Учимся анализировать — полный цикл
Всем привет!
Контент будет ориентирован на новичков в анализе данных, ниже мы с Вами рассмотрим дата сет интернет-магазина, поставим цели и проверим гипотезы.
Язык программирования: Python
Весь код указан с пояснениями, но если у Вас возникли вопросы — отвечу в комментариях.
Начнем!!!
Интернет-магазин компьютерных игр
Цель проекта:
Нам необходимо выявить, определяющие успешность игры, закономерности. Эти данные позволят сделать ставку на потенциально популярный продукт и спланировать рекламные кампании.
Ход исследования:
Откройте файл с данными и изучите общую информацию
Подготовка данных
2.1. Замените названия столбцов;
2.2. Преобразуйте данные в нужные типы. Опишите, в каких столбцах заменили тип данных и почему;
2.3. Обработайте пропуски при необходимости:
2.3.1. Объясните, почему заполнили пропуски определённым образом или почему не стали это делать;
2.3.2. Опишите причины, которые могли привести к пропускам;
2.3.3. Обратите внимание на аббревиатуру 'tbd' в столбцах с рейтингом. Отдельно разберите это значение и опишите, как его обработать;
Исследовательский анализ данных
3.1. Посмотрите, сколько игр выпускалось в разные годы. Важны ли данные за все периоды?
3.2. Посмотрите, как менялись продажи по платформам. Выберите платформы с наибольшими суммарными продажами и постройте распределение по годам. За какой характерный срок появляются новые и исчезают старые платформы?
3.3. Возьмите данные за соответствующий актуальный период. Актуальный период определите самостоятельно в результате исследования предыдущих вопросов. Основной фактор — эти данные помогут построить прогноз на 2017 год.
3.4. Какие платформы лидируют по продажам, растут или падают? Выберите несколько потенциально прибыльных платформ;
3.5. Постройте график «ящик с усами» по глобальным продажам игр в разбивке по платформам. Опишите результат;
3.6. Посмотрите, как влияют на продажи внутри одной популярной платформы отзывы пользователей и критиков. Постройте диаграмму рассеяния и посчитайте корреляцию между отзывами и продажами. Сформулируйте выводы;
Составление портрета пользователя каждого региона, Определите для пользователя каждого региона (NA, EU, JP):
4.1. Самые популярные платформы (топ-5). Опишите различия в долях продаж.
4.2. Самые популярные жанры (топ-5). Поясните разницу.
4.3. Влияет ли рейтинг ESRB на продажи в отдельном регионе?
Проверка гипотез
5.1. Средние пользовательские рейтинги платформ Xbox One и PC одинаковые;
5.2. Средние пользовательские рейтинги жанров Action (англ. «действие», экшен-игры) и Sports (англ. «спортивные соревнования») разные;
5.3. Как вы сформулировали нулевую и альтернативную гипотезы;
5.4. Какой критерий применили для проверки гипотез и почему;
Общий вывод
Опишем значения столбцов в данных для удобства в работе:
Name — название игры
Platform — платформа
Year_of_Release — год выпуска
Genre — жанр игры
NA_sales — продажи в Северной Америке (миллионы проданных копий)
EU_sales — продажи в Европе (миллионы проданных копий)
JP_sales — продажи в Японии (миллионы проданных копий)
Other_sales — продажи в других странах (миллионы проданных копий)
Critic_Score — оценка критиков (максимум 100)
User_Score — оценка пользователей (максимум 10)
Rating — рейтинг от организации ESRB (англ. Entertainment Software Rating Board).
Эта ассоциация определяет рейтинг компьютерных игр и присваивает им подходящую возрастную категорию.
1. Открываем файл с данными и изучаем общую информацию
# импортируем необходимые нам библиотеки
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy import stats as st
import warnings
warnings.filterwarnings('ignore')
читаем файл с данными и сохраненяем в переменную data
data = pd.read_csv('/datasets/games.csv')
получаем первые 10 строк таблицы
display(data.head(10))
# проверяем тип данных в столбцах таблицы
data.info()
Изучая типы данных, с использование выгрузки из таблицы выше, можно заметить, что в столбце Year_of_Release вместо значения int стоит float. Так же в столбце User_Score необходимо изменить значение на float.
# выгружаем наименования стобцов для проверки корректного отображения
data.columns
Нам необходимо поработать с заголовками столбцов, а именно привести их к единому малому регистру. Делать мы это будем уже на следующем этапе «Подготовке данных».
# проверяем уникальные значения в столбцах, важно пробежаться по каждому столбцу и проверить
data['Name'].unique()
Вывод
Подведем промежуточный итог. Мы выгрузили таблицу и присвоили переменной data, и импортировали все необходимые библиотеки, которые будут нужны для дальнейшей работы. Далее мы с помощью метода info () проверили какие типы данные в каждом столбце и выяснили, что необходимо изменить тип данных в двух столбцах: Year_of_Release, User_Score.
тип данных в столбце Year_of_Release необходимо изменить с float на int
тип данных в столбце User_Score необходимо изменить с object на float
После этого проверили наименования столбцов, и выяснили, что столбцы некорректно записаны, и необходимо изменить регистр на малые буквы.
И напоследок проверили уникальные значения в ячейках таблицы и выяснили, что с некоторыми значениями необходимо поработать, а именно:
столбец Year_of_Release — значение NaN
столбец Genre — значение NaN
столбец Critic_Score — значение NaN
столбец User_Score — значения NaN и tbd
столбец Rating — значения NaN и K-A
Все указанные корректировки мы внесем и обоснуем на следующем этапе диагностики.
2. Подготовка данных
Заменяем названия столбцов
# изменяем регистр с помощью метода str.lower()
data.columns = data.columns.str.lower()
проверяем внесенные изменения
data.columnsIndex (['name', 'platform', 'year_of_release', 'genre', 'na_sales', 'eu_sales', 'jp_sales', 'other_sales', 'critic_score', 'user_score', 'rating'], dtype='object')
Еще раз просмотри ячейки, с которыми нам необходимо работать. Напомним, что некорректные, для анализа, ячейки находятся в столбцах year_of_release, genre, critic_score, user_score, rating.
# изменяем регистр zxttr столбца genre с помощью метода str.lower()
data['genre'] = data['genre'].str.lower()
выведем содержимое столбцов
display(data['year_of_release'].unique())
display(data['genre'].unique())
display(data['critic_score'].unique())
display(data['user_score'].unique())
display(data['rating'].unique())array ([2006., 1985., 2008., 2009., 1996., 1989., 1984., 2005., 1999.,
2007., 2010., 2013., 2004., 1990., 1988., 2002., 2001., 2011.,
1998., 2015., 2012., 2014., 1992., 1997., 1993., 1994., 1982.,
2016., 2003., 1986., 2000., nan, 1995., 1991., 1981., 1987.,
1980., 1983.])array (['sports', 'platform', 'racing', 'role-playing', 'puzzle', 'misc',
'shooter', 'simulation', 'action', 'fighting', 'adventure',
'strategy', nan], dtype=object)array ([76., nan, 82., 80., 89., 58., 87., 91., 61., 97., 95., 77., 88.,
83., 94., 93., 85., 86., 98., 96., 90., 84., 73., 74., 78., 92.,
71., 72., 68., 62., 49., 67., 81., 66., 56., 79., 70., 59., 64.,
75., 60., 63., 69., 50., 25., 42., 44., 55., 48., 57., 29., 47.,
65., 54., 20., 53., 37., 38., 33., 52., 30., 32., 43., 45., 51.,
40., 46., 39., 34., 35., 41., 36., 28., 31., 27., 26., 19., 23.,
24., 21., 17., 22., 13.])array (['8', nan, '8.3', '8.5', '6.6', '8.4', '8.6', '7.7', '6.3', '7.4',
'8.2', '9', '7.9', '8.1', '8.7', '7.1', '3.4', '5.3', '4.8', '3.2',
'8.9', '6.4', '7.8', '7.5', '2.6', '7.2', '9.2', '7', '7.3', '4.3',
'7.6', '5.7', '5', '9.1', '6.5', 'tbd', '8.8', '6.9', '9.4', '6.8',
'6.1', '6.7', '5.4', '4', '4.9', '4.5', '9.3', '6.2', '4.2', '6',
'3.7', '4.1', '5.8', '5.6', '5.5', '4.4', '4.6', '5.9', '3.9',
'3.1', '2.9', '5.2', '3.3', '4.7', '5.1', '3.5', '2.5', '1.9', '3',
'2.7', '2.2', '2', '9.5', '2.1', '3.6', '2.8', '1.8', '3.8', '0',
'1.6', '9.6', '2.4', '1.7', '1.1', '0.3', '1.5', '0.7', '1.2',
'2.3', '0.5', '1.3', '0.2', '0.6', '1.4', '0.9', '1', '9.7'],
dtype=object)array (['E', nan, 'M', 'T', 'E10+', 'K-A', 'AO', 'EC', 'RP'], dtype=object)
В столбце user_score выделим значение tbd. Выше мы воспользовались методом info () и обратили внимание, что формат ячейки object. Хотя судя по общему содержанию, а так же по описанию столбца (оценка пользователей (максимум 10)) тип данных должен быть float. Поэтому предлагаю считать данное значение (tbd) пустым и изменить на NaN.
# Функция для замены значения 'tbd' на NaN
def replace_wrong_user_scores(wrong_user_scores, correct_user_score):
data['user_score'] = data['user_score'].replace(wrong_user_scores, correct_user_score)
replace_wrong_user_scores('tbd', np.NaN)
проверяем уникальные значения в столбце после применения функции
data['user_score'].unique()array (['8', nan, '8.3', '8.5', '6.6', '8.4', '8.6', '7.7', '6.3', '7.4', '8.2', '9', '7.9', '8.1', '8.7', '7.1', '3.4', '5.3', '4.8', '3.2', '8.9', '6.4', '7.8', '7.5', '2.6', '7.2', '9.2', '7', '7.3', '4.3', '7.6', '5.7', '5', '9.1', '6.5', '8.8', '6.9', '9.4', '6.8', '6.1', '6.7', '5.4', '4', '4.9', '4.5', '9.3', '6.2', '4.2', '6', '3.7', '4.1', '5.8', '5.6', '5.5', '4.4', '4.6', '5.9', '3.9', '3.1', '2.9', '5.2', '3.3', '4.7', '5.1', '3.5', '2.5', '1.9', '3', '2.7', '2.2', '2', '9.5', '2.1', '3.6', '2.8', '1.8', '3.8', '0', '1.6', '9.6', '2.4', '1.7', '1.1', '0.3', '1.5', '0.7', '1.2', '2.3', '0.5', '1.3', '0.2', '0.6', '1.4', '0.9', '1', '9.7'], dtype=object)
Значение в столбце user_score скорректировано и далее уже будем работать со значением NaN.
В столбце rating есть два значения 'K-A' и 'E10+' — это два значения носящие один и тот же смысл (первоначально «K-A» («Kids to Adults»), потом было переименовано на E10+), поэтому предлагаю переименовать 'K-A' в 'E10+' для удобного и более точного анализа в дальнейшем.
# Функция для замены значения 'K-A' на 'E10+'
def replace_wrong_ratings(wrong_ratings, correct_rating):
data['rating'] = data['rating'].replace(wrong_ratings, correct_rating)
replace_wrong_ratings('K-A', 'E10+')
data['rating'].value_counts()E 3990
T 2961
M 1563
E10+ 1423
EC 8
RP 3
AO 1
Name: rating, dtype: int64
Внесем небольшие изменения в наименования значений столбца platform для того, чтобы было большее понимание о каких именно игровых платформах идет речь.
# Функция для замены значения аббревиатур на полное название бля понимание, что это за игровая платформа.
def replace_wrong_platforms(wrong_platforms, correct_platform):
data['platform'] = data['platform'].replace(wrong_platforms, correct_platform)
replace_wrong_platforms('2600', 'Atari 2600')
replace_wrong_platforms('Wii', 'Nintendo Wii')
replace_wrong_platforms('NES', 'Nintendo NES')
replace_wrong_platforms('GB', 'GB-60')
replace_wrong_platforms('DS', 'Nintendo DS')
replace_wrong_platforms('X360', 'Xbox 360')
replace_wrong_platforms('SNES', 'Nintendo SNES')
replace_wrong_platforms('GBA', 'Game Boy Advance')
replace_wrong_platforms('3DS', 'Nintendo 3DS')
replace_wrong_platforms('N64', 'Nintendo 64')
replace_wrong_platforms('XB', 'Xbox')
replace_wrong_platforms('XOne', 'Xbox One')
replace_wrong_platforms('WiiU', 'Nintendo Wii U')
replace_wrong_platforms('GC', 'Nintendo GameCube')
replace_wrong_platforms('GEN', 'SEGA Retro Genesis')
replace_wrong_platforms('DC', 'Dendy Classic')
replace_wrong_platforms('PSV', 'PS Vita')
replace_wrong_platforms('SAT', 'Sega Saturn')
replace_wrong_platforms('WS', 'WonderSwan')
replace_wrong_platforms('TG16', 'NEC TurboGrafx')
replace_wrong_platforms('3DO', 'Panasonic 3DO')
replace_wrong_platforms('GG', 'Game Gear')
replace_wrong_platforms('PCFX', 'NEC PC-FX')
проверяем уникальные значения в столбце
display(data['platform'].unique())array (['Nintendo Wii', 'Nintendo NES', 'GB-60', 'Nintendo DS', 'Xbox 360', 'PS3', 'PS2', 'Nintendo SNES', 'Game Boy Advance', 'PS4', 'Nintendo 3DS', 'Nintendo 64', 'PS', 'Xbox', 'PC', 'Atari 2600', 'PSP', 'Xbox One', 'Nintendo Wii U', 'Nintendo GameCube', 'SEGA Retro Genesis', 'Dendy Classic', 'PS Vita', 'Sega Saturn', 'SCD', 'WonderSwan', 'NG', 'NEC TurboGrafx', 'Panasonic 3DO', 'Game Gear', 'NEC PC-FX'], dtype=object)
Обрабатываем пропущенные значения
Вначале c помощью методов .isna ().sum () смотрим в каких столбцах есть пропуска, далее нам нужно понять удалять эти строки или заполнить по среднему значению или медиане.
data.isna().sum()name 2
platform 0
year_of_release 269
genre 2
na_sales 0
eu_sales 0
jp_sales 0
other_sales 0
critic_score 8578
user_score 9125
rating 6766
dtype: int64
В 6 столбцах есть пустые ячейки. Приступим к изучению.
столбец
nameотвечает за название компьютерной игры. По данной ячейке мы не можем рассчитать среднее значение или медиану. Оставить его пустым тоже нельзя, т.к. непонятно о какой видеоигре идет речь, поэтому мы принимаем решение удалить эти 2 строки, иначе они повлияют на нашу статистику. На счет появления пропуска в данном столбце можно сказать, что или его забыли указать при заведении данных, или у игры не было утверждено официальное название и поэтому ячейка оказалась пуста.в столбцах
critic_score,user_scoreдовольно много значений и поэтому мы рассчитаем медиану по показателям, т.к. пропуски могут повлиять на дальнейшую аналитику. Причиной отсутствия рейтинга может быть просто отсутствие оценок (неоцененные игры) или же игры были недавнего вышедшие и еще не получили свои оценки.со столбцом
year_of_releaseесть названия игр с указанием года выпуска и в итоге будет выглядеть не совсем логично (на примере ИД16373 игра с названием 'PDC World Championship Darts 2008' и год не указан.) Поэтому предлагаю удалить пропуска, чтобы не было нелогичного установления года выпуска. Пропуск в данном столбце мог возникнуть из-за того, что при заполнении данных об игре забыли указать или точная дата выхода игры точно не определена.столбец
genreтак же сложно подвести к какому-либо значению, т.к. необходимо знать конкретную игру. Так же удаляем строки с пустыми значениями. Пропуск в данном столбце мог возникнуть из-за того, что при заполнении данных об игре его забыли указать или не определились к какому именно жанру относится видеоигра.столбец
ratingтак же подлежит удалению, т.к. мы не сможем понять возрастное ограничение, если не будем знать это точно.
# удаляем строки с пустыми значениями в столбцах
data.dropna(subset = ['name', 'year_of_release', 'genre'], inplace = True)
Функция для присвоения пропущенных значениям в столбце 'rating' на значение 'неопределенные'
def replace_wrong_user_scores(wrong_user_scores, correct_user_score):
data['rating'] = data['rating'].replace(wrong_user_scores, correct_user_score)
replace_wrong_user_scores(np.NaN, 'неопределенный')Изменим тип данных в столбцах year_of_release и user_score.
# после удаления пропусков и корректировки неверных значений ячеек в столбцах необходимо перевести значения в корректный формат
data['year_of_release'] = data['year_of_release'].astype(int)
data['user_score'] = data['user_score'].astype(float)
проверяем изменение типов
data.info()
Int64Index: 16444 entries, 0 to 16714
Data columns (total 11 columns):
name 16444 non-null object
platform 16444 non-null object
year_of_release 16444 non-null int64
genre 16444 non-null object
na_sales 16444 non-null float64
eu_sales 16444 non-null float64
jp_sales 16444 non-null float64
other_sales 16444 non-null float64
critic_score 7983 non-null float64
user_score 7463 non-null float64
rating 16444 non-null object
dtypes: float64(6), int64(1), object (4)
memory usage: 1.5+ MB
# заполняем столбцы critic_score, user_score медианой по платформе
data.loc[data['critic_score'].isna(), 'critic_score'] = -1
data.loc[data['user_score'].isna(), 'user_score'] = -1
проверяем количество пропусков после удаления
data.isna().sum()name 0
platform 0
year_of_release 0
genre 0
na_sales 0
eu_sales 0
jp_sales 0
other_sales 0
critic_score 0
user_score 0
rating 0
dtype: int64
Отлично! С пропусками мы разобрались.
Теперь типы данных корректные. Таблица готова к дальнейшей диагностике.
Посчитаем суммарные продажи во всех регионах
Необходимо посчитать сумму продаж во всех регионах. Для этого суммируем значения нескольких столбцов (na_sales, eu_sales, jp_sales, other_sales) и полученные значения присвоить столбцу sum_sales_game.
# создадим отдельную таблицу для проведения общих расчетов, в дальнейшем она нам понадобится
data_all = data
посчитаем суммарные продажи во всех регионах
data['sum_sales_game'] = data[['na_sales','eu_sales','jp_sales', 'other_sales']].sum(axis = 1)
проверим
data.head(10)
Вывод
На стадии подготовки данных нам необходимо подготовить данные для последующего исследования. Начнем с изменения регистра в названии столбцов с помощью метода str.lower (), т.к. формат разных регистров в наименовании столбцов считается некорректным.
Далее нам необходимо проверить уже известные нам столбцы (year_of_release, genre, critic_score, user_score, rating) на наличие некорректных значений в ячейка. Помимо пустых ячеек NaN мы видим и другие значения. В столбце user_score выделим значение tbd. Выше мы воспользовались методом info () и обратили внимание, что формат ячейки object. Хотя судя по общему содержанию, а так же по описанию столбца (оценка пользователей (максимум 10)) тип данных должен быть float. Поэтому предлагаю считать данное значение (tbd) пустым и изменить на NaN. Значение в столбце user_score скорректировано и далее уже будем работать со значением NaN. В столбце rating есть два значения 'K-A' и 'E10+' — это два значения носящие один и тот же смысл (первоначально «K-A» («Kids to Adults»), потом было переименовано на E10+), поэтому предлагаю переименовать 'K-A' в 'E10+' для удобного и более точного анализа в дальнейшем.
В столбцах user_score и rating изменяем значения с помощью функций. Так же было принять решение изменить наименование платформ для более комфортного понимания платформ, о которых идет речь.
Следующей стадией будет обработка пропусков. Выяснить какие именно значения у нас пропущены и какое количество поможет метод isna ().sum ()
В 6 столбцах есть пустые ячейки. Приступим к изучению.
столбец name отвечает за название компьютерной игры. По данной ячейке мы не можем рассчитать среднее значение или медиану. Оставить его пустым тоже нельзя, т.к. непонятно о какой видеоигре идет речь, поэтому мы принимаем решение удалить эти 2 строки, иначе они повлияют на нашу статистику. На счет появления пропуска в данном столбце можно сказать, что или его забыли указать при заведении данных, или у игры не было утверждено официальное название и поэтому ячейка оказалась пуста.
в столбцах
critic_score,user_scoreдовольно много значений и поэтому мы рассчитаем присвоили значение -1 по пустым показателям, т.к. пропуски могут повлиять на дальнейшую аналитику. Причиной отсутствия рейтинга может быть просто отсутствие оценок (неоцененные игры) или же игры были недавнего вышедшие и еще не получили свои оценки.со столбцом
year_of_releaseесть названия игр с указанием года выпуска и в итоге будет выглядеть не совсем логично (на примере ИД16373 игра с названием 'PDC World Championship Darts 2008' и год не указан.) Поэтому предлагаю удалить пропуска, чтобы не было нелогичного установления года выпуска. Пропуск в данном столбце мог возникнуть из-за того, что при заполнении данных об игре забыли указать или точная дата выхода игры точно не определена.столбец genre так же сложно подвести к какому-либо значению, т.к. необходимо знать конкретную игру. Так же удаляем строки с пустыми значениями. Пропуск в данном столбце мог возникнуть из-за того, что при заполнении данных об игре его забыли указать или не определились к какому именно жанру относится видеоигра.
пустые значения столбца rating были заполнены значением «неопределенный»
После удаления пропусков мы приступим к изменению типа ячеек в столбцах year_of_release и user_score, как описывалось выше.
И напоследок выведем отдельный столбец с суммарным количеством продаж по всем регионам.
3. Исследовательский анализ данных
Посчитаем сколько игр вышло в разные года по разным платформам. Для этого сделаем 2 выгрузки: — первая выгрузка покажет нам сумму игр в группировке по игровой платформе и годам. — вторая выгрузка — общее количество игр по годам.
# первая выгрузка
count_games_1 = data.groupby(['platform', 'year_of_release'])['name'].count()
count_games_1platform year_of_release
Atari 2600 1980 9
1981 46
1982 36
1983 11
1984 1
…
Xbox 360 2016 13
Xbox One 2013 19
2014 61
2015 80
2016 87
Name: name, Length: 238, dtype: int64
Теперь посчитаем сколько игр вышло в разные года по всем платформам.
# вторая выгрузка
count_games_2 = data.groupby('year_of_release')['name'].count()
count_games_2year_of_release
1980 9
1981 46
1982 36
1983 17
1984 14
1985 14
1986 21
1987 16
1988 15
1989 17
1990 16
1991 41
1992 43
1993 60
1994 121
1995 219
1996 263
1997 289
1998 379
1999 338
2000 350
2001 482
2002 829
2003 775
2004 762
2005 939
2006 1006
2007 1197
2008 1427
2009 1426
2010 1255
2011 1136
2012 653
2013 544
2014 581
2015 606
2016 502
Name: name, dtype: int64
Для дальнейшей диагностики выделим года, по которым будет оптимально анализировать динамику продаж. Берем 2015 и 2016 года.
# оставим в выгрузке только нужные года
data = data.query("2015 <= year_of_release <= 2016")
построим график распределения по годам
data.pivot_table(index='year_of_release', columns = 'platform', values='sum_sales_game', aggfunc='sum').plot(grid=True, figsize=(15, 7))
plt.show()
Посмотрим, как менялись продажи по платформам.
На графике мы можем заметить, что продажи в течении года стремительно уменьшались и из всех платформ в выборке остались только две, по которым показатели значительно положительные. Это платформы Xbox One, PS4. По остальным платформам показатель близится к 0.
Далее выведем таблицу с подсчетом общих продаж.
# суммируем столбцы продаж и добавим результат в столбец sum_sales_game
data.groupby(['platform'])['na_sales', 'eu_sales', 'jp_sales', 'other_sales', 'sum_sales_game'].sum()
Из данной выгрузки мы можем выделить две игровые платформы с наибольшими суммарными продажами. Выделим от 40 млн продаж — это платформы: Xbox One, PS4, тем самым мы отсеиваем мало продаваемые позиции и устаревшие.
# обновим выгрузку и оставим только интересующие нас платформы
data = data.query("platform == ['Xbox One', 'PS4']")
data
На графике выше мы видим самые продаваемые позиции за период с 2015 по 2016 года. Обратим внимание, что все платформы, кроме Xbox One, PS4 к 2016 году приравниваются к 0 продаж.
За какой характерный срок появляются новые и исчезают старые платформы?
Новые модели, если не брать в расчет PS2, появлялись с регулярностью в 1 год, за исключением двух последних платформ, которые появились одновременно.
Исчезновение старых моделей так же было постепенно, относительно их появления, за исключением платформ Nintendo. Хоть они и появились в разные периоды, но эпоха Nintendo закончила в один год.
Возьмем данные за актуальный период, которые определим самостоятельно.
Актуальные период для прогноза на 2017 возьмем с 2015 по 2016 года. Данный период выбран в связи с тем, чтобы мы могли посмотреть какие платформы в принципе не будут продаваться. Если сделать период меньше, то часть данных будет урезана.
# Построим график распределения по годам с 2015 по 2016 (актуальный период)
data = data.query("platform == ['Xbox One', 'PS4'] and year_of_release == ['2015', '2016']")
data.pivot_table(index='year_of_release', columns = 'platform', values='sum_sales_game', aggfunc='sum').plot(grid=True, figsize=(15, 7))
# меняем наименование горизонтальной линии ('X')
plt.xlabel('Год и месяц реализации')
# меняем наименование вертикальной линии ('Y')
plt.ylabel('Продажи экземпляров (млн.)')
plt.show()
В данном обсуждении мы будем отталкиваться от актуального периода (2015–2016 года).
Если отталкивать от нашего графика, то можно сделать следующий вывод — потенциально прибыльной платформой можно считать PS4 и Xbox One. Именно эта платформа дольше всего «на плаву». Xbox One так же имеет продажи, но значительно меньше. Но так как продажи более 20 млн. — так же в рассмотрении.
Постройте график «ящик с усами» по глобальным продажам игр в разбивке по платформам. Опишите результат.
data.groupby('platform')['sum_sales_game'].describe()
# построим общую диаграмму размаха
data.boxplot(column='sum_sales_game', by='platform')
plt.show()
Просмотрев общую диаграмму размаха мы видели частые выбросы и редкие. Данные выбросы предлагаю оставить, т.к. есть игры, которые могли «стрельнуть» большими продажами.
Посмотрим, как влияют на продажи внутри одной популярной платформы отзывы пользователей и критиков.
Для диагностики возьмем платформу PS4, т.к. у этой платформы значительные продажи в 2016 году.
# выведем таблицу рассеивания по платформе PS3, отобразив отзывы пользователей
data[data['platform']=='PS4'].plot(x='user_score', y='sum_sales_game', kind='scatter', alpha=0.3, figsize=(8,8), grid=True)
plt.show()
# выведем таблицу рассеивания по платформе PS3, отобразив отзывы критиков
data[data['platform']=='PS4'].plot(x='critic_score', y='sum_sales_game', kind='scatter', alpha=0.3, figsize=(8,8), grid=True)
plt.show()
# вычислим корреляционную матрицу, диапазон элементов которой равен [-1, 1], по умолчанию она использует коэффициент корреляции Пирсона. sns.heatmap -это просто способ показать с помощью цветов, насколько сильны корреляции, где зеленый цвет в данном случае предполагает положительную корреляцию, близкую к 1 .
data_ps4 = data[data['platform']=='PS4']
data_ps4_cor = data_ps4['user_score'].corr(data_ps4['sum_sales_game'])
display('Корреляция слабо положительная: {}'.format(data_ps4_cor))'Корреляция слабо положительная: 0.07810659085915489'
# вычислим корреляционную матрицу, диапазон элементов которой равен [-1, 1], по умолчанию она использует коэффициент корреляции Пирсона. sns.heatmap -это просто способ показать с помощью цветов, насколько сильны корреляции, где зеленый цвет в данном случае предполагает положительную корреляцию, близкую к 1 .
#data_ps4_1 = data[data['platform']=='PS4']
создаем выгрузку без заглушек
data_without_user = data_ps4[data_ps4['user_score'] != -1]
data_without_user_cor = data_without_user['user_score'].corr(data_without_user['sum_sales_game'])
display('Корреляция слабо отрицательная: {}'.format(data_without_user_cor))'Корреляция слабо отрицательная: -0.05973845712638215'
# вычислим корреляционную матрицу, диапазон элементов которой равен [-1, 1], по умолчанию она использует коэффициент корреляции Пирсона. sns.heatmap -это просто способ показать с помощью цветов, насколько сильны корреляции, где зеленый цвет в данном случае предполагает положительную корреляцию, близкую к 1 .
#data_ps4_1 = data[data['platform']=='PS4']
data_ps4_cor = data_ps4['critic_score'].corr(data_ps4['sum_sales_game'])
display('Корреляция слабо положительная: {}'.format(data_ps4_cor))'Корреляция слабо положительная: 0.18098000145868295'
# создаем выгрузку без заглушек
data_without_critic = data_ps4[data_ps4['critic_score'] != -1]
data_without_critic_cor = data_without_critic['critic_score'].corr(data_without_critic['sum_sales_game'])
display('Корреляция слабо положительная: {}'.format(data_without_critic_cor))'Корреляция слабо положительная: 0.3928485555130601'
Перед подведение итогов еще раз посмотрим на продажи PS4
# Построим график распределения по годам с 2015 по 2016 (актуальный период)
ps3 = data.query("platform == ['PS4'] and year_of_release == ['2015', '2016']")
ps3.pivot_table(index='year_of_release', columns = 'platform', values='sum_sales_game', aggfunc='sum').plot(grid=True, figsize=(15, 7))
plt.show()
Сделаем небольшой вывод:
Просмотрев соотношение отзывов покупателе и критиков можно сказать, что большую часть составляют высокие оценки. Мы выяснили, что по данным из диаграммы рассеивания у нас:- слабо отрицательная корреляция -0.05973845712638215 по отзывам покупателей- слабо положительная корреляция 0.3928485555130601 по отзывам критиков
Сравним выводы с продажами игр на других платформах.
# воспользуемся переменной data_all со всеми платформами
data_all.groupby('platform')['sum_sales_game'].describe()
Построим диаграмму размаха по всем платформам. Ранее мы создали переменную data_all, которой сейчас и воспользуемся. Сделаем несколько диаграмм с постепенным уменьшением диапазона, тем самым мы уберем редкие выбросы и оставим более частые выбросы, которые так же важны для анализа.
# выводим диаграмму размаха общего плана
data_all.boxplot(column='sum_sales_game', by='platform', figsize=(25,7))
plt.show()
В представленной диаграмме мы видим, что есть очень редкие выбросы с продажами в 80 млн (видимо эта игра была очень популярная игра), так же редкие, в отличии от других, выбросы есть в диапазоне от 20 до 40 млн. Уберем эти выбросы и еще раз посмотрим на диаграмму размаха.
# теперь сужаем диапазон до 20 млн продаж
data_all.boxplot(column='sum_sales_game', by='platform', figsize=(25,7))
# подгоняем данные по стороне 'Y'
plt.ylim(0, 20)
plt.show()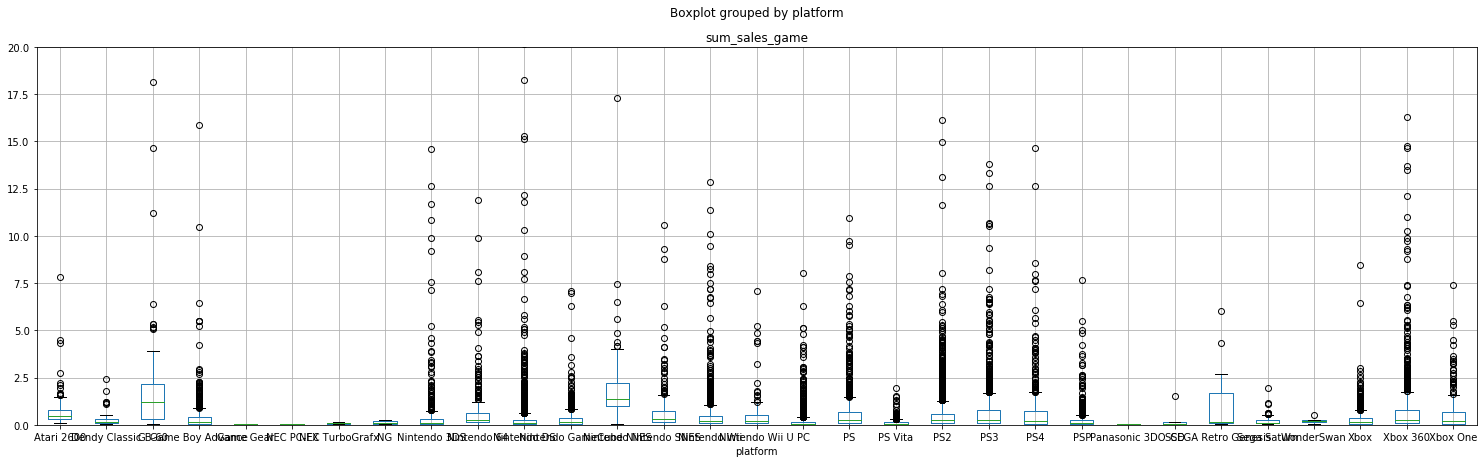
В этой выгрузке так же у всех позиций есть редкие выбросы, что нам не нужно. Если и оставлять выбросы, то они должны быть максимально частыми, которые будут полезны статистике. Мы уже близки к нашей финальной визуализации.
# сужаем диапазон до 5 млн продаж
data_all.boxplot(column='sum_sales_game', by='platform', figsize=(25,7))
# подгоняем данные по стороне 'Y'
plt.ylim(0, 5)
plt.show()
В диаграмме размаха выше можно было бы оставить этот вариант, но я предлагаю еще сузить диапазон до 3.9 млн
# сужаем диапазон до 3.9 млн продаж
data_all.boxplot(column='sum_sales_game', by='platform', figsize=(25,7))
# подгоняем данные по стороне 'Y'
plt.ylim(0, 3.9)
plt.show()
Финальная диаграмма готова. Конечно может возникнуть вопрос: зачем оставлять эту версию, если есть позиции где достаточно редкие выбросы? Ответим, что по данной выгрузке у нас большая часть позиций с очень частыми выбросами и убирать их было бы ошибкой.
Если сравнить продажи платформ из нашей выборки с теми, которые не попали в нее, то после просмотра диаграмм размаха с разными диапазонами можем подвести небольшой ИТОГ.
Можем выделить несколько платформ, которые выделяются: PS и PS4 и Xbox One. Границы этих платформ высокие, но при всем при этом медиана у всех платформ, кроме PS и PS3, не выходит за рамки 0.5 млн продаж, т.к. медиана и размах примерно на одном уровне, можно сказать, что у наших платформ, в отличии от тех, которые не попали в выборку есть намного больше игр, которые покупались намного чаще.
Предположим, потому что каждые из платформ из выборки были с нововведением:
Nintendo DS — платформа с 2 дисплееями, что то новое;
Nintendo Wii — платформа с дистанционной игрой;
PS2 — габариты данной платформы могли вызвать ажиотаж в покупке;
PS3 — появления функционала с дистанционной игрой, а так жсе платформа с возможностью выхода в интернет;
Xbox 360 — аналогия PS3 c иными джостиками.
Остальным приставки, были или такими же по функционалу и просто усовершенственной версией или такие платформы как Dendy Classic или Game Boy Advance были доступны не всем сегментам людей.
Для начала сделаем выгрузку жанров со всех платформ по всем годам, чтобы посмотреть какие жанры были успешны за все время.
Посмотрим на общее распределение игр по жанрам.
# посмотрим популярность жанров на всех платформах за все время
(
data_all.pivot_table(index='genre', values='sum_sales_game', aggfunc='median')
.boxplot(column='sum_sales_game', by='genre', figsize=(25,7))
)
plt.show()
(
data_all.pivot_table(index='genre', values='sum_sales_game', aggfunc='median')
.plot(grid=True, figsize=(12, 5))
)
plt.show()

В круговой диаграмме мы можем выделить ТОП-5 жанров:
1. Platform
2. Shooter
3. Sports
4. Fighting
5. Action
ТОП-5 самых непопулярных жанров:
1. Adventure
2. Puzzle
3. Strategy
4. Simulation
5. Misc
Теперь посмотрим какие будут результаты согласно нашей выборке. Будут ли они отличаться?
Посмотрим на распределение игр по жанрам в нашей выгрузке на 2016 год.
# смотрим популярность жанров исходя из нашей выборки
(
data.pivot_table(index='genre', values='sum_sales_game', aggfunc='median')
.boxplot(column='sum_sales_game', by='genre', figsize=(25,7))
)
plt.show()
(
data.pivot_table(index='genre', values='sum_sales_game', aggfunc='median')
.plot(grid=True, figsize=(12, 5))
)
plt.show()
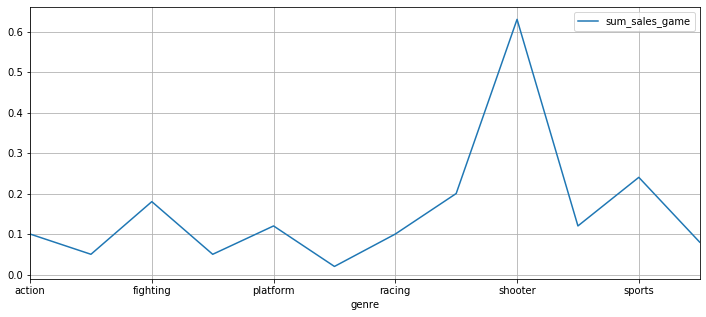
В круговой диаграмме мы можем выделить ТОП-5 жанров:
1. Shooter
2. Sports
3. Role-Playing
4. Fighting
5. Platform
ТОП-5 самых непопулярных жанров:
1. Puzzle
2. Adventure
3. Misc
4. Strategy
5. Racing
Вывод
Начнем исследовательский анализ данных с того, что посчитаем количество выпущенных игр с группировкой на года и платформы. После выгрузки мы уже можем сделать вывод в какие года выпускалось большего всего игр и взять этот период для нашей выгрузки. Период с 2015 по 2016 года был установлен исходят из актуальной диагностики в игровой индустрии.
Далее мы посчитаем суммарное количество продаж по каждой платформе в рамках выше указанных годов. По изучению суммарных показателей мы можем выделить самые продаваемые платформы с продажами 40 млн и более. У нас вышли следующие платформы (PS4 и Xbox One). Корректируем нашу выгрузку и оставляем в ней только эти позиции.
Теперь займемся построением графиков распределения.
Первый наш график будет показывать актуальность платформ по годам отталкиваясь от количество проданных игр. Подробное описание по данным графика вы можете почитать выше, чуть ниже самого графика выведена корректная диагностика с подробным описанием.
Модели выпускались с периодичностью в год, в некоторых годах выпускало аж 2 платформы сразу.
Далее нам необходимо определить актуальные период, для того чтобы спрогнозировать последующие продажи. Установим актуальный период с 2006 по 2016 года. Данный период выбран в связи с тем, чтобы мы могла посмотреть какие платформы в принципе не будут продаваться. Если сделать период меньше, то часть данных будет урезана.
Можно выделить лидирующую платформу — PS4.
Далее мы оставляем все выбросы, т.к. они нам важны для дальнейшей аналитики.
Так же нам необходимо посмотреть на примере одной популярной платформы влияют ли отзывы критиков и покупателей на продажи. Просмотрев соотношение отзывов покупателе и критиков можно сказать, что большую часть составляют высокие оценки, а график продаж мы вывели для того, чтобы показать что хорошие оценки покупателей и критиков соотносятся с продолжительными высокими продажами игр данной платформы. Так же мы выяснили, что по данным из диаграммы рассеивания у нас: корреляция слабо отрицательная: -0.0652804641386599
по оценкам покупателей корреляция слабо отрицательная: -0.0652804641386599
по оценкам критиков корреляция слабо положительная: 0.3914585293351539Далее мы решили сравнить показатели со всеми платформами которые выпускали и после вывода финальной диаграммы подвели итоги. Так как все подробно расписано дублировать здесь не будем, м
