Учимся жить с Kafka без Zookeeper

При всех достоинствах Kafka как распределенного хранилища потока сообщений, боль вызывало раздельное хранение метаданных (топологии разделов, конфигурации кластера и прочего) и необходимость запуска в кластере рядом с Kafka еще и Apache Zookeeper. Побочным эффектом такого соседства (кроме дополнительных забот об администрировании и мониторинге) является долгое время восстановления после сбоя при больших размерах кластера, значительном количестве разделов или сложной топологии групп. Но ситуация улучшается и отличная новость появилась полторы недели назад в KIP-833, что в ближайшей версии Kafka 3.3 новый протокол согласования метаданных (KRaft), работающий внутри Kafka без Zookeeper, будет признан Production-Ready и далее постепенно зависимость от Zookeeper будет помечена как deprecated и удалена. В этой статье мы поговорим об особенностях протокола KRaft и разберемся как настроить новый кластер Kafka без необходимости установки Zookeeper.
Чтобы понять, зачем Kafka дополнительное нужно распределенное хранилище и как в целом работает распределенная очередь? Основной структурой хранения сообщений является тема (topic), который может рассматриваться как бесконечная лента с единственной функцией добавления элемента в начало (с возможностью удаления старых сообщений по количеству или по времени). Для отказоустойчивости темы представляются в виде набора разделов (partition), которые реплицируются между узлами кластера. Для раздела выбирается лидер, который обрабатывает входящие сообщения и рассылает по другим репликам (follower). Получатели (consumer) могут объединяться в группы (consumer groups) могут читать сообщения из разных реплик по собственному курсору для распределения нагрузки. Как можно видеть, Kafka содержит большое количество информации о топологии сети (consumer groups, partition replicas, current leader) и о конфигурации системы (включая права доступа) и доступ к ней должен быть обеспечен для всех узлов кластера, поэтому и появилась необходимость в использовании дополнительного распределенного хранилища конфигурации и для этого был выбран Apache Zookeeper.
Zookeeper (как и etcd, consul) является отказоустойчивым хранилищем конфигурации, которое может интерпретироваться как иерархическая key-value база данных, которая реплицируется по N узлам и использует собственный протокол ZAB (Zookeeper Atomic Broadcast) для синхронизации реплик. Кластер Zookeeper называется ансамбль (ensemble), каждый узел должен иметь уникальный ZOO_MY_ID и обладать информацией о топологии кластера в переменной окружения ZOO_SERVERS (при использовании официального docker-образа). Zookeeper также выбирает лидер среди узлов, при этом клиент может подключаться к любому узлу для чтения или записи (при этом операции чтения могут вернуть несогласованные данные, но операции записи размещаются в очередь и обрабатываются последовательно в порядке поступления).
Узлы Kafka при запуске должны иметь доступ к любому серверу кластера Zookeeper для выполнения саморегистрации и получения загрузочной информации о топологии кластера и здесь есть один нетривиальный момент при запуске через Docker Compose/Swarm или Kubernetes регистрируется указанным названием хоста (в KAFKA_ADVERTISED_LISTENERS) и дальше это же название будет возвращаться при получении конфигурации через Zookeeper (и как следствие, имя должно быть доступно клиенту). Здесь можно либо использовать полное доменное имя, либо запускать клиента в той же docker-сети или привязывать через hosts или --add-host связь анонсированного имени и адреса публикации.
Кластер Zookeeper сохраняет ссылку на выбранный им узел-контроллер Kafka, который копирует всю информацию о топологии узлов, разделов, топиков и групп получателей и управляет процессом репликации по другим узлам (брокерам). Брокеры и клиенты также могли обращаться к Zookeeper для обновления расположения реплик, в результате возникала необходимость периодического обновления конфигурации контроллера. При потере соединения с контроллером или холодного перезапуска кластера новый контроллер должен быть забрать необходимую информацию из Zookeeper (которому тоже нужно время на загрузку и переход в согласованное состояние), а это могло быть весьма длительным процессом.
Некоторое время клиенты подключались к Kafka через Zookeeper (по умолчанию к порту 2181), откуда получают информацию об узлах и топологии топиков, разделов и групп получателей и дальше уже взаимодействует с соответствующими репликами (исходя из идентификатора группы и расположения). Постепенно и клиенты и консольные утилиты стали использовать информацию о топологии кластера Kafka исходя из списка bootstrap_servers (обычно перечисляются все или несколько опубликованных узлов для отказоустойчивости), который в свою очередь получает необходимые метаданные из контроллера кластера Kafka. И возникает разумный вопрос — зачем использовать дополнительное хранилище метаданных, когда сама Kafka поддерживает репликацию и может содержать и распространять по своим узлам конфигацию. Разработчики думали также и так появился KRaft.
Сходство название с протоколом консенсуса Raft не случайно. Для хранения конфигурации KRaft вводит понятие контроллера кворума (Quorum Controller), которые синхронизируются между собой. Успешным считается обновление конфигурации, которое распространилось на (n+1)/2 узлов и любой из этих узлов может стать источником подтвержденной конфигурации для остального кластера. Среди кворума выбирается лидер, который координируют обновление конфигурации на других серверах, при этом каждое обновление становится новым событием в логе. Основное преимущество в том, что при потере соединения с лидером, новый лидер выбирается большинством из узлов, которые уже содержат полный лог с метаданными, и кластер восстанавливает свою работу за очень короткое время (т.к. не требуется выполнять достаточно медленные операции по взаимодействию с внешним хранилищем на Zookeeper, особенно при большом количестве топиков/разделов). Принципиальное отличие от протокола Raft состоит в том, что KRaft использует pull-модель между контроллерами.
Нужно отметить, что не все узлы Kafka автоматически становятся контроллерами и администратор самостоятельно маркирует их соответствующей ролью (один из них выбирается как leader, остальные входящих в кворум становятся voters, а не входящие в кворум — observers). Остальные узлы продолжают выполнять функции брокера и не участвуют в хранении метаданных.
Давайте перейдем к настройке кластера из 5 узлов (3 будут в роли контроллера, 2 останутся брокерами) и создадим также producer и consumer процессы, которые будут взаимодействовать с топиком events. Но сначала посмотрим на методы конфигурирования и обнаружения узлов Kafka. При добавлении нового узла ему необходимо получить информацию о текущем состоянии кластера (в частности, получить адрес контроллера) и при необходимости выполнить синхронизацию разделов с другими узлами. В случае с использованием Zookeeper решение было очевидное — конфигурацию зарегистрированных Kafka Advertised Listeners можно получить из него, но как быть с подключением узла к кластеру без Zookeeper? И как указать новому узлу, что необходимо использовать протокол KRaft для получения метаданных кластера?
При запуске узла из docker-контейнера нам доступно два способа конфигурирования — монтирование файла конфигурации (server.properties, расположение зависит от выбранного контейнера, например для bitnami/kafka в /opt/bitnami/kafka/config, в ubuntu/kafka расположение /etc/kafka), либо определение параметров через переменные окружения (для bitnami/kafka) с префиксом KAFKA_CFG (транслируется в одноименный ключ с заменой _ на ., например KAFKA_CFG_MAX_REQUEST_SIZE определит параметр конфигурации max.request.size). Обязательно должен быть указан уникальный идентификатор брокера KAFKA_CFG_BROKER_ID (целое число). Для подключения клиентов без использования шифрования необходимо указать ALLOW_PLAINTEXT_LISTENER=yes и KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://0.0.0.0:9092. При использовании Zookeeper должен быть указан аргумент KAFKA_CFG_ZOOKEEPER_CONNECT с адресом и портом любого сервера zookeeper (можно использовать Kubernetes Service для балансировки нагрузки).
Для использования Kafka без Zookeeper нужно определить следующие переменные окружения:
KAFKA_ENABLE_KRAFT=yes— разрешить использование протокола KRaft;KAFKA_CFG_CONTROLLER_LISTENER_NAMES— определение типа слушателя для публикации контроллера (используется ниже вKAFKA_CFG_LISTENERS и KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP);KAFKA_CFG_PROCESS_ROLE=broker,controller— узел может входить в кворум как контроллер, но также (как брокер) обеспечивает хранение разделов и добавление новых сообщений в разделы;KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093— кроме прослушивания порта для подключения клиентов (и взаимодействия узлов Kafka) также публикуется порт контроллера;KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT— разрешаем доступ без шифрования и авторизации для клиентов и для взаимодействия контроллеров;KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@127.0.0.1:9093— обозначаем идентификатор контроллера (как части кворума) и его адрес и порт (здесь нужно перечислить адреса всех известных контроллеров);KAFKA_KRAFT_CLUSTER_ID=somevalue— идентификатор кластера (должен быть одинаковым у всех контроллеров и брокеров), его мы получим после первого запуска.
Начнем с запуска одного узла и будем последовательно масштабировать кластер. Для управления контейнерами будем использовать Docker Compose. Создадим файл для запуска первого узла:
version: "3.9"
volumes:
volume1:
services:
kafka1:
image: 'bitnami/kafka:latest'
ports:
- "9092:9092"
environment:
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092
- KAFKA_BROKER_ID=1
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093
- ALLOW_PLAINTEXT_LISTENER=yes
volumes:
- volume1:/bitnami/kafkaЗдесь важно отметить, какой адрес указан в ADVERTISED_LISTENERS — Kafka регистрируется как localhost и ожидает, что этот адрес будет использоваться и для подключения клиентов. Более правильно здесь было бы использовать имя контейнера kafka1, но тогда клиенты должны либо быть запущены в этой же сети, либо обращаться через имя хоста и разрешать имя через hosts или --add-host в контейнере.
Сначала сгенерируем идентификатор кластера:
docker compose exec kafka1 kafka-storage.sh random-uuidИ добавим полученный идентификатор в переменную окружения KAFKA_KRAFT_CLUSTER_ID в docker-compose.yaml
- KAFKA_KRAFT_CLUSTER_ID=L0ZEQh1yTbGhNNUE7-6wSQИ проверим возможность подключения к серверу, для этого создадим контейнер с образом provectuslabs/kafka-ui, добавим его к docker-compose.yaml и изменим ADVERTISED_LISTENERS на внутреннее имя контейнера:
version: "3.9"
volumes:
volume1:
services:
kafka1:
image: 'bitnami/kafka:latest'
environment:
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka1:9092
- KAFKA_CFG_BROKER_ID=1
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_KRAFT_CLUSTER_ID=L0ZEQh1yTbGhNNUE7-6wSQ
volumes:
- volume1:/bitnami/kafka
ui:
image: provectuslabs/kafka-ui:v0.4.0
ports:
- "8080:8080"
environment:
- KAFKA_CLUSTERS_0_BOOTSTRAP_SERVERS=kafka1:9092
- KAFKA_CLUSTERS_0_NAME=kraftПосле этого в браузере по адресу http://localhost:8080 мы сможем увидеть веб-интерфейс для управления Kafka.
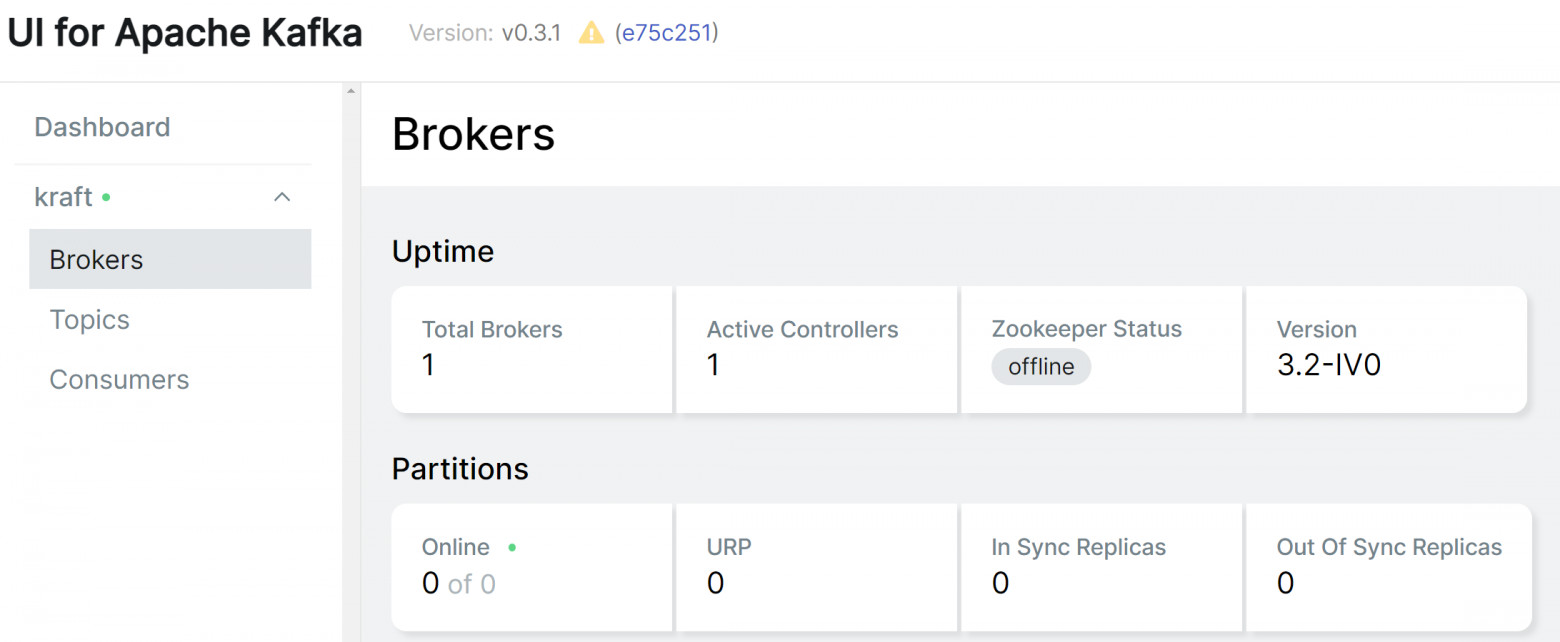 Состояние кластера с одним контроллером после запуска
Состояние кластера с одним контроллером после запуска
Обратите внимание, что сейчас в кластере представлен один узел, который является одновременно и брокером и контроллером, при этом Zookeeper не используется.
Для тестирования создадим один Topic из 3 разделов. Фактор репликации и min-in-sync-replicas (необходимое и достаточное количество подтвержденных реплик сообщения, чтобы считать его успешно обработанным) оставим пока 1, поскольку в кластере еще нет узлов (заменим позднее). Time to retain определим в 86400000 мс (одни сутки), остальные ограничения могут быть заданы при необходимости (общий размер сообщений на диске, максимальный размер одного сообщения:
 Создание топика
Создание топика
И отправим в него сообщение для проверки:
 Отправка сообщения в Partition 0
Отправка сообщения в Partition 0
На текущий момент у нас в брокере содержится один topic и одно сообщение:
 Текущее состояние кластера
Текущее состояние кластера
Давайте перейдем к добавлению новых брокеров и контроллеров. Узлы мы будем добавлять в ту же сеть (через docker-compose.yaml и создадим 3 узла с ролями controller, broker. Для указания voters нам нужно будет перечислить все существующие контроллеры. Три узла будут иметь сходную конфигурацию, различия будут только в названии контейнера, идентификаторе брокера и используемого volume для хранения данных. Для первого контроллера конфигурация может выглядеть следующим образом:
kafka1:
image: 'bitnami/kafka:latest'
environment:
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka1:9092
- KAFKA_CFG_BROKER_ID=1
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_KRAFT_CLUSTER_ID=L0ZEQh1yTbGhNNUE7-6wSQ
volumes:
- volume1:/bitnami/kafkaПосле перезапуска мы увидим, что теперь в кластере зарегистрировано 3 узла. Изменим в http://localhost:8080/ui/clusters/kraft/topics/events/edit количество реплик на 3 для проверки корректности работы кластера в целом.
Проверим метаданные кластера, для этого будем использовать инструмент kafka-metadata-shell.sh, которой передается файл с информацией внутреннего commit log для кластера.
docker compose exec kafka1 kafka-metadata-shell.sh \
--snapshot /bitnami/kafka/data/__cluster_metadata-0/00000000000000000000.logMetadata Shell представляет интерфейс, похожий на командную строку GNU/Linux для работы с файловой системой:
cat— просмотр содержания ключа иерархической структуры метаданных;ls— перечисление подузлов текущего узла;cd— изменение текущего узла (перемещение по дереву);find— поиск узлов по заданным критериям;pwd— отображение текущего пути;exit— выход из оболочки.
В узле /brokers лежат подузлы для описания брокеров (например, cat /brokers/1/registration выведен информацию о состоянии подключения и расположении брокера с идентификатором 1). cat /metadataQuorum/leader отобразит информацию о текущем выбранном лидере и эпохе (эпоха увеличивается при перевыборах), например LeaderAndEpoch(leaderId=OptionalInt[3], epoch=2).
Также в метаданных представлены данных о топиках и разделах (например, для просмотра статуса раздела 0 для topic events, можно просмотреть узел cat /topics/events/0/data) и они связываются с идентификаторами топиков, перечисленных в /topicIds и также продублирован в /topics/ (например, /topics/events/name). Для проверки корректности репликации между контроллерами можно запросить метаданные с разных узлов и убедиться, что отображается одинаковая структура и содержание узлов для всех контроллеров.
Начиная с версии Kafka 3.2 в протоколе KRaft поддерживается также контроль доступа (ACL), раньше для этого требовалось возвращаться на Zookeeper. Для управления правами доступа через консоль можно использовать инструмент kafka-acls.sh и позволяет добавлять разрешенные и запрещенные хосты (--allow-host / --deny-host), разрешать и запрещать доступы для авторизованных пользователей (--allow-principal principalType:name / --deny-principal principalType:name, например User:logger). При вызове обязательно указать стартовый сервер для подключения к Kafka (--bootstrap-server), также можно уточнить consumer group, к которым применяется правило (--group ), topic к которому применяется разрешение (--topic ). При описании прав можно перечислять как индивидуальные разрешения (--operation , например --operation Write), так и группы прав (--producer — необходимые права для отправки сообщений, --consumer — права для чтения сообщений). Например, для добавления прав на отправку в топик events для авторизованного пользователя logger можно использовать следующую команду (запускаем внутри контейнера, поэтому обращаемся к серверу как localhost).
$ kafka-acls.sh --bootstrap-server localhost:9092 --add --topic events --producer --allow-principal User:loggerДля поддержки авторизации по пользователям нужно сгенерировать сертификаты и использовать их при подключении через SSL/TLS (также должно быть быть разрешено в KAFKA_CFG_LISTENER_SECURITY_PROTOCOL), имя пользователя определяется по сертификату. Более подробно описание алгоритма создания и использования сертификатов можно посмотреть в этой статье.
При необходимости отключить брокер от кластера (и выполнить ребалансировку реплик разделов) нужно использовать kafka-cluster.sh:
$ kafka-cluster.sh --bootstrap-server localhost:9092Kafka поддерживает множество утилит командной строки для перераспределение разделов по брокерам (kafka-reassign-partitions.sh), управления топикам (kafka-topics.sh), динамического изменения конфигурации (kafka-configs.sh), управления группами получателей (kafka-consumer-groups.sh), перевыборов лидера (kafka-leader-election.sh). Для отладки мы будем использовать kafka-dump-log.sh, который может выгружать как содержание topic, так и декодировать метаданные самого кластера. Просмотрим информацию об истории модификации метаданных:
$ kafka-dump-log.sh --cluster-metadata-decoder --files /bitnami/kafka/data/__cluster_metadata-0/00000000000000000000.logНапример, так можно увидеть события регистрации брокеров:
| offset: 1 CreateTime: 1654697207725 keySize: -1 valueSize: 58 sequence: -1
headerKeys: [] payload: {"type":"REGISTER_BROKER_RECORD","version":0,
"data":{"brokerId":3,"incarnationId":"r8KWwW_2R46jZVoxIqj-dQ","brokerEpoch":0,
"endPoints":[{"name":"PLAINTEXT","host":"kafka3","port":9092,"securityProtocol":0}],
"features":[],"rack":null,"fenced":true}}Или можно получить содержание сообщений из топика:
$ kafka-dump-log.sh --files /bitnami/kafka/data/events-0/00000000000000000000.log --print-data-log
Dumping /bitnami/kafka/data/events-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1654700985929 size: 103 magic: 2 compresscodec: none crc: 819204779 isvalid: true
| offset: 0 CreateTime: 1654700985929 keySize: 11 valueSize: 24 sequence: -1 headerKeys: [] key: "ad dolore" payload: "est ullamco mollit non"Команды просмотра содержания топиков и метаданных (на чтение) может быть выполнена на любом брокере. Bootstrap-сервером может указан любой брокер (или несколько брокеров через запятую).
Попробуем теперь повзаимодействовать с нашим кластером. Будем использовать kafka-console-producer.sh для этого подключимся к первому брокеру и отправим сообщение:
docker compose exec kafka1 bash
$ echo "Hello, World!" | kafka-console-producer.sh --topic events --bootstrap-server localhost:9092Теперь проверим, что сообщение доставлено (подключимся к другому брокеру):
docker compose exec kafka5 bash
kafka-console-consumer.sh --topic events --bootstrap-server localhost:9092 --from-beginningДля внешнего доступа важно иметь возможность разрешения анонсированных адресов (или доменных имен) в KAFKA_CFG_ADVERTISED_LISTENERS и можно использовать подходящую библиотеку для выбранной технологии разработки из этого списка.
В завершении попробуем смоделировать возникновение проблемы, когда текущий лидер среди контроллеров будет остановлен. Ранее мы обнаружили, что лидером был выбран узел с идентификатором 3 на второй эпохе (leaderId=OptionalInt[3], epoch=2), остановим его:
docker compose stop kafka3И проверим доступность данных:
docker compose exec kafka5 bash
$ kafka-console-consumer.sh --topic events --bootstrap-server localhost:9092 --from-beginningПоскольку для topic был установлен replicationFactor = 3, каждое сообщение в разделе было распространено по 3 серверам и отключение одного из них не приводит к потере доступа и будет отображен список отправленных в topic events сообщений (с запуска кластера). Посмотрим теперь какой контроллер стал лидером кластера:
docker compose exec kafka1 kafka-metadata-shell.sh \
--snapshot /bitnami/kafka/data/__cluster_metadata-0/00000000000000000000.log \
cat /metadataQuorum/leader
LeaderAndEpoch(leaderId=OptionalInt[1], epoch=3) Можно увидеть, что среди контроллеров был избран новый лидер (в эпоху 3) и теперь он отвечает за координацию обновлений метаданных кластера при добавлении или изменении конфигурации topic / partition и размещения реплик. Таким образом, реализация протокола консенсуса KRaft позволит использовать Kafka без необходимости использования хранения конфигурации в Zookeeper, что упрощает развертывание и повышает производительность при большом количестве topic, а также существенно уменьшает время восстановления после сбоев, поскольку все метаданные хранятся внутри кластера и не требуют дополнительного копирования и синхронизации.
Ну и напоследок хочу пригласить всех желающих на бесплатный урок курса Highload Architect по теме: «Шардирование в highload-системах».
