Укрощаем асинхронные процессы в Android с RxJava. Опыт Яндекса
Всем привет, меня зовут Алексей Агапитов и сегодня я хочу рассказать, как с
помощью такой библиотеки как RxJava можно легко обрабатывать множество
асинхронных процессов в вашем Android приложении.
Мы разберём, как создавать свои холодные и горячие последовательности, обратим
внимание на некоторые нюансы при использовании RxJava, а также рассмотрим
насколько мощными инструментами являются предоставляемые данной библиотекой
операторы.
Рассказывать обо всём я буду на примере приложения Яндекс.Недвижимость и его
главного экрана с картой.
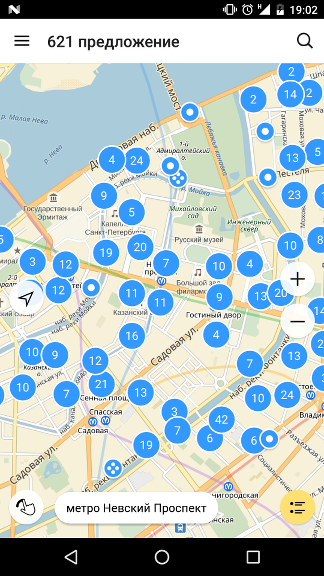
Для начала посмотрим на экран и разберёмся, что на нём происходит и что нам
предстоит реализовать.

Прежде всего возникает взаимодействие с картой: человек может двигать карту
и на ней будут появляться точки с объявлениями, подходящими под его фильтры.
Точки могут быть единичными объявлениями, новостройками, домами и кластерами,
объединяющими множество объявлений. Заметим, что единичные объявления могут быть
помечены как просмотренные (этот флаг хранится локально на устройстве).
Сами фильтры меняются на другом экране, но их необходимо использовать при запросе
интересующих нас точек на карте.
Ещё одна составляющая запроса это географический объект, для которого мы ищем
объявления.

Данный элемент необходим, чтобы быстро включать/выключать
поиск в этом объекте или в той области, которая сейчас открыта на карте.
Таким образом, точки на карте необходимо обновлять по каждому из перечисленных
действий (изменение карты, фильтров или геообъекта). Для краткости мы не будем
рассматривать возможность рисования объектов на карте, считаем что такие объекты
являются частным случаем геообъекта.
Помимо этого, у нас есть два процесса, происходящих в других потоках: получение
точек от веб-API и проверка, какие из этих точек уже были просмотрены на данном
устройстве (для этого мы обращаемся к базе данных).
Учитывая, что карта, фильтры и геообъект меняются быстрее и чаще,
чем приходят ответы с точками от сервера, то необходимо использовать только
самые свежие результаты и отбрасывать предыдущие.
Таким образом, нам необходимо реализовать экран, содержащий немалое количество
асинхронных процессов, зависящих друг от друга.
Сравнение RxJava с традиционным Android подходом
В традиционном для Android подходе, для наблюдения за каждым из рассмотренных
процессов мы бы использовали коллбэки. Когда происходит событие изменения
составляющих элементов на карте (например, карту подвинули), мы читаем остальные
составляющие и соединяем их в один запрос, который и выполняем.
При реализации данного подхода возникают некоторые сложности.
- Коллбэки плохо комбинируются друг с другом:
- сложнее читать код — сложнее понять связи коллбэков друг с другом, определить,
кто от кого зависит, коллбэки разнесены по коду и в нём сложнее ориентироваться; - теряется гибкость кода — имеется меньше возможностей для его
переиспользования, сложнее вносить изменения в существующие решения.
- сложнее читать код — сложнее понять связи коллбэков друг с другом, определить,
- Необходимо явно хранить дополнительное состояние, связанное с выполняемой
асинхронной операцией и её коллбэком. Чем больше таких переменных состояния,
тем больше вероятность допустить ошибку (например, при работе с несколькими потоками).
Мы выбрали библиотеку RxJava по следующим причинам:
- Наличие универсальной абстракции над асинхронными процессами любой природы
(событийная модель, многопоточная обработка) под названием Observable –
наблюдаемая последовательность; - Возможность изменять последовательности за счёт применения операторов и
большое количество полезных операторов; - Возможность комбинировать последовательности друг с другом;
- Уменьшение количества переменных состояния за счёт использования
последовательностей и операторов; - Стабильность и качество реализации библиотеки;
Эту библиотеку мы используем в приложении для самых разных целей — начиная с
фоновой загрузки и обработки данных и заканчивая обработкой множества
событий, происходящих в пользовательском интерфейсе.
Реализация
Посмотрим на примерах, как используется библиотека в нашем приложении.
Наблюдаем за изменениями карты
Сначала возьмём наблюдение за изменением состояния карты.
Для этого мы используем следующую последовательность, которая сообщает о том,
что координатные границы карты изменились:
public static Observable observeMapBoundingBox(final MapController mapController) {
return Observable.create(new Observable.OnSubscribe() {
@Override
public void call(final Subscriber subscriber) {
final OnMapListener listener = new OnMapListener() {
@Override
public void onMapActionEvent(MapEvent mapEvent) {
switch (mapEvent.getMsg()) {
case MapEvent.MSG_SCALE_END:
case MapEvent.MSG_SCROLL_END:
case MapEvent.MSG_ZOOM_END:
if (!subscriber.isUnsubscribed()) {
subscriber.onNext(getViewportBoundingBox(mapController));
}
break;
}
}
};
mapController.addMapListener(listener);
//если от последовательности отписались - удалить этого слушателя
subscriber.add(Subscriptions.create(() -> {
mapController.removeMapListener(listener);
}));
}
});
} В данной реализации две основные части:
- создание и добавление слушателя событий карты
- удаление данного слушателя, когда от последовательности отписались.
Обратите внимание, что мы создаём и регистрируем слушателя внутри OnSubscribe,
то есть когда последовательность стала активна (на неё кто-то подписался).
Здесь мы имеем дело с классическим примером холодной последовательности — такой,
которая выпускает новые элементы, пока на неё подписаны.
Отличным примером реализации подобных последовательностей является
библиотека RxBinding, позволяющая наблюдать за событиями в виджетах,
присутствующих в стандартном API, а также support-библиотеке.
Наблюдаем за изменением фильтров
Теперь рассмотрим вторую составляющую запроса на точки — фильтры.
Предположим, у нас есть класс, который хранит в себе текущие фильтры
и предоставляет методы, для их обновления. И мы хотим наблюдать за изменением
значения этого поля. Мы можем пойти тем же путём, что и в случае карты, добавив
поле с наблюдателем изменений этого поля и уведомлением наблюдателя, когда
поле изменилось. Но, наблюдателей у поля может быть много, а значит, либо надо
хранить их массив, либо при создании последовательности использовать
операторы share, publish + autoConnect
для того, чтобы отправлять событие сразу нескольким наблюдателям последовательности.
Однако хочется сделать это прозрачно для потребителя, и здесь нам поможет такой
класс из библиотеки RxJava, как Subject, на который мы переложим все перечисленные
обязанности.
Subject представляет собой последовательность, у которой одновременно
может быть множество подписчиков, которые получают все данные и уведомления
о её завершении или ошибке. При этом, работа с Subject происходит с помощью
тех же методов, которыми обладают его подписчики: onNext, onCompleted, onError.
То есть, Subject сам является подписчиком, а значит при необходимости он может
подписаться на другую последовательность и ретранслировать её всем своим
подписчикам.
Посмотрим на примере, что это нам даёт:
public class FilterHolder {
private final PublishSubject subject = PublishSubject.create();
private Filter current;
public Observable observeChanges(boolean emitCurrentValue) {
return emitCurrentValue ? subject.startWith(current) : subject;
}
public void set(Filter filter) {
this.current = filter;
subject.onNext(filter);
}
} Как видите, при установке нового значения мы отправляем его всем подписчикам.
В данном случае мы используем PublishSubject, который отправляет
свежеполученные данные, всем своим подписчикам. В принципе, можно было бы
использовать ReplaySubject, который умеет хранить последние полученные
данные и повторять их для тех подписчиков, которые подписались уже после
получения этих данных. Но в таком случае нам пришлось бы поменять реализацию методаobserveChanges — вместо отправки текущего значения, мы бы его пропускали.
Подобным образом можно расширить уже существующие классы и добавить им
реактивные возможности.
Subject является примером горячей последовательности, то есть он
остаётся активным и будет принимать/отправлять элементы, даже
если на него никто не подписан.
Главное — помнить, что Subject может принимать новые элементы
последовательности в onNext и рассылать их своим подписчикам до тех пор,
пока у него не будет вызван onCompleted или onError.
Это важно, в тех ситуациях когда источник данных/событий бесконечный и не
предполагается вызовов onCompleted и onError, поэтому вызов этих методов
у Subject, рассылающего эти данные своим подписчикам, может привести к неожиданным
эффектам.
Наблюдение за третьей составляющей запроса к API на точки — геообъектом аналогично
фильтрам и реализуется с помощью Subject.
Наконец, надо собрать эти три элемента вместе и отправить их в сетевом запросе.
Обращение к API
Для обращения к API мы используем известную библиотеку Retrofit, а все
результаты сетевых вызовов представляются в виде Observable.
В итоге метод в сетевом слое будет выглядеть следующим образом:
public Observable getClusters(MapBoundingBox box, Filter filter, GeoObject geo) {
//обращаемся к адаптеру API
} Объединяем всё вместе
Вот так, мы объединяем все перечисленные асинхронные процессы:
Observable.combineLatest(
observeMapBoundingBox(mapController).debounce(300L, TimeUnit.MILLISECONDS, AndroidSchedulers.mainThread()),
filterHolder.observeChanges(true),
observeGeoObject(true),
SearchRequest::clusters//собрать все составляющие в промежуточный объект
)
.switchMap(request -> networkHelper
.getClusters(request.boundingBox, request.filter, request.geoObject)
.observeOn(AndroidSchedulers.mainThread())
.doOnError(handleErrorAction())//обрабатываем ошибку
.onErrorResumeNext(Observable.empty())//подавляем ошибку
)
.observeOn(Schedulers.computation())
//смотрим в БД, какие точки отметить как просмотренные
.map(this::processViewedClusters)
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Observer() {
@Override
public void onCompleted() {
}
@Override
public void onError(Throwable e) {
//в нормальной ситуации ошибок не происходит, поэтому просто логируем
}
@Override
public void onNext(ClustersData clustersData) {
//показываем точки на карте
}
}); Мы используем оператор combineLatest чтобы следить за изменением
каждого из трёх значений, и при изменении одного из них создаём объект описывающий
сетевой запрос.
Данный оператор работает следующим образом: он ждёт, пока каждая
из переданных ему последовательностей предоставит по одному элементу и вызывает
функцию, которая преобразует все эти элементы в какой-то другой объект.
Далее при каждом появлении нового элемента в любой из последовательностей
оператор снова вызывает эту функцию передавая ей это новое значение и
последние значения остальных.

Таким образом, он очень похож, на zip, с той лишь разницей, что использует
последние известные значения элементов, если последовательности не предоставили
новые. Это удобно когда сочетаешь последовательности, выпускающие элементы с
разной частотой, например изменение состояния карты, которое случается чаще,
чем фильтры.
После того как объект сетевого запроса построен, мы переходим непосредственно
к запросу. Для этого мы обращаемся к объекту, отвечающему за взаимодействие с
API, и передаём ему собранные нами параметры.
Здесь есть два интересных момента.
Но сначала рассмотрим оператор flatMap, который для каждого элемента
исходной последовательности возвращает новую последовательность, а потом
объединяет их все в одну результирующую последовательность.

Оператор switchMap работает так же, с той лишь разницей, что он
отписывается от последовательности, полученной от предыдущего элемента,
переключается на новую и ждёт результатов от неё.
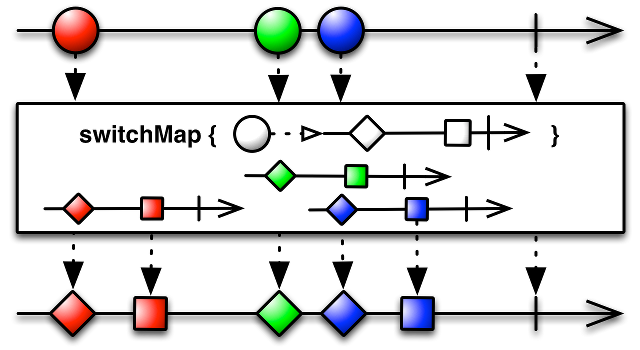
Это необходимо потому, что сетевые запросы выполняются медленно, так что если,
например, человек передвинул карту, то предыдущий запрос теряет актуальность
и мы должны запросить новые точки.
Вторым моментом является подавление сетевых ошибок при помощи операторовdoOnError и onErrorResumeNext (с помощью которого
мы возвращаем пустую последовательность).
Это делается для того, чтобы последовательность
карта / фильтры / геообъект → сетевой запрос → точки на карте не разрывалась,
если один из запросов завершился (сетевой) ошибкой — ведь, в таком случае
новые изменения карты не дадут никакого результата, а сетевые ошибки
вполне могут происходить, и нам их надо обрабатывать.
Следующим шагом после получения точек на карте является определение тех из них,
которые пользователь уже просматривал. Для этого делается запрос к базе данных,
после которого у всех просмотренных точек проставляется соответствующий флаг.
Поскольку это долгая операция, мы освобождаем сетевой планировщик и переключаем
вычисления на computation: observeOn(Schedulers.computation()).
Для запроса к базе данных мы используем Cupboard и свои Rx обёртки
поверх него, но в данном случае мы обошлись обычным синхронным методом, хотя
можно было использовать метод, возвращающий Observable.
Вы, наверное, уже заметили, что в последовательности наблюдения за изменением
положения карты появился оператор debounce, который позволяет отбросить
лишние элементы, если они все пришли в указанный интервал времени. Это нужно,
чтобы не делать слишком часто запросы на сервер, пока пользователь рассматривает
карту. По умолчанию этот оператор использует computation-планировщик, но,
поскольку мы знаем, что наши события происходят в главном потоке, то можно
переопределить его на планировщик для главного потока.
Это позволяет избежать ненужного в данном месте переключения потоков, а также
избавляет computation-планировщик от лишних задач (так как количество потоков
в нём по умолчанию ограничено количеством ядер).
А теперь подведём итоги.
Небольшое количество кода.
Вся логика уместилась в одну последовательность,
по которой понятно движение данных и логика их обработки.
Субъективно такой код кажется проще, чем если бы мы использовали коллбэки.
Но тут надо оговориться, что для этого необходимо как минимум знание основ RxJava.
Более простая реализация
Всю работу по синхронизации и хранению промежуточного состояния асинхронных
операций мы переложили на плечи библиотеки. Как следствие, мы храним
минимум промежуточного состояния. Это снижает вероятность ошибок при работе с
несколькими потоками и асинхронными процессами.
Кроме того, вместо того чтобы реализовывать обработку множества
асинхронных процессов, мы оперируем потоками данных и реализуем непосредственно
наши бизнес-задачи. При этом в нашу последовательность легко добавлять новые шаги
обработки и менять существующие.
Ещё хочется упомянуть, что код с последовательностями проще тестировать, потому что
последовательность можно заменить на ту, которая необходима для тестирования
(в случае с коллбэками это будет сложнее).
Например, можно заменить все последовательности, связанные с интерфейсом, на
предустановленные значения, используя оператор just.
