благодаря её экономичности и прозрачной совместимости с семибитной ASCII. Латинские и служебные символы, основные знаки препинания и цифры — т.е. все символы семибитной ASCII — кодируются в UTF-8 одним байтом, тем же, что и в ASCII. Символы многих основных письменностей, не считая некоторых более редких иероглифических знаков, представлены в ней двумя или тремя байтами. Самая большая из определённых стандартом кодовых позиций — 10FFFF — кодируется четырьмя байтами.
Обратите внимание, что UTF-8 — это кодировка с переменной длиной кода. Каждый юникод-символ в ней представляется последовательностью кодовых квантов с минимальной длиной в один квант. Число 8 означает битовую длину кодового кванта (code unit) — 8 бит. Для семейства кодировок UTF-16 размер кодового кванта составляет, соответственно, 16 бит. Для UTF-32 — 32 бита.
Если вы пересылаете по сети HTML-страницу с кириллическим текстом, то UTF-8 может дать весьма ощутимый выигрыш, т.к. вся разметка, а также JavaScript и CSS блоки будут эффективно кодироваться одним байтом. К примеру главная страница Хабра в UTF-8 занимает 139Кб, а в UTF-16 уже 256Кб. Для сравнения, если использовать win-1251 с потерей возможности сохранять некоторые символы, то размер сократится всего на 11Кб.
Для хранения строковой информации в приложениях часто используются 16-битные юникод-кодировки в силу их простоты, а так же того факта, что символы основных мировых систем письма кодируются одним шестнадцатибитовым квантом. Так, например, Java для внутреннего представления строк успешно применяет UTF-16.
В любом случае, пока мы остаёмся в пространстве Юникода, не так уж и важно, как хранится строковая информация в рамках отдельного приложения. Если внутренний формат хранения позволяет корректно кодировать все миллион с лишним кодовых позиций и на границе приложения, например при чтении из файла или копировании в буфер обмена, не происходит потерь информации, то всё хорошо.
Для корректной интерпретации текста, прочитанного с диска или из сетевого сокета, необходимо сначала определить его кодировку. Это делается либо с использованием метаинформации, предоставленной пользователем, записанной в тексте или рядом с ним, либо определяется эвристически.
В сухом остатке
Информации много и имеет смысл привести краткую выжимку всего, что было написано выше:
- Юникод постулирует чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
- Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF.
- Базовая многоязыковая плоскость включает в себя юникод-символы от U+0000 до U+FFFF, которые кодируются в UTF-16 двумя байтами.
- Любая юникод-кодировка позволяет закодировать всё пространство кодовых позиций Юникода и конвертация между различными такими кодировками осуществляется без потерь информации.
- Однобайтные кодировки позволяют закодировать лишь небольшую часть юникод-спектра, но могут оказаться полезными при работе с большим объёмом моноязыковой информации.
- Кодировки UTF-8 и UTF-16 обладают переменной длиной кода. В UTF-8 каждый юникод-символ может быть закодирован одним, двумя, тремя или четырьмя байтами. В UTF-16 — двумя или четырьмя байтами.
- Внутренний формат хранения текстовой информации в рамках отдельного приложения может быть произвольным при условии корректной работы со всем пространством кодовых позиций Юникода и отсутствии потерь при трансграничной передаче данных.
Краткое замечание про кодирование
С термином кодирование может произойти некоторая путаница. В рамках Юникода кодирование происходит дважды. Первый раз кодируется набор символов Юникода (character set), в том смысле, что каждому юникод-символу ставится с соответствие кодовая позиция. В рамках этого процесса набор символов Юникода превращается в кодированный набор символов (coded character set). Второй раз последовательность юникод-символов преобразуется в строку байтов и этот процесс также называется кодирование.
В англоязычной терминологии существуют два разных глагола to code и to encode, но даже носители языка зачастую в них путаются. К тому же термин набор символов (character set или charset) используется в качестве синонима к термину кодированный набор символов (coded character set).
Всё это мы говорим к тому, что имеет смысл обращать внимание на контекст и различать ситуации, когда речь идёт о кодовой позиции абстрактного юникод-символа и когда речь идёт о его байтовом представлении.
В заключение
В Юникоде так много различных аспектов, что осветить всё в рамках одной статьи невозможно. Да и ненужно. Приведённой выше информации вполне достаточно, чтобы не путаться в основных принципах и работать с текстом в большинстве повседневных задач (читай: не выходя за рамки BMP). В следующих статьях мы расскажем о нормализации, дадим более полный исторический обзор развития кодировок, побеседуем о проблемах русскоязычной юникод-терминологии, а также сделаем материал о практических аспектах использования UTF-8 и UTF-16.
