Улучшаем Кузнечик на Rust

Начало
Порой, простое и красивое решение лучше правильного и выдержанного. Возможно, именно так бы и было, если в жизни всё происходило как в учебниках. На практике же, нужно пройти долгий путь, чтобы создать задуманное.
Отступая от лирики, в данной статье я хочу рассказать заинтересованному читателю про шифрование по ГОСТ, а именно — алгоритм «Кузнечик», и про то, что стоит обратить внимание на новые и перспективные средства — язык Rust.
Хватит отступлений, предлагаю начать!
Что будет в данной статье
В данной статье я хочу рассказать вам о моей реализации алгоритма Кузнечик на языке Rust. О том почему я выбрал данный язык. И что получилось в итоге. К сожалению, материала получилось многовато, поэтому некоторые главы я оставил на потом.
Для тех, кто уже устал читать, даю ссылочку на код, возможно кому-то пригодится.
Rust или не Rust?

Rust или C++, Go или Rust, Rust или …, на эту тему существует уже довольно много статей, поэтому я ограничусь лишь парочкой слов. Rust сочетает в себе все современные и необходимые для разработки средства, включая многочисленные плюшки, которые нравятся разработчикам. Являясь при этом системным языком, Rust не обладает дополнительным оверхедом в виде сборщика мусора и выполняет максимум оптимизаций на этапе компиляции, а также позволяет писать нативный код для встраиваемых систем.
Я считаю, для данной задачи Rust удовлетворяет требованиям производительности и использования памяти, а также что, он более перспективный и удобный в использовании, чем тот же C++. Это лишь моё субъективное мнение и никого не прошу придерживаться его. К тому же, язык программирования это всего лишь инструмент со своими особенностями, преимуществами и недостатками. Если вы считаете, что это не так рад буду услышать вашу позицию по данному вопросу.
Реализация
Перед тем, как вдаваться в подробности кода было бы не плохо продемонстрировать «Hello World». Для начала подключим библиотеку kuznechik:
Cargo.toml:
[dependencies]
kuznechik = "0.2.0"Теперь зашифруем и расшифруем строку «Hello World!»:
main.rs:
fn hello_world() {
// Инициализация
let gamma = vec![0x12, 0x34, 0x56, 0x78, 0x90, 0xab, 0xce, 0xf0, 0xa1, 0xb2, 0xc3, 0xd4, 0xe5, 0xf0, 0x01, 0x12,
0x23, 0x34, 0x45, 0x56, 0x67, 0x78, 0x89, 0x90, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19];
let kuz = Kuznechik::new("Кузнечик на Rust").unwrap();
let mut alg = AlgOfb::new(&kuz);
alg.gamma = gamma.clone();
let data = String::from("Hello World!").into_bytes();
// Шифрование
let enc_data = alg.encrypt(data.clone());
println!("Encrypted data:\n{:?}", &enc_data);
// Расшифрование
alg.gamma = gamma;
let dec_data = alg.decrypt(enc_data);
println!(
"Decrypted data:\n{}",
String::from_utf8(dec_data.clone()).unwrap()
);
assert_eq!(dec_data, data);
}В коде, представленном выше для создания объекта Kuznechik используется пароль в виде строки. Функция Kuznechik: new () принимает строку и хеширует её по алгоритму Sha3–256 для получения мастер ключа. Также вы можете напрямую задать мастер ключ, для этого можно воспользоваться функцией Kuznechik: new_with_master_key (). Данная функция принимает массив длиной 256 бит (тип [u8; 32]).
Функции alg.encrypt () и alg.decrypt () принимают на вход и возвращают вектор байтов Vec
Обзор библиотеки
Архитектура
Архитектура библиотеки устроена так, что неизменяемые данные — ключи, хранятся в структуре Kuznechik, а изменяемые и присущи конкретному режиму шифрования данные в структурах, начинающихся с префикса Alg- (в данном примере — AlgOfb). Это касается и функционального кода. Всё это позволяет создать один экземпляр Kuznechik (единожды развернуть ключи) и использовать разные режимы.
Режимы шифрования
Алгоритм Кузнечик может работать в шести режимах (типы AlgEcb, AlgCtr, AlgOfb, AlgCbc, AlgCfb, AlgMac). В приведённом выше примере представлен режим гаммирования с обратной связью по выходу (OFB). В данном режиме для работы алгоритма требуется гамма, значение которой задаётся через переменную alg.gamma. Необходимо учесть, что данная переменная изменяется в процессе шифрования и для успешного расшифрования требуется установить начальное значение гаммы.
Базовый алгоритм
В этом разделе я покажу, как может выглядеть реализация на Rust. Более подробно вы можете посмотреть в исходниках на GitHub.
Базовый алгоритм шифрования выглядит намного проще чем его описание в стандарте:
pub fn encrypt_block(data: &mut Block128, keys: &[Block128; 10]) {
for i in 0..9 {
tfm_lsx(data, &keys[i]);
}
tfm_x(data, &keys[9]);
}Здесь производится девять итераций LSX-преобразования и затем ещё одну итерацию X-преобразования. Напомню длина блока 128 бит или 16 байт. Тип Block128 именно такого размера, элементы которого имеют тип u8.
Далее LSX-преобразование. Оно состоит из поочерёдного вызова X, S, и L преобразований.
fn tfm_lsx(data: &mut Block128, key: &Block128) {
tfm_x(data, key);
tfm_s(data);
tfm_l(data);
}В свою очередь X-преобразование делает сложение по модулю 2 (проще говоря — XOR) блока данных с ключом:
fn tfm_x(data: &mut Block128, key: &Block128) {
for i in 0..16 {
data[i] ^= key[i];
}
}В S-преобразовании в данные вносится нелинейность для чего к данным применяется подстановка π (пи).
fn tfm_s(data: &mut Block128) {
for i in 0..16 {
data[i] = K_PI[data[i] as usize];
}
}L-преобразование производит 16 раз R-преобразование на данными.
fn tfm_l(data: &mut Block128) {
for _ in 0..16 {
tfm_r(data);
}
}И наконец R-преобразование:
fn tfm_r(data: &mut Block128) {
let temp = trf_linear(data);
data.rotate_right(1);
data[0] = temp;
}Данное преобразование лучше всего показать на рисунке. F — линейное преобразование, которое соотносит 16 байтам однобайтовый результат, согласно выражению ниже.
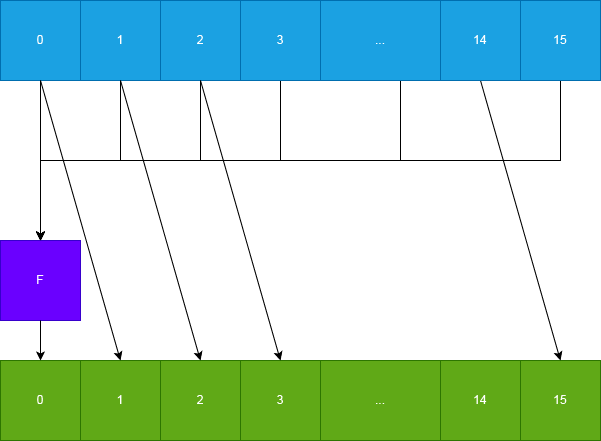
Линейное преобразование:
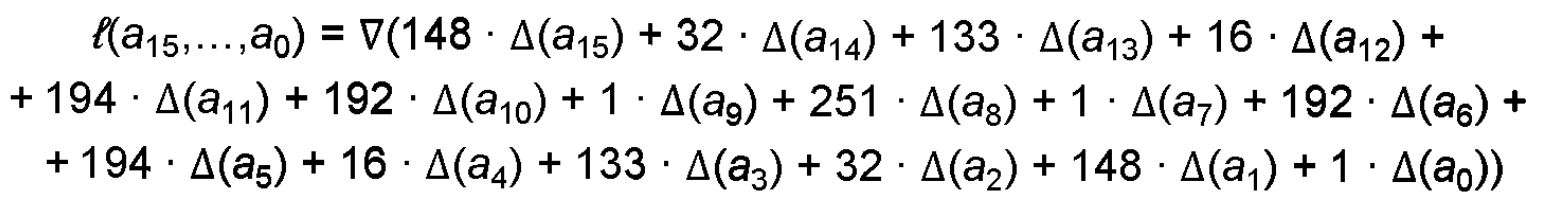
Чтобы не вычислять значение линейного преобразования на каждой итерации L — преобразования, можно вычислить, своего рода, таблицу умножения. Таблица содержит 7 строк и 256 столбцов, что соответствует произведениям в поле Галуа коэффициентов на значения входных данных (произведения входных данных на коэффициент равный 1 нет смысла держать в таблице, т.к. результат равен входным данным).
Вычисление линейного преобразования по такой таблице умножения занимает O (1) времени и требует O (1) памяти, а точнее 7×256 = 1792 байта, что не так много для современного компьютера.
Собственно реализация:
fn trf_linear(data: &Block128) -> u8 {
// indexes: 0, 1, 2, 3, 4, 5, 6
// values: 16, 32, 133, 148, 192, 194, 251
let mut res = 0u8;
res ^= MULT_TABLE[3][data[0] as usize];
res ^= MULT_TABLE[1][data[1] as usize];
res ^= MULT_TABLE[2][data[2] as usize];
res ^= MULT_TABLE[0][data[3] as usize];
res ^= MULT_TABLE[5][data[4] as usize];
res ^= MULT_TABLE[4][data[5] as usize];
res ^= data[6];
res ^= MULT_TABLE[6][data[7] as usize];
res ^= data[8];
res ^= MULT_TABLE[4][data[9] as usize];
res ^= MULT_TABLE[5][data[10] as usize];
res ^= MULT_TABLE[0][data[11] as usize];
res ^= MULT_TABLE[2][data[12] as usize];
res ^= MULT_TABLE[1][data[13] as usize];
res ^= MULT_TABLE[3][data[14] as usize];
res ^= data[15];
res
}Что касается сложения в линейном преобразовании, то это всего лишь XOR. Таблицу умножения вы можете посмотреть в исходниках.
На этом всё, показывать обратные преобразования и режимы работы здесь будет уже лишним, и так уже кода получилось многовато, если что вы знаете где искать. Да, благодарю вас если вы дочитали до этого момента, всё же статья уже затянулась.
Про велосипед
Многие, наверно спросят, зачем писать то, что уже написано. Можно же использовать готовое от дяди Васи. В ответ я перечислю основные причины, которые подтолкнули меня на создание такого проекта.
Лицензирование ПО.
Качество ПО (безопасность, производительность, требования к памяти и тд.).
Интерфейс взаимодействия.
Зависимости.
Ну и конечно же опыт, который получаешь в процессе разработки.
Продолжение следует…
Разместить все свои мысли в одной статье, на мой взгляд, было бы неправильно. Так можно быстро утомиться и потерять интерес к материалу. К тому же мне было бы приятно услышать ваше мнение и рассмотреть общие с вами темы.
На этом пока всё. Надеюсь, что данная статья поможет кому-нибудь в понимании алгоритма Кузнечик и языка Rust. Спасибо за внимание.
Отдельное спасибо Chris F за фотографии кузнечика.
