Уничтожить монополию Америки в EDA. Иннополис делает первый шаг

Еще с 1990-х годов меня поражало, что проектирование всей мировой цифровой микроэлектроники контролируется двумя конторами в Калифорнии, которые находятся в 10 минутах езды друг от друга — Synopsys и Cadence. В те времена четверть мирового проектирования делалось в Японии (континентальный Китай тогда находился в примитивном состоянии), и все эти Sony, Hitachi, Fujitsu и другие гиганты ездили на поклон в Америку и платили несчетные миллионы долларов за программы, которые потом использовали японские проектировщики. Сейчас это продолжается с Samsung, Huawei и с даже российскими конторами, которые проектируют микросхемы для космоса.
Русская земля умудрилась вырастить Yandex супротив Гугла, так почему бы и не попробовать создать какие-нибудь программы для проектирования микросхем? Начать можно с малого: популяризовать конкурсы и хакатоны по разработке алгоритмов автоматизации проектирования (Electronic Design Automation — EDA). Эти алгоритмы удобны тем, что у них много уровней сложности: простейшую программу Place & Route может написать студент за выходные, но вот на продвинутую потребуются десятилетия работы сотен людей и миллиарды долларов на R&D.
Сейчас в Иннополисе возле Казани делают мероприятие для студентов в формате «две недели подготовки + хакатон». Одним из тем стала традиционная задача EDA — размещение и трассировка графа электронной схемы на ряды стандартных ячеек. Будет интересно увидеть, что за это короткое время сможет осуществить небольшая команда студентов-программистов с базовым пониманием C++/Java/Python, методов парсирования текста, алгоритмов работы с графами и навыками визуализации структур данных с помощью GUI.
Итак — постановка задачи: 
Задача состоит из трех подзадач, которыми могут заниматься разные студенты:
- Парсирование текстового представления графа цифровой схемы.
- Размещение графа на рядах стандартных ячеек микросхемы и соединение этих ячеек дорожками (трассировка).
- Визуализация результатов — вывод на экран схемы дорожек и соединений.
Входом для программы является текстовый файл на очень ограниченном подмножестве языка описания аппаратуры Verilog. В этом файле описаны входы и выходы для схемы (input, output), внутренние соединения (wire) и приведен список логических элементов в формате «тип имя-экземпляра (список соединений)». Файл можно парсировать на C/C++ с помощью Lex+Yacc или аналогичных программ.

Результатом парсирования текста должно быть представление графа из элементов в памяти. Это представление будет использовано алгоритмом размещения и трассировки, которые потом создаст другую структуру. Если в команде хакатона будет достаточно участников, то результат начального парсирования можно визуализировать во время хакатона в качестве дополнительного задания. Примерно в таком духе, пусть даже не так красиво:

Если участников во время хакатона будет не хватать, то визуализацию промежуточного, неразмещенного графа стоит оставить на потом, а во время хакатона выводить на экран только окончательное размещение.
Вообще задачу парсирования можно ставить с несколькими уровнями сложности:
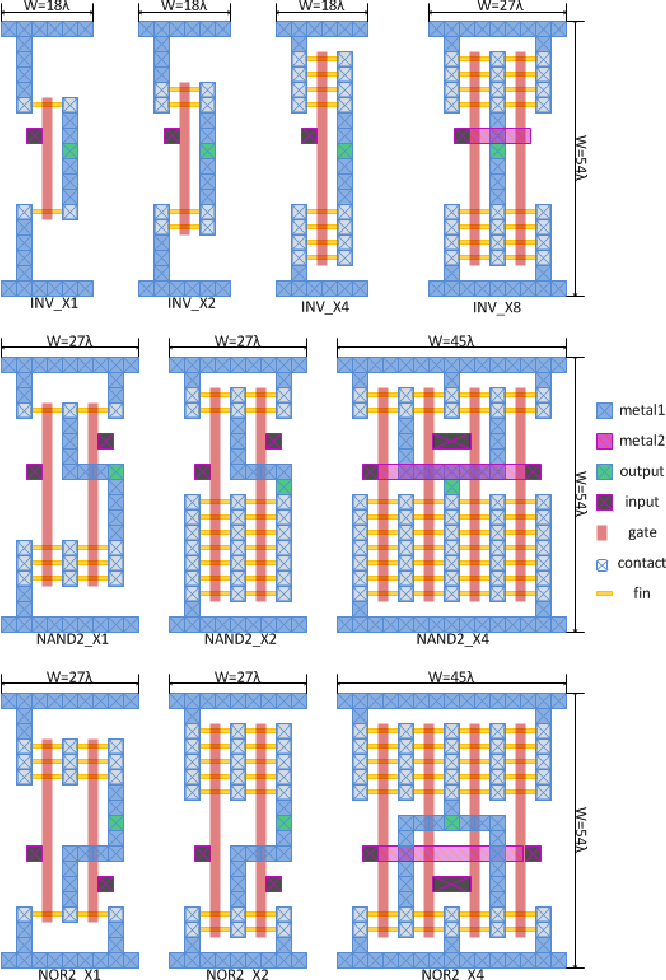
- В простейшем случаи все узлы графа — это двух-входовые логические элементы AND и OR, а также одновходовые элементы XOR. На окончательном размещении они реализуются стандартными ячейками одинаковой ширины.
- Если для хакатона хватит времени, задачу можно усложнить:
- ввести трех- и четырех-входовые ячейки AND3, OR4 и т.д.;
- расширить набор типов узлов добавлением NAND, XOR, D-триггеров (D-Flip-Flop) с разными опциями (reset, enable) и т.д.;
- сделать дополнительный текстовый файл, в котором задать ширину и другие параметры ячеек.
- После хакатона задачу можно привязать к реальному миру, и именно парсировать не абстрактные AND и OR, а файл в таком же формате, но с ячейками из реальных библиотек стандартных ячеек ASIC на 28, 14 или 7 нанометров, которые поставляют разработчикам EDA программ и проектировщикам фабрики типа TSMC (Taiwan Semiconductor Manufacturing Company).
Что такое стандартная ячейка? Это ячейка стандартной высоты для данной ASIC library, то есть библиотеки примитивов для изготовления микросхемы на фабрике по некоторой технологии. ASIC — Application Specific Integrated Circuit. Сейчас большинство микросхем, например в смартфонах — это ASIC. Ячейки в библиотеке ASIC имеют стандартную высоту, чтобы их было удобно выстраивать в ряды для подвода к ним питания и облегчения алгоритмов трассировки. Разные ячейки в библиотеке могут реализовывать не только примитивы типа AND и OR, но и более сложные конструкции — мультиплексоры, защелки, комбинации из двух-трех логических элементов (AND-OR) и т.д.
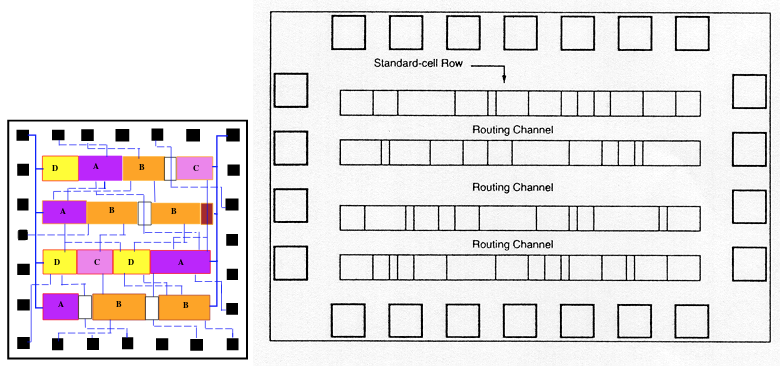
Ячейки на микросхеме выстраиваются в ряды (слайд из лекций Чарльза Данчека):

Между рядами есть каналы (routing channels), в которых проходят соединения. Ширину каналов можно менять, если в соединениях образуются заторы (congestion). В рядах можно делать просветы между ячейками:
Для хакатона задачу можно упростить до уровня сферического коня в вакууме:
- Ограничить типы ячеек. Для начала можно вообще размещать просто граф из двухвходовых NAND.
- Считать все ячейки имеющими одинаковую ширину.
- Игнорировать все аспекты физической природы ячеек, в том числе задержку прохождения сигнала и энергопотребление.
Здесь «игнорировать» — означает, что в учебном упражнении можно не учитывать физику ячейки при оценке качества размещения и трассировки. Для начала достаточно учитывать только геометрию, например минимизировать общую длину соединений и количество слоев, на которых делаются соединения. Необходимость в новом слое возникает когда невозможно разместить два проводника без их пересечения.
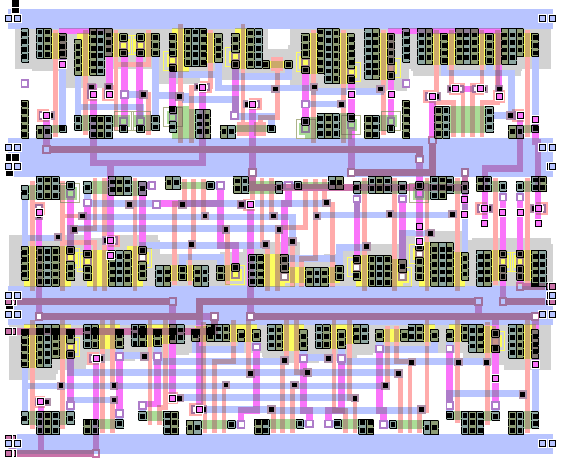
На хакатоне достаточно рассматривать стандартные ячейки как «черные ящики» и выводить их на экран как на рисунках сверху. Или с изображениями логических элементов, как на слайде из лекций Игоря Маркова:

Хотя если выводить с внутренностями ячеек, то картинки получаются более декоративными. Слайд из лекций Чарльза Данчека:

Еще картинка из интернета с размещением и трассировкой + изображением внутренностей ячеек:
А как размещать ячейки в ряды, расширять и сужать каналы между рядами, строить соединения, вводить новые слои, оценивать оптимальность результатов и перебирать варианты? Ну это чисто алгоритмически-программистские задачки, в Иннополисе наверное такому учат, посему я не буду растекаться мыслию или мысью по древу. В качестве начального вдохновения для трассировки можно использовать древний метод волновой трассировки, который описан в третьей части курса для школьников от РОСНАНО. Хотя этот метод не для стандартных ячеек выстроенных в ряды, а для менее упорядоченного случая с небольшим числом компонент:
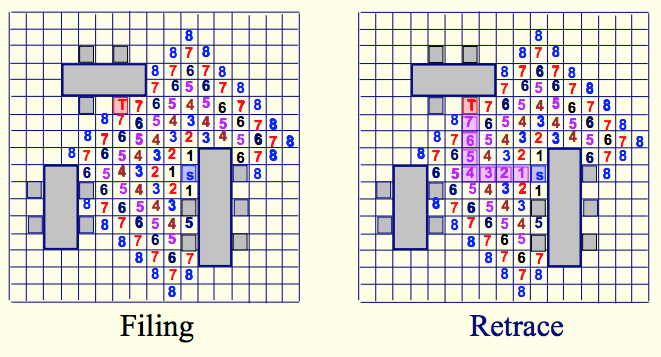
2.10. Как это делается: Алгоритм волновой трассировки.Один из классических алгоритмов, которые применяли ранние программы трассировки — это волновая трассировка, которую описал в статье 1961 года Честер Ли (C.Y. Lee), исследователь из Bell Labs. По английски алгоритм Ли называют «maze routing», что дословно переводится как «лабиринтовая трассировка». Такое название связано с тем, что помимо программ для проектирования электроники, алгоритм Ли применяли в игровых программах для нахождения кратчайшего пути в лабиринте.
Алгоритм Ли представляет блоки, которые нужно соединить, в виде фигур на ограниченной плоскости, размеченной «в клеточку». Чтобы найти кратчайший путь от вывода одного блока к выводу другого блока, алгоритм Ли использует два прохода:
- Первый проход называется «распостранение волн». Помечаем все «клеточки» или ячейка у первого вывода единицей. После этого для каждой ячейки, помеченной числом N, помечаем все соседние свободные непомеченные ячейки числом N + 1. Повторяем разметку до тех пор, пока мы либо не дойдем к выводу второго блока, либо больше не будет возможности распостранять «волну».
- Второй проход называется «восстановление пути». Если ячейка у второго блока помечена, выберем среди ее соседей ячейку, которая помечена на 1 меньше, чем число в текущей ячейке. Добавляем соседнюю ячейку в путь, переходим в нее и начинаем смотреть на ее соседей, которые помечены еще на 1 меньше. Повторям это, пока мы не прийдем к выводу первого блока.
Сначала алгоритм Ли применяли в программах для проектирования печатных плат, потом его стали использовать и для проектирования микросхем. Однако когда размер микросхем вырос, применять алгоритм Ли в его первоначальном виде стало невозможно, так как он требует большого количества памяти для хранения массива данных, а также большого количества времени для многочисленных проходов через этот массив. Несмотря на то, что современные программы автоматической трассировки используют другие алгоритмы, алгоритм Ли остается отличным упражнением для тех, кто недавно освоил программирование и хочет написать небольшую программу трассировки сам.

Для более серьезных алгоритмов вы можете поискать идеи в материалах Игоря Маркова. Но круче всего было бы проявить творчество — вдруг вы придумаете что-нибудь, что не придумали тысячи математически-подкованных алгоритмистов-программистов, которые каждое утро стоят в пробках на 101-м, 880-м и 237-м фривеям в офисы Synopsys и Cadence в городах Сан-Хосе, Саннивейл и Маунтин-Вью, Калифорния.
Список литературы (от простого к сложному):
- Вводные лекции по основам цифрового проектирования в Иннополисе: 1, 2.
- Вводный курс в цифровую электронику и EDA для продвинутых школьников олимпиадного типа. От РОСНАНО: 1, 2, 3.
- Учебник Харрис & Харрис.
- Слайды лекций Чарльза Данчека.
- Курс Игоря Маркова из университета Мичигана. Этот курс он прочитал в МГУ.
Выражаю надежду, что почин Иннополиса по алгоритмическим соревнованиям расширится. Область EDA математически интересна и хорошо оплачивается. Synopsys открыл отделение в Армении и превратился там в одного из ведущих работодателей: «Today, Synopsys is one of the largest IT employers in Armenia with more than 650 employees (including more than 600 engineers).» Замечу, что Россия крупнее Армении и наверное может создать свой Synopsys. В конце-концов, программистов в России много, математиков тоже, а текущая рыночная капитализация Synopsys + Cadence примерно равна затратам на сочинскую олимпиаду.
